Spaces:
Runtime error

Runtime error
all project
Browse files- LICENSE +21 -0
- README 2.md +117 -0
- app.py +1 -1
- packages.txt +1 -0
- requirements.txt +20 -0
- transcription.csv +2 -0
- word_embeddings.csv +0 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Daniel Avila
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README 2.md
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<h1 align="center">
|
| 2 |
+
YoutubeGPT 🤖
|
| 3 |
+
</h1>
|
| 4 |
+
|
| 5 |
+
Read the article to know how it works: <a href="https://medium.com/@dan.avila7/youtube-gpt-start-a-chat-with-a-video-efe92a499e60">Medium Article</a>
|
| 6 |
+
|
| 7 |
+
With Youtube GPT you will be able to extract all the information from a video on YouTube just by pasting the video link.
|
| 8 |
+
You will obtain the transcription, the embedding of each segment and also ask questions to the video through a chat.
|
| 9 |
+
|
| 10 |
+
All code was written with the help of <a href="https://codegpt.co">Code GPT</a>
|
| 11 |
+
|
| 12 |
+
<a href="https://codegpt.co" target="_blank"><img width="753" alt="Captura de Pantalla 2023-02-08 a la(s) 9 16 43 p m" src="https://user-images.githubusercontent.com/6216945/217699939-eca3ae47-c488-44da-9cf6-c7caef69e1a7.png"></a>
|
| 13 |
+
|
| 14 |
+
<hr>
|
| 15 |
+
<br>
|
| 16 |
+
|
| 17 |
+
# Features
|
| 18 |
+
|
| 19 |
+
- Video transcription with **OpenAI Whisper**
|
| 20 |
+
- Embedding Transcript Segments with the OpenAI API (**text-embedding-ada-002**)
|
| 21 |
+
- Chat with the video using **streamlit-chat** and OpenAI API (**text-davinci-003**)
|
| 22 |
+
|
| 23 |
+
# Example
|
| 24 |
+
For this example we are going to use this video from The PyCoach
|
| 25 |
+
https://youtu.be/lKO3qDLCAnk
|
| 26 |
+
|
| 27 |
+
Add the video URL and then click Start Analysis
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
## Pytube and OpenAI Whisper
|
| 31 |
+
The video will be downloaded with pytube and then OpenAI Whisper will take care of transcribing and segmenting the video.
|
| 32 |
+
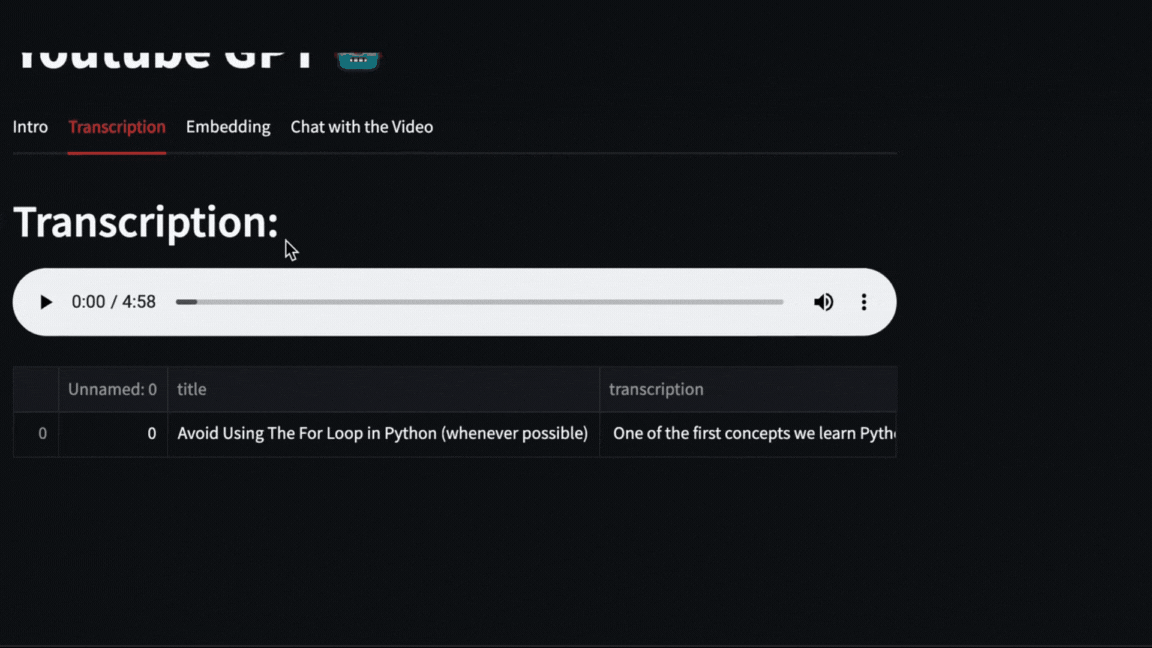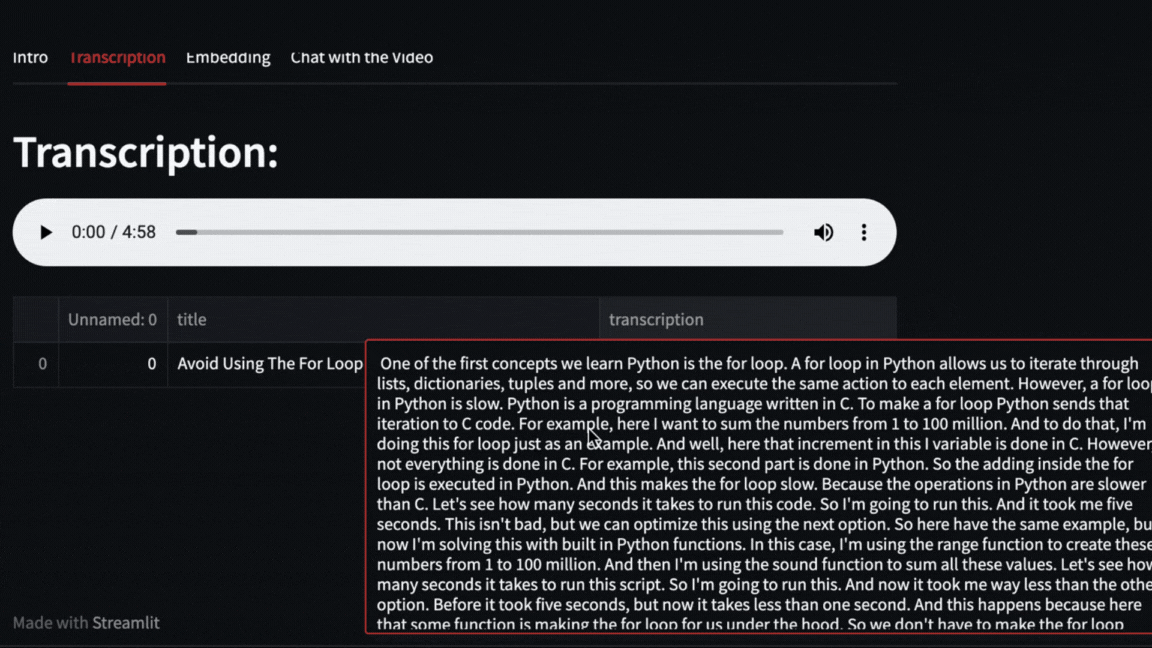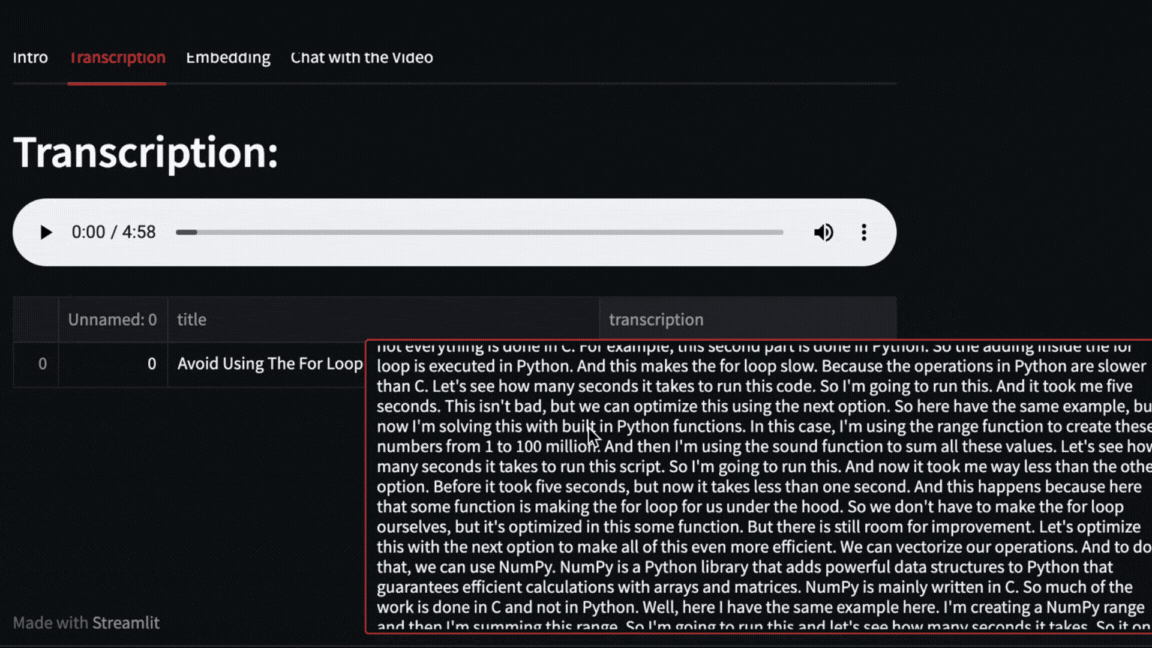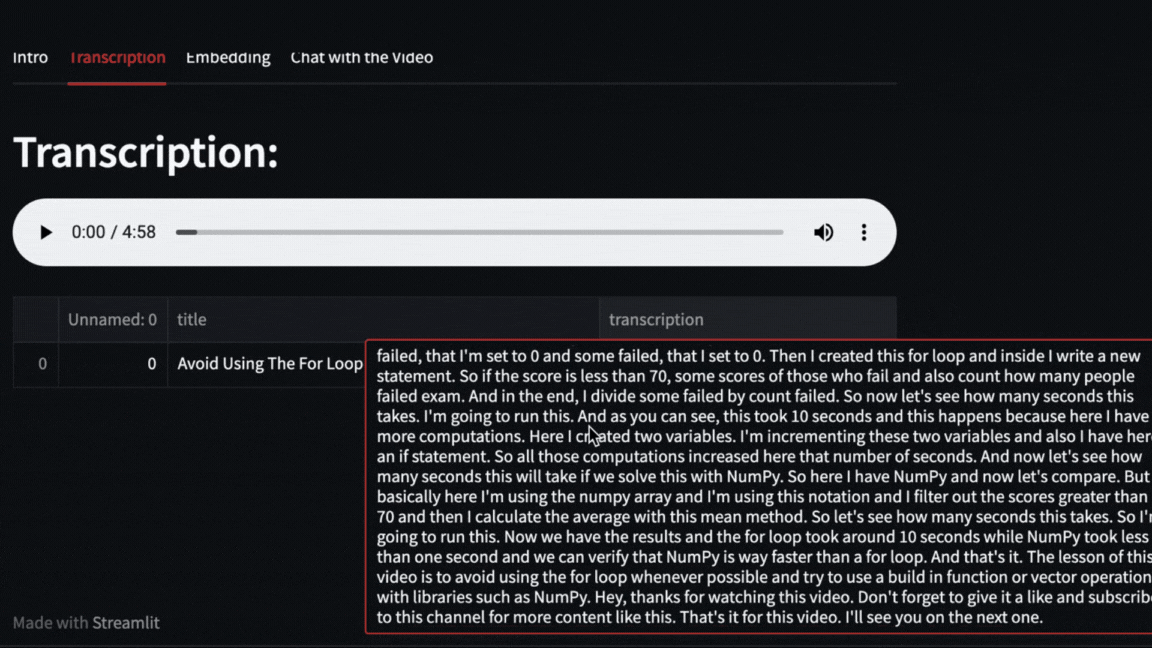
|
| 33 |
+
|
| 34 |
+
```python
|
| 35 |
+
# Get the video
|
| 36 |
+
youtube_video = YouTube(youtube_link)
|
| 37 |
+
streams = youtube_video.streams.filter(only_audio=True)
|
| 38 |
+
mp4_video = stream.download(filename='youtube_video.mp4')
|
| 39 |
+
audio_file = open(mp4_video, 'rb')
|
| 40 |
+
|
| 41 |
+
# whisper load base model
|
| 42 |
+
model = whisper.load_model('base')
|
| 43 |
+
|
| 44 |
+
# Whisper transcription
|
| 45 |
+
output = model.transcribe("youtube_video.mp4")
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
## Embedding with "text-embedding-ada-002"
|
| 49 |
+
We obtain the vectors with **text-embedding-ada-002** of each segment delivered by whisper
|
| 50 |
+
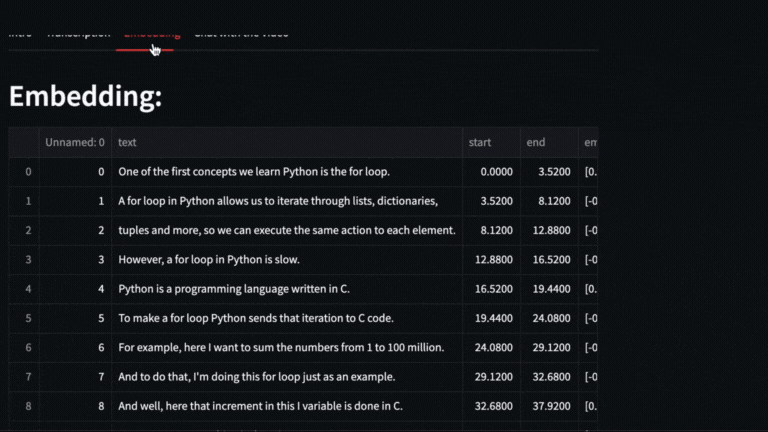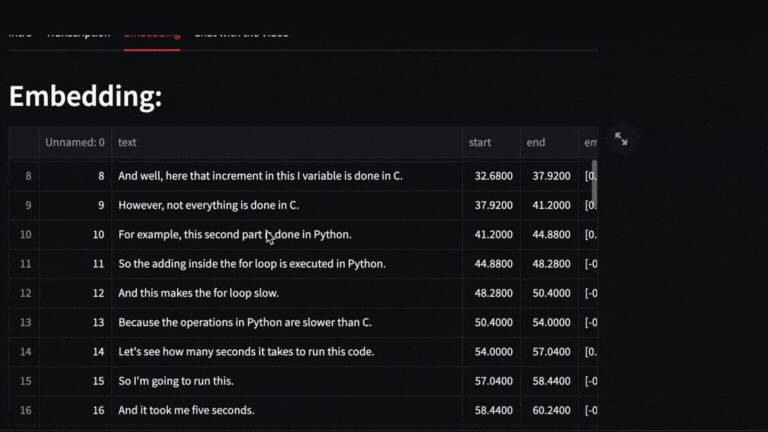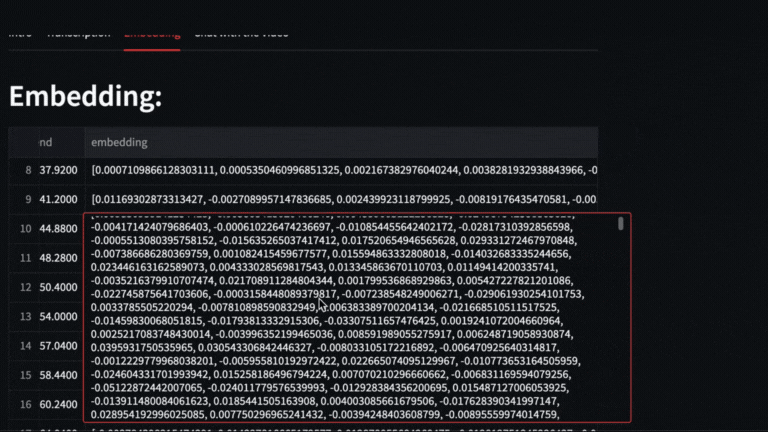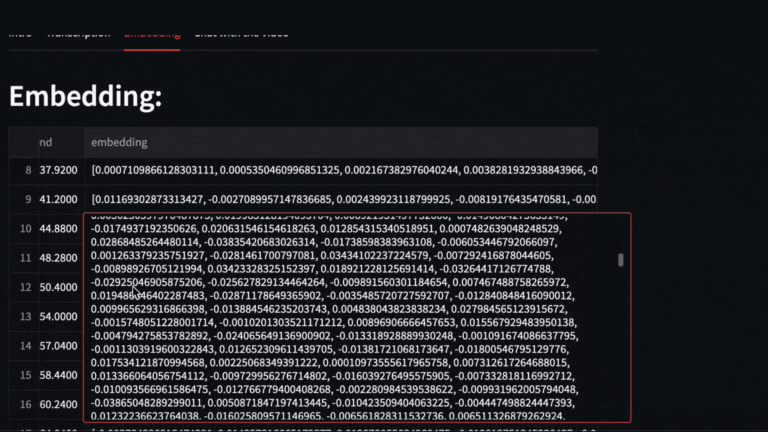
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
# Embeddings
|
| 54 |
+
segments = output['segments']
|
| 55 |
+
for segment in segments:
|
| 56 |
+
openai.api_key = user_secret
|
| 57 |
+
response = openai.Embedding.create(
|
| 58 |
+
input= segment["text"].strip(),
|
| 59 |
+
model="text-embedding-ada-002"
|
| 60 |
+
)
|
| 61 |
+
embeddings = response['data'][0]['embedding']
|
| 62 |
+
meta = {
|
| 63 |
+
"text": segment["text"].strip(),
|
| 64 |
+
"start": segment['start'],
|
| 65 |
+
"end": segment['end'],
|
| 66 |
+
"embedding": embeddings
|
| 67 |
+
}
|
| 68 |
+
data.append(meta)
|
| 69 |
+
pd.DataFrame(data).to_csv('word_embeddings.csv')
|
| 70 |
+
```
|
| 71 |
+
## OpenAI GPT-3
|
| 72 |
+
We make a question to the vectorized text, we do the search of the context and then we send the prompt with the context to the model "text-davinci-003"
|
| 73 |
+
|
| 74 |
+
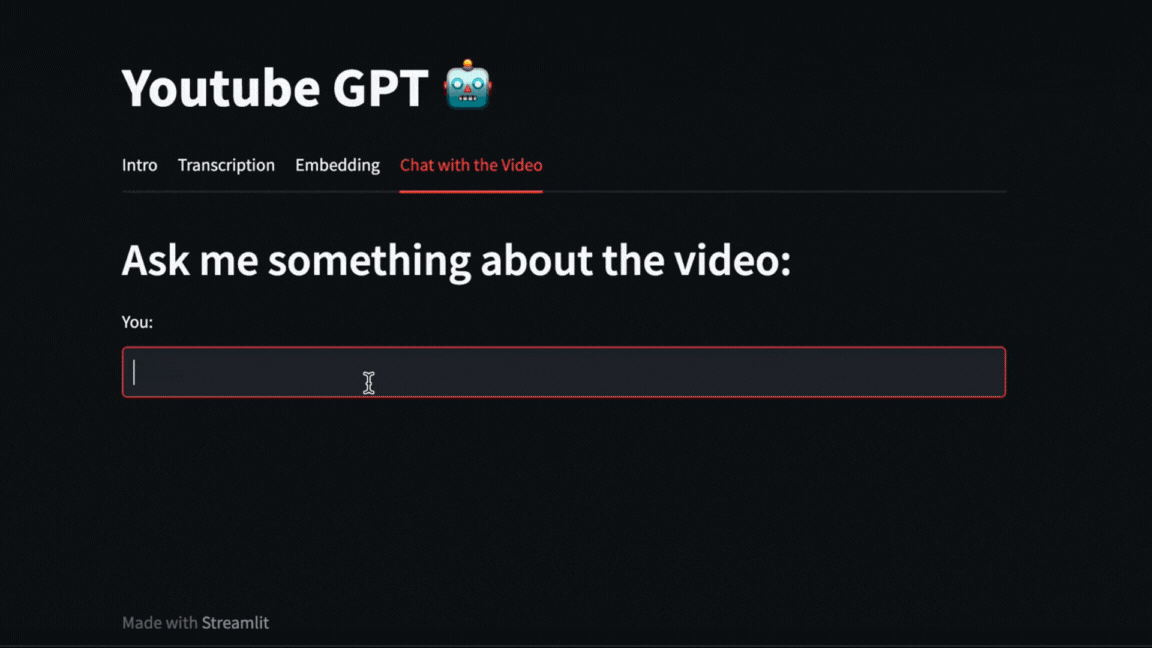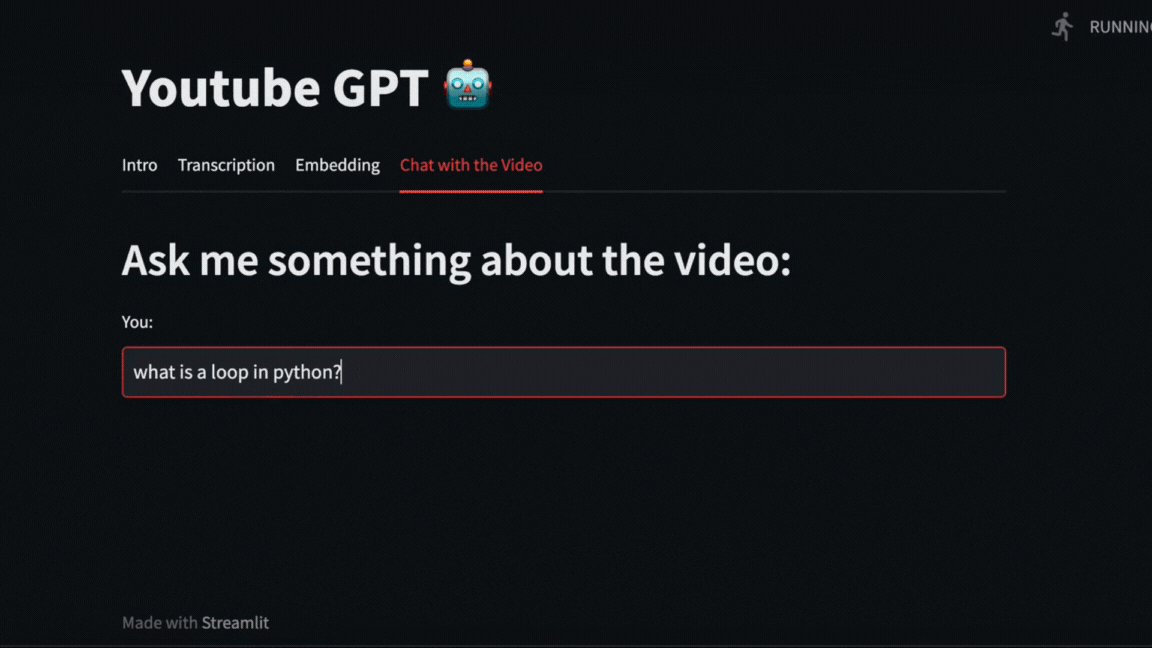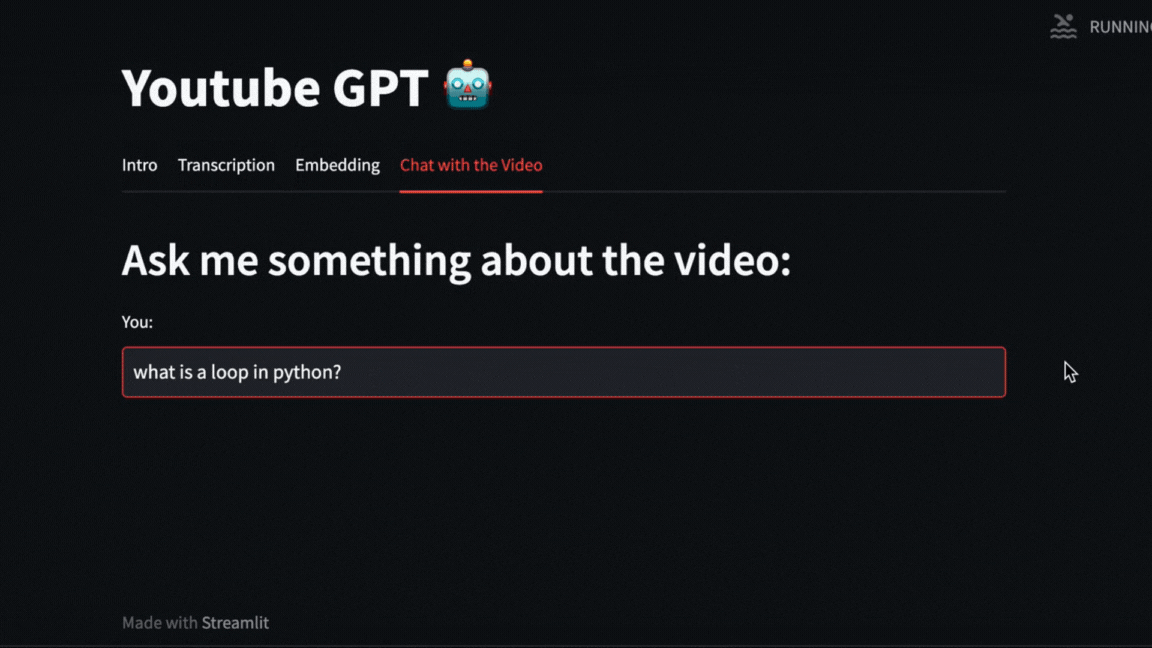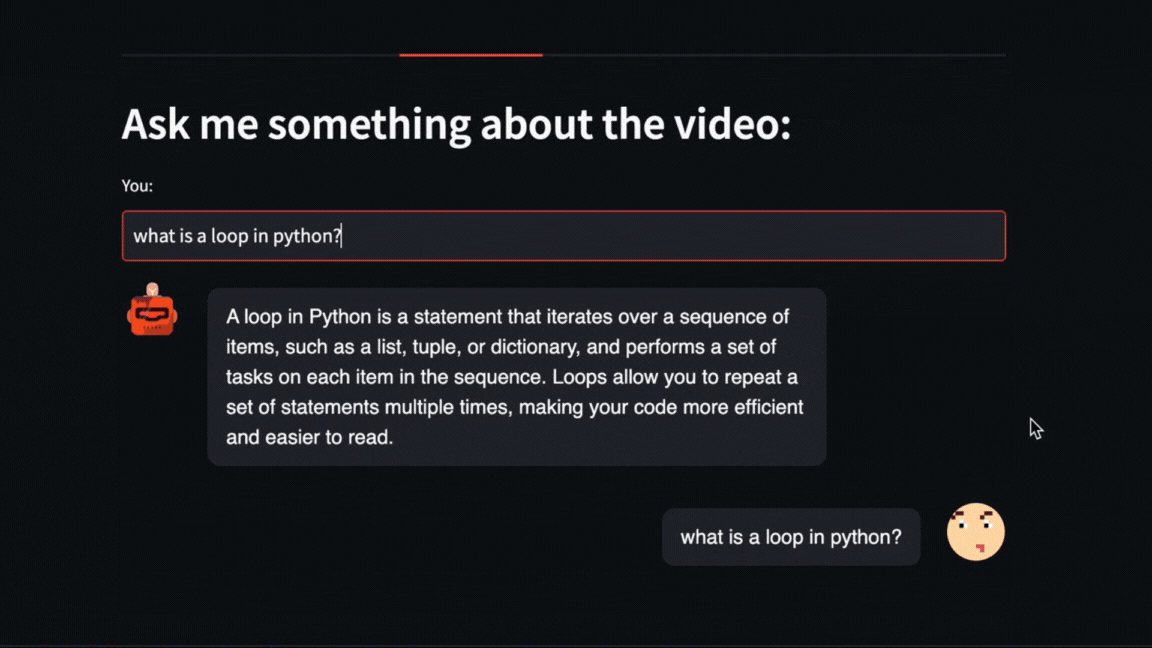
|
| 75 |
+
|
| 76 |
+
We can even ask direct questions about what happened in the video. For example, here we ask about how long the exercise with Numpy that Pycoach did in the video took.
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
# Running Locally
|
| 81 |
+
|
| 82 |
+
1. Clone the repository
|
| 83 |
+
|
| 84 |
+
```bash
|
| 85 |
+
git clone https://github.com/davila7/youtube-gpt
|
| 86 |
+
cd youtube-gpt
|
| 87 |
+
```
|
| 88 |
+
2. Install dependencies
|
| 89 |
+
|
| 90 |
+
These dependencies are required to install with the requirements.txt file:
|
| 91 |
+
|
| 92 |
+
* streamlit
|
| 93 |
+
* streamlit_chat
|
| 94 |
+
* matplotlib
|
| 95 |
+
* plotly
|
| 96 |
+
* scipy
|
| 97 |
+
* sklearn
|
| 98 |
+
* pandas
|
| 99 |
+
* numpy
|
| 100 |
+
* git+https://github.com/openai/whisper.git
|
| 101 |
+
* pytube
|
| 102 |
+
* openai-whisper
|
| 103 |
+
|
| 104 |
+
```bash
|
| 105 |
+
pip install -r requirements.txt
|
| 106 |
+
```
|
| 107 |
+
3. Run the Streamlit server
|
| 108 |
+
|
| 109 |
+
```bash
|
| 110 |
+
streamlit run app.py
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
## Upcoming Features 🚀
|
| 114 |
+
|
| 115 |
+
- Semantic search with embedding
|
| 116 |
+
- Chart with emotional analysis
|
| 117 |
+
- Connect with Pinecone
|
app.py
CHANGED
|
@@ -180,7 +180,7 @@ with tab4:
|
|
| 180 |
df['distances'] = distances_from_embeddings(q_embedding, df['embedding'].values, distance_metric='cosine')
|
| 181 |
returns = []
|
| 182 |
|
| 183 |
-
# Sort by distance with
|
| 184 |
for i, row in df.sort_values('distances', ascending=True).head(4).iterrows():
|
| 185 |
# Else add it to the text that is being returned
|
| 186 |
returns.append(row["text"])
|
|
|
|
| 180 |
df['distances'] = distances_from_embeddings(q_embedding, df['embedding'].values, distance_metric='cosine')
|
| 181 |
returns = []
|
| 182 |
|
| 183 |
+
# Sort by distance with 2 hints
|
| 184 |
for i, row in df.sort_values('distances', ascending=True).head(4).iterrows():
|
| 185 |
# Else add it to the text that is being returned
|
| 186 |
returns.append(row["text"])
|
packages.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
ffmpeg
|
requirements.txt
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#
|
| 2 |
+
# This file is autogenerated by pip-compile with python 3.10
|
| 3 |
+
# To update, run:
|
| 4 |
+
#
|
| 5 |
+
# pip-compile
|
| 6 |
+
#
|
| 7 |
+
matplotlib
|
| 8 |
+
plotly
|
| 9 |
+
scipy
|
| 10 |
+
sklearn
|
| 11 |
+
scikit-learn
|
| 12 |
+
pandas
|
| 13 |
+
numpy
|
| 14 |
+
git+https://github.com/openai/whisper.git
|
| 15 |
+
pytube
|
| 16 |
+
streamlit
|
| 17 |
+
streamlit_chat
|
| 18 |
+
openai
|
| 19 |
+
pinecone-client
|
| 20 |
+
python-dotenv
|
transcription.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,title,transcription
|
| 2 |
+
0,equivocarse," Entonces lo que tenemos que hacer es la institución es grandes, es si hacer un cambio interno, capacitarlos en las nuevas tecnologías y metodología y ellos tienen que seguir haciendo su departamento tecnológico internos en un proceso, pero tienen que crear una capacidad paralela de abrirse al ecosistema y de usar esta arta para crear nuevo valor y nuevos ingresos, esto no es votar tu plataforma actual, lo que no hacemos es buscar distinta alternativa, lo que hace la empresa buscar una línea, voy a hacer transformación digital, voy a hacer una app, no es transformación digital hacer una app, es buscar las distintas plataformas y las distintas tecnologías dentro de la organización y probar con muchas empresas afuera y a una de esas le van a apuntar, a 10 capácte no le apunten, pero el fracaso de aprendizaje, el fracaso no es fracaso, el fracaso es que aprendiste y puede seguir otro camino."
|
word_embeddings.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|