
File size: 19,579 Bytes
1e6d67a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 |
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<h1 align="center"> <p>🤗 PEFT</p></h1>
<h3 align="center">
<p>State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods</p>
</h3>
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model's parameters. Fine-tuning large-scale PLMs is often prohibitively costly. In this regard, PEFT methods only fine-tune a small number of (extra) model parameters, thereby greatly decreasing the computational and storage costs. Recent State-of-the-Art PEFT techniques achieve performance comparable to that of full fine-tuning.
Seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
Supported methods:
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/abs/2106.09685)
2. Prefix Tuning: [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://aclanthology.org/2021.acl-long.353/), [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. P-Tuning: [GPT Understands, Too](https://arxiv.org/abs/2103.10385)
4. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/abs/2104.08691)
5. AdaLoRA: [Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning](https://arxiv.org/abs/2303.10512)
## Getting started
```python
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
```
## Use Cases
### Get comparable performance to full finetuning by adapting LLMs to downstream tasks using consumer hardware
GPU memory required for adapting LLMs on the few-shot dataset [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints). Here, settings considered
are full finetuning, PEFT-LoRA using plain PyTorch and PEFT-LoRA using DeepSpeed with CPU Offloading.
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
| Model | Full Finetuning | PEFT-LoRA PyTorch | PEFT-LoRA DeepSpeed with CPU Offloading |
| --------- | ---- | ---- | ---- |
| bigscience/T0_3B (3B params) | 47.14GB GPU / 2.96GB CPU | 14.4GB GPU / 2.96GB CPU | 9.8GB GPU / 17.8GB CPU |
| bigscience/mt0-xxl (12B params) | OOM GPU | 56GB GPU / 3GB CPU | 22GB GPU / 52GB CPU |
| bigscience/bloomz-7b1 (7B params) | OOM GPU | 32GB GPU / 3.8GB CPU | 18.1GB GPU / 35GB CPU |
Performance of PEFT-LoRA tuned [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) on [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints) leaderboard.
A point to note is that we didn't try to squeeze performance by playing around with input instruction templates, LoRA hyperparams and other training related hyperparams. Also, we didn't use the larger 13B [mt0-xxl](https://huggingface.co/bigscience/mt0-xxl) model.
So, we are already seeing comparable performance to SoTA with parameter efficient tuning. Also, the final checkpoint size is just `19MB` in comparison to `11GB` size of the backbone [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) model.
| Submission Name | Accuracy |
| --------- | ---- |
| Human baseline (crowdsourced) | 0.897 |
| Flan-T5 | 0.892 |
| lora-t0-3b | 0.863 |
**Therefore, we can see that performance comparable to SoTA is achievable by PEFT methods with consumer hardware such as 16GB and 24GB GPUs.**
A insightful blogpost explaining the advantages of using PEFT for fine-tuning FlanT5-XXL: [https://www.philschmid.de/fine-tune-flan-t5-peft](https://www.philschmid.de/fine-tune-flan-t5-peft)
### Parameter Efficient Tuning of Diffusion Models
GPU memory required by different settings during training is given below. The final checkpoint size is `8.8 MB`.
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
| Model | Full Finetuning | PEFT-LoRA | PEFT-LoRA with Gradient Checkpointing |
| --------- | ---- | ---- | ---- |
| CompVis/stable-diffusion-v1-4 | 27.5GB GPU / 3.97GB CPU | 15.5GB GPU / 3.84GB CPU | 8.12GB GPU / 3.77GB CPU |
**Training**
An example of using LoRA for parameter efficient dreambooth training is given in `~examples/lora_dreambooth/train_dreambooth.py`
```bash
export MODEL_NAME= "CompVis/stable-diffusion-v1-4" #"stabilityai/stable-diffusion-2-1"
export INSTANCE_DIR="path-to-instance-images"
export CLASS_DIR="path-to-class-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--class_data_dir=$CLASS_DIR \
--output_dir=$OUTPUT_DIR \
--train_text_encoder \
--with_prior_preservation --prior_loss_weight=1.0 \
--instance_prompt="a photo of sks dog" \
--class_prompt="a photo of dog" \
--resolution=512 \
--train_batch_size=1 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=200 \
--use_lora \
--lora_r 16 \
--lora_alpha 27 \
--lora_text_encoder_r 16 \
--lora_text_encoder_alpha 17 \
--learning_rate=1e-4 \
--gradient_accumulation_steps=1 \
--gradient_checkpointing \
--max_train_steps=800
```
Try out the 🤗 Gradio Space which should run seamlessly on a T4 instance:
[smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth).
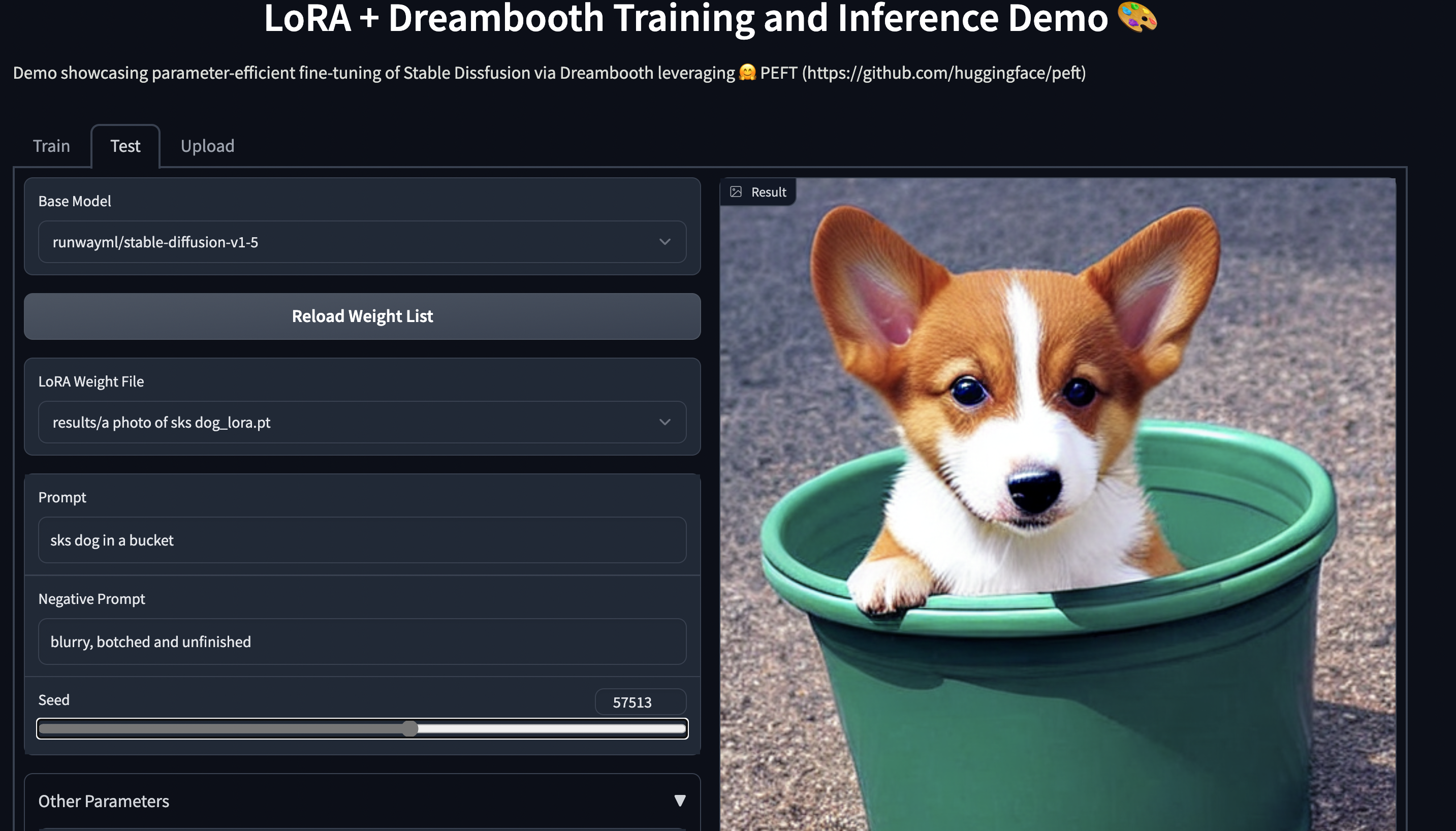
**NEW** ✨ Multi Adapter support and combining multiple LoRA adapters in a weighted combination

### Parameter Efficient Tuning of LLMs for RLHF components such as Ranker and Policy
- Here is an example in [trl](https://github.com/lvwerra/trl) library using PEFT+INT8 for tuning policy model: [gpt2-sentiment_peft.py](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt2-sentiment_peft.py) and corresponding [Blog](https://huggingface.co/blog/trl-peft)
- Example using PEFT for Instrction finetuning, reward model and policy : [stack_llama](https://github.com/lvwerra/trl/tree/main/examples/stack_llama/scripts) and corresponding [Blog](https://huggingface.co/blog/stackllama)
### INT8 training of large models in Colab using PEFT LoRA and bits_and_bytes
- Here is now a demo on how to fine tune [OPT-6.7b](https://huggingface.co/facebook/opt-6.7b) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
- Here is now a demo on how to fine tune [whishper-large](openai/whisper-large-v2) (1.5B params) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1DOkD_5OUjFa0r5Ik3SgywJLJtEo2qLxO?usp=sharing) and [](https://colab.research.google.com/drive/1vhF8yueFqha3Y3CpTHN6q9EVcII9EYzs?usp=sharing)
### Save compute and storage even for medium and small models
Save storage by avoiding full finetuning of models on each of the downstream tasks/datasets,
With PEFT methods, users only need to store tiny checkpoints in the order of `MBs` all the while retaining
performance comparable to full finetuning.
An example of using LoRA for the task of adapting `LayoutLMForTokenClassification` on `FUNSD` dataset is given in `~examples/token_classification/PEFT_LoRA_LayoutLMForTokenClassification_on_FUNSD.py`. We can observe that with only `0.62 %` of parameters being trainable, we achieve performance (F1 0.777) comparable to full finetuning (F1 0.786) (without any hyerparam tuning runs for extracting more performance), and the checkpoint of this is only `2.8MB`. Now, if there are `N` such datasets, just have these PEFT models one for each dataset and save a lot of storage without having to worry about the problem of catastrophic forgetting or overfitting of backbone/base model.
Another example is fine-tuning [`roberta-large`](https://huggingface.co/roberta-large) on [`MRPC` GLUE](https://huggingface.co/datasets/glue/viewer/mrpc) dataset using different PEFT methods. The notebooks are given in `~examples/sequence_classification`.
## PEFT + 🤗 Accelerate
PEFT models work with 🤗 Accelerate out of the box. Use 🤗 Accelerate for Distributed training on various hardware such as GPUs, Apple Silicon devices, etc during training.
Use 🤗 Accelerate for inferencing on consumer hardware with small resources.
### Example of PEFT model training using 🤗 Accelerate's DeepSpeed integration
DeepSpeed version required `v0.8.0`. An example is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py`.
a. First, run `accelerate config --config_file ds_zero3_cpu.yaml` and answer the questionnaire.
Below are the contents of the config file.
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config: {}
machine_rank: 0
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
use_cpu: false
```
b. run the below command to launch the example script
```bash
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
```
c. output logs:
```bash
GPU Memory before entering the train : 1916
GPU Memory consumed at the end of the train (end-begin): 66
GPU Peak Memory consumed during the train (max-begin): 7488
GPU Total Peak Memory consumed during the train (max): 9404
CPU Memory before entering the train : 19411
CPU Memory consumed at the end of the train (end-begin): 0
CPU Peak Memory consumed during the train (max-begin): 0
CPU Total Peak Memory consumed during the train (max): 19411
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
GPU Memory before entering the eval : 1982
GPU Memory consumed at the end of the eval (end-begin): -66
GPU Peak Memory consumed during the eval (max-begin): 672
GPU Total Peak Memory consumed during the eval (max): 2654
CPU Memory before entering the eval : 19411
CPU Memory consumed at the end of the eval (end-begin): 0
CPU Peak Memory consumed during the eval (max-begin): 0
CPU Total Peak Memory consumed during the eval (max): 19411
accuracy=100.0
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
```
### Example of PEFT model inference using 🤗 Accelerate's Big Model Inferencing capabilities
An example is provided in `~examples/causal_language_modeling/peft_lora_clm_accelerate_big_model_inference.ipynb`.
## Models support matrix
### Causal Language Modeling
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
|--------------| ---- | ---- | ---- | ---- |
| GPT-2 | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ✅ |
| OPT | ✅ | ✅ | ✅ | ✅ |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ |
| GPT-J | ✅ | ✅ | ✅ | ✅ |
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ |
| LLaMA | ✅ | ✅ | ✅ | ✅ |
| ChatGLM | ✅ | ✅ | ✅ | ✅ |
### Conditional Generation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
| --------- | ---- | ---- | ---- | ---- |
| T5 | ✅ | ✅ | ✅ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ |
### Sequence Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
| --------- | ---- | ---- | ---- | ---- |
| BERT | ✅ | ✅ | ✅ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ |
| GPT-2 | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ✅ |
| OPT | ✅ | ✅ | ✅ | ✅ |
| GPT-Neo | ✅ | ✅ | ✅ | ✅ |
| GPT-J | ✅ | ✅ | ✅ | ✅ |
| Deberta | ✅ | | ✅ | ✅ |
| Deberta-v2 | ✅ | | ✅ | ✅ |
### Token Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
| --------- | ---- | ---- | ---- | ---- |
| BERT | ✅ | ✅ | | |
| RoBERTa | ✅ | ✅ | | |
| GPT-2 | ✅ | ✅ | | |
| Bloom | ✅ | ✅ | | |
| OPT | ✅ | ✅ | | |
| GPT-Neo | ✅ | ✅ | | |
| GPT-J | ✅ | ✅ | | |
| Deberta | ✅ | | | |
| Deberta-v2 | ✅ | | | |
### Text-to-Image Generation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
| --------- | ---- | ---- | ---- | ---- |
| Stable Diffusion | ✅ | | | |
### Image Classification
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
| --------- | ---- | ---- | ---- | ---- |
| ViT | ✅ | | | |
| Swin | ✅ | | | |
### Image to text (Multi-modal models)
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
| --------- | ---- | ---- | ---- | ---- |
| Blip-2 | ✅ | | | |
___Note that we have tested LoRA for [ViT](https://huggingface.co/docs/transformers/model_doc/vit) and [Swin](https://huggingface.co/docs/transformers/model_doc/swin) for fine-tuning on image classification. However, it should be possible to use LoRA for any compatible model [provided](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&search=vit) by 🤗 Transformers. Check out the respective
examples to learn more. If you run into problems, please open an issue.___
The same principle applies to our [segmentation models](https://huggingface.co/models?pipeline_tag=image-segmentation&sort=downloads) as well.
### Semantic Segmentation
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
| --------- | ---- | ---- | ---- | ---- |
| SegFormer | ✅ | | | |
## Caveats:
1. Below is an example of using PyTorch FSDP for training. However, it doesn't lead to
any GPU memory savings. Please refer issue [[FSDP] FSDP with CPU offload consumes 1.65X more GPU memory when training models with most of the params frozen](https://github.com/pytorch/pytorch/issues/91165).
```python
from peft.utils.other import fsdp_auto_wrap_policy
...
if os.environ.get("ACCELERATE_USE_FSDP", None) is not None:
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
model = accelerator.prepare(model)
```
Example of parameter efficient tuning with [`mt0-xxl`](https://huggingface.co/bigscience/mt0-xxl) base model using 🤗 Accelerate is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py`.
a. First, run `accelerate config --config_file fsdp_config.yaml` and answer the questionnaire.
Below are the contents of the config file.
```yaml
command_file: null
commands: null
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
downcast_bf16: 'no'
dynamo_backend: 'NO'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_transformer_layer_cls_to_wrap: T5Block
gpu_ids: null
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_name: null
tpu_zone: null
use_cpu: false
```
b. run the below command to launch the example script
```bash
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
```
2. When using `P_TUNING` or `PROMPT_TUNING` with `SEQ_2_SEQ` task, remember to remove the `num_virtual_token` virtual prompt predictions from the left side of the model outputs during evaluations.
3. For encoder-decoder models, `P_TUNING` or `PROMPT_TUNING` doesn't support `generate` functionality of transformers because `generate` strictly requires `decoder_input_ids` but
`P_TUNING`/`PROMPT_TUNING` appends soft prompt embeddings to `input_embeds` to create
new `input_embeds` to be given to the model. Therefore, `generate` doesn't support this yet.
4. When using ZeRO3 with zero3_init_flag=True, if you find the gpu memory increase with training steps. we might need to set zero3_init_flag=false in accelerate config.yaml. The related issue is [[BUG] memory leak under zero.Init](https://github.com/microsoft/DeepSpeed/issues/2637)
## Backlog:
- [x] Add tests
- [x] Multi Adapter training and inference support
- [x] Add more use cases and examples
- [ ] Explore and possibly integrate `Bottleneck Adapters`, `(IA)^3`, `AdaptionPrompt` ...
## Citing 🤗 PEFT
If you use 🤗 PEFT in your publication, please cite it by using the following BibTeX entry.
```bibtex
@Misc{peft,
title = {PEFT: State-of-the-art Parameter-Efficient Fine-Tuning methods},
author = {Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul},
howpublished = {\url{https://github.com/huggingface/peft}},
year = {2022}
}
```
|