Spaces:
Runtime error

YoutubeGPT 🤖
Read the article to know how it works: Medium Article
With Youtube GPT you will be able to extract all the information from a video on YouTube just by pasting the video link. You will obtain the transcription, the embedding of each segment and also ask questions to the video through a chat.
All code was written with the help of Code GPT

Features
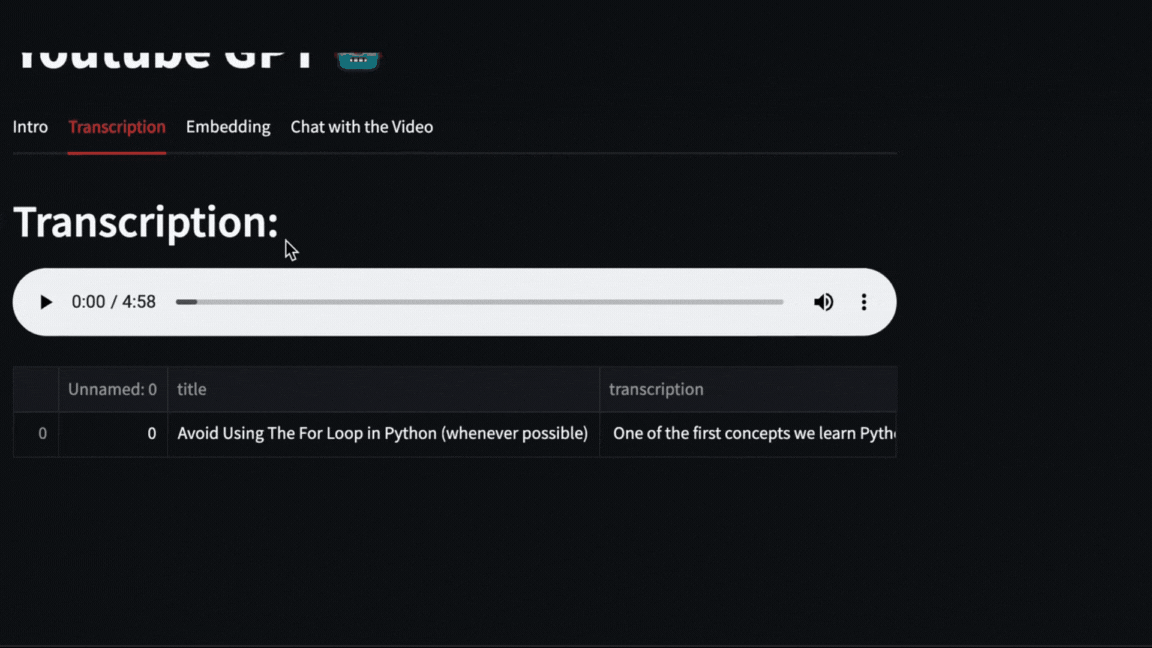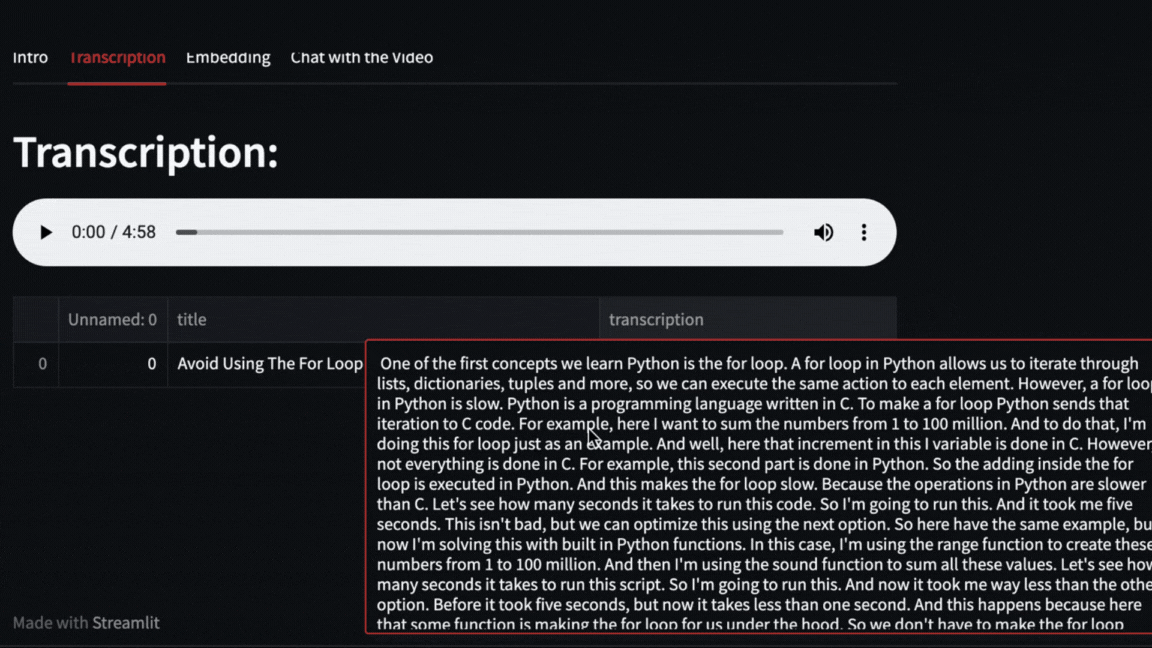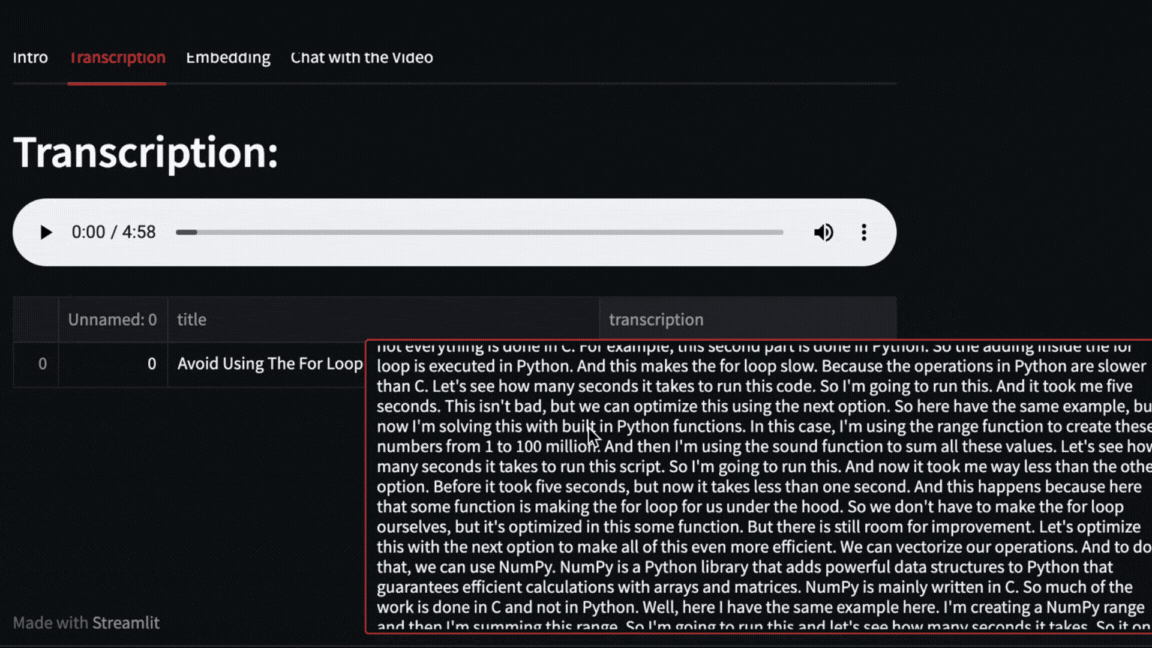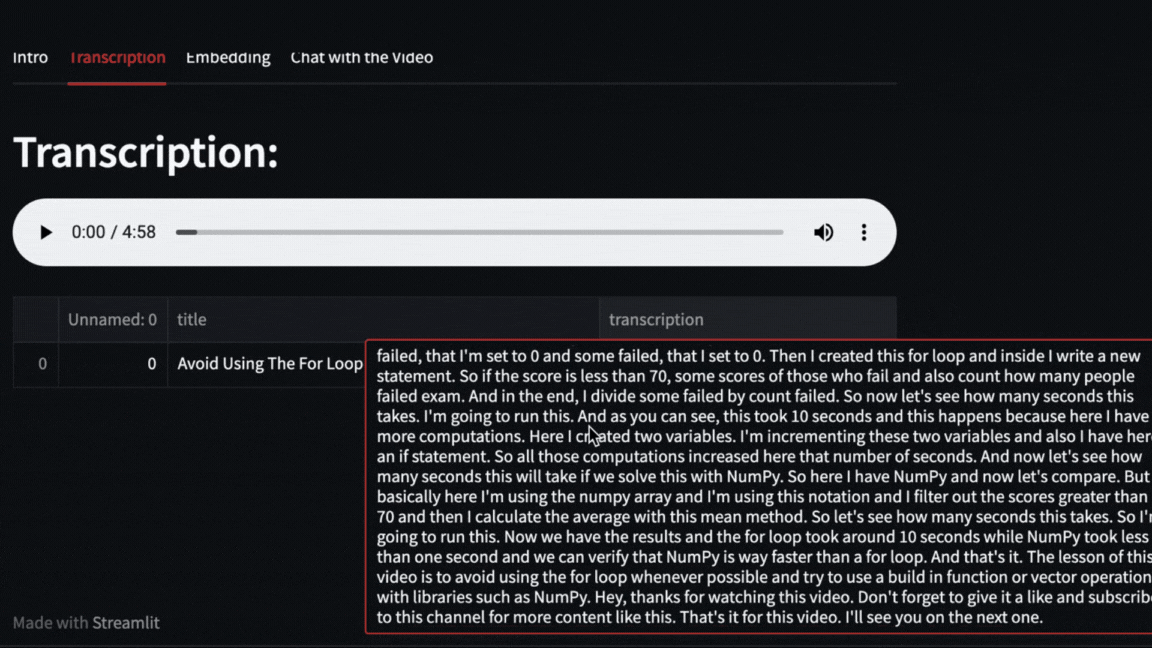
- Video transcription with OpenAI Whisper
- Embedding Transcript Segments with the OpenAI API (text-embedding-ada-002)
- Chat with the video using streamlit-chat and OpenAI API (text-davinci-003)
Example
For this example we are going to use this video from The PyCoach https://youtu.be/lKO3qDLCAnk
Add the video URL and then click Start Analysis
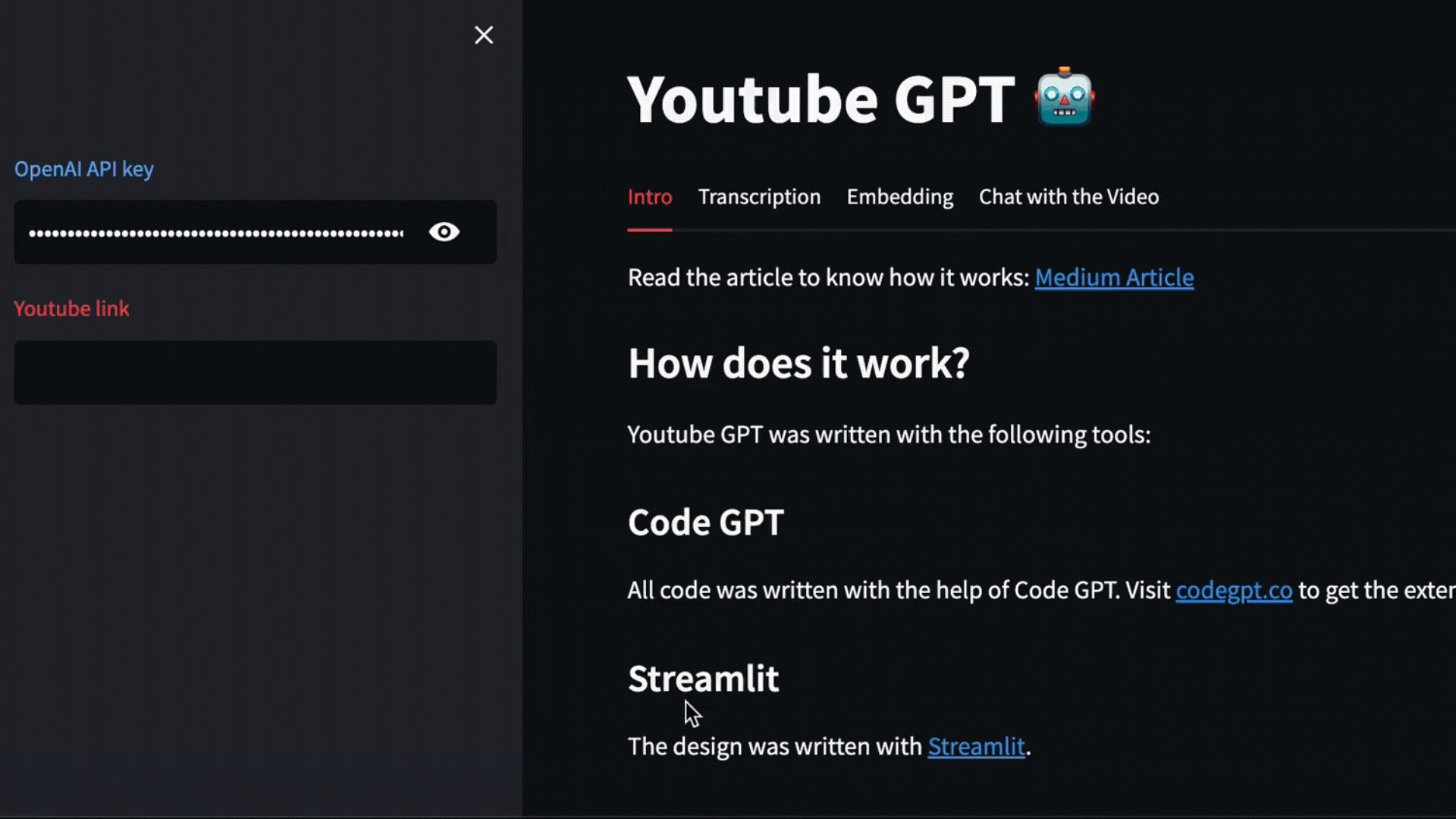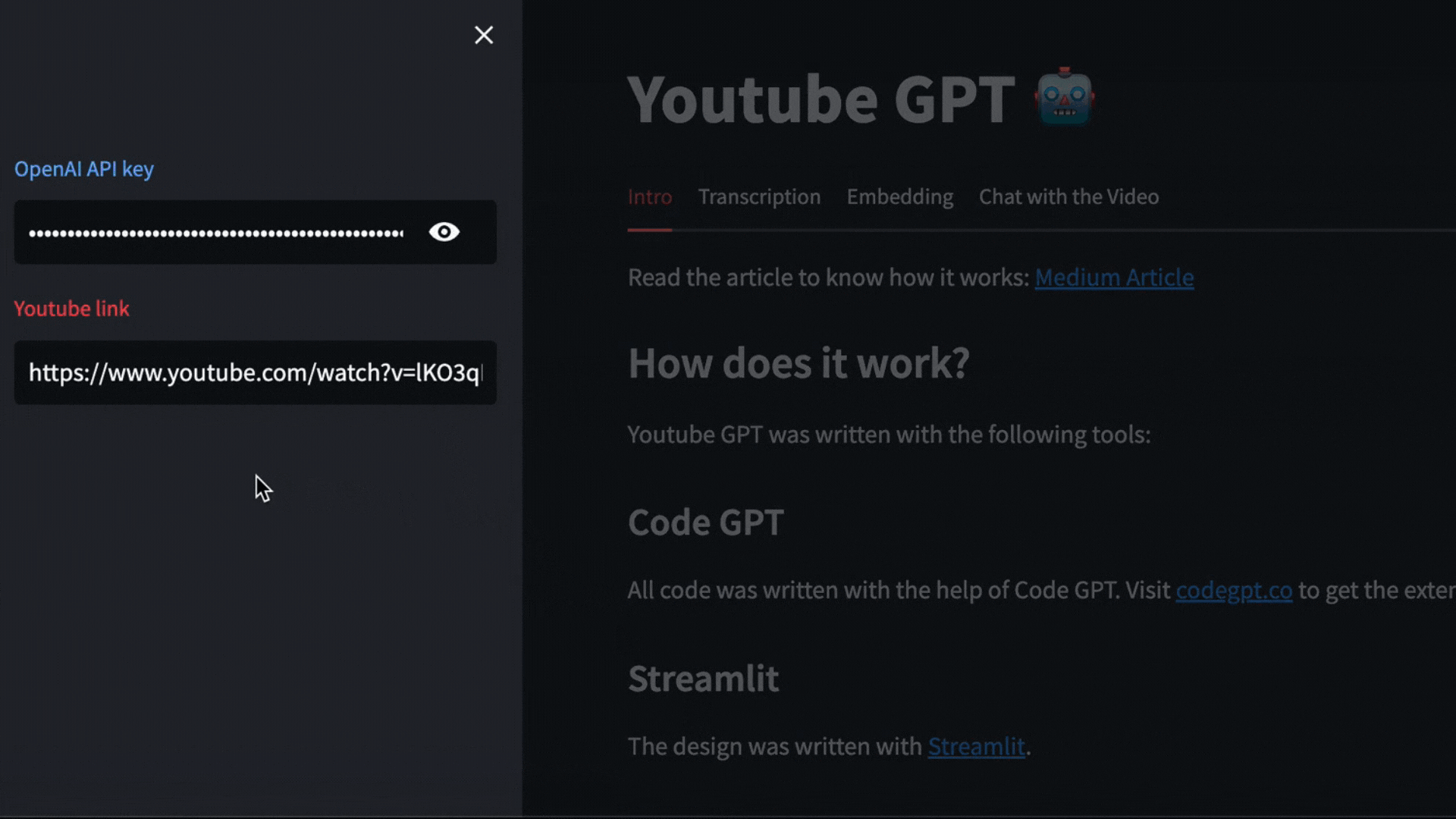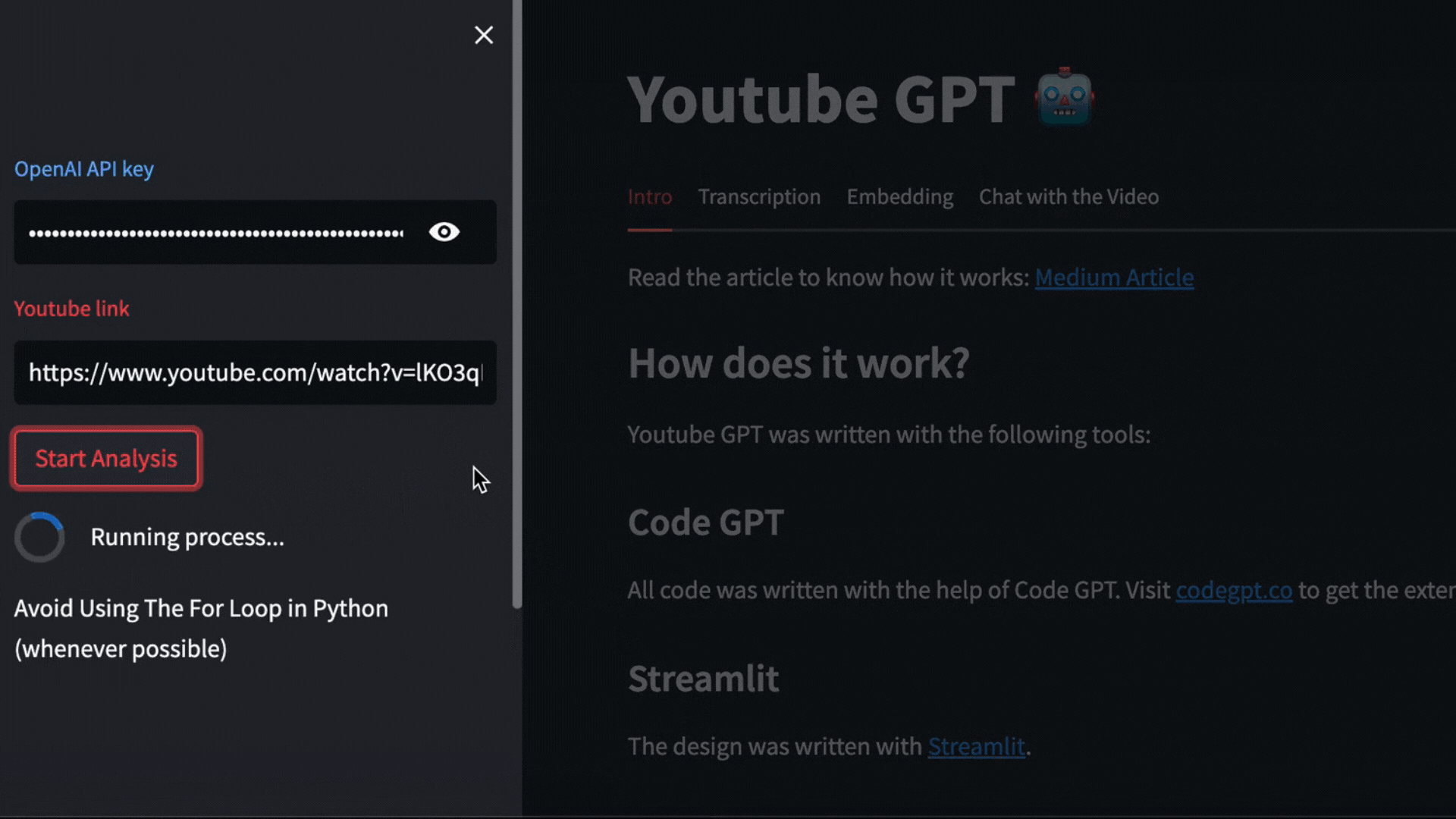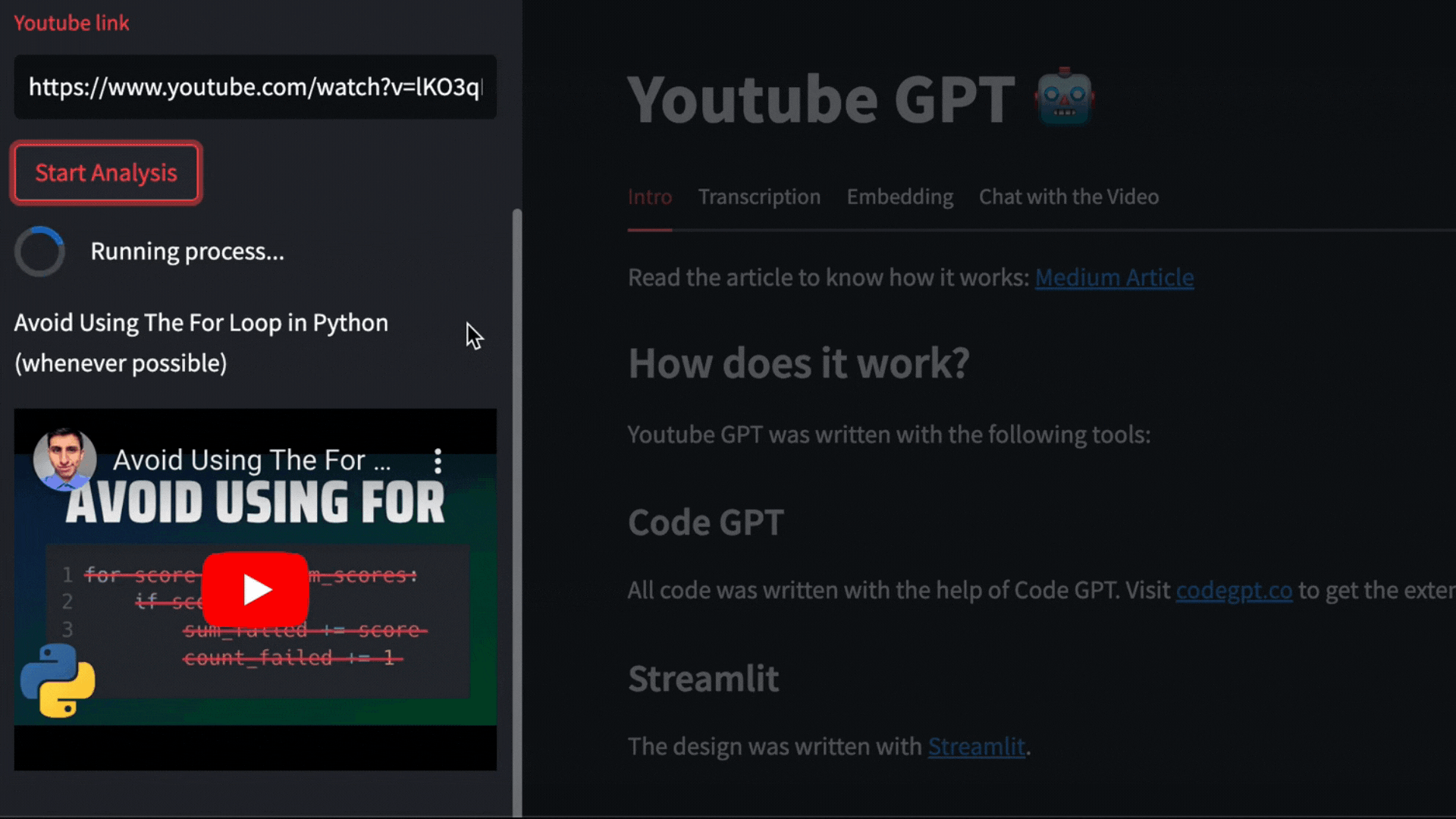
Pytube and OpenAI Whisper
The video will be downloaded with pytube and then OpenAI Whisper will take care of transcribing and segmenting the video.
# Get the video
youtube_video = YouTube(youtube_link)
streams = youtube_video.streams.filter(only_audio=True)
mp4_video = stream.download(filename='youtube_video.mp4')
audio_file = open(mp4_video, 'rb')
# whisper load base model
model = whisper.load_model('base')
# Whisper transcription
output = model.transcribe("youtube_video.mp4")
Embedding with "text-embedding-ada-002"
We obtain the vectors with text-embedding-ada-002 of each segment delivered by whisper
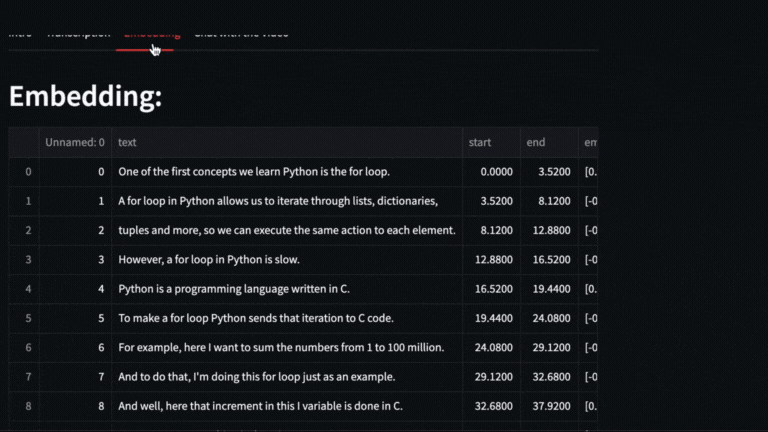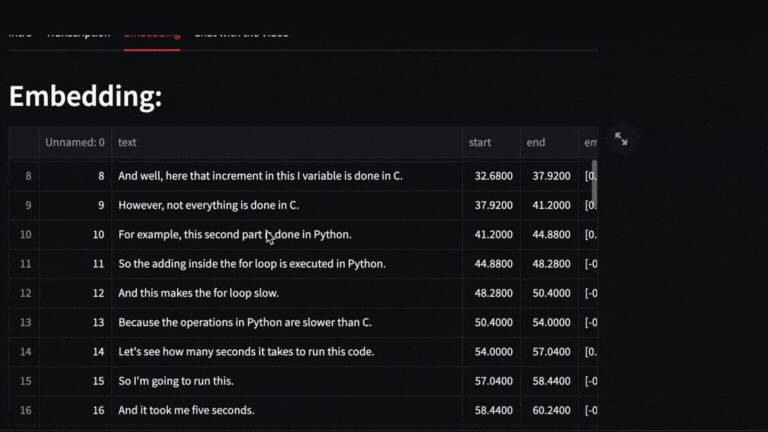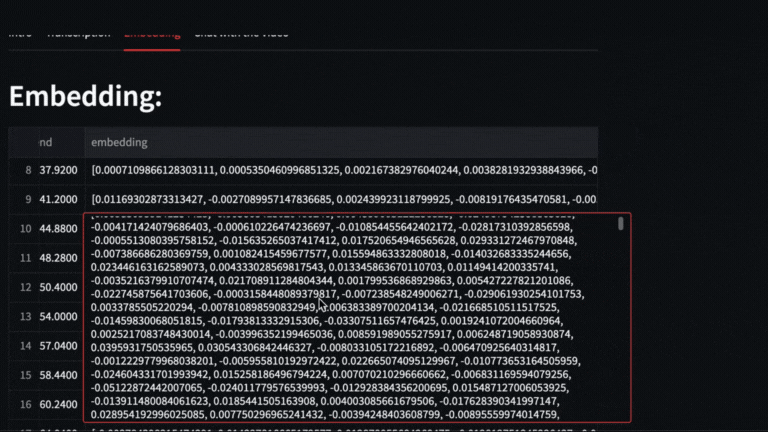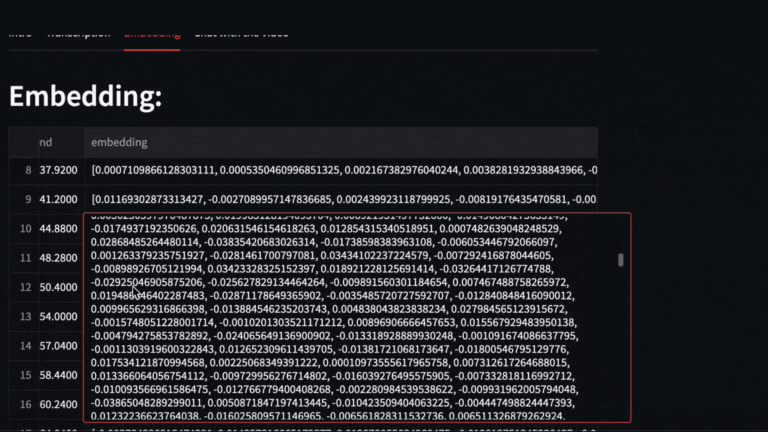
# Embeddings
segments = output['segments']
for segment in segments:
openai.api_key = user_secret
response = openai.Embedding.create(
input= segment["text"].strip(),
model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']
meta = {
"text": segment["text"].strip(),
"start": segment['start'],
"end": segment['end'],
"embedding": embeddings
}
data.append(meta)
pd.DataFrame(data).to_csv('word_embeddings.csv')
OpenAI GPT-3
We make a question to the vectorized text, we do the search of the context and then we send the prompt with the context to the model "text-davinci-003"
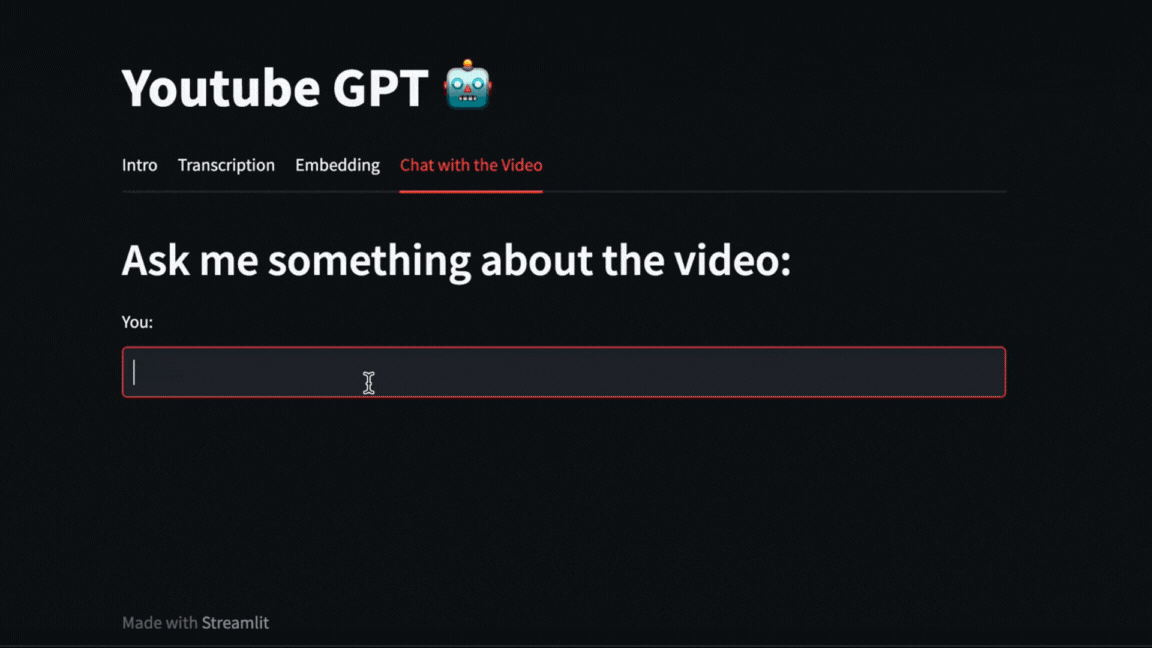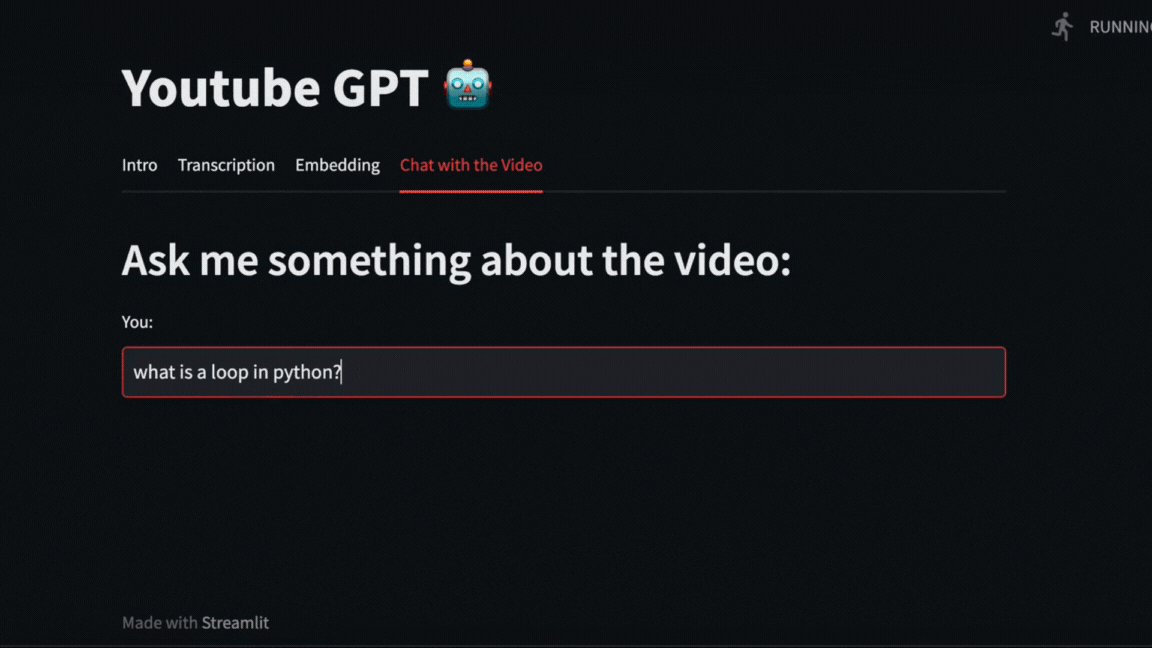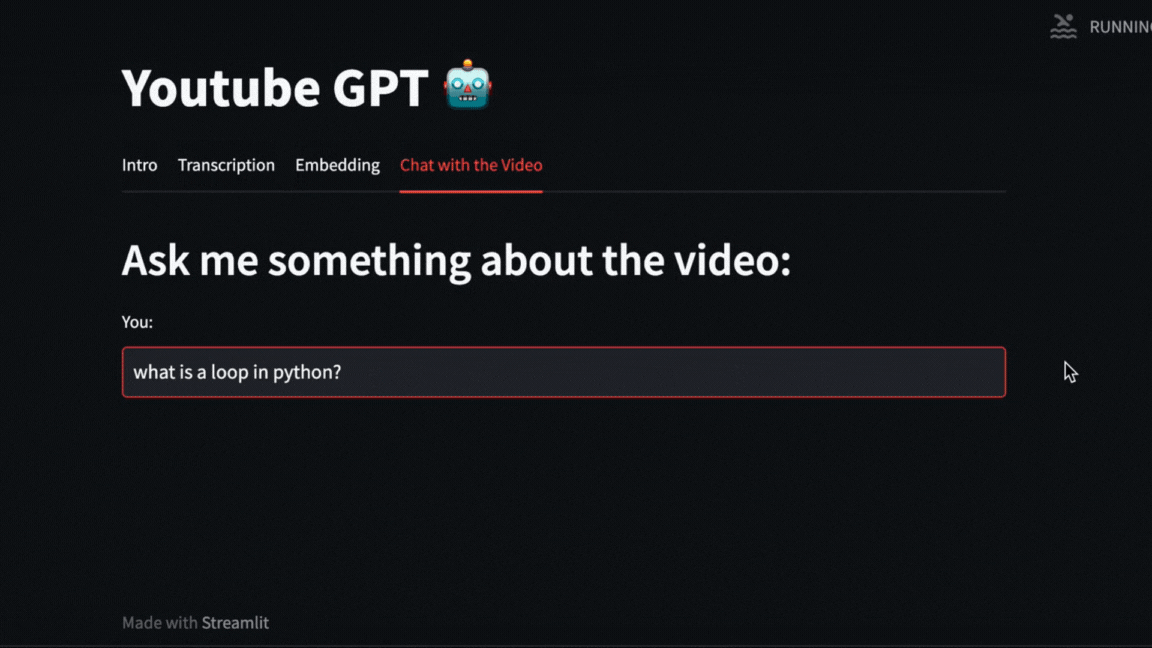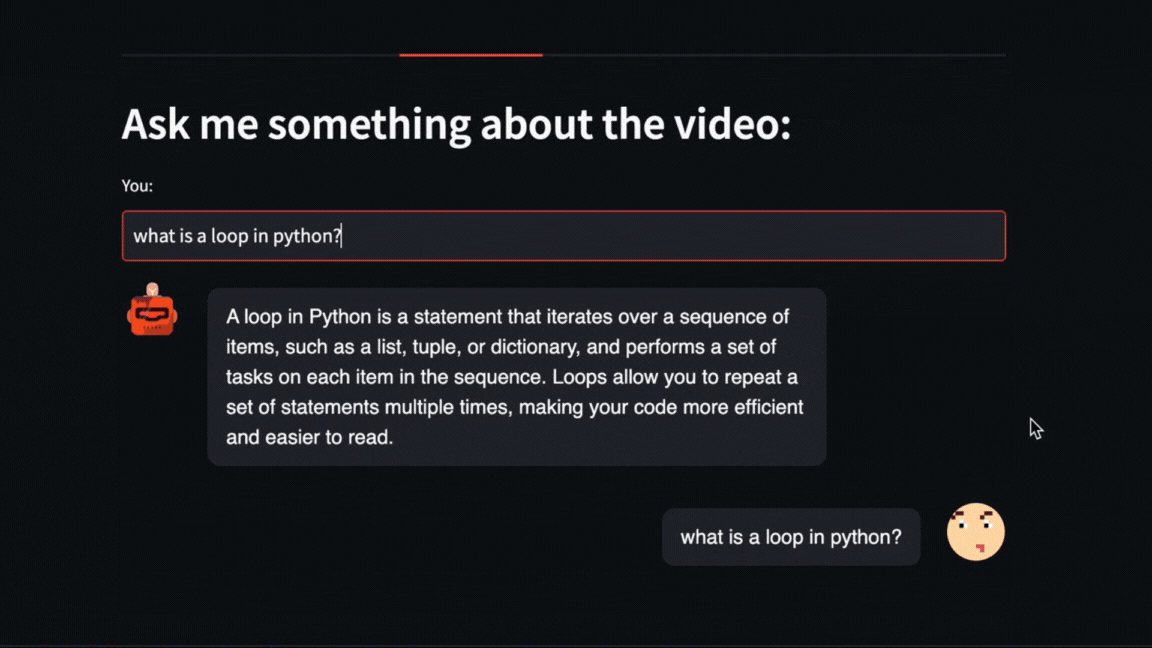
We can even ask direct questions about what happened in the video. For example, here we ask about how long the exercise with Numpy that Pycoach did in the video took.

Running Locally
- Clone the repository
git clone https://github.com/davila7/youtube-gpt
cd youtube-gpt
- Install dependencies
These dependencies are required to install with the requirements.txt file:
- streamlit
- streamlit_chat
- matplotlib
- plotly
- scipy
- sklearn
- pandas
- numpy
- git+https://github.com/openai/whisper.git
- pytube
- openai-whisper
pip install -r requirements.txt
- Run the Streamlit server
streamlit run app.py
Upcoming Features 🚀
- Semantic search with embedding
- Chart with emotional analysis
- Connect with Pinecone