Spaces:
Runtime error

A newer version of the Gradio SDK is available:
4.42.0
title: Vocabulary-free Image Classification
emoji: 🌍
colorFrom: green
colorTo: yellow
sdk: gradio
sdk_version: 4.36.0
python_version: '3.9'
app_file: app.py
pinned: false
Vocabulary-free Image Classification
Alessandro Conti, Enrico Fini, Massimiliano Mancini, Paolo Rota, Yiming Wang, Elisa Ricci
Recent advances in large vision-language models have revolutionized the image classification paradigm. Despite showing impressive zero-shot capabilities, a pre-defined set of categories, a.k.a. the vocabulary, is assumed at test time for composing the textual prompts. However, such assumption can be impractical when the semantic context is unknown and evolving. We thus formalize a novel task, termed as Vocabulary-free Image Classification (VIC), where we aim to assign to an input image a class that resides in an unconstrained language-induced semantic space, without the prerequisite of a known vocabulary. VIC is a challenging task as the semantic space is extremely large, containing millions of concepts, with hard-to-discriminate fine-grained categories.
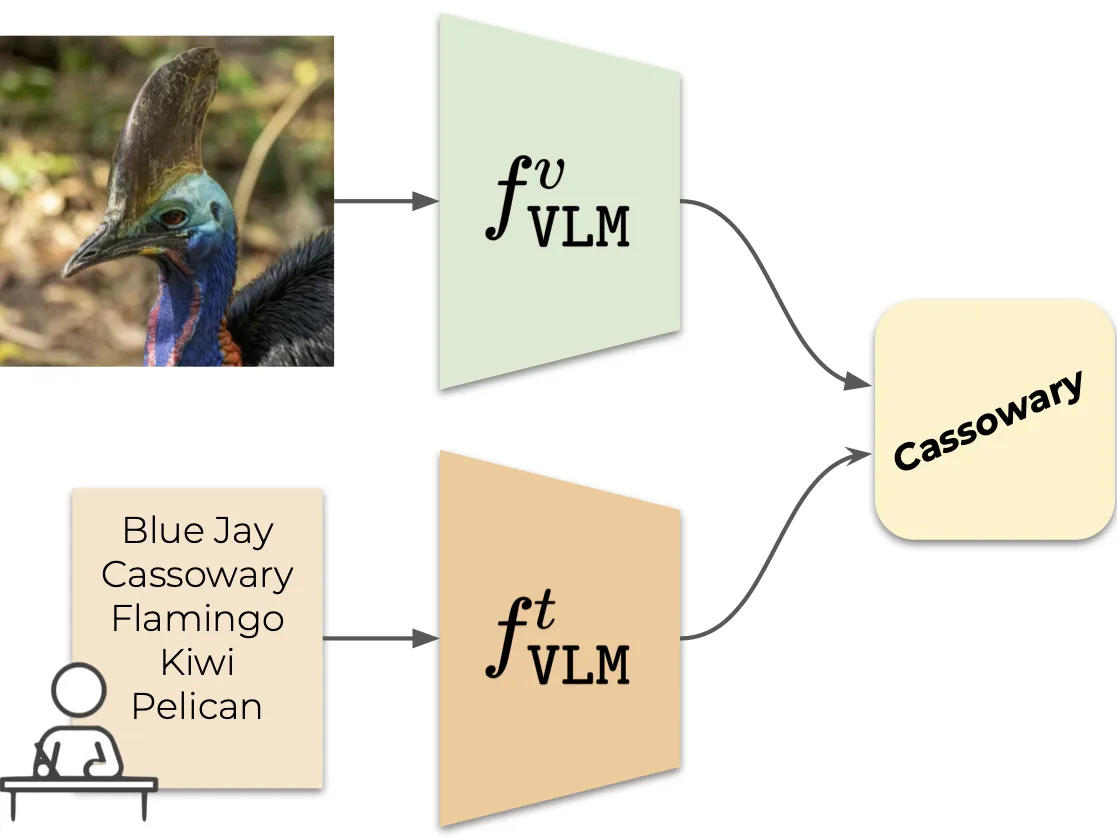 |
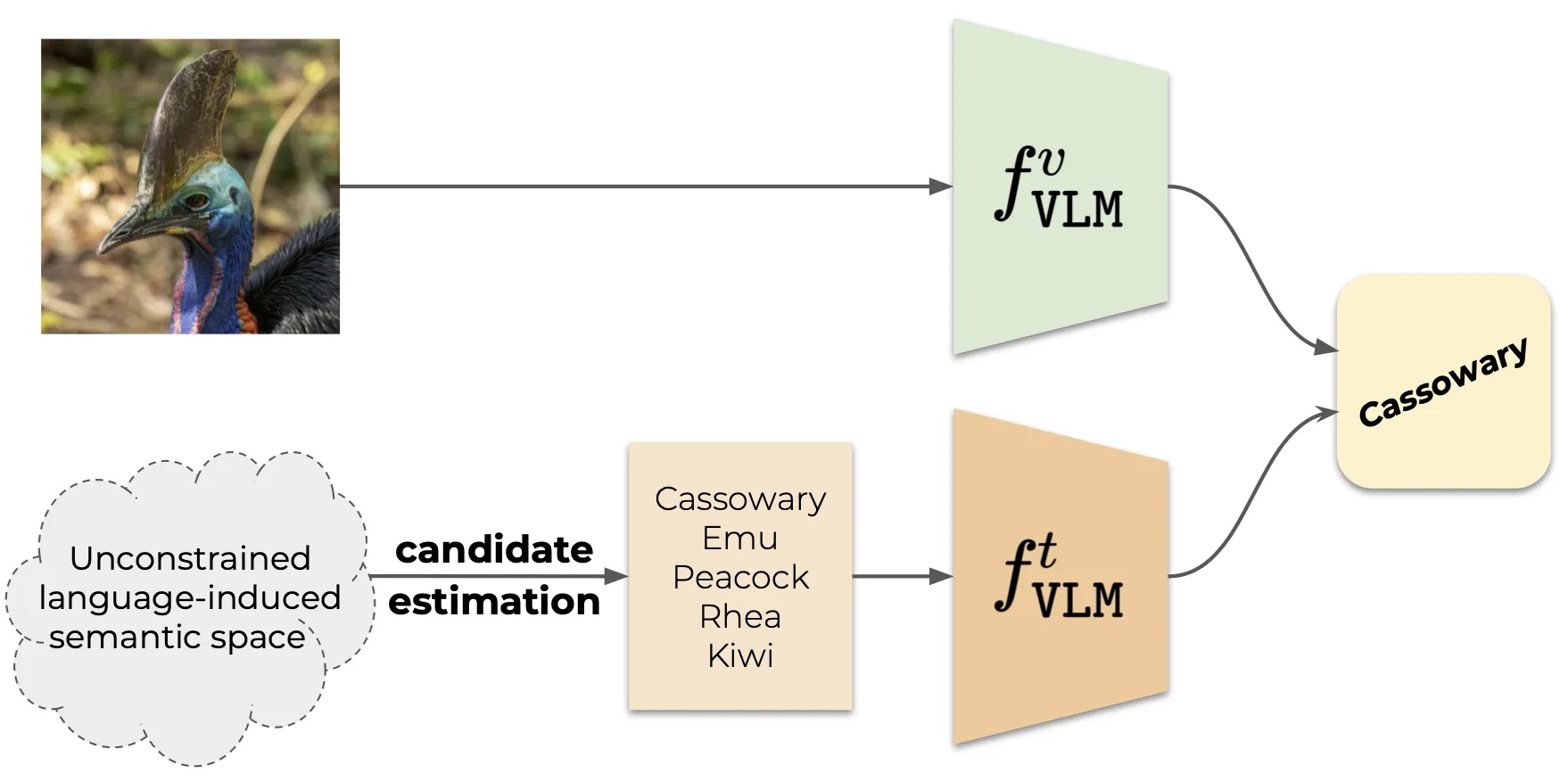 |
|---|---|
| Vision Language Model (VLM)-based classification | Vocabulary-free Image Classification |
In this work, we first empirically verify that representing this semantic space by means of an external vision-language database is the most effective way to obtain semantically relevant content for classifying the image. We then propose Category Search from External Databases (CaSED), a method that exploits a pre-trained vision-language model and an external vision-language database to address VIC in a training-free manner. CaSED first extracts a set of candidate categories from captions retrieved from the database based on their semantic similarity to the image, and then assigns to the image the best matching candidate category according to the same vision-language model. Experiments on benchmark datasets validate that CaSED outperforms other complex vision-language frameworks, while being efficient with much fewer parameters, paving the way for future research in this direction.
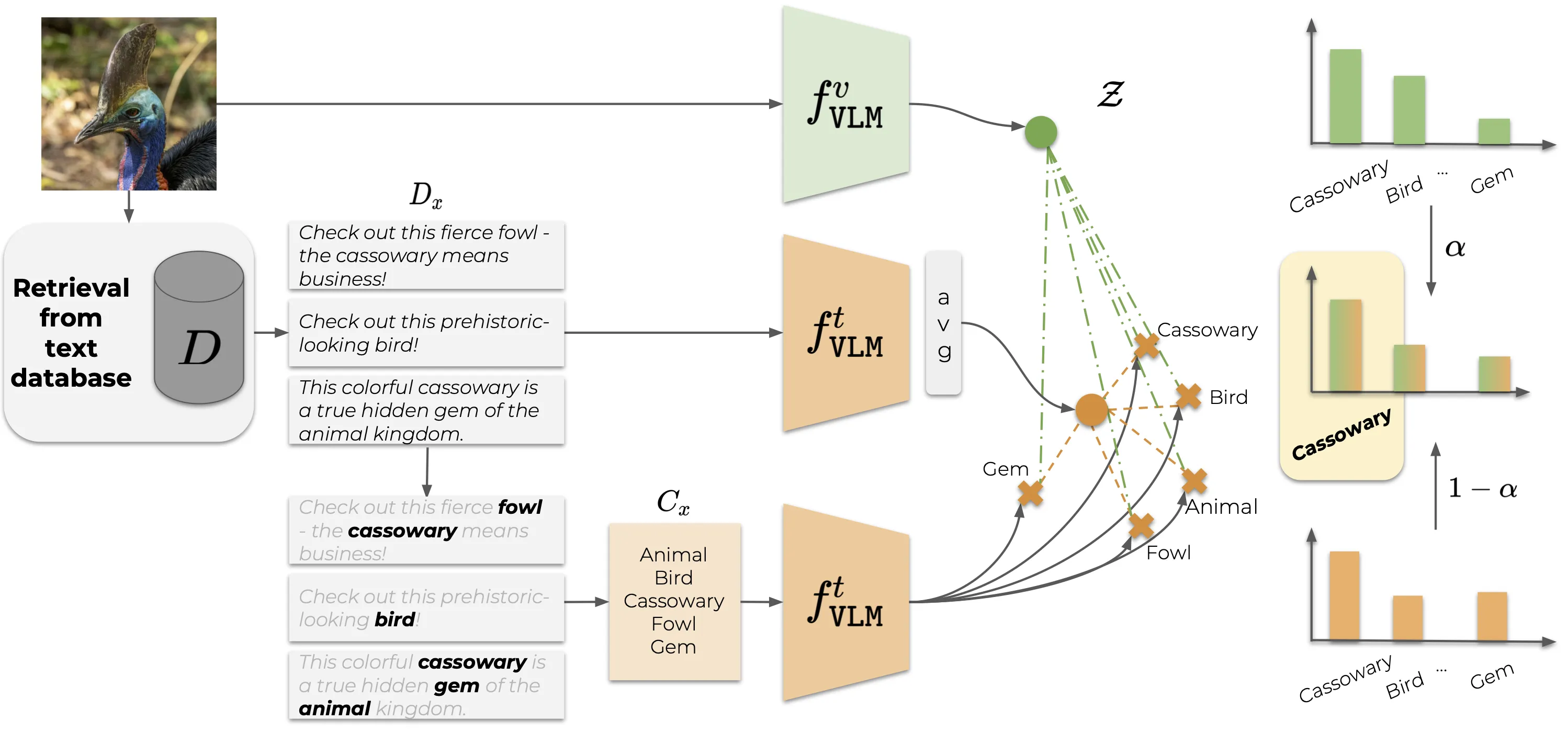 |
|---|
| Overview of CaSED. Given an input image, CaSED retrieves the most relevant captions from an external database filtering them to extract candidate categories. We classify image-to-text and text-to-text, using the retrieved captions centroid as the textual counterpart of the input image. |
Citation
If you find this work useful, please consider citing:
@article{conti2023vocabularyfree,
title={Vocabulary-free Image Classification},
author={Alessandro Conti and Enrico Fini and Massimiliano Mancini and Paolo Rota and Yiming Wang and Elisa Ricci},
year={2023},
journal={NeurIPS},
}