
File size: 2,156 Bytes
bc77b51 dbc0707 bc77b51 ef82ea7 069a6e9 f21473d bc77b51 f21473d fea3cb1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
---
datasets:
- HuggingFaceM4/vatex
language:
- en
metrics:
- bleu
- meteor
- rouge
pipeline_tag: text-generation
inference: false
tags:
- video-captioning
---
# SpaceTimeGPT - A Spatiotemporal Video Captioning Model
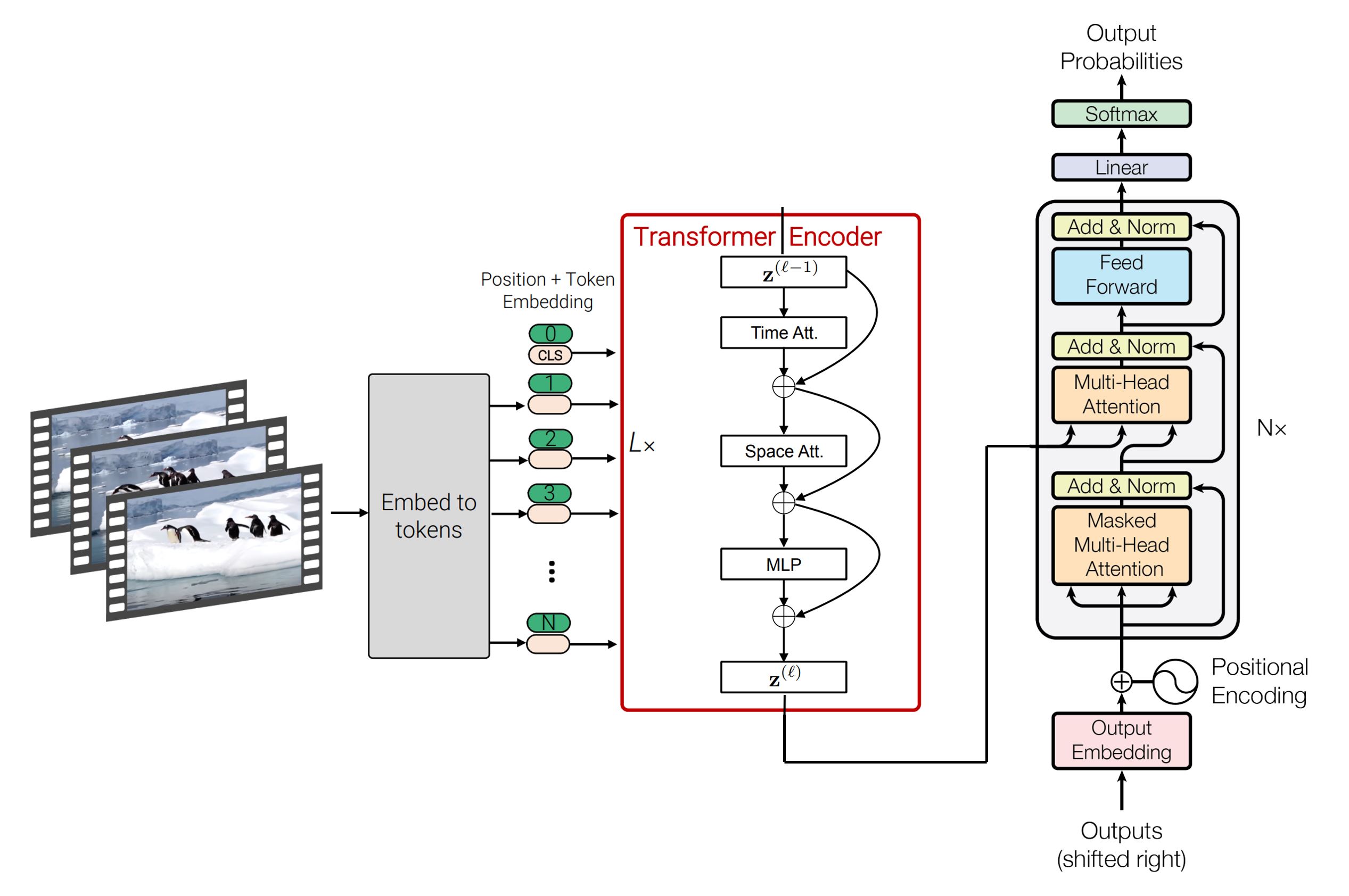
Vision Encoder Model: [timesformer-base-finetuned-k600](https://huggingface.co/facebook/timesformer-base-finetuned-k600) \
Text Decoder Model: [gpt2](https://huggingface.co/gpt2)
#### Evaluation Result:
67.2 CIDEr on [VaTeX](https://eric-xw.github.io/vatex-website/index.html) public test set
#### Example Inference Code:
```python
import av
import numpy as np
import torch
from transformers import AutoImageProcessor, AutoTokenizer, VisionEncoderDecoderModel
device = "cuda" if torch.cuda.is_available() else "cpu"
# load pretrained processor, tokenizer, and model
image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = VisionEncoderDecoderModel.from_pretrained("Neleac/timesformer-gpt2-video-captioning").to(device)
# load video
video_path = "never_gonna_give_you_up.mp4"
container = av.open(video_path)
# extract evenly spaced frames from video
seg_len = container.streams.video[0].frames
clip_len = model.config.encoder.num_frames
indices = set(np.linspace(0, seg_len, num=clip_len, endpoint=False).astype(np.int64))
frames = []
container.seek(0)
for i, frame in enumerate(container.decode(video=0)):
if i in indices:
frames.append(frame.to_ndarray(format="rgb24"))
# generate caption
gen_kwargs = {
"min_length": 10,
"max_length": 20,
"num_beams": 8,
}
pixel_values = image_processor(frames, return_tensors="pt").pixel_values.to(device)
tokens = model.generate(pixel_values, **gen_kwargs)
caption = tokenizer.batch_decode(tokens, skip_special_tokens=True)[0]
print(caption) # A man and a woman are dancing on a stage in front of a mirror.
```
#### Author Information:
👾 [Discord](https://discordapp.com/users/297770280863137802) \
🐙 [GitHub](https://github.com/Neleac) \
🤝 [LinkedIn](https://www.linkedin.com/in/caelenw/) |