
Pretraining Without Attention(BiGS)
Official JAX Models with Maximal Sequence Length 512
This is the finetune checkpoint in MNLI with val accuracy 86.54
Paper
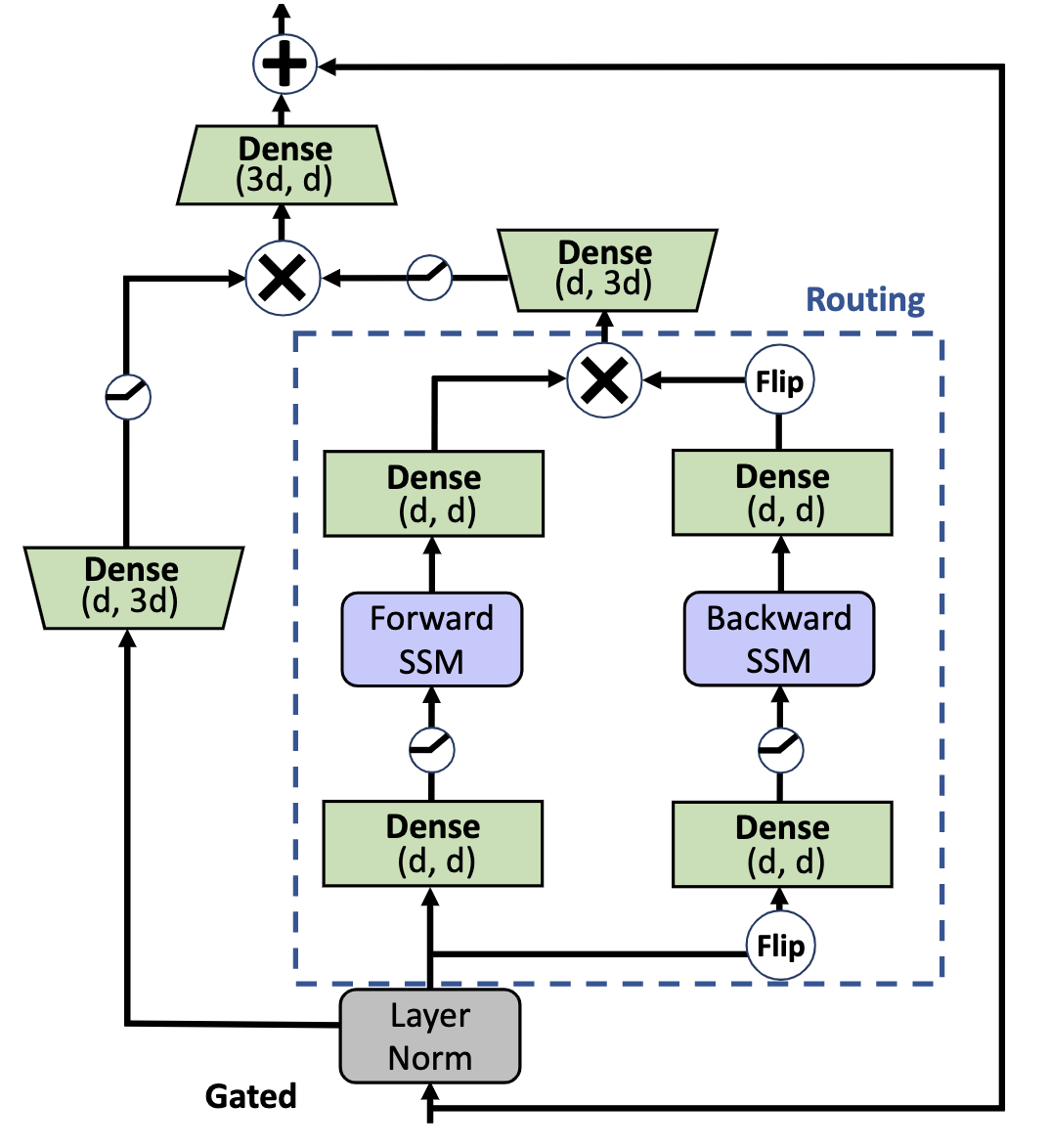
This repository contains BiGS's jax model definitions, pretrained models weights, training and fintuning code for our paper exploring using state space models for pretraining. You can find more details in our paper.
Pretraining Without Attention
Junxiong Wang, Jing Nathan Yan, Albert Gu, Alexander M.Rush
Cornell University, Cornell Tech, DeepMind
Transformers have been essential to pretraining success in NLP. While other architectures have been used, downstream accuracy is either significantly worse, or requires attention layers to match standard benchmarks such as GLUE. This work explores pretraining without attention by using recent advances in sequence routing based on state-space models (SSMs). Our proposed model, Bidirectional Gated SSM (BiGS), combines SSM layers with a multiplicative gating architecture that has been effective in simplified sequence modeling architectures. The model learns static layers that do not consider pair-wise interactions. Even so, BiGS is able to match BERT pretraining accuracy on GLUE and can be extended to long-form pretraining of 4096 tokens without approximation. Analysis shows that while the models have similar accuracy, the approach has significantly different inductive biases than BERT in terms of interactions and syntactic representations.
Load Sequence Classification Model
from BiGS.modeling_flax_bigs import FlaxBiGSForSequenceClassification
model = FlaxBiGSForSequenceClassification.from_pretrained('JunxiongWang/BiGS_512_MNLI')
GLUE
For MRPC, STS-B and RTE, we finetune on the MNLI model
export TASK_NAME=mrpc
python run_glue.py \
--model_name_or_path JunxiongWang/BiGS_512_MNLI \
--task_name $TASK_NAME \
--max_seq_length 512 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--per_device_train_batch_size 2 \
--logging_steps 100 \
--eval_steps 500 \
--weight_decay 0.01 \
--output_dir BiGS_$TASK_NAME/
| Task | Metric | Result |
|---|---|---|
| MRPC | F1/Accuracy | 88.3/83.3 |
| STS-B | Pearson/Spearman corr. | 89.9/89.7 |
| RTE | Accuracy | 79.8 |
- Downloads last month
- 9