
Math-aware BERT
This repository contains our pre-trained BERT-based model. It was initialised from BERT-base-cased and further pre-trained on Math StackExchange in three different stages. We also added more LaTeX tokens to the tokenizer to enable a better tokenization of mathematical formulas. This model is not yet fine-tuned on a specific task.
Training Details
The model was instantiated from BERT-base-cased weights and further pre-trained in three stages using different data for the sentence order prediction. During all three stages, the mask language modelling task was trained simultaneously. In addition, we added around 500 LaTeX tokens to the tokenizer to better cope with mathematical formulas.
The image illustrates the three pre-training stages: First, we train on mathematical formulas only. The NSP classifier predicts which segment contains the left hand side of the formula and which one contains the right hand side. This way we model inter-formula-coherence. The second stages models formula-sentence-coherence, i.e., whether the formula comes first in the original document or whether the natural language part comes first. Finally, we add the inter-sentence-coherence stage that is default for ALBERT/BERT. In this stage, sentences were split by a sentence separator. Note, that in all three stages we do not use sentences from different documents as the NSP task for BERT would usually do, but instead we are only switching two consecutive sequences (formulas, sentences, ...). This would be the default behaviour of ALBERT's SOP task.
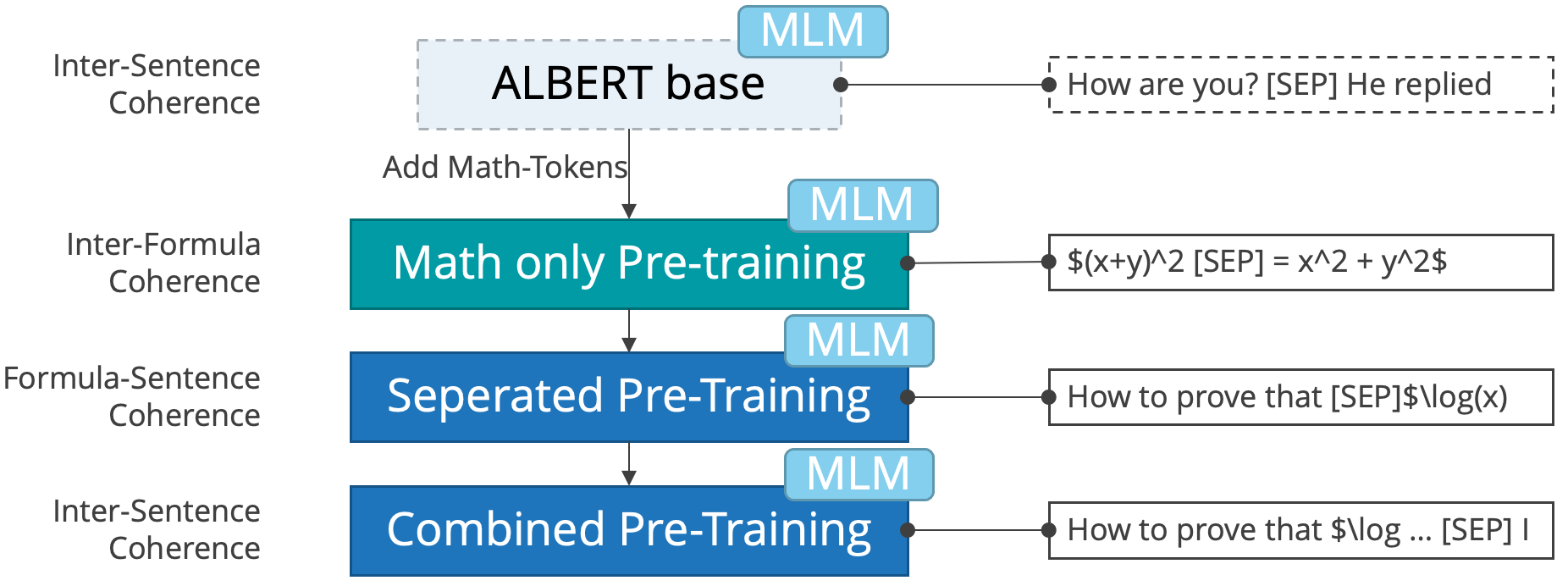
It is trained in exactly the same way as our ALBERT model which was our best-performing model in ARQMath 3 (2022). Details about our ALBERT Model can be found here.
Usage
You can use this model to further fine-tune it on any math-aware task you have in mind, e.g., classification, question-answering, etc. . Please note, that the model in this repository is only pre-trained and not fine-tuned.
Citation
If you find this model useful, consider citing our paper for the way the pre-training was performed:
@article{reusch2022transformer,
title={Transformer-Encoder and Decoder Models for Questions on Math},
author={Reusch, Anja and Thiele, Maik and Lehner, Wolfgang},
year={2022},
organization={CLEF}
}
- Downloads last month
- 33