Spaces:
Paused

A newer version of the Gradio SDK is available:
4.39.0
LiLT
Overview
The LiLT model was proposed in LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding by Jiapeng Wang, Lianwen Jin, Kai Ding. LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable LayoutLM-like document understanding for many languages.
The abstract from the paper is the following:
Structured document understanding has attracted considerable attention and made significant progress recently, owing to its crucial role in intelligent document processing. However, most existing related models can only deal with the document data of specific language(s) (typically English) included in the pre-training collection, which is extremely limited. To address this issue, we propose a simple yet effective Language-independent Layout Transformer (LiLT) for structured document understanding. LiLT can be pre-trained on the structured documents of a single language and then directly fine-tuned on other languages with the corresponding off-the-shelf monolingual/multilingual pre-trained textual models. Experimental results on eight languages have shown that LiLT can achieve competitive or even superior performance on diverse widely-used downstream benchmarks, which enables language-independent benefit from the pre-training of document layout structure.
Tips:
- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the hub, refer to this guide.
The script will result in
config.jsonandpytorch_model.binfiles being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
from transformers import LiltModel
model = LiltModel.from_pretrained("path_to_your_files")
model.push_to_hub("name_of_repo_on_the_hub")
- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
- As lilt-roberta-en-base uses the same vocabulary as LayoutLMv3, one can use [
LayoutLMv3TokenizerFast] to prepare data for the model. The same is true for lilt-roberta-en-base: one can use [LayoutXLMTokenizerFast] for that model.
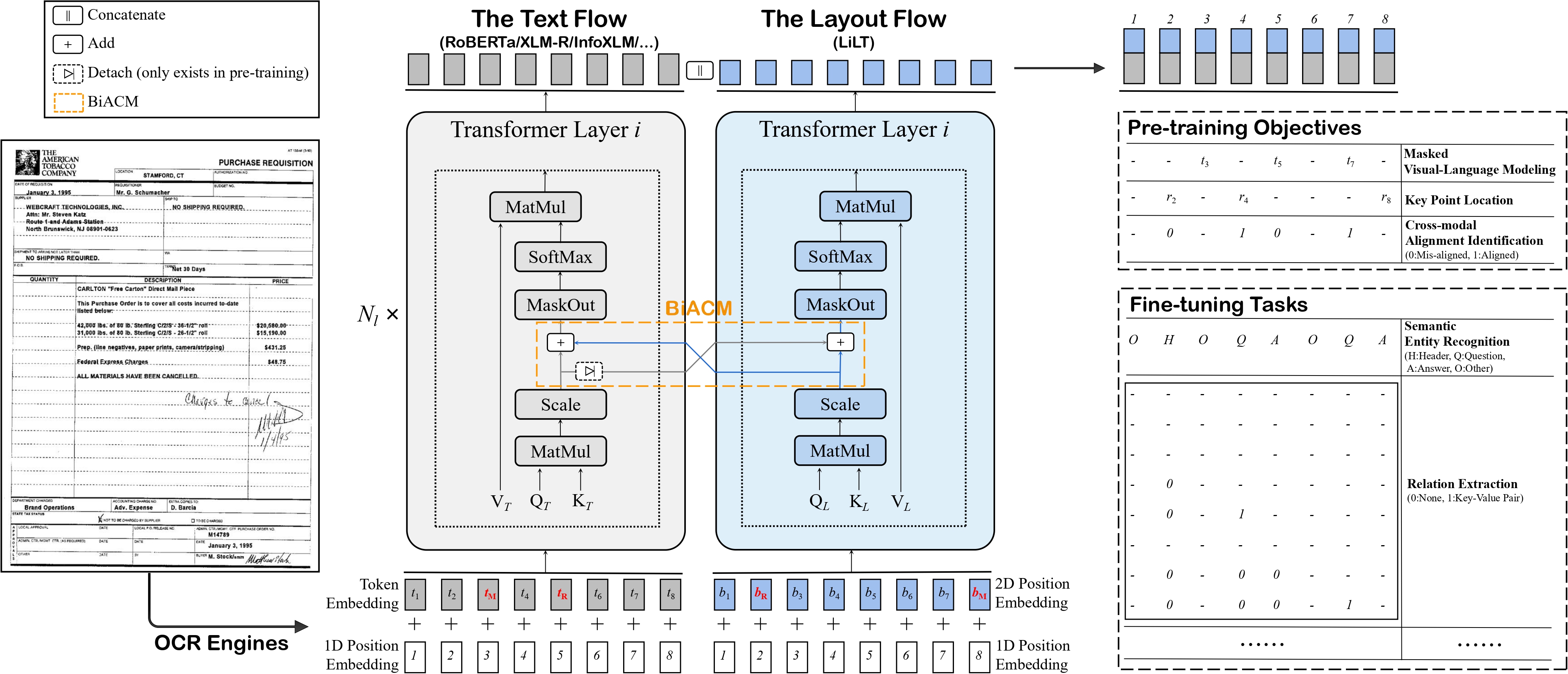
LiLT architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
- Demo notebooks for LiLT can be found here.
Documentation resources
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
LiltConfig
[[autodoc]] LiltConfig
LiltModel
[[autodoc]] LiltModel - forward
LiltForSequenceClassification
[[autodoc]] LiltForSequenceClassification - forward
LiltForTokenClassification
[[autodoc]] LiltForTokenClassification - forward
LiltForQuestionAnswering
[[autodoc]] LiltForQuestionAnswering - forward