
[CVPR 25] RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete.
🤗 Models
Base Planning Model: The model was trained on general datasets in Stages 1–2 and on the Robotic Planning dataset in Stage 3, which is designed for Planning prediction.A-LoRA for Affordance: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Affordance dataset to predict affordance.T-LoRA for Trajectory: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Trajectory dataset to predict trajectory.
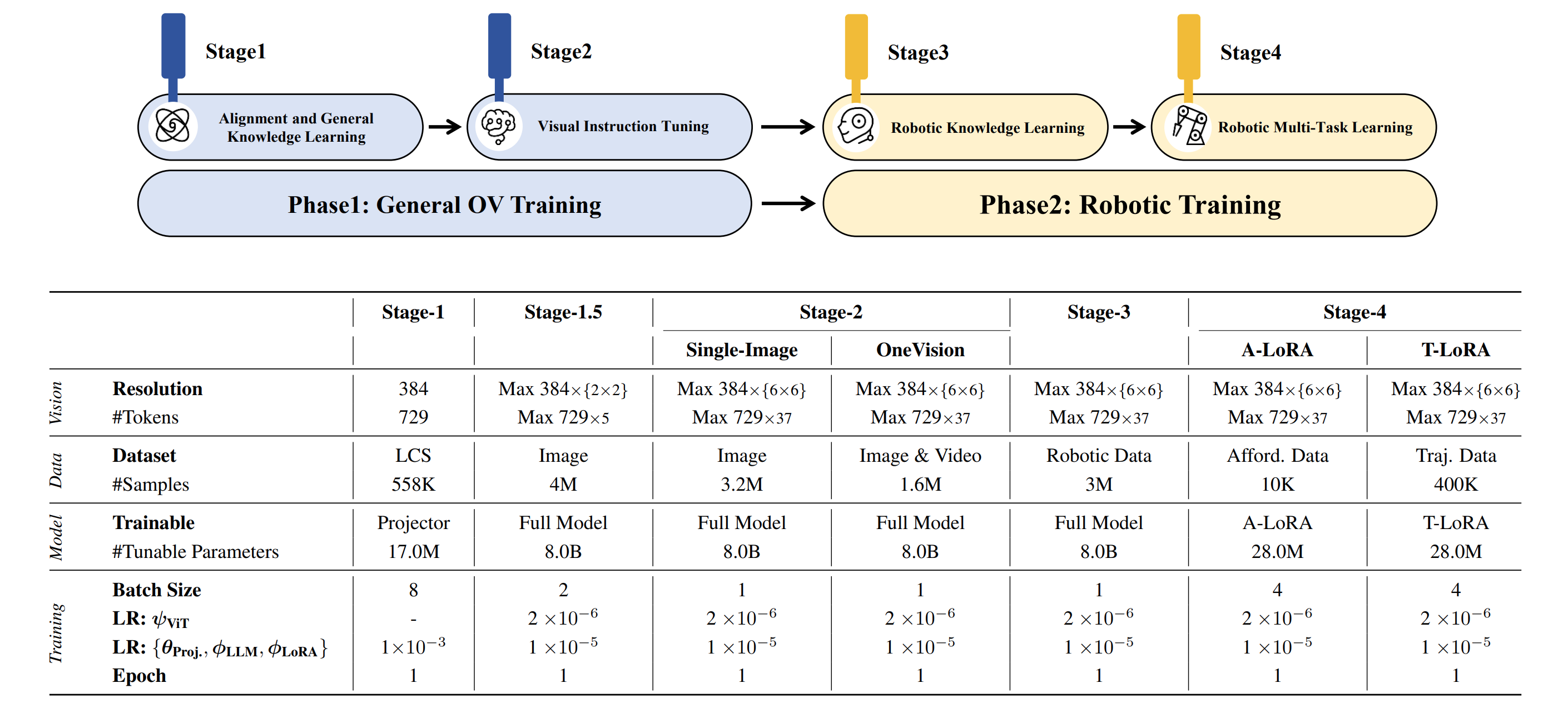
| Models | Checkpoint | Description |
|---|---|---|
| Planning Model | 🤗 Planning CKPTs | Used for Planning prediction in our paper |
| Affordance (A-LoRA) | 🤗 Affordance CKPTs | Used for Affordance prediction in our paper |
| Trajectory (T-LoRA) | 🤗 Trajectory CKPTs | Used for Trajectory prediction in our paper |
🛠️ Setup
# clone repo.
git clone https://github.com/FlagOpen/RoboBrain.git
cd RoboBrain
# build conda env.
conda create -n robobrain python=3.10
conda activate robobrain
pip install -r requirements.txt
🤖 Training
1. Data Preparation
# Modify datasets for Stage 4_traj, please refer to:
- yaml_path: scripts/train/yaml/stage_4_trajectory.yaml
Note: During training, we applied normalization to the path points, representing them as waypoints and retaining three decimal places for each. The sample format in each JSON file should be like this, representing the future waypoints of the end-effector:
{
"id": 0,
"image": [
"shareRobot/trajectory/images/rtx_frames_success_0/10_utokyo_pr2_tabletop_manipulation_converted_externally_to_rlds#episode_2/frame_0.png"
],
"conversations": [
{
"from": "human",
"value": "<image>\nYou are a robot using the joint control. The task is \"reach for the cloth\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
},
{
"from": "gpt",
"value": "[[0.781, 0.305], [0.688, 0.344], [0.570, 0.344], [0.492, 0.312]]"
}
]
},
2. Training
# Training on Stage 4_traj:
bash scripts/train/stage_4_0_resume_finetune_lora_t.sh
Note: Please change the environment variables (e.g. DATA_PATH, IMAGE_FOLDER, PREV_STAGE_CHECKPOINT) in the script to your own.
3. Convert original weights to HF weights
# Planning Model
python model/llava_utils/convert_robobrain_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
# A-LoRA & T-RoRA
python model/llava_utils/convert_lora_weights_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
⭐️ Inference
Usage for Trajectory Prediction
# please refer to https://github.com/FlagOpen/RoboBrain
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
model = SimpleInference(model_id, lora_id)
# Example 1:
prompt = "You are a robot using the joint control. The task is \"reach for the cloth\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_1.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.781, 0.305], [0.688, 0.344], [0.570, 0.344], [0.492, 0.312]]
'''
# Example 2:
prompt = "You are a robot using the joint control. The task is \"reach for the grapes\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_2.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.898, 0.352], [0.766, 0.344], [0.625, 0.273], [0.500, 0.195]]
'''
🤖 Evaluation
Coming Soon ...
😊 Acknowledgement
We would like to express our sincere gratitude to the developers and contributors of the following projects:
- LLaVA-NeXT: The comprehensive codebase for training Vision-Language Models (VLMs).
- Open-X-Emboddied: A powerful evaluation tool for Vision-Language Models (VLMs).
- RoboPoint: An point dataset that provides instructions and corresponding points.
Their outstanding contributions have played a pivotal role in advancing our research and development initiatives.
📑 Citation
If you find this project useful, welcome to cite us.
@article{ji2025robobrain,
title={RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete},
author={Ji, Yuheng and Tan, Huajie and Shi, Jiayu and Hao, Xiaoshuai and Zhang, Yuan and Zhang, Hengyuan and Wang, Pengwei and Zhao, Mengdi and Mu, Yao and An, Pengju and others},
journal={arXiv preprint arXiv:2502.21257},
year={2025}
}
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.