Spaces:
Running
on
T4

A newer version of the Gradio SDK is available:
5.6.0
RAFT
This repository contains the source code for our paper:
RAFT: Recurrent All Pairs Field Transforms for Optical Flow
ECCV 2020
Zachary Teed and Jia Deng
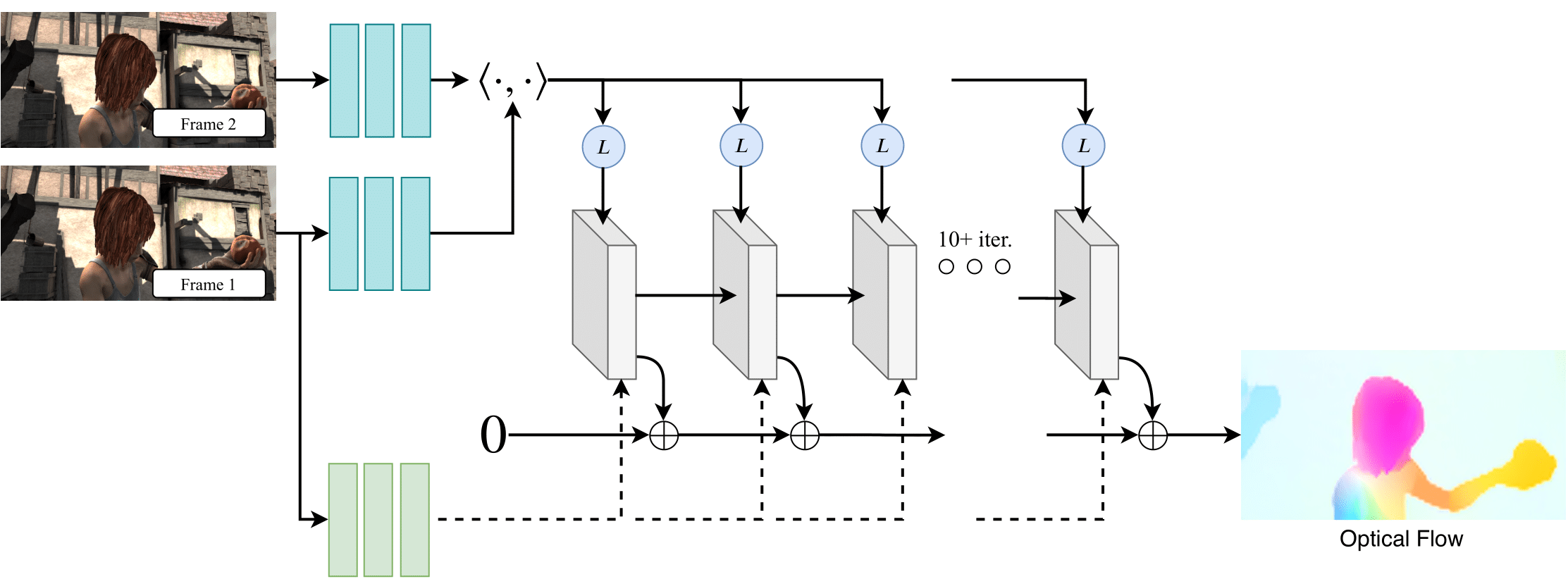
Requirements
The code has been tested with PyTorch 1.6 and Cuda 10.1.
conda create --name raft
conda activate raft
conda install pytorch=1.6.0 torchvision=0.7.0 cudatoolkit=10.1 matplotlib tensorboard scipy opencv -c pytorch
Demos
Pretrained models can be downloaded by running
./download_models.sh
or downloaded from google drive
You can demo a trained model on a sequence of frames
python demo.py --model=models/raft-things.pth --path=demo-frames
Required Data
To evaluate/train RAFT, you will need to download the required datasets.
- FlyingChairs
- FlyingThings3D
- Sintel
- KITTI
- HD1K (optional)
By default datasets.py will search for the datasets in these locations. You can create symbolic links to wherever the datasets were downloaded in the datasets folder
├── datasets
├── Sintel
├── test
├── training
├── KITTI
├── testing
├── training
├── devkit
├── FlyingChairs_release
├── data
├── FlyingThings3D
├── frames_cleanpass
├── frames_finalpass
├── optical_flow
Evaluation
You can evaluate a trained model using evaluate.py
python evaluate.py --model=models/raft-things.pth --dataset=sintel --mixed_precision
Training
We used the following training schedule in our paper (2 GPUs). Training logs will be written to the runs which can be visualized using tensorboard
./train_standard.sh
If you have a RTX GPU, training can be accelerated using mixed precision. You can expect similiar results in this setting (1 GPU)
./train_mixed.sh
(Optional) Efficent Implementation
You can optionally use our alternate (efficent) implementation by compiling the provided cuda extension
cd alt_cuda_corr && python setup.py install && cd ..
and running demo.py and evaluate.py with the --alternate_corr flag Note, this implementation is somewhat slower than all-pairs, but uses significantly less GPU memory during the forward pass.