Spaces:
Paused

![]()
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
This is the repo for the Video-LLaMA project, which is working on empowering large language models with video and audio understanding capabilities.
News
- [08.03] NOTE: Release the LLaMA-2-Chat version of Video-LLaMA, including its pre-trained and instruction-tuned checkpoints. We uploaded full weights on Huggingface (7B-Pretrained,7B-Finetuned,13B-Pretrained,13B-Finetuned), just for your convenience and secondary development. Welcome to try.
- [06.14] NOTE: the current online interactive demo is primarily for English chatting and it may NOT be a good option to ask Chinese questions since Vicuna/LLaMA does not represent Chinese texts very well.
- [06.13] NOTE: the audio support is ONLY for Vicuna-7B by now although we have several VL checkpoints available for other decoders.
- [06.10] NOTE: we have NOT updated the HF demo yet because the whole framework (with audio branch) cannot run normally on A10-24G. The current running demo is still the previous version of Video-LLaMA. We will fix this issue soon.
- [06.08] 🚀🚀 Release the checkpoints of the audio-supported Video-LLaMA. Documentation and example outputs are also updated.
- [05.22] 🚀🚀 Interactive demo online, try our Video-LLaMA (with Vicuna-7B as language decoder) at Hugging Face and ModelScope!!
- [05.22] ⭐️ Release Video-LLaMA v2 built with Vicuna-7B
- [05.18] 🚀🚀 Support video-grounded chat in Chinese
- Video-LLaMA-BiLLA: we introduce BiLLa-7B as language decoder and fine-tune the video-language aligned model (i.e., stage 1 model) with machine-translated VideoChat instructions.
- Video-LLaMA-Ziya: same with Video-LLaMA-BiLLA but the language decoder is changed to Ziya-13B.
- [05.18] ⭐️ Create a Hugging Face repo to store the model weights of all the variants of our Video-LLaMA.
- [05.15] ⭐️ Release Video-LLaMA v2: we use the training data provided by VideoChat to further enhance the instruction-following capability of Video-LLaMA.
- [05.07] Release the initial version of Video-LLaMA, including its pre-trained and instruction-tuned checkpoints.
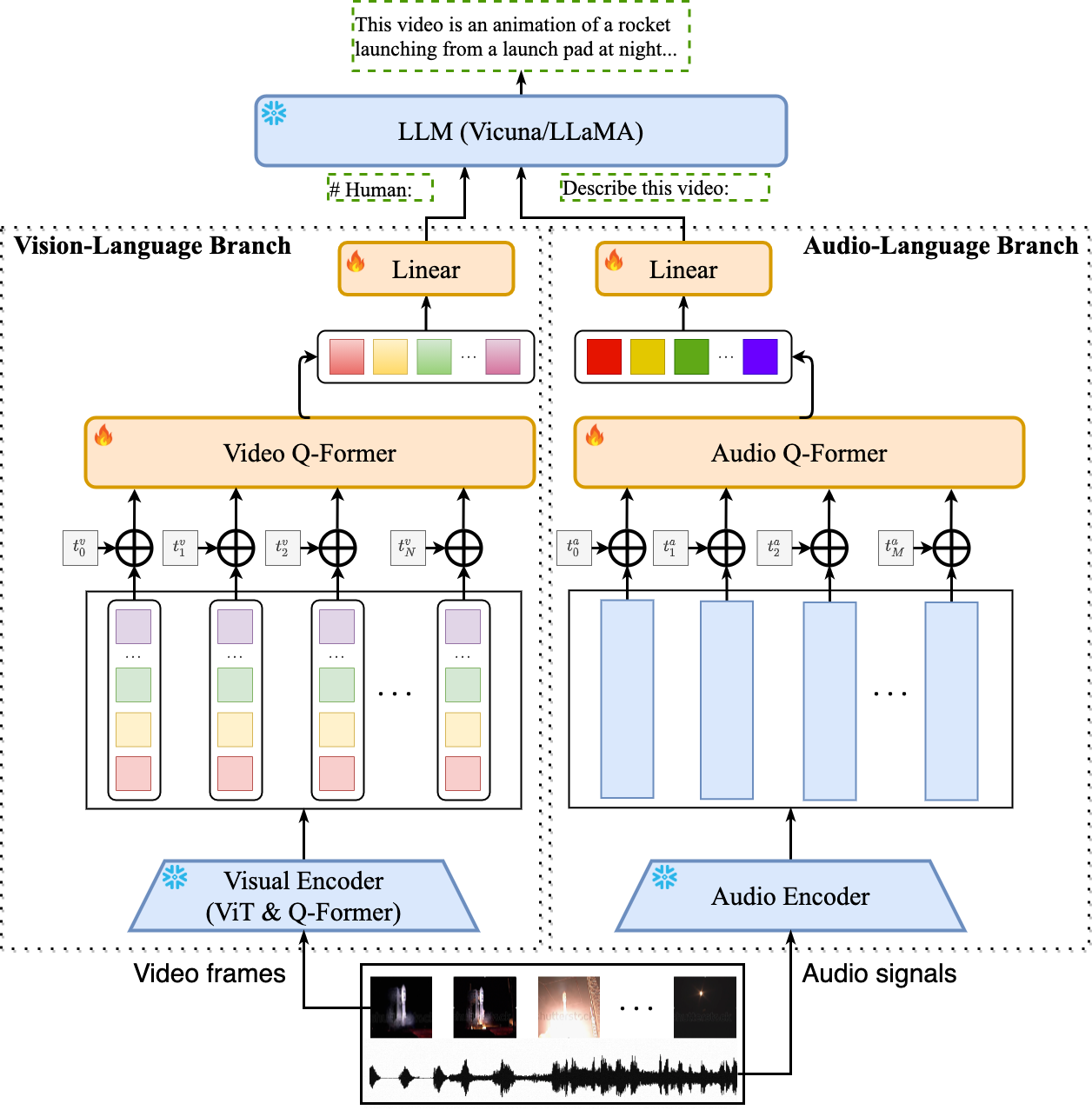
Introduction
- Video-LLaMA is built on top of BLIP-2 and MiniGPT-4. It is composed of two core components: (1) Vision-Language (VL) Branch and (2) Audio-Language (AL) Branch.
- VL Branch (Visual encoder: ViT-G/14 + BLIP-2 Q-Former)
- A two-layer video Q-Former and a frame embedding layer (applied to the embeddings of each frame) are introduced to compute video representations.
- We train VL Branch on the Webvid-2M video caption dataset with a video-to-text generation task. We also add image-text pairs (~595K image captions from LLaVA) into the pre-training dataset to enhance the understanding of static visual concepts.
- After pre-training, we further fine-tune our VL Branch using the instruction-tuning data from MiniGPT-4, LLaVA and VideoChat.
- AL Branch (Audio encoder: ImageBind-Huge)
- A two-layer audio Q-Former and a audio segment embedding layer (applied to the embedding of each audio segment) are introduced to compute audio representations.
- As the used audio encoder (i.e., ImageBind) is already aligned across multiple modalities, we train AL Branch on video/image instrucaption data only, just to connect the output of ImageBind to language decoder.
- VL Branch (Visual encoder: ViT-G/14 + BLIP-2 Q-Former)
- Note that only the Video/Audio Q-Former, positional embedding layers and the linear layers are trainable during cross-modal training.
Example Outputs
- Video with background sound
Video without sound effects
Static image
Pre-trained & Fine-tuned Checkpoints
The following checkpoints store learnable parameters (positional embedding layers, Video/Audio Q-former and linear projection layers) only.
Vision-Language Branch
| Checkpoint | Link | Note |
|---|---|---|
| pretrain-vicuna7b | link | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
| finetune-vicuna7b-v2 | link | Fine-tuned on the instruction-tuning data from MiniGPT-4, LLaVA and VideoChat |
| pretrain-vicuna13b | link | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
| finetune-vicuna13b-v2 | link | Fine-tuned on the instruction-tuning data from MiniGPT-4, LLaVA and VideoChat |
| pretrain-ziya13b-zh | link | Pre-trained with Chinese LLM Ziya-13B |
| finetune-ziya13b-zh | link | Fine-tuned on machine-translated VideoChat instruction-following dataset (in Chinese) |
| pretrain-billa7b-zh | link | Pre-trained with Chinese LLM BiLLA-7B |
| finetune-billa7b-zh | link | Fine-tuned on machine-translated VideoChat instruction-following dataset (in Chinese) |
Audio-Language Branch
| Checkpoint | Link | Note |
|---|---|---|
| pretrain-vicuna7b | link | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
| finetune-vicuna7b-v2 | link | Fine-tuned on the instruction-tuning data from MiniGPT-4, LLaVA and VideoChat |
Usage
Enviroment Preparation
First, install ffmpeg.
apt update
apt install ffmpeg
Then, create a conda environment:
conda env create -f environment.yml
conda activate videollama
Prerequisites
Before using the repository, make sure you have obtained the following checkpoints:
Pre-trained Language Decoder
- Get the original LLaMA weights in the Hugging Face format by following the instructions here.
- Download Vicuna delta weights :point_right: [7B][13B] (Note: we use v0 weights instead of v1.1 weights).
- Use the following command to add delta weights to the original LLaMA weights to obtain the Vicuna weights:
python apply_delta.py \
--base /path/to/llama-13b \
--target /output/path/to/vicuna-13b --delta /path/to/vicuna-13b-delta
Pre-trained Visual Encoder in Vision-Language Branch
- Download the MiniGPT-4 model (trained linear layer) from this link.
Pre-trained Audio Encoder in Audio-Language Branch
- Download the weight of ImageBind from this link.
Download Learnable Weights
Use git-lfs to download the learnable weights of our Video-LLaMA (i.e., positional embedding layer + Q-Former + linear projection layer):
git lfs install
git clone https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series
The above commands will download the model weights of all the Video-LLaMA variants. For sure, you can choose to download the weights on demand. For example, if you want to run Video-LLaMA with Vicuna-7B as language decoder locally, then:
wget https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna7b-v2.pth
wget https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune_vicuna7b_audiobranch.pth
should meet the requirement.
How to Run Demo Locally
Firstly, set the llama_model, imagebind_ckpt_path, ckpt and ckpt_2 in eval_configs/video_llama_eval_withaudio.yaml.
Then run the script:
python demo_audiovideo.py \
--cfg-path eval_configs/video_llama_eval_withaudio.yaml --model_type vicuna --gpu-id 0
Training
The training of each cross-modal branch (i.e., VL branch or AL branch) in Video-LLaMA consists of two stages,
Pre-training on the Webvid-2.5M video caption dataset and LLaVA-CC3M image caption dataset.
Fine-tuning using the image-based instruction-tuning data from MiniGPT-4/LLaVA and the video-based instruction-tuning data from VideoChat.
1. Pre-training
Data Preparation
Download the metadata and video following the instruction from the official Github repo of Webvid. The folder structure of the dataset is shown below:
|webvid_train_data
|──filter_annotation
|────0.tsv
|──videos
|────000001_000050
|──────1066674784.mp4
|cc3m
|──filter_cap.json
|──image
|────GCC_train_000000000.jpg
|────...
Script
Config the the checkpoint and dataset paths in video_llama_stage1_pretrain.yaml. Run the script:
conda activate videollama
torchrun --nproc_per_node=8 train.py --cfg-path ./train_configs/video_llama_stage1_pretrain.yaml
2. Instruction Fine-tuning
Data
For now, the fine-tuning dataset consists of:
- 150K image-based instructions from LLaVA [link]
- 3K image-based instructions from MiniGPT-4 [link]
- 11K video-based instructions from VideoChat [link]
Script
Config the checkpoint and dataset paths in video_llama_stage2_finetune.yaml.
conda activate videollama
torchrun --nproc_per_node=8 train.py --cfg-path ./train_configs/video_llama_stage2_finetune.yaml
Recommended GPUs
- Pre-training: 8xA100 (80G)
- Instruction-tuning: 8xA100 (80G)
- Inference: 1xA100 (40G/80G) or 1xA6000
Acknowledgement
We are grateful for the following awesome projects our Video-LLaMA arising from:
- MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models
- FastChat: An Open Platform for Training, Serving, and Evaluating Large Language Model based Chatbots
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- EVA-CLIP: Improved Training Techniques for CLIP at Scale
- ImageBind: One Embedding Space To Bind Them All
- LLaMA: Open and Efficient Foundation Language Models
- VideoChat: Chat-Centric Video Understanding
- LLaVA: Large Language and Vision Assistant
- WebVid: A Large-scale Video-Text dataset
- mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
The logo of Video-LLaMA is generated by Midjourney.
Term of Use
Our Video-LLaMA is just a research preview intended for non-commercial use only. You must NOT use our Video-LLaMA for any illegal, harmful, violent, racist, or sexual purposes. You are strictly prohibited from engaging in any activity that will potentially violate these guidelines.
Citation
If you find our project useful, hope you can star our repo and cite our paper as follows:
@article{damonlpsg2023videollama,
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
year = 2023,
journal = {arXiv preprint arXiv:2306.02858},
url = {https://arxiv.org/abs/2306.02858}
}