
license: cc-by-nc-4.0
base_model: google/gemma-2b
model-index:
- name: Octopus-V2-2B
results: []
tags:
- function calling
- on-device language model
- android
inference: false
space: false
spaces: false
language:
- en
Octopus V2: On-device language model for super agent
Octopus V3 Release
We are excited to announce that Octopus v3 is now available! check our technical report and Octopus V3 tweet!
Key Features of Octopus v3:
- Efficiency: Sub-billion parameters, making it less than half the size of its predecessor, Octopus v2.
- Multi-Modal Capabilities: Proceed both text and images inputs.
- Speed and Accuracy: Incorporate our patented functional token technology, achieving function calling accuracy on par with GPT-4V and GPT-4.
- Multilingual Support: Simultaneous support for English and Mandarin.
Check the Octopus V3 demo video for Android and iOS.

Octopus V2 Release
After open-sourcing our model, we got many requests to compare our model with Apple's OpenELM and Microsoft's Phi-3. Please see Evaluation section. From our benchmark dataset, Microsoft's Phi-3 achieves accuracy of 45.7% and the average inference latency is 10.2s. While Apple's OpenELM fails to generate function call, please see this screenshot. Our model, Octopus V2, achieves 99.5% accuracy and the average inference latency is 0.38s.
{kind=link}
We are a very small team with many work. Please give us more time to prepare the code, and we will open source it. We hope Octopus v2 model will be helpful for you. Let's democratize AI agents for everyone. We've received many requests from car industry, health care, financial system etc. Octopus model is able to be applied to any function, and you can start to think about it now.
- Nexa AI Product - ArXiv - Video Demo
![]()
Introduction
Octopus-V2-2B, an advanced open-source language model with 2 billion parameters, represents Nexa AI's research breakthrough in the application of large language models (LLMs) for function calling, specifically tailored for Android APIs. Unlike Retrieval-Augmented Generation (RAG) methods, which require detailed descriptions of potential function arguments—sometimes needing up to tens of thousands of input tokens—Octopus-V2-2B introduces a unique functional token strategy for both its training and inference stages. This approach not only allows it to achieve performance levels comparable to GPT-4 but also significantly enhances its inference speed beyond that of RAG-based methods, making it especially beneficial for edge computing devices.
📱 On-device Applications: Octopus-V2-2B is engineered to operate seamlessly on Android devices, extending its utility across a wide range of applications, from Android system management to the orchestration of multiple devices.
🚀 Inference Speed: When benchmarked, Octopus-V2-2B demonstrates a remarkable inference speed, outperforming the combination of "Llama7B + RAG solution" by a factor of 36X on a single A100 GPU. Furthermore, compared to GPT-4-turbo (gpt-4-0125-preview), which relies on clusters A100/H100 GPUs, Octopus-V2-2B is 168% faster. This efficiency is attributed to our functional token design.
🐙 Accuracy: Octopus-V2-2B not only excels in speed but also in accuracy, surpassing the "Llama7B + RAG solution" in function call accuracy by 31%. It achieves a function call accuracy comparable to GPT-4 and RAG + GPT-3.5, with scores ranging between 98% and 100% across benchmark datasets.
💪 Function Calling Capabilities: Octopus-V2-2B is capable of generating individual, nested, and parallel function calls across a variety of complex scenarios.
Example Use Cases
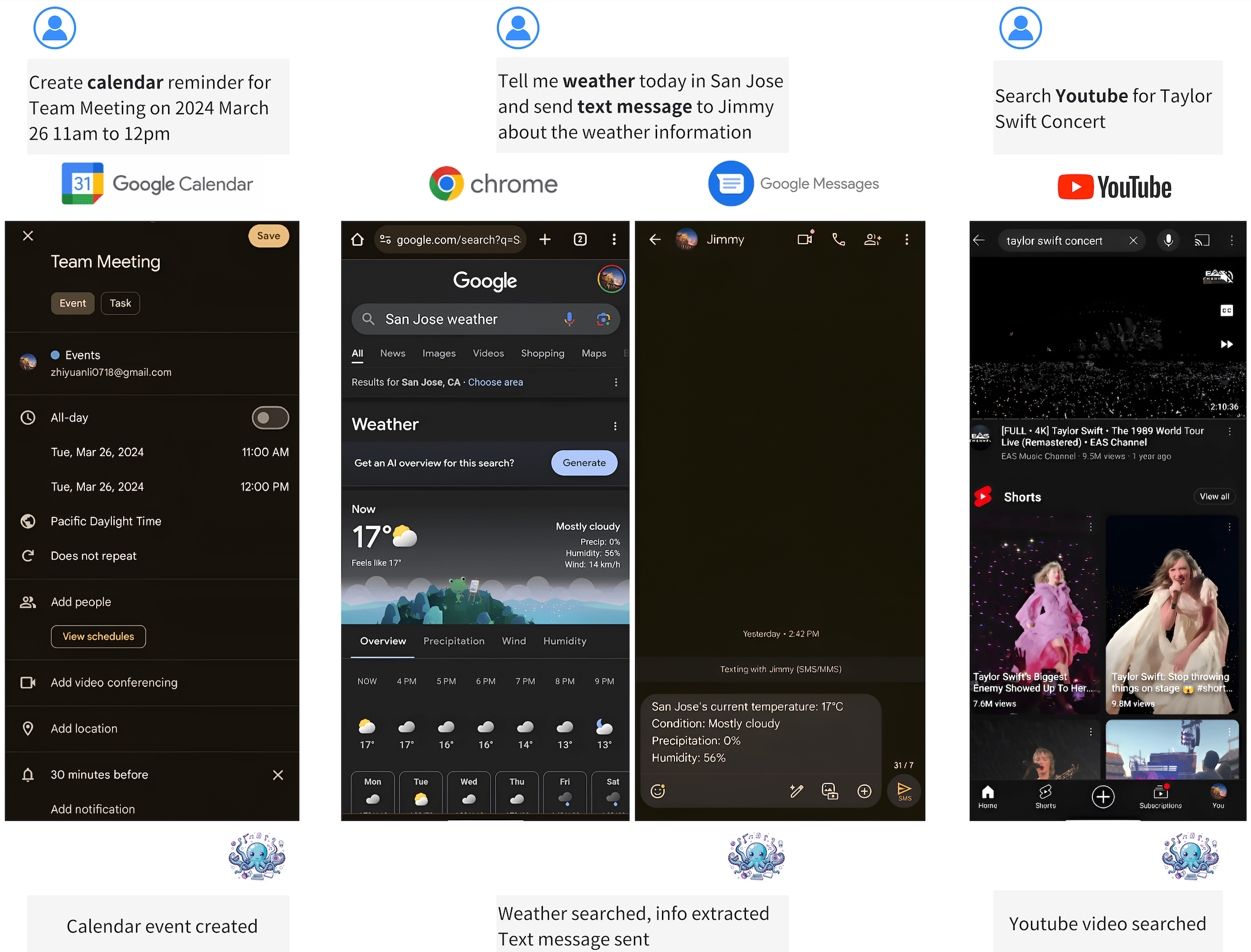
You can run the model on a GPU using the following code.
from transformers import AutoTokenizer, GemmaForCausalLM
import torch
import time
def inference(input_text):
start_time = time.time()
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
input_length = input_ids["input_ids"].shape[1]
outputs = model.generate(
input_ids=input_ids["input_ids"],
max_length=1024,
do_sample=False)
generated_sequence = outputs[:, input_length:].tolist()
res = tokenizer.decode(generated_sequence[0])
end_time = time.time()
return {"output": res, "latency": end_time - start_time}
model_id = "NexaAIDev/Octopus-v2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = GemmaForCausalLM.from_pretrained(
model_id, torch_dtype=torch.bfloat16, device_map="auto"
)
input_text = "Take a selfie for me with front camera"
nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"
start_time = time.time()
print("nexa model result:\n", inference(nexa_query))
print("latency:", time.time() - start_time," s")
Evaluation
The benchmark result can be viewed in this excel, which has been manually verified. Microsoft's Phi-3 model achieved an accuracy of 45.7%, with an average inference latency of 10.2 seconds. Meanwhile, Apple's OpenELM was unable to generate a function call, as shown in this screenshot. Additionally, OpenELM's score on the MMLU benchmark is quite low at 26.7, compared to Google's Gemma 2B, which scored 42.3.
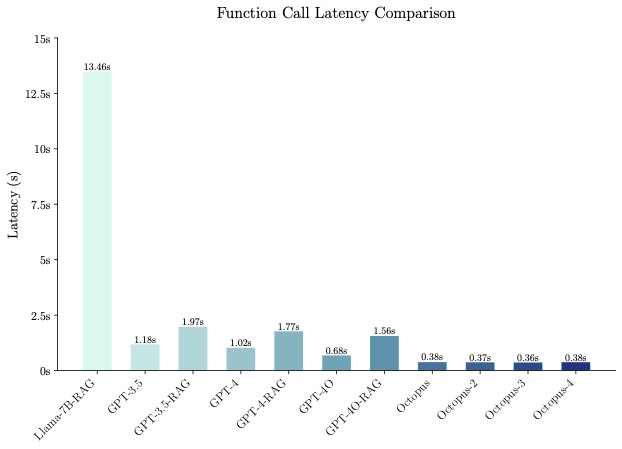
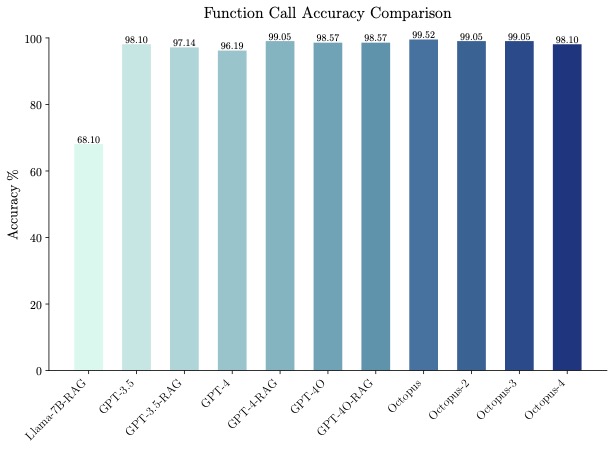
Note: One can notice that the query includes all necessary parameters used for a function. It is expected that query includes all parameters during inference as well.
Training Data
We wrote 20 Android API descriptions to used to train the models, see this file for details. The Android API implementations for our demos, and our training data will be published later. Below is one Android API description example
def get_trending_news(category=None, region='US', language='en', max_results=5):
"""
Fetches trending news articles based on category, region, and language.
Parameters:
- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.
- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.
- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.
- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.
Returns:
- list[str]: A list of strings, each representing an article. Each string contains the article's heading and URL.
"""
License
This model was trained on commercially viable data. For use of our model, refer to the license information.
References
We thank the Google Gemma team for their amazing models!
@misc{gemma-2023-open-models,
author = {{Gemma Team, Google DeepMind}},
title = {Gemma: Open Models Based on Gemini Research and Technology},
url = {https://goo.gle/GemmaReport},
year = {2023},
}
Citation
@misc{chen2024octopus,
title={Octopus v2: On-device language model for super agent},
author={Wei Chen and Zhiyuan Li},
year={2024},
eprint={2404.01744},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Contact
Please contact us to reach out for any issues and comments!