Spaces:
Runtime error

AlignScore
This is the repository for AlignScore, a metric for automatic factual consistency evaluation of text pairs introduced in
AlignScore: Evaluating Factual Consistency with a Unified Alignment Function
Yuheng Zha, Yichi Yang, Ruichen Li and Zhiting Hu
ACL 2023
Factual consistency evaluation is to evaluate whether all the information in b is contained in a (b does not contradict a). For example, this is a factual inconsistent case:
- a: Children smiling and waving at camera.
- b: The kids are frowning.
And this is a factual consistent case:
- a: The NBA season of 1975 -- 76 was the 30th season of the National Basketball Association.
- b: The 1975 -- 76 season of the National Basketball Association was the 30th season of the NBA.
Factual consistency evaluation can be applied to many tasks like Summarization, Paraphrase and Dialog. For example, large language models often generate hallucinations when summarizing documents. We wonder if the generated text is factual consistent to its original context.
Leaderboards
We introduce two leaderboards that compare AlignScore with similar-sized metrics and LLM-based metrics, respectively.
Leaderboard --- compare with similar-sized metrics
We list the performance of AlignScore as well as other metrics on the SummaC (includes 6 datasets) and TRUE (includes 11 datasets) benchmarks, as well as other popular factual consistency datasets (include 6 datasets).
* SummaC Benchmark: [Paper] | [Github]. We report AUC ROC on the SummaC benchmark.
** TRUE Benchmark: [Paper] | [Github]. We report AUC ROC on the TRUE benchmark.
*** Besides the SummaC and TRUE benchmarks, we also include other popular factual consistency evaluation datasets: XSumFaith, SummEval, QAGS-XSum, QAGS-CNNDM, FRANK-XSum, FRANK-CNNDM and SamSum. We compute the Spearman Correlation coefficients between the human annotated score and the metric predicted score, following common practice.
**** To rank these metrics, we simply compute the average performance of SummaC, TRUE and Other Datasets.
Leaderboard --- compare with LLM-based metrics
We also show the performance comparison with large-language-model based metrics below. The rank is based on the average Spearman Correlation coefficients on SummEval, QAGS-XSum and QAGS-CNNDM datasets.*
| Rank | Metrics | Base Model | SummEval | QAGS-XSUM | QAGS-CNNDM | Average | Paper | Code |
|---|---|---|---|---|---|---|---|---|
| 1 | AlignScore-large | RoBERTa-l (355M) | 46.6 | 57.2 | 73.9 | 59.3 | :page_facing_up:(Zha et al. 2023) | :octocat: |
| 2 | G-EVAL-4 | GPT4 | 50.7 | 53.7 | 68.5 | 57.6 | :page_facing_up:(Liu et al. 2023) | :octocat: |
| 3 | AlignScore-base | RoBERTa-b (125M) | 43.4 | 51.9 | 69.0 | 54.8 | :page_facing_up:(Zha et al. 2023) | :octocat: |
| 4 | FActScore (modified)** | GPT3.5-d03 + GPT3.5-turbo | 52.6 | 51.2 | 57.6 | 53.8 | :page_facing_up:(Min et al. 2023) | :octocat:* |
| 5 | ChatGPT (Chen et al. 2023) | GPT3.5-turbo | 42.7 | 53.3 | 52.7 | 49.6 | :page_facing_up:(Yi Chen et al. 2023) | :octocat: |
| 6 | GPTScore | GPT3.5-d03 | 45.9 | 22.7 | 64.4 | 44.3 | :page_facing_up:(Fu et al. 2023) | :octocat: |
| 7 | GPTScore | GPT3-d01 | 46.1 | 22.3 | 63.9 | 44.1 | :page_facing_up:(Fu et al. 2023) | :octocat: |
| 8 | G-EVAL-3.5 | GPT3.5-d03 | 38.6 | 40.6 | 51.6 | 43.6 | :page_facing_up:(Liu et al. 2023) | :octocat: |
| 9 | ChatGPT (Gao et al. 2023) | GPT3.5-turbo | 41.6 | 30.4 | 48.9 | 40.3 | :page_facing_up:(Gao et al. 2023) | - |
* We notice that evaluating factual consistency using GPT-based models is expensive and slow. And we need human labor to interpret the response (generally text) to numerical scores. Therefore, we only benchmark on 3 popular factual consistency evaluation datasets: SummEval, QAGS-XSum and QAGS-CNNDM.
** We use a modified version of FActScore retrieval+ChatGPT where we skip the retrieval stage and use the context documents in SummEval, QAGS-XSUM, and QAGS-CNNDM directly. As samples in theses datasets do not have "topics", we make a small modification to the original FActScore prompt and do not mention topic when not available. See our fork of FActScore for more details.
Introduction
The AlignScore metric is an automatic factual consistency evaluation metric built with the following parts:
Unified information alignment function between two arbitrary text pieces: It is trained on 4.7 million training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic textual similarity and summarization)
The chunk-sentence splitting method: The input context is splitted into chunks (contains roughly 350 tokens each) and the input claim is splitted into sentences. With the help of the alignment function, it's possible to know the alignment score between chunks and sentences. We pick the maximum alignment score for each sentence and then average these scores to get the example-level factual consistency score (AlignScore).
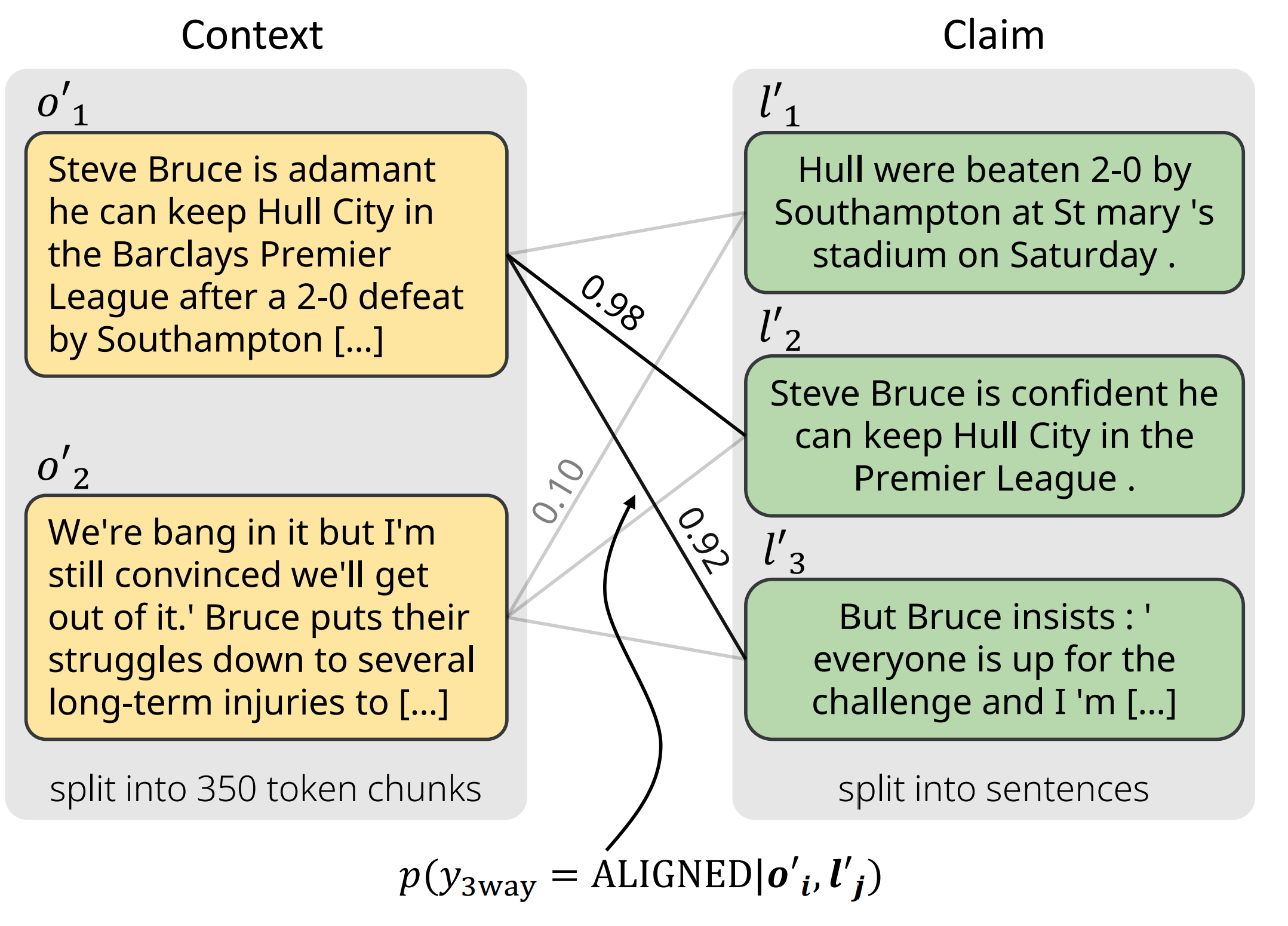
We assume there are two inputs to the metric, namely context and claim. And the metric evaluates whether the claim is factual consistent with the context. The output of AlignScore is a single numerical value, which shows the degree of the factual consistency.
Installation
Our models are trained and evaluated using PyTorch 1.12.1. We recommend using this version to reproduce the results.
- Please first install the right version of PyTorch before installing
alignscore. - You can install
alignscoreby cloning this repository andpip install .. - After installing
alignscore, please usepython -m spacy download en_core_web_smto install the required spaCy model (we usespaCyfor sentenization).
Evaluating Factual Consistency
To evaluate the factual consistency of the claim w.r.t. the context, simply use the score method of AlignScore.
from alignscore import AlignScore
scorer = AlignScore(model='roberta-base', batch_size=32, device='cuda:0', ckpt_path='/path/to/checkpoint', evaluation_mode='nli_sp')
score = scorer.score(contexts=['hello world.'], claims=['hello world.'])
model: the backbone model of the metric. Now, we only provide the metric trained on RoBERTa
batch_size: the batch size of the inference
device: which device to run the metric
ckpt_path: the path to the checkpoint
evaluation_mode: choose from 'nli_sp', 'nli', 'bin_sp', 'bin'. nli and bin refer to the 3-way and binary classficiation head, respectively. sp indicates if the chunk-sentence splitting method is used. nli_sp is the default setting of AlignScore
Checkpoints
We provide two versions of the AlignScore checkpoints: AlignScore-base and AlignScore-large. The -base model is based on RoBERTa-base and has 125M parameters. The -large model is based on RoBERTa-large and has 355M parameters.
AlignScore-base: https://huggingface.co/yzha/AlignScore/resolve/main/AlignScore-base.ckpt
AlignScore-large: https://huggingface.co/yzha/AlignScore/resolve/main/AlignScore-large.ckpt
Training
You can use the above checkpoints directly for factual consistency evaluation. However, if you wish to train an alignment model from scratch / on your own data, use train.py.
python train.py --seed 2022 --batch-size 32 \
--num-epoch 3 --devices 0 1 2 3 \
--model-name roberta-large -- ckpt-save-path ./ckpt/ \
--data-path ./data/training_sets/ \
--max-samples-per-dataset 500000
--seed: the random seed for initialization
--batch-size: the batch size for training
--num-epoch: training epochs
--devices: which devices to train the metric, a list of GPU ids
--model-name: the backbone model name of the metric, default RoBERTa-large
--ckpt-save-path: the path to save the checkpoint
--training-datasets: the names of the training datasets
--data-path: the path to the training datasets
--max-samples-per-dataset: the maximum number of samples from a dataset
Benchmarking
Our benchmark includes the TRUE and SummaC benchmark as well as several popular factual consistency evaluation datasets.
To run the benchmark, a few additional dependencies are required and can be installed with pip install -r requirements.txt.
Additionally, some depedencies are not available as packages and need to be downloaded manually (please see python benchmark.py --help for instructions).
Note installing summac may cause dependency conflicts with alignscore. Please reinstall alignscore to force the correct dependency versions.
The relevant arguments for evaluating AlignScore are:
--alignscore: evaluation the AlignScore metric
--alignscore-model: the name of the backbone model (either 'roberta-base' or 'roberta-large')
--alignscore-ckpt: the path to the saved checkpoint
--alignscore-eval-mode: the evaluation mode, defaults to nli_sp
--device: which device to run the metric, defaults to cuda:0
--tasks: which tasks to benchmark, e.g., SummEval, QAGS-CNNDM, ...
For the baselines, please see python benchmark.py --help for details.
Training datasets download
Most datasets are downloadable from Huggingface (refer to generate_training_data.py). Some datasets that needed to be imported manually are now also avaialable on Huggingface (See Issue).
Evaluation datasets download
The following table shows the links to the evaluation datasets mentioned in the paper
Citation
If you find the metric and this repo helpful, please consider cite:
@inproceedings{zha-etal-2023-alignscore,
title = "{A}lign{S}core: Evaluating Factual Consistency with A Unified Alignment Function",
author = "Zha, Yuheng and
Yang, Yichi and
Li, Ruichen and
Hu, Zhiting",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.634",
pages = "11328--11348",
abstract = "Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.",
}