
LightGlue ⚡️
Local Feature Matching at Light Speed
Philipp Lindenberger · Paul-Edouard Sarlin · Marc Pollefeys
ICCV 2023
Paper | Colab | Poster | Train your own!

LightGlue is a deep neural network that matches sparse local features across image pairs.
An adaptive mechanism makes it fast for easy pairs (top) and reduces the computational complexity for difficult ones (bottom).
This repository hosts the inference code of LightGlue, a lightweight feature matcher with high accuracy and blazing fast inference. It takes as input a set of keypoints and descriptors for each image and returns the indices of corresponding points. The architecture is based on adaptive pruning techniques, in both network width and depth - check out the paper for more details.
We release pretrained weights of LightGlue with SuperPoint, DISK, ALIKED and SIFT local features. The training and evaluation code can be found in our library glue-factory.
Installation and demo 
Install this repo using pip:
git clone https://github.com/cvg/LightGlue.git && cd LightGlue
python -m pip install -e .
We provide a demo notebook which shows how to perform feature extraction and matching on an image pair.
Here is a minimal script to match two images:
from lightglue import LightGlue, SuperPoint, DISK, SIFT, ALIKED, DoGHardNet
from lightglue.utils import load_image, rbd
# SuperPoint+LightGlue
extractor = SuperPoint(max_num_keypoints=2048).eval().cuda() # load the extractor
matcher = LightGlue(features='superpoint').eval().cuda() # load the matcher
# or DISK+LightGlue, ALIKED+LightGlue or SIFT+LightGlue
extractor = DISK(max_num_keypoints=2048).eval().cuda() # load the extractor
matcher = LightGlue(features='disk').eval().cuda() # load the matcher
# load each image as a torch.Tensor on GPU with shape (3,H,W), normalized in [0,1]
image0 = load_image('path/to/image_0.jpg').cuda()
image1 = load_image('path/to/image_1.jpg').cuda()
# extract local features
feats0 = extractor.extract(image0) # auto-resize the image, disable with resize=None
feats1 = extractor.extract(image1)
# match the features
matches01 = matcher({'image0': feats0, 'image1': feats1})
feats0, feats1, matches01 = [rbd(x) for x in [feats0, feats1, matches01]] # remove batch dimension
matches = matches01['matches'] # indices with shape (K,2)
points0 = feats0['keypoints'][matches[..., 0]] # coordinates in image #0, shape (K,2)
points1 = feats1['keypoints'][matches[..., 1]] # coordinates in image #1, shape (K,2)
We also provide a convenience method to match a pair of images:
from lightglue import match_pair
feats0, feats1, matches01 = match_pair(extractor, matcher, image0, image1)

LightGlue can adjust its depth (number of layers) and width (number of keypoints) per image pair, with a marginal impact on accuracy.
Advanced configuration
[Detail of all parameters - click to expand]
n_layers: Number of stacked self+cross attention layers. Reduce this value for faster inference at the cost of accuracy (continuous red line in the plot above). Default: 9 (all layers).flash: Enable FlashAttention. Significantly increases the speed and reduces the memory consumption without any impact on accuracy. Default: True (LightGlue automatically detects if FlashAttention is available).mp: Enable mixed precision inference. Default: False (off)depth_confidence: Controls the early stopping. A lower values stops more often at earlier layers. Default: 0.95, disable with -1.width_confidence: Controls the iterative point pruning. A lower value prunes more points earlier. Default: 0.99, disable with -1.filter_threshold: Match confidence. Increase this value to obtain less, but stronger matches. Default: 0.1
The default values give a good trade-off between speed and accuracy. To maximize the accuracy, use all keypoints and disable the adaptive mechanisms:
extractor = SuperPoint(max_num_keypoints=None)
matcher = LightGlue(features='superpoint', depth_confidence=-1, width_confidence=-1)
To increase the speed with a small drop of accuracy, decrease the number of keypoints and lower the adaptive thresholds:
extractor = SuperPoint(max_num_keypoints=1024)
matcher = LightGlue(features='superpoint', depth_confidence=0.9, width_confidence=0.95)
The maximum speed is obtained with a combination of:
- FlashAttention: automatically used when
torch >= 2.0or if installed from source. - PyTorch compilation, available when
torch >= 2.0:
matcher = matcher.eval().cuda()
matcher.compile(mode='reduce-overhead')
For inputs with fewer than 1536 keypoints (determined experimentally), this compiles LightGlue but disables point pruning (large overhead). For larger input sizes, it automatically falls backs to eager mode with point pruning. Adaptive depths is supported for any input size.
Benchmark
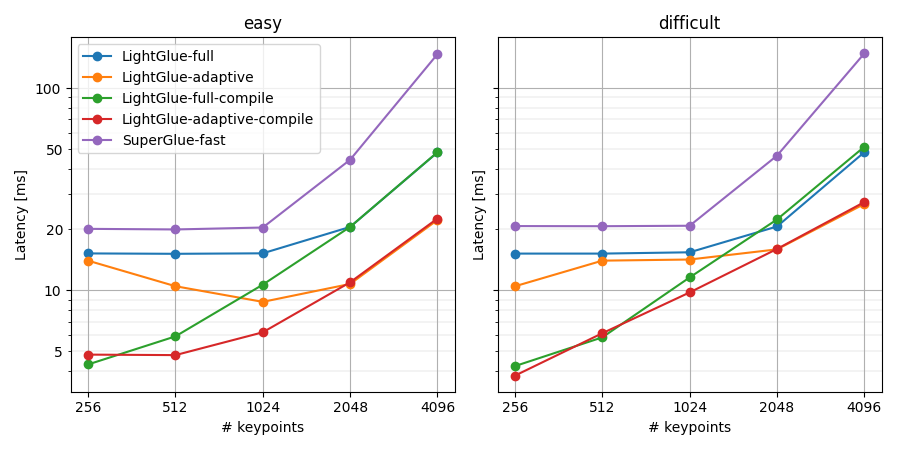
Benchmark results on GPU (RTX 3080). With compilation and adaptivity, LightGlue runs at 150 FPS @ 1024 keypoints and 50 FPS @ 4096 keypoints per image. This is a 4-10x speedup over SuperGlue.
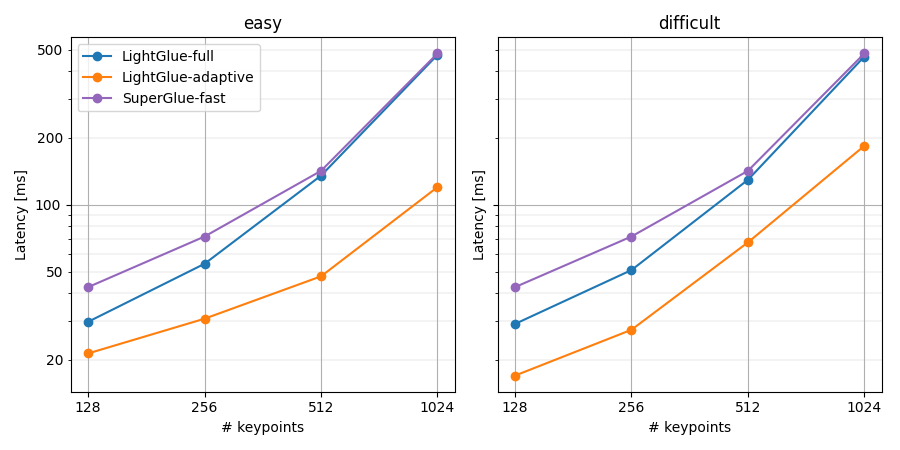
Benchmark results on CPU (Intel i7 10700K). LightGlue runs at 20 FPS @ 512 keypoints.
Obtain the same plots for your setup using our benchmark script:
python benchmark.py [--device cuda] [--add_superglue] [--num_keypoints 512 1024 2048 4096] [--compile]
[Performance tip - click to expand]
Note: Point pruning introduces an overhead that sometimes outweighs its benefits.
Point pruning is thus enabled only when the there are more than N keypoints in an image, where N is hardware-dependent.
We provide defaults optimized for current hardware (RTX 30xx GPUs).
We suggest running the benchmark script and adjusting the thresholds for your hardware by updating LightGlue.pruning_keypoint_thresholds['cuda'].
Training and evaluation
With Glue Factory, you can train LightGlue with your own local features, on your own dataset! You can also evaluate it and other baselines on standard benchmarks like HPatches and MegaDepth.
Other links
- hloc - the visual localization toolbox: run LightGlue for Structure-from-Motion and visual localization.
- LightGlue-ONNX: export LightGlue to the Open Neural Network Exchange (ONNX) format with support for TensorRT and OpenVINO.
- Image Matching WebUI: a web GUI to easily compare different matchers, including LightGlue.
- kornia now exposes LightGlue via the interfaces
LightGlueandLightGlueMatcher.
BibTeX citation
If you use any ideas from the paper or code from this repo, please consider citing:
@inproceedings{lindenberger2023lightglue,
author = {Philipp Lindenberger and
Paul-Edouard Sarlin and
Marc Pollefeys},
title = {{LightGlue: Local Feature Matching at Light Speed}},
booktitle = {ICCV},
year = {2023}
}
License
The pre-trained weights of LightGlue and the code provided in this repository are released under the Apache-2.0 license. DISK follows this license as well but SuperPoint follows a different, restrictive license (this includes its pre-trained weights and its inference file). ALIKED was published under a BSD-3-Clause license.