

Most code models are trained on data from public software repositories hosted on GitHub. Some also include code coupled with natural text from platforms such as Stack Overflow. Additional datasets can be crafted based on the target task of the model. Alphacode, for instance, was fine-tuned on CodeContests, a competitive programming dataset for machine-learning. Another popular dataset is The Pile, which is a large corpus containing both natural language texts and code from different sources such as StackExchange dumps and popular (>100 stars) GitHub repositories. It can be efficient for models intended to do translation from natural text to code or the opposite, it was used in CodeGen for instance.
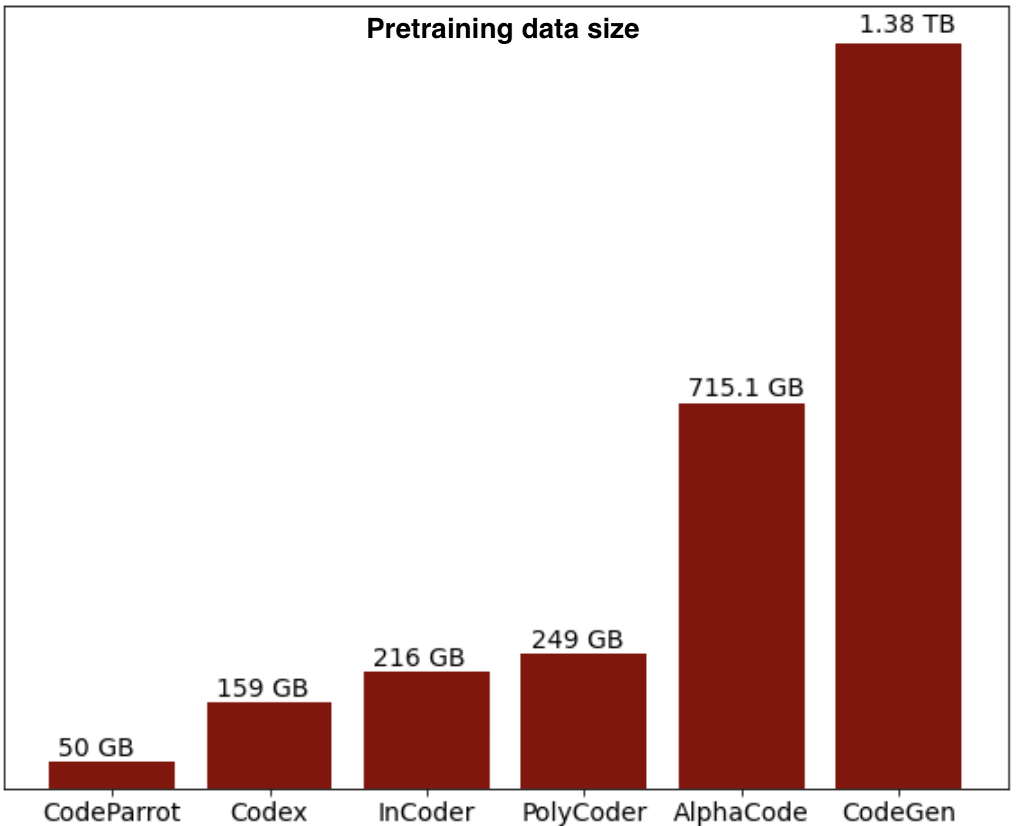
Below is the distribution of the pretraining data size of some code models, we provide model-specific information for open-source models later in this section:
Some other useful datasets that are available on the 🤗 Hub are CodeSearchNet, a corpus of 2 milllion (comment, code) pairs from open-source libraries hosted on GitHub for several programming languages, and Mostly Basic Python Problems (mbpp), a benchmark of around 1,000 crowd-sourced Python programming problems, for entry level programmers, where each problem consists of a task description, code solution and 3 automated test cases, this dataset was used in InCoder evaluation in addition to HumanEval that we will present later. You can also find APPS, a benchmark with 10000 problems consisting of programming questions in English and code solutions in Python, this dataset was also used in Codex evaluation along with HumanEval.