
YAML Metadata
Warning:
empty or missing yaml metadata in repo card
(https://huggingface.co/docs/hub/model-cards#model-card-metadata)
KoMiniLM
🐣 Korean mini language model
Overview
Current language models usually consist of hundreds of millions of parameters which brings challenges for fine-tuning and online serving in real-life applications due to latency and capacity constraints. In this project, we release a light weight korean language model to address the aforementioned shortcomings of existing language models.
Quick tour
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("BM-K/KoMiniLM") # 23M model
model = AutoModel.from_pretrained("BM-K/KoMiniLM")
inputs = tokenizer("안녕 세상아!", return_tensors="pt")
outputs = model(**inputs)
Update history
** Updates on 2022.06.20 **
- Release KoMiniLM-bert-68M
** Updates on 2022.05.24 **
- Release KoMiniLM-bert-23M
Pre-training
Teacher Model: KLUE-BERT(base)
Object
Self-Attention Distribution and Self-Attention Value-Relation [Wang et al., 2020] were distilled from each discrete layer of the teacher model to the student model. Wang et al. distilled in the last layer of the transformer, but that was not the case in this project.
Data sets
| Data | News comments | News article |
|---|---|---|
| size | 10G | 10G |
Config
- KoMiniLM-23M
{
"architectures": [
"BertForPreTraining"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 384,
"initializer_range": 0.02,
"intermediate_size": 1536,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 6,
"output_attentions": true,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"return_dict": false,
"torch_dtype": "float32",
"transformers_version": "4.13.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 32000
}
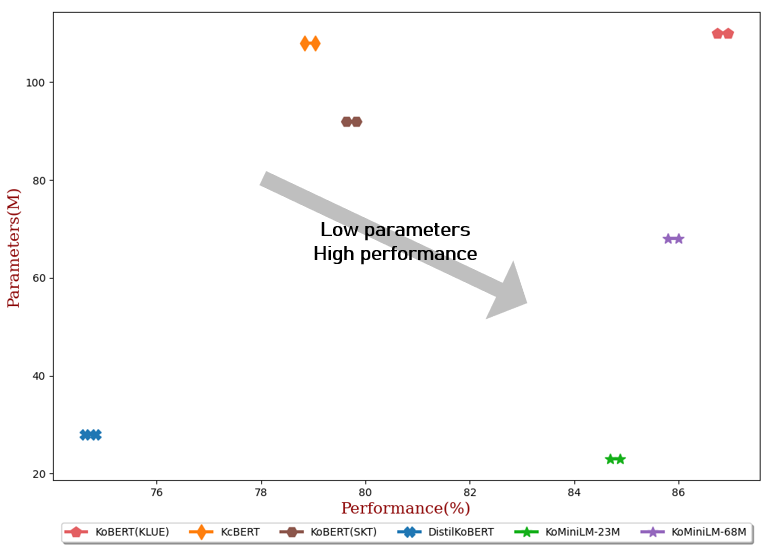
Performance on subtasks
- The results of our fine-tuning experiments are an average of 3 runs for each task.
cd KoMiniLM-Finetune
bash scripts/run_all_kominilm.sh
| #Param | Average | NSMC (Acc) |
Naver NER (F1) |
PAWS (Acc) |
KorNLI (Acc) |
KorSTS (Spearman) |
Question Pair (Acc) |
KorQuaD (Dev) (EM/F1) |
|
|---|---|---|---|---|---|---|---|---|---|
| KoBERT(KLUE) | 110M | 86.84 | 90.20±0.07 | 87.11±0.05 | 81.36±0.21 | 81.06±0.33 | 82.47±0.14 | 95.03±0.44 | 84.43±0.18 / 93.05±0.04 |
| KcBERT | 108M | 78.94 | 89.60±0.10 | 84.34±0.13 | 67.02±0.42 | 74.17±0.52 | 76.57±0.51 | 93.97±0.27 | 60.87±0.27 / 85.01±0.14 |
| KoBERT(SKT) | 92M | 79.73 | 89.28±0.42 | 87.54±0.04 | 80.93±0.91 | 78.18±0.45 | 75.98±2.81 | 94.37±0.31 | 51.94±0.60 / 79.69±0.66 |
| DistilKoBERT | 28M | 74.73 | 88.39±0.08 | 84.22±0.01 | 61.74±0.45 | 70.22±0.14 | 72.11±0.27 | 92.65±0.16 | 52.52±0.48 / 76.00±0.71 |
| KoMiniLM† | 68M | 85.90 | 89.84±0.02 | 85.98±0.09 | 80.78±0.30 | 79.28±0.17 | 81.00±0.07 | 94.89±0.37 | 83.27±0.08 / 92.08±0.06 |
| KoMiniLM† | 23M | 84.79 | 89.67±0.03 | 84.79±0.09 | 78.67±0.45 | 78.10±0.07 | 78.90±0.11 | 94.81±0.12 | 82.11±0.42 / 91.21±0.29 |
- NSMC (Naver Sentiment Movie Corpus)
- Naver NER (NER task on Naver NLP Challenge 2018)
- PAWS (Korean Paraphrase Adversaries from Word Scrambling)
- KorNLI/KorSTS (Korean Natural Language Understanding)
- Question Pair (Paired Question)
- KorQuAD (The Korean Question Answering Dataset)
User Contributed Examples
-
Reference
- Downloads last month
- 194
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support