Spaces:
Runtime error

Runtime error
Self-Chained Image-Language Model for Video Localization and Question Answering
- Authors: Shoubin Yu, Jaemin Cho, Prateek Yadav, Mohit Bansal
- arXiv
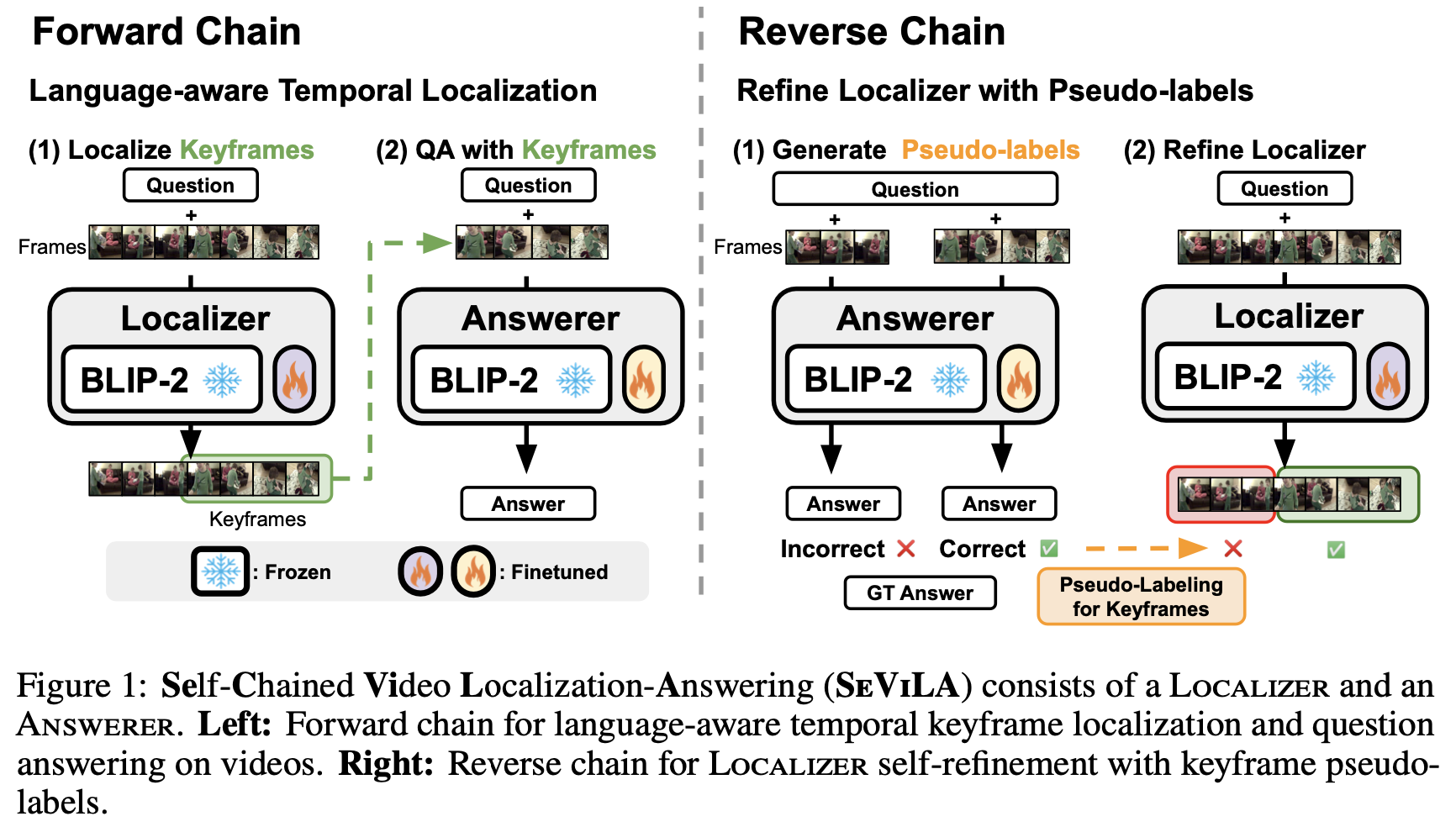
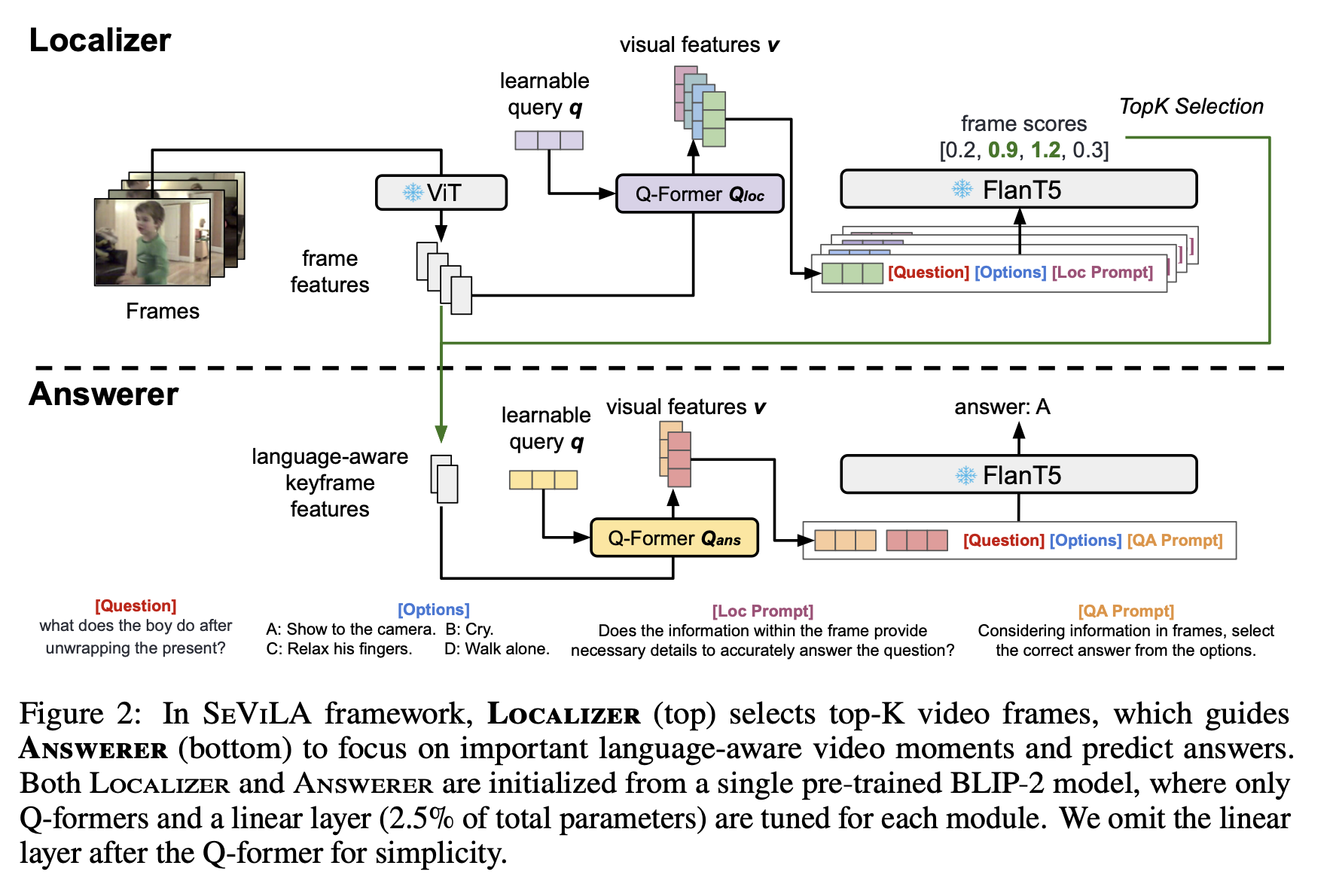
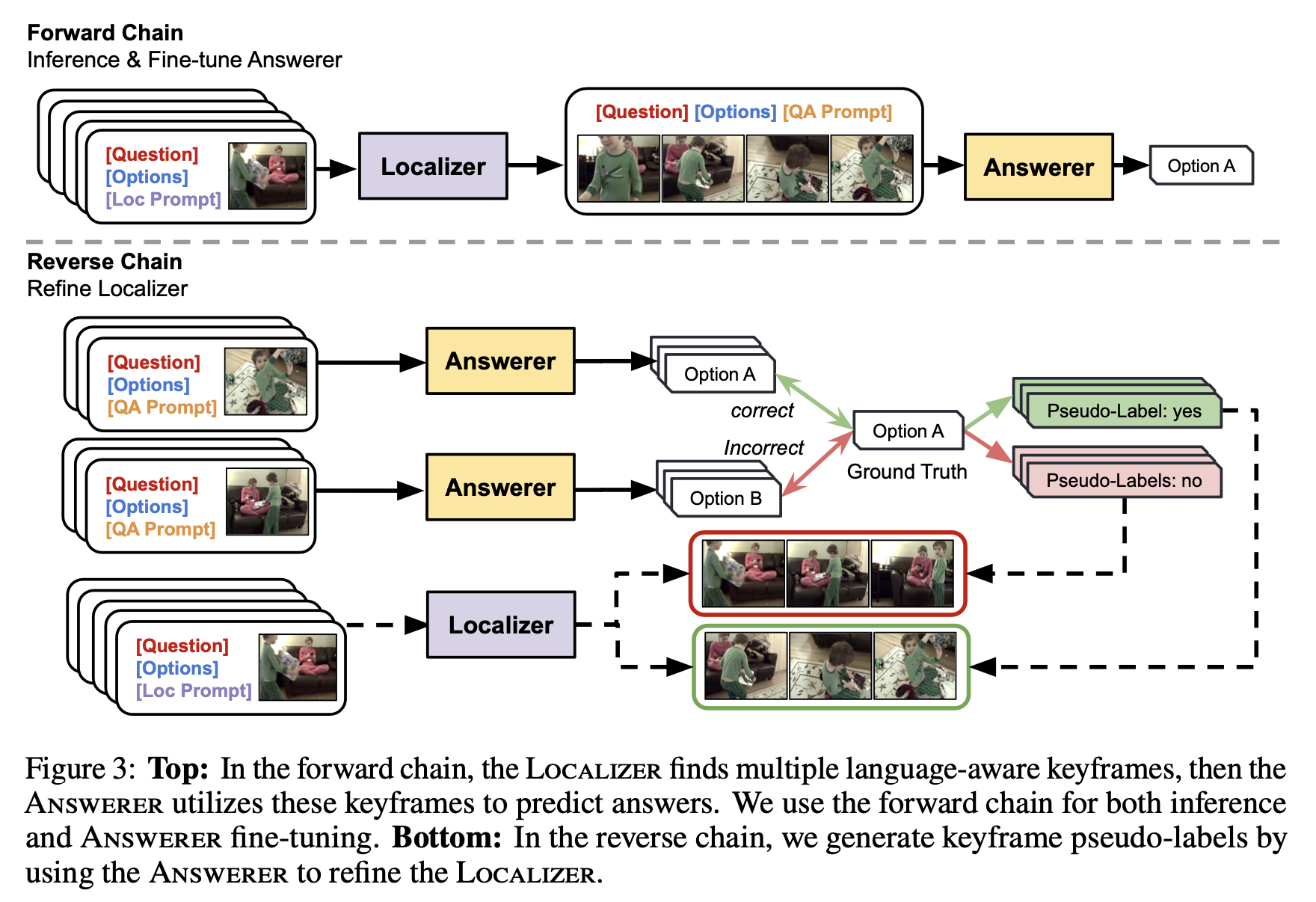
Code structure
# Data & Data Preprocessing
./sevila_data
# Pretrained Checkpoints
./sevila_checkpoints
# SeViLA code
./lavis/
# running scripts for SeViLa localizer/answerer training/inference
./run_scripts
Setup
Install Dependencies
- (Optional) Creating conda environment
conda create -n sevila python=3.8
conda activate sevila
- build from source
pip install -e .
Download Pretrained Models
We pre-train SeViLA localizer on QVHighlights and hold checkpoints via Huggingface. Download checkpoints and put it under /sevila_checkpoints. The checkpoints (814.55M) contains pre-trained localizer and zero-shot answerer.
Dataset Preparation
We test our model on:
please download original data and preprocess them via our scripts under ./sevila_data/ .
Training and Inference
We provideo SeViLA training and inference script examples as following:
1) Localizer Pre-training
sh run_scripts/sevila/pre-train/pretrain_qvh.sh
2) Localizer Self-refinement
sh run_scripts/sevila/refinement/nextqa_sr.sh
3) Answerer Fine-tuning
sh run_scripts/sevila/finetune/nextqa_ft.sh
4) Inference
sh run_scripts/sevila/inference/nextqa_infer.sh
Acknowledgments
We thank the developers of LAVIS, BLIP-2, CLIP, All-in-one, for their public code release.
Reference
Please cite our paper if you use our models in your works:
@misc{yu2023selfchained,
title={Self-Chained Image-Language Model for Video Localization and Question Answering},
author={Shoubin Yu and Jaemin Cho and Prateek Yadav and Mohit Bansal},
year={2023},
eprint={2305.06988},
archivePrefix={arXiv},
primaryClass={cs.CV}
}