
Kohaku XL
Collection
Kohaku series SDXL anime base model
•
9 items
•
Updated
•
7
The best example of tuning t2i model at home with consumer-level hardware












Kohaku XL Epsilon, the fifth major iteration in the Kohaku XL series, features a 5.2 million images dataset, LyCORIS fine-tuning[1], trained on comsumer-level hardware, and is fully open-sourced.
CCIP score on 3600 characters
(0~1, higher is better)
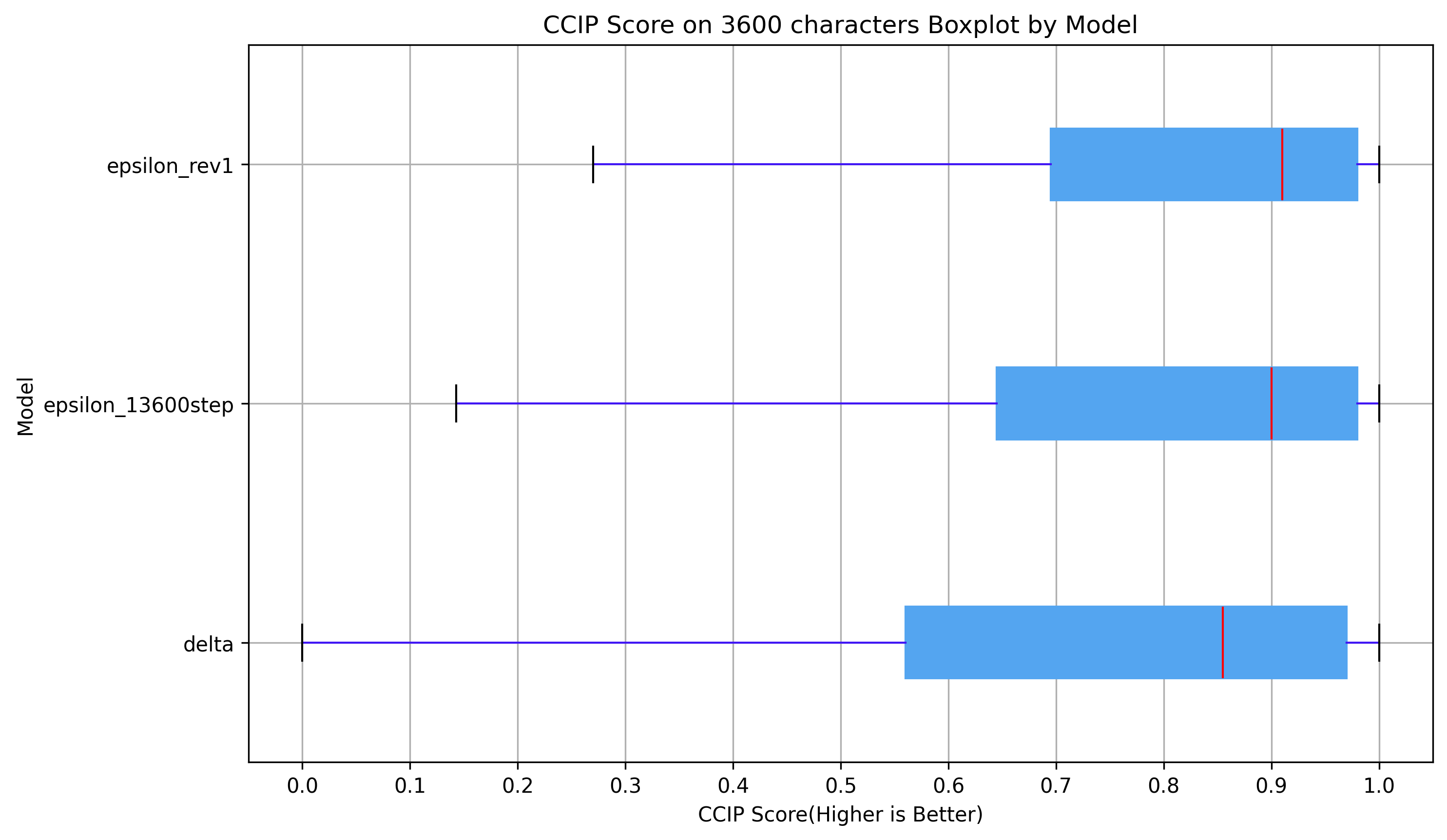 Clearly, Kohaku XL Epsilon is way better than Kohaku XL Delta
Clearly, Kohaku XL Epsilon is way better than Kohaku XL Delta
<1girl/1boy/1other/...>,
<character>, <series>, <artists>,
<general tags>,
<quality tags>, <year tags>, <meta tags>, <rating tags>
Kohaku XL Epsilon has mastered more artists' styles then Delta. But it also increases the stablility when combining multiple artist tags together. Users are encouraged to make their own style prompts.
Some good style prompts
ask \(askzy\), torino aqua, migolu, (jiu ye sang:1.1), (rumoon:0.9), (mizumi zumi:1.1)
ciloranko, maccha \(mochancc\), lobelia \(saclia\), migolu,
ask \(askzy\), wanke, (jiu ye sang:1.1), (rumoon:0.9), (mizumi zumi:1.1)
shiro9jira, ciloranko, ask \(askzy\), (tianliang duohe fangdongye:0.8)
(azuuru:1.1), (torino aqua:1.2), (azuuru:1.1), kedama milk,
fuzichoco, ask \(askzy\), chen bin, atdan, hito, mignon
ask \(askzy\), torino aqua, migolu
All the danbooru tags with at least 1000 popularity should work. All the danbooru tags with at least 100 popularity can possibly work with high emphasis.
Remember to remove all the underscore in tags. (Underscores in short tags are not be removed, which are very likely part of emoji tags.)
Remember to use xxx\(yyy\)when tag have bracket and you are using sd-webui.
Quality Tags Quality tags are assigned based on the percentile rankings of the favorite count (fav_count) within each rating category to avoid bias on nsfw content (Animagine XL v3 have met this problem), organized from high to low as follows: 90th, 75th, 60th, 45th, 30th, and 10th percentiles. This creates seven distinct quality levels separated by six thresholds.
I lower the threshold since I found that the average quality of images in Danbooru is higher than I expected.
Rating tags
Note: During training, content tagged as "explicit" is also considered under "nsfw" to ensure a comprehensive understanding.
Date tags Date tags are based on the upload dates of the images, as the metadata does not include the actual creation dates. The periods are categorized as follows:
This model is trained for resolutions from ARB 1024x1024 with minimum resolution 256 and maximum resolution 4096. This means you can use the standard SDXL resolution. However, opting for a slightly higher resolution than 1024x1024 is recommended. Applying a hires-fix is also suggested for better results.
For more information, please check out the sample images provided.
Same as Delta, just a test for new dataset and it is good. The outputs are also very different (compare to Delta).
The dataset for training this model was sourced from HakuBooru, comprising 5.2 million images selected from the danbooru2023 dataset.[2][3]
A selection process was employed to choose 1 million posts from IDs 0 to 2,000,000, another 2 millions from IDs 2,000,000 to 4,999,999, and all posts after ID 5,000,000, totaling 5.35 million posts. After filtering out deleted posts, gold account posts and those without images (which could be GIFs or MP4s), the final dataset comprised 5.2 million images.
The selection was essentially random, but a fixed seed was utilized to ensure reproducibility.
Further Process
The training of Kohaku XL Epsilon was facilitated by the LyCORIS project and the trainer from kohya-ss/sd-scripts. [1][4]
Algorithm: LoKr[5] The model was trained using the LoKr algorithm with full matrix triggered and a factor of 2~8 for different modules. The aim was to demonstrate the applicability of LoRA/LyCORIS in training base models.
The original LoKr file size is under 800MB, and the TE was not frozen. The original LoKr file also be provided as "delta-lokr" version.
For detailed settings, refer to the LyCORIS config file from Kohaku XL Delta.
Other Training Details
Warning: Versions 0.36.0~0.41.0 of bitsandbytes have significant bugs in the 8bit optimizer that could compromise training, so updating is essential.[6]
Training Cost Utilizing DDP with four RTX 3090s, completing 1 epoch across the 5.2 million image dataset took approximately 12 to 13 days. Each step for an equivalent batch size of 256 took about 49 to 50 seconds to complete.
The training progress have crashed when between 13600step~15300step. And kohya-ss trainer didn't implement resume+step skip before.
Although Kohya and I figured out how to do it correctly and did some sanity check on it. I still cannot fully ensure the final result is correct. So I publish the final intermedate ckpt so if anyone want to reproduce the training. They have chance to figure out the problem of final result.
I am focusing on making new dataset (targeting 10M~15M images), and wait for SD3 to see if it is worth trying.
I may also do some small FT on Epsilon and publish them as rev2/3/4... but dataset still my main focus now.
AngelBottomless & Nyanko7: danbooru2023 dataset[3] Kohya-ss: Trainer[4]
AI art should be looked like AI, not like humans.
(Some fun fact: this slogan come from my personal homepage. Lot of ppl like this one and put it in their model page.)
[1] SHIH-YING YEH, Yu-Guan Hsieh, Zhidong Gao, Bernard B W Yang, Giyeong Oh, & Yanmin Gong (2024). Navigating Text-To-Image Customization: From LyCORIS Fine-Tuning to Model Evaluation. In The Twelfth International Conference on Learning Representations.
[2] HakuBooru - text-image dataset maker for booru style image platform. https://github.com/KohakuBlueleaf/HakuBooru
[3] Danbooru2023: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset. https://huggingface.co/datasets/nyanko7/danbooru2023
[4] kohya-ss/sd-scripts. https://github.com/kohya-ss/sd-scripts
[5] LyCORIS - Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion. https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Algo-Details.md#lokr
[6] TimDettmers/bitsandbytes - issue 659/152/227/262 - Wrong indented lines cause bugs for a long time. https://github.com/TimDettmers/bitsandbytes/issues/659
This model is licensed under "Fair-AI public license 1.0-SD", please refer to the original License for more information: https://freedevproject.org/faipl-1.0-sd/