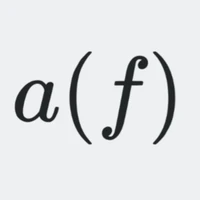
OFA-huge-caption
This is the huge version of OFA pretrained model finetuned on COCO captioning task, forked & converted from the original fairseq version and compressed into float16.
The conversion script is custom, but the procedure described Issue #171 should also apply (quantization is not performed, but that's trivial).
You will need a OFA modified version of transformers to use this model. No idea why it is still not in master. Tips: You can just copy-paste the transformers folder into your project and rename it, then monkey-patch the transformers module to point to your local copy to avoid having to install it.
Original README below
Introduction
This is the huge version of OFA pretrained model. OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework.
The directory includes 4 files, namely config.json which consists of model configuration, vocab.json and merge.txt for our OFA tokenizer, and lastly pytorch_model.bin which consists of model weights. There is no need to worry about the mismatch between Fairseq and transformers, since we have addressed the issue yet.
How to use
To use it in transformers, please refer to https://github.com/OFA-Sys/OFA/tree/feature/add_transformers. Install the transformers and download the models as shown below.
git clone --single-branch --branch feature/add_transformers https://github.com/OFA-Sys/OFA.git
pip install OFA/transformers/
git clone https://huggingface.co/OFA-Sys/OFA-huge
After, refer the path to OFA-huge to ckpt_dir, and prepare an image for the testing example below. Also, ensure that you have pillow and torchvision in your environment.
>>> from PIL import Image
>>> from torchvision import transforms
>>> from transformers import OFATokenizer, OFAModel
>>> from generate import sequence_generator
>>> mean, std = [0.5, 0.5, 0.5], [0.5, 0.5, 0.5]
>>> resolution = 480
>>> patch_resize_transform = transforms.Compose([
lambda image: image.convert("RGB"),
transforms.Resize((resolution, resolution), interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
>>> tokenizer = OFATokenizer.from_pretrained(ckpt_dir)
>>> txt = " what does the image describe?"
>>> inputs = tokenizer([txt], return_tensors="pt").input_ids
>>> img = Image.open(path_to_image)
>>> patch_img = patch_resize_transform(img).unsqueeze(0)
# using the generator of fairseq version
>>> model = OFAModel.from_pretrained(ckpt_dir, use_cache=True)
>>> generator = sequence_generator.SequenceGenerator(
tokenizer=tokenizer,
beam_size=5,
max_len_b=16,
min_len=0,
no_repeat_ngram_size=3,
)
>>> data = {}
>>> data["net_input"] = {"input_ids": inputs, 'patch_images': patch_img, 'patch_masks':torch.tensor([True])}
>>> gen_output = generator.generate([model], data)
>>> gen = [gen_output[i][0]["tokens"] for i in range(len(gen_output))]
# using the generator of huggingface version
>>> model = OFAModel.from_pretrained(ckpt_dir, use_cache=False)
>>> gen = model.generate(inputs, patch_images=patch_img, num_beams=5, no_repeat_ngram_size=3)
>>> print(tokenizer.batch_decode(gen, skip_special_tokens=True))
- Downloads last month
- 13