

license: apache-2.0
language:
- en
pipeline_tag: text-generation
library_name: transformers
tags:
- nlp
- llm
K2: a fully-reproducible large language model outperforming Llama 2 70B using 35% less compute
LLM360 demystifies the training recipe used for Llama 2 70B with K2. K2 is fully transparent, meaning we’ve open-sourced all artifacts, including code, data, model checkpoints, intermediate results, and more.
About K2:
- 65 billion parameter LLM
- Tokens: 1.4T
- Languages: English
- Models Released: base, chat model
- Trained in 2 stages
- License: Apache 2.0
K2 was developed as a collaboration between MBZUAI, Petuum, and LLM360.
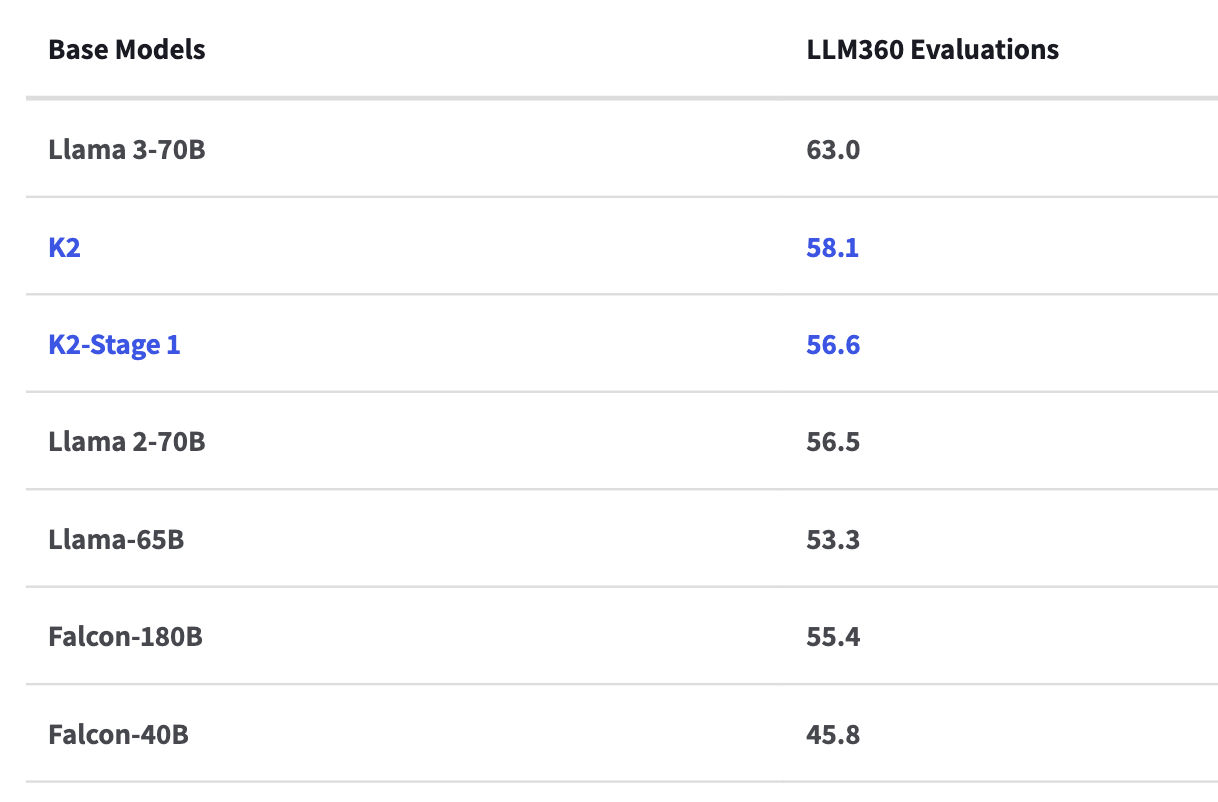
LLM360 Model Performance and Evaluation Collection
The LLM360 Performance and Evaluation Collection is a robust evaluations set consisting of general and domain specific evaluations to assess model knowledge and function.
Evaluations include standard best practice benchmarks, medical, math, and coding knowledge. More about the evaluations can be found here.

Detailed analysis can be found on the K2 Weights and Biases project here
K2 Gallery
The K2 gallery allows one to browse the output of various prompts on intermediate K2 checkpoints, which provides an intuitive understanding on how the model develops and improves over time. This is inspired by The Bloom Book.
Datasets and Mix
The following data mix was used to train K2 and achieve results in line with Llama 2 70B.
The full data sequence can be found here
| Dataset | Starting Tokens | Multiplier | Total Tokens | % of Total |
|---|---|---|---|---|
| dm-math | 4.33B | 3x | 13B | 1% |
| pubmed-abstracts | 4.77B | 3x | 14.3B | 1.1% |
| uspto | 4.77B | 3x | 14.3B | 1.1% |
| pubmed-central | 26B | 1x | 26B | 2% |
| redpajama.arxiv | 27.3B | 1x | 27.3B | 2.1% |
| starcoder.spm | 67.6B | 0.5x | 33.8B | 2.6% |
| starcoder.fim | 67.6B | 0.5x | 33.8B | 2.6% |
| redpajama.stackexchange | 61.1B | 1x | 61.1B | 4.7% |
| starcoder | 132.6B | 0.5x | 66.3B | 5.1% |
| pile-of-law | 76.7B | 1x | 76.7B | 5.9% |
| redpajama.book | 80.6B | 1x | 80.6B | 6.2% |
| s2orc | 107.9B | 1x | 107.9B | 8.3% |
| redpajama.wikipedia | 22.1B | 6x | 132.6B | 10.2% |
| refinedweb | 612.3B | 1x | 612.3B | 47.1% |
| Totals | - | - | 1.3T | 100% |
LLM360 Reasearch Suite
Stage 2 - Last 10 Checkpoints
| Checkpoints | |
|---|---|
| Checkpoint 380 | Checkpoint 375 |
| Checkpoint 379 | Checkpoint 374 |
| Checkpoint 378 | Checkpoint 373 |
| Checkpoint 377 | Checkpoint 372 |
| Checkpoint 376 | Checkpoint 371 |
Stage 1 - Last 10 Checkpoints
| Checkpoints | |
|---|---|
| Checkpoint 360 | Checkpoint 355 |
| Checkpoint 359 | Checkpoint 354 |
| Checkpoint 358 | Checkpoint 353 |
| Checkpoint 357 | Checkpoint 352 |
| Checkpoint 356 | Checkpoint 351 |
[to find all branches: git branch -a]
LLM360 Pretraining Suite
We provide step-by-step reproducation tutorials for tech enthusiasts, AI practitioners and academic or industry researchers who want to learn pretraining techniques here.
LLM360 Developer Suite
We provide step-by-step finetuning tutorials for tech enthusiasts, AI practitioners and academic or industry researchers here.
Loading K2
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2")
model = AutoModelForCausalLM.from_pretrained("LLM360/K2")
prompt = 'what is the highest mountain on earth?'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
About LLM360
LLM360 is an open research lab enabling community-owned AGI through open-source large model research and development.
LLM360 enables community-owned AGI by creating standards and tools to advance the bleeding edge of LLM capability and empower knowledge transfer, research, and development.
We believe in a future where artificial general intelligence (AGI) is created by the community, for the community. Through an open ecosystem of equitable computational resources, high quality data, and flowing technical knowledge, we can ensure ethical AGI development and universal access for all innovators.
Citation
BibTeX:
@article{K2,
title={LLM360 K2-65B: Scaling Up Fully Transparent Open-Source LLMs},
author={The LLM360 Team},
year={2024},
}