
SPHINX Family
Collection
2 items
•
Updated
•
1
Official implementation of 'SPHINX: A Mixer of Tasks, Domains, and Embeddings Advances Multi-modal Large Language Models'.
Try out our web demo 🚀 here!
Github link: Github • 👋 join our WeChat
We present SPHINX, a versatile multi-modal large language model (MLLM) with a mixer of training tasks, data domains, and visual embeddings.
Task Mix. For all-purpose capabilities, we mix a variety of vision-language tasks for mutual improvement: VQA, REC, REG, OCR, DET, POSE, REL DET, T2I, etc.
Embedding Mix. We capture robust visual representations by fusing distinct visual architectures, pre-training, and granularity.
Domain Mix. For data from real-world and synthetic domains, we mix the weights of two domain-specific models for complementarity.
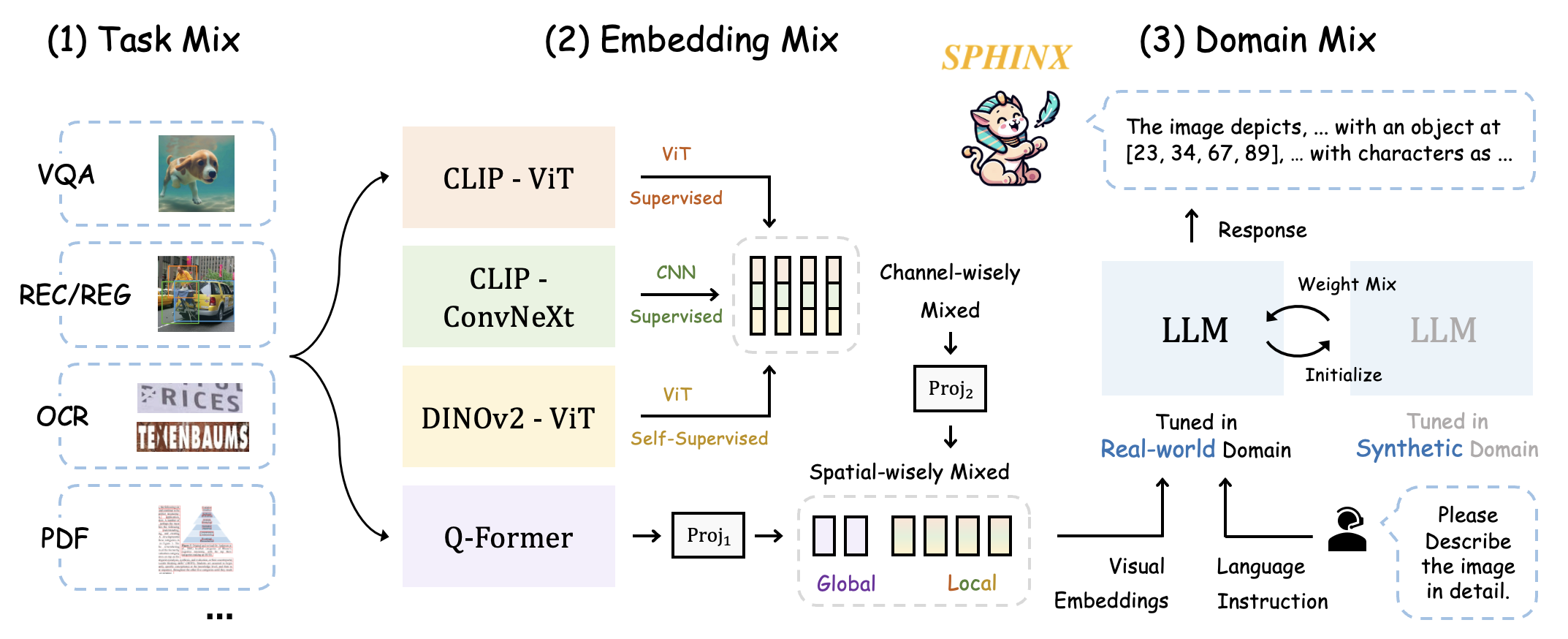
On top of SPHINX, we propose to further mix visual scales and sub-images for better capture fine-grained semantics on high-resolution images.

SPHINX is built upon LLaMA2-Accessory, please follow the instructions here for environment setup.
This section provides a step-by-step guide for hosting a local SPHINX demo. If you're already familiar with the LLAMA2-Accessory toolkit, note that hosting a SPHINX demo follows the same pipeline as hosting demos for the other models supported by LLAMA2-Accessory.
We provide the beta-version checkpoints on HuggingFace🤗. Please download them to your own machine. The file structure should appear as follows:
ckpt_path/
├── consolidated.00-of-02.model.pth
└── consolidated.01-of-02.model.pth
Please follow the instructions here to see the instruction and complete the use of the model.
We provide a comprehensive evaluation of SPHINX and showcase results across multiple benchmarks.
Our evaluation encompasses both quantitative metrics and qualitative assessments, providing a holistic understanding of our VLM model's performance.
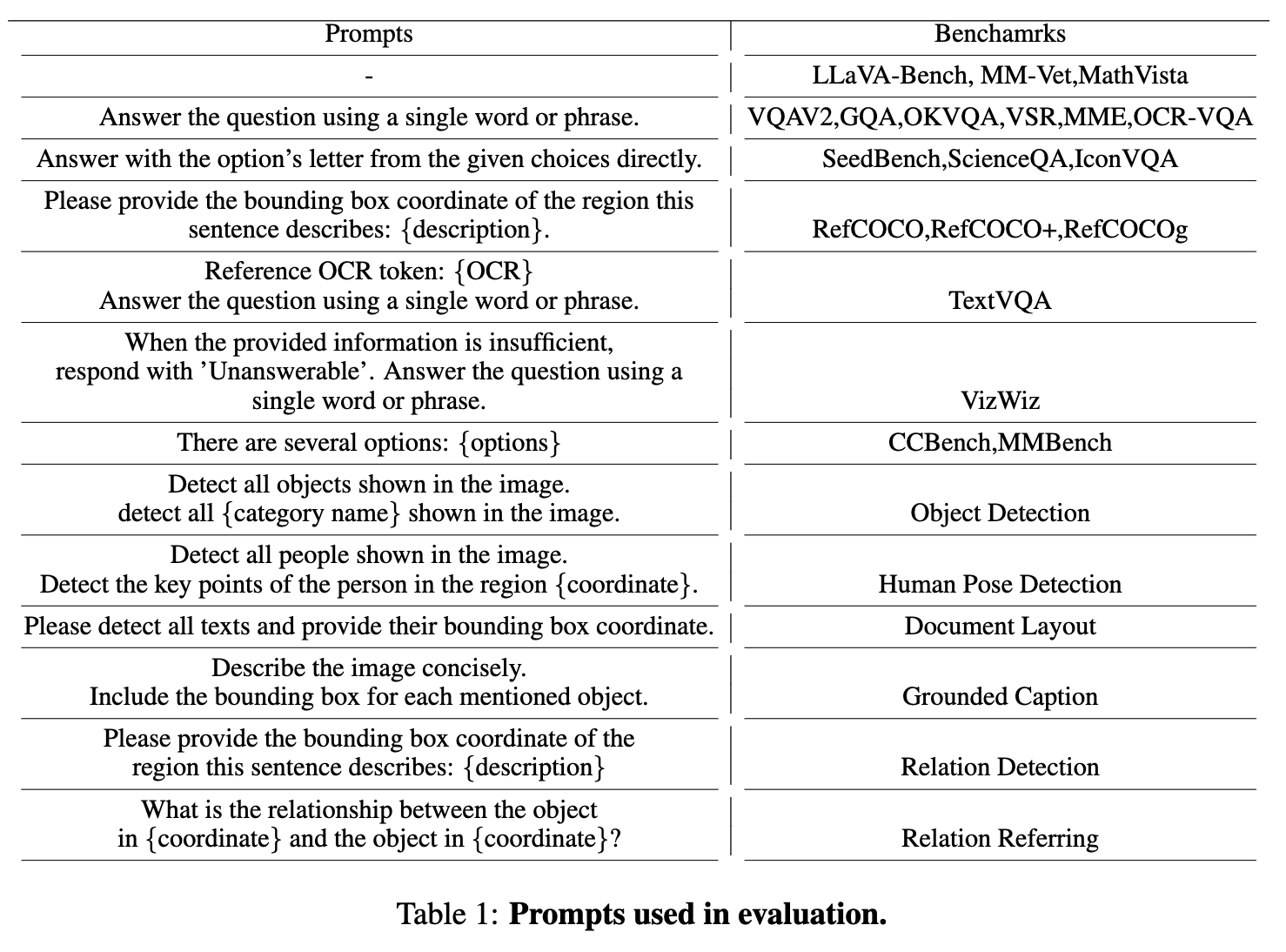
Evaluation Prompt Design
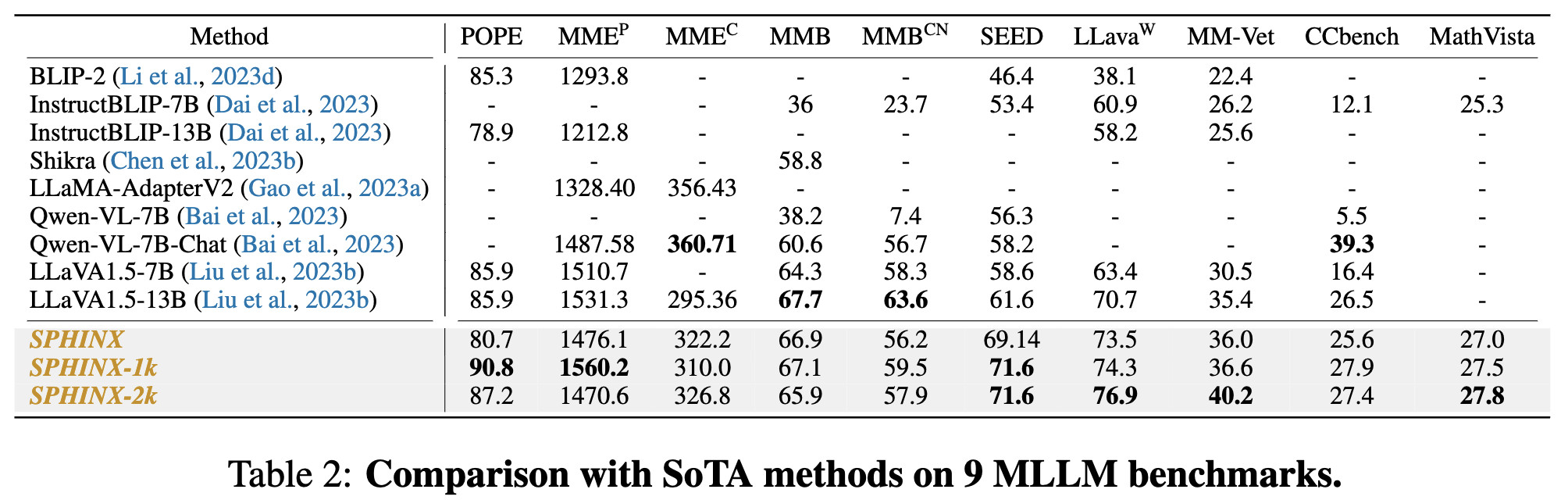
Benchmarks on Multimodal Large Language Models
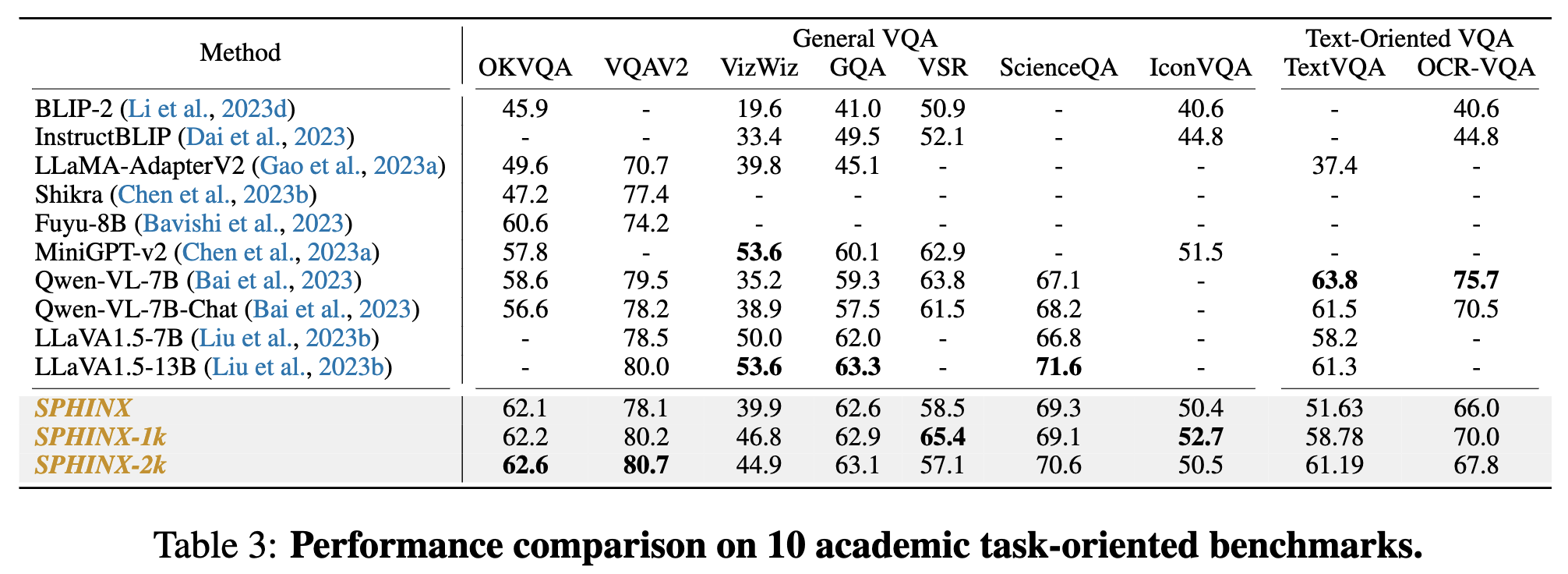
Visual Question Answering
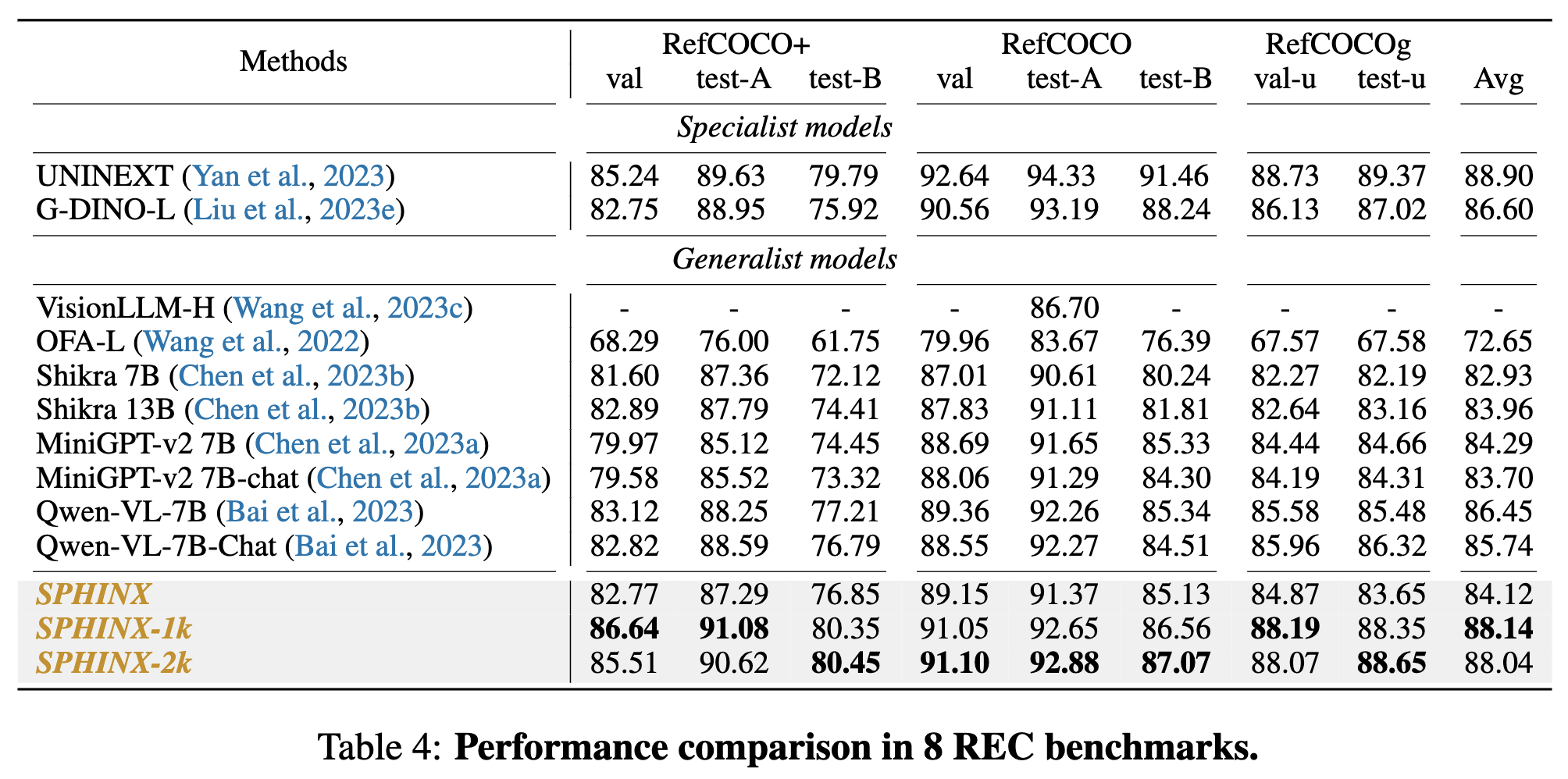
Visual Grounding
❓ Encountering issues or have further questions? Find answers to common inquiries here. We're here to assist you!
Llama 2 is licensed under the LLAMA 2 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved.