
BK-BERT
Event Knowledge-Based BERT (EBK-BERT) leverages knowledge extracted from events-related sentences to mask words that are significant to the events detection task. This approach aims to produce a language model that enhances the performance of the down-stream event detection task, which is later trained during the fine-tuning process.
Model description
The BERT-base configuration is adopted which has 12 encoder blocks, 768 hidden dimensions, 12 attention heads, 512 maximum sequence length, and a total of 110M parameters.
Pre-training Data
The pre-training data consists of news articles from the 1.5 billion words corpus by (El-Khair, 2016). Due to computation limitations, we only use articles from Alittihad, Riyadh, Almasrya- lyoum, and Alqabas, which amount to 10GB of text and about 8M sentences after splitting the articles to approximately 100 word sentences to accommodate the 128 max_sentence length used when training the model. The average number of tokens per sentence is 105.
Pretraining
As previous studies have shown, contextual representation models that are pre-trained using top Personnel Transaction Contact Nature Movement Life Justice Conflict business the MLM training task benefit from masking the most significant words, using whole word masking. To select the most significant words we use odds-ratio. Only words with greater than 2 odds-ratio are considered in the masking, which means the words included are at least twice as likely to appear in one event type than the other.
Google Cloud GPU is used for pre-training the model. The selected hyperparameters are: learning rate=1e − 4, batch size =16, maxi- mum sequence length = 128 and average se- quence length = 104. In total, we pre-trained our models for 500, 000 steps, completing 1 epoch. Pre-training a single model took approximately 2.25 days.
Fine-tuning data
Tweets are collected from well-known Arabic news accounts, which are: Al-Arabiya, Sabq, CNN Arabic, and BBC Arabic. These accounts belong to television channels and online newspapers, where they use Twitter to broadcast news related to real-world events. The first collection process tracks tweets from the news accounts for 20 days period, between November 2, 2021, and November 22, 2021 and we call this dataset AraEvent(November).
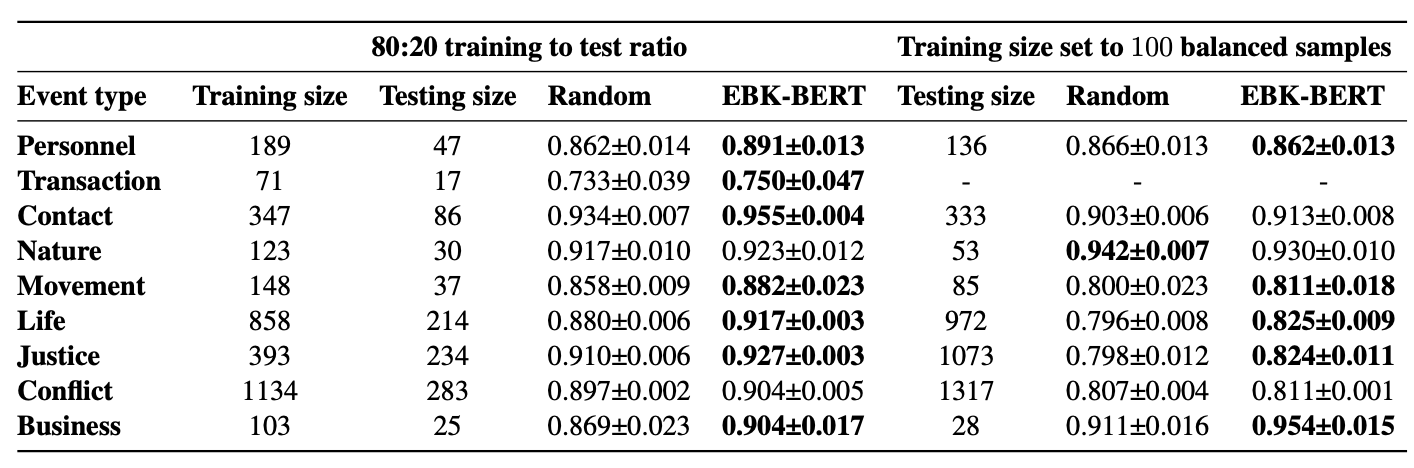
Evaluation results
When fine-tuned on down-stream event detection task, this model achieves the following results:
Gradio Demo
will be released soon