
DynMoE Family
Collection
DynMoE model checkpoints and paper on huggingface
•
4 items
•
Updated
•
2
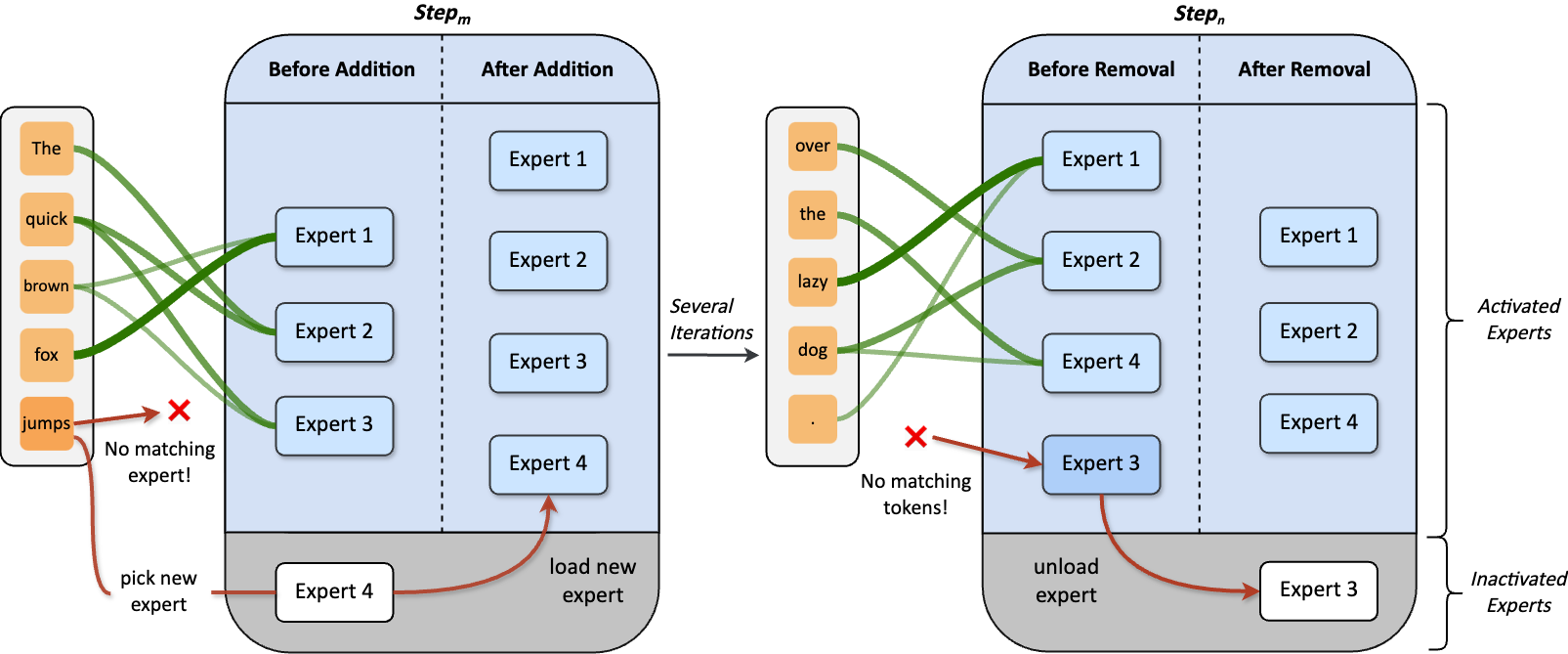
Dynamic Mixture of Experts (DynMoE) incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training.
We are grateful for the following awesome projects:
This project is released under the Apache-2.0 license as found in the LICENSE file.
@misc{guo2024dynamic,
title={Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models},
author={Yongxin Guo and Zhenglin Cheng and Xiaoying Tang and Tao Lin},
year={2024},
eprint={2405.14297},
archivePrefix={arXiv},
primaryClass={cs.LG}
}