
license: apache-2.0
datasets:
- imagenet-1k
metrics:
- accuracy
pipeline_tag: image-classification
tags:
- vision
language:
- en
library_name: pytorch
TransNeXt
Official Model release for "TransNeXt: Robust Foveal Visual Perception for Vision Transformers" [CVPR 2024] .
Model Details
- Code: https://github.com/DaiShiResearch/TransNeXt
- Paper: TransNeXt: Robust Foveal Visual Perception for Vision Transformers
- Author: Dai Shi
- Email: daishiresearch@gmail.com
Methods
Pixel-focused attention (Left) & aggregated attention (Right):
![]()
Convolutional GLU (First on the right):
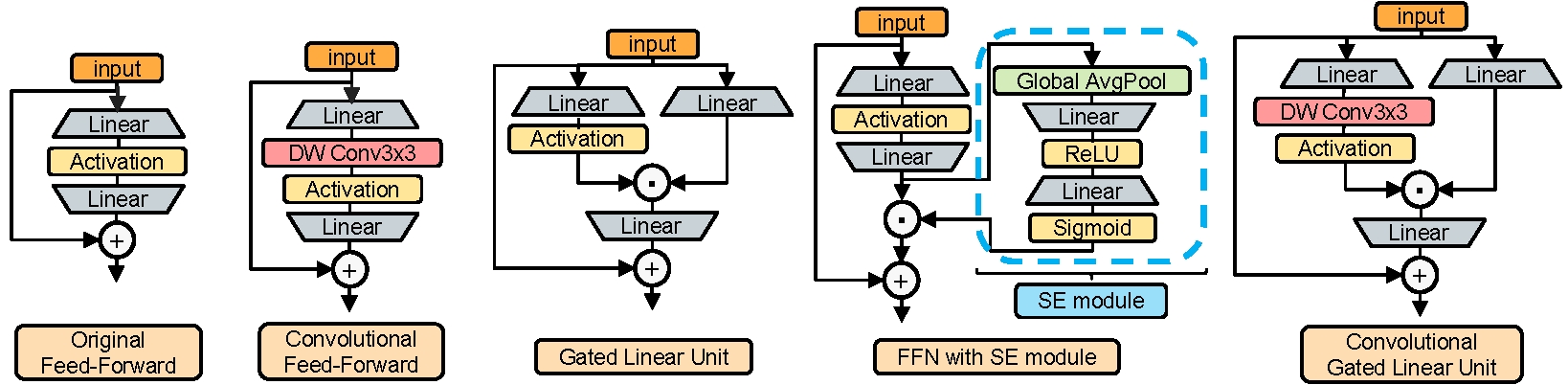
Results
Image Classification, Detection and Segmentation:

Attention Visualization:
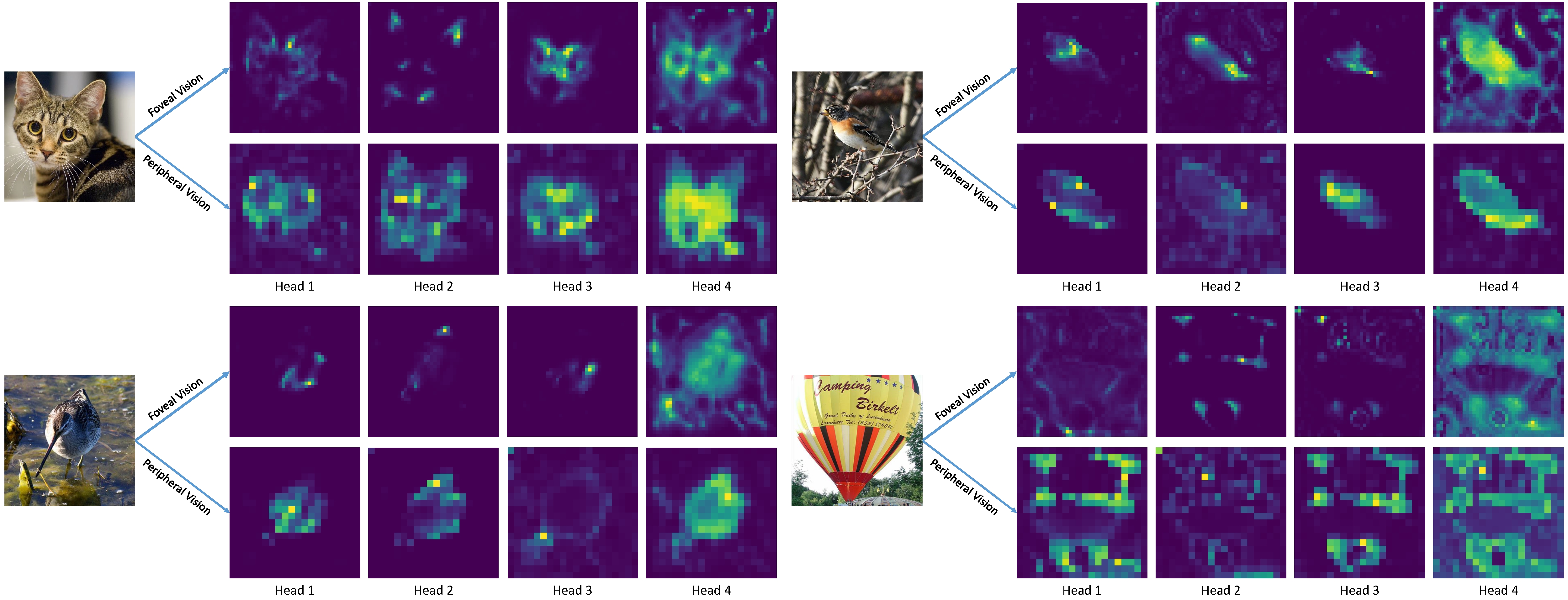
Model Zoo
Image Classification
Classification code & weights & configs & training logs are >>>here<<<.
ImageNet-1K 224x224 pre-trained models:
| Model | #Params | #FLOPs | IN-1K | IN-A | IN-C↓ | IN-R | Sketch | IN-V2 | Download | Config | Log |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TransNeXt-Micro | 12.8M | 2.7G | 82.5 | 29.9 | 50.8 | 45.8 | 33.0 | 72.6 | model | config | log |
| TransNeXt-Tiny | 28.2M | 5.7G | 84.0 | 39.9 | 46.5 | 49.6 | 37.6 | 73.8 | model | config | log |
| TransNeXt-Small | 49.7M | 10.3G | 84.7 | 47.1 | 43.9 | 52.5 | 39.7 | 74.8 | model | config | log |
| TransNeXt-Base | 89.7M | 18.4G | 84.8 | 50.6 | 43.5 | 53.9 | 41.4 | 75.1 | model | config | log |
ImageNet-1K 384x384 fine-tuned models:
| Model | #Params | #FLOPs | IN-1K | IN-A | IN-R | Sketch | IN-V2 | Download | Config |
|---|---|---|---|---|---|---|---|---|---|
| TransNeXt-Small | 49.7M | 32.1G | 86.0 | 58.3 | 56.4 | 43.2 | 76.8 | model | config |
| TransNeXt-Base | 89.7M | 56.3G | 86.2 | 61.6 | 57.7 | 44.7 | 77.0 | model | config |
ImageNet-1K 256x256 pre-trained model fully utilizing aggregated attention at all stages:
(See Table.9 in Appendix D.6 for details)
| Model | Token mixer | #Params | #FLOPs | IN-1K | Download | Config | Log |
|---|---|---|---|---|---|---|---|
| TransNeXt-Micro | A-A-A-A | 13.1M | 3.3G | 82.6 | model | config | log |
Object Detection
Object detection code & weights & configs & training logs are >>>here<<<.
COCO object detection and instance segmentation results using the Mask R-CNN method:
| Backbone | Pretrained Model | Lr Schd | box mAP | mask mAP | #Params | Download | Config | Log |
|---|---|---|---|---|---|---|---|---|
| TransNeXt-Tiny | ImageNet-1K | 1x | 49.9 | 44.6 | 47.9M | model | config | log |
| TransNeXt-Small | ImageNet-1K | 1x | 51.1 | 45.5 | 69.3M | model | config | log |
| TransNeXt-Base | ImageNet-1K | 1x | 51.7 | 45.9 | 109.2M | model | config | log |
COCO object detection results using the DINO method:
| Backbone | Pretrained Model | scales | epochs | box mAP | #Params | Download | Config | Log |
|---|---|---|---|---|---|---|---|---|
| TransNeXt-Tiny | ImageNet-1K | 4scale | 12 | 55.1 | 47.8M | model | config | log |
| TransNeXt-Tiny | ImageNet-1K | 5scale | 12 | 55.7 | 48.1M | model | config | log |
| TransNeXt-Small | ImageNet-1K | 5scale | 12 | 56.6 | 69.6M | model | config | log |
| TransNeXt-Base | ImageNet-1K | 5scale | 12 | 57.1 | 110M | model | config | log |
Semantic Segmentation
Semantic segmentation code & weights & configs & training logs are >>>here<<<.
ADE20K semantic segmentation results using the UPerNet method:
| Backbone | Pretrained Model | Crop Size | Lr Schd | mIoU | mIoU (ms+flip) | #Params | Download | Config | Log |
|---|---|---|---|---|---|---|---|---|---|
| TransNeXt-Tiny | ImageNet-1K | 512x512 | 160K | 51.1 | 51.5/51.7 | 59M | model | config | log |
| TransNeXt-Small | ImageNet-1K | 512x512 | 160K | 52.2 | 52.5/52.8 | 80M | model | config | log |
| TransNeXt-Base | ImageNet-1K | 512x512 | 160K | 53.0 | 53.5/53.7 | 121M | model | config | log |
- In the context of multi-scale evaluation, TransNeXt reports test results under two distinct scenarios: interpolation and extrapolation of relative position bias.
ADE20K semantic segmentation results using the Mask2Former method:
| Backbone | Pretrained Model | Crop Size | Lr Schd | mIoU | #Params | Download | Config | Log |
|---|---|---|---|---|---|---|---|---|
| TransNeXt-Tiny | ImageNet-1K | 512x512 | 160K | 53.4 | 47.5M | model | config | log |
| TransNeXt-Small | ImageNet-1K | 512x512 | 160K | 54.1 | 69.0M | model | config | log |
| TransNeXt-Base | ImageNet-1K | 512x512 | 160K | 54.7 | 109M | model | config | log |
Citation
If you find our work helpful, please consider citing the following bibtex. We would greatly appreciate a star for this project.
@InProceedings{shi2023transnext,
author = {Dai Shi},
title = {TransNeXt: Robust Foveal Visual Perception for Vision Transformers},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {17773-17783}
}