Spaces:
Running

title: Grpo Sql Optimizer
emoji: 🧠
colorFrom: pink
colorTo: red
sdk: static
pinned: false
GRPO Training for SQL Query Optimization (DuckDB-Verifiable Rewards)
Fine-tuned Qwen/Qwen2.5-0.5B-Instruct using GRPO (Group Relative Policy Optimization) to optimize SQL queries with verifiable rewards: we execute the original + rewritten SQL against a real DuckDB database and score based on measured speedup and correctness.
- Repo (source of truth): https://github.com/OfficialAbhinavSingh/SQL-Query-Optimization-Environment-
- Model: https://huggingface.co/laterabhi/grpo-sql-optimizer
- Space: https://huggingface.co/spaces/laterabhi/grpo-sql-optimizer
Why this matters
LLMs often generate SQL that is syntactically valid but slow (or subtly wrong) at scale. Classic training setups use heuristic scoring, which can be gamed. This project trains/evaluates SQL optimization with execution-grounded feedback.
Environment (5 tasks, increasing difficulty)
We use the SQL Query Optimization Environment (OpenEnv compliant), backed by an in-memory DuckDB dataset:
users(10k),orders(500k),events(1M),products(1k)
Tasks:
task_1_basic_antipatterns(easy)task_2_correlated_subqueries(medium)task_3_wildcard_scan(medium-hard)task_4_implicit_join(hard)task_5_window_functions(expert)
Reward function (execution-grounded)
Composite reward in [0, 1], combining:
- execution_speedup (35%): measured ratio
original_ms / optimized_msfrom DuckDB - result_correctness (20%): results match check (order-independent for large outputs)
- issue_detection (25%): anti-pattern detection vs ground-truth keywords per task
- approval_correctness (8%)
- summary_quality (7%)
- severity_labels (5%)
This is designed to be hard to game: “fast but wrong” loses correctness; “verbose but slow” loses speedup.
Training setup (GRPO)
- Algorithm: GRPO (group-relative policy optimization)
- Base model:
Qwen/Qwen2.5-0.5B-Instruct - Group size: 4 completions per prompt
- Notebook: Kaggle (linked in the repo README)
Results (from the GitHub repo)
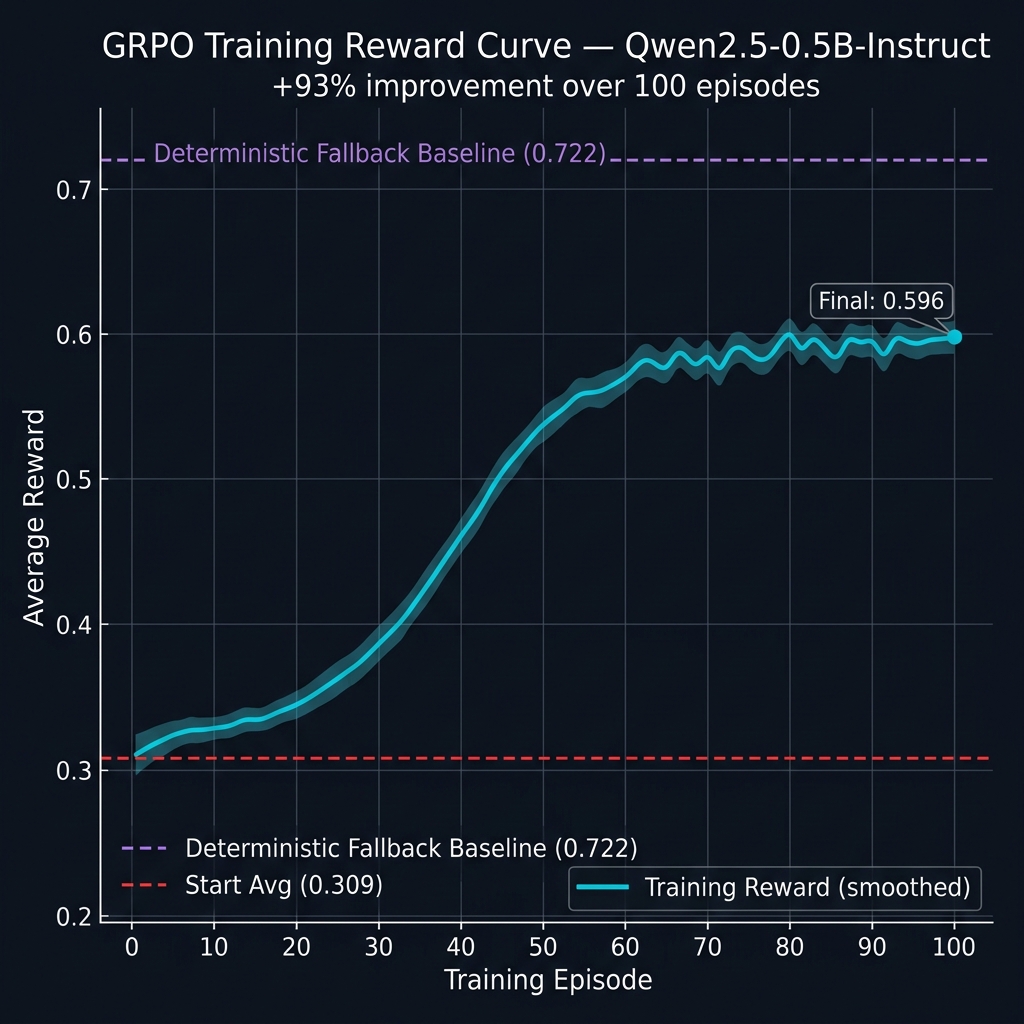
Training progress (100 episodes)
| Metric | Value |
|---|---|
| Start avg (ep 1–10) | 0.3090 |
| End avg (ep 91–100) | 0.5962 |
| Improvement | +93% |
Reward curve:
Final evaluation (per task)
| Task | Difficulty | Score |
|---|---|---|
| task_1_basic_antipatterns | easy | 0.7500 ✅ |
| task_2_correlated_subqueries | medium | 0.8313 ✅ |
| task_3_wildcard_scan | medium-hard | 0.6563 ✅ |
| task_4_implicit_join | hard | 0.6563 ✅ |
| task_5_window_functions | expert | 0.6500 ✅ |
Task 5 note:
task_5_window_functionsis the expert scenario, so it’s expected to be the lowest. This is not an error—just the hardest distribution.
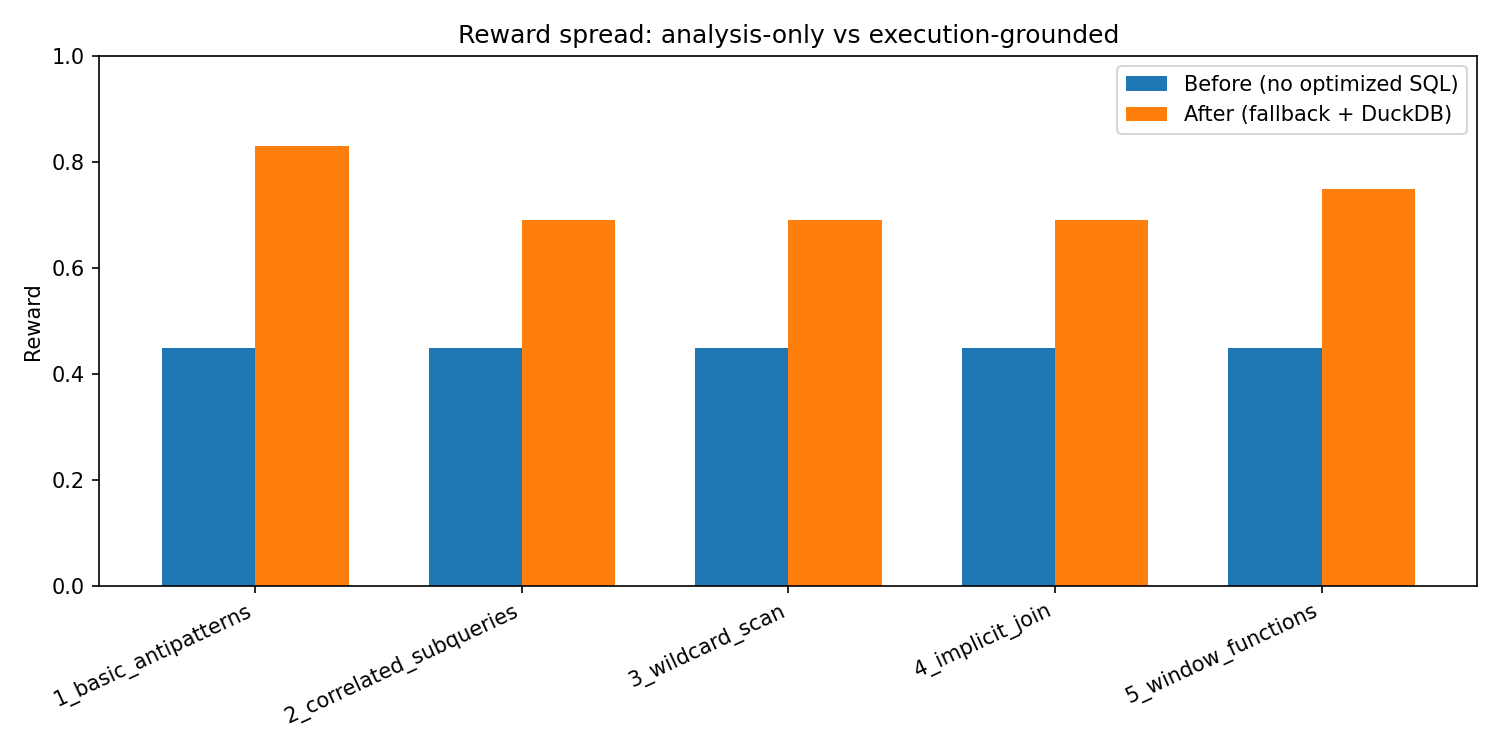
“Before / After” (environment-only, no API keys)
We also provide a reproducible before/after contrast:
- Before: suggestions present but
optimized_queryempty (no speedup/correctness signal) - After: deterministic fallback policy with a real optimized query
How to reproduce (locally)
git clone https://github.com/OfficialAbhinavSingh/SQL-Query-Optimization-Environment-.git
cd SQL-Query-Optimization-Environment-
pip install -r requirements.txt
# Baselines (fallback + optional LLM if HF_TOKEN set)
python baseline_runner.py
# Environment-only before/after (no API keys)
python training/eval_before_after.py --save-dir results