Zesen Cheng
ClownRat



AI & ML interests
multi-modal foundation model; Segmentation, Detection, and Tracking;
Recent Activity
upvoted
a
paper
15 days ago
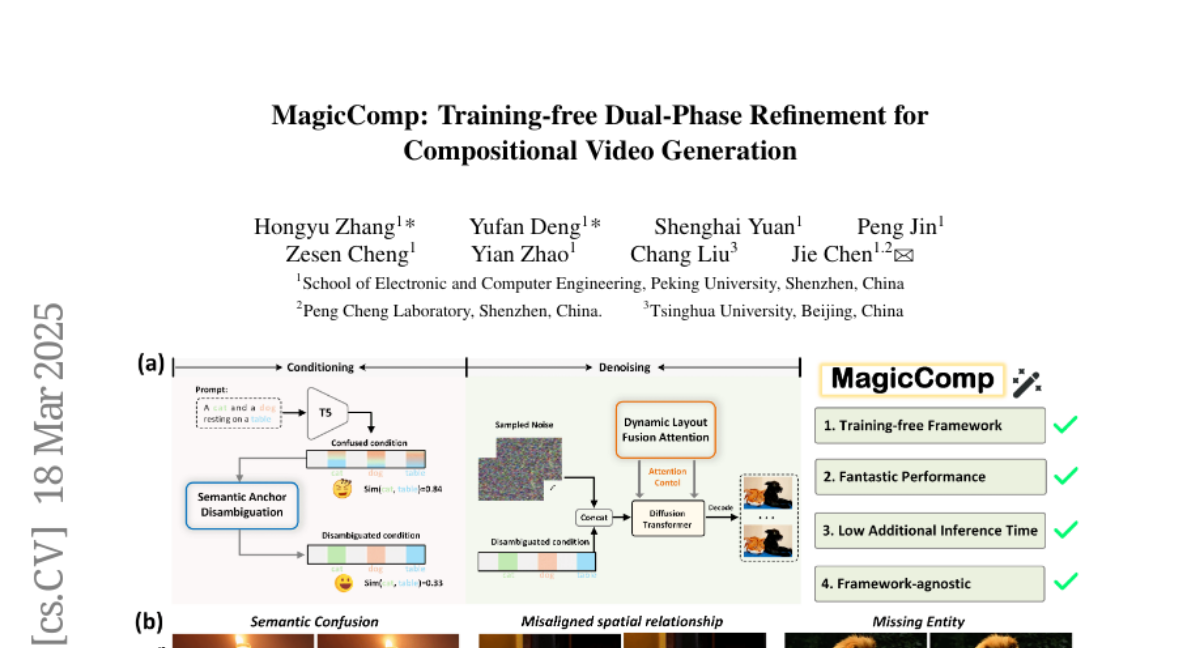
MagicComp: Training-free Dual-Phase Refinement for Compositional Video
Generation
authored
a paper
15 days ago
MagicComp: Training-free Dual-Phase Refinement for Compositional Video
Generation
upvoted
a
paper
21 days ago
LLaVA-o1: Let Vision Language Models Reason Step-by-Step
Organizations