Spaces:
Runtime error

Runtime error
Upload 15 files
Browse files- alignscore/LICENSE +21 -0
- alignscore/README.md +216 -0
- alignscore/alignscore_fig.png +0 -0
- alignscore/baselines.py +704 -0
- alignscore/benchmark.py +494 -0
- alignscore/evaluate.py +1793 -0
- alignscore/generate_training_data.py +1519 -0
- alignscore/pyproject.toml +41 -0
- alignscore/requirements.txt +9 -0
- alignscore/src/alignscore/__init__.py +1 -0
- alignscore/src/alignscore/alignscore.py +16 -0
- alignscore/src/alignscore/dataloader.py +610 -0
- alignscore/src/alignscore/inference.py +293 -0
- alignscore/src/alignscore/model.py +308 -0
- alignscore/train.py +144 -0
alignscore/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 yuh-zha
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
alignscore/README.md
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AlignScore
|
| 2 |
+
This is the repository for AlignScore, a metric for automatic factual consistency evaluation of text pairs introduced in \
|
| 3 |
+
[AlignScore: Evaluating Factual Consistency with a Unified Alignment Function](https://arxiv.org/abs/2305.16739) \
|
| 4 |
+
Yuheng Zha, Yichi Yang, Ruichen Li and Zhiting Hu \
|
| 5 |
+
ACL 2023
|
| 6 |
+
|
| 7 |
+
**Factual consistency evaluation** is to evaluate whether all the information in **b** is contained in **a** (**b** does not contradict **a**). For example, this is a factual inconsistent case:
|
| 8 |
+
|
| 9 |
+
* **a**: Children smiling and waving at camera.
|
| 10 |
+
* **b**: The kids are frowning.
|
| 11 |
+
|
| 12 |
+
And this is a factual consistent case:
|
| 13 |
+
|
| 14 |
+
* **a**: The NBA season of 1975 -- 76 was the 30th season of the National Basketball Association.
|
| 15 |
+
* **b**: The 1975 -- 76 season of the National Basketball Association was the 30th season of the NBA.
|
| 16 |
+
|
| 17 |
+
Factual consistency evaluation can be applied to many tasks like Summarization, Paraphrase and Dialog. For example, large language models often generate hallucinations when summarizing documents. We wonder if the generated text is factual consistent to its original context.
|
| 18 |
+
|
| 19 |
+
# Leaderboards
|
| 20 |
+
We introduce two leaderboards that compare AlignScore with similar-sized metrics and LLM-based metrics, respectively.
|
| 21 |
+
## Leaderboard --- compare with similar-sized metrics
|
| 22 |
+
|
| 23 |
+
We list the performance of AlignScore as well as other metrics on the SummaC (includes 6 datasets) and TRUE (includes 11 datasets) benchmarks, as well as other popular factual consistency datasets (include 6 datasets).
|
| 24 |
+
|
| 25 |
+
| Rank | Metrics | SummaC* | TRUE** | Other Datasets*** | Average**** | Paper | Code |
|
| 26 |
+
| ---- | :--------------- | :-----: | :----: | :------------: | :-----: | :---: | :--: |
|
| 27 |
+
| 1 | **AlignScore-large** | 88.6 | 83.8 | 49.3 | 73.9 | [:page\_facing\_up:(Zha et al. 2023)](https://arxiv.org/pdf/2305.16739.pdf) | [:octocat:](https://github.com/yuh-zha/AlignScore) |
|
| 28 |
+
| 2 | **AlignScore-base** | 87.4 | 82.5 | 44.9 | 71.6 | [:page\_facing\_up:(Zha et al. 2023)](https://arxiv.org/pdf/2305.16739.pdf) | [:octocat:](https://github.com/yuh-zha/AlignScore) |
|
| 29 |
+
| 3 | QAFactEval | 83.8 | 79.4 | 42.4 | 68.5 | [:page\_facing\_up:(Fabbri et al. 2022)](https://arxiv.org/abs/2112.08542) | [:octocat:](https://github.com/salesforce/QAFactEval) |
|
| 30 |
+
| 4 | UniEval | 84.6 | 78.0 | 41.5 | 68.0 | [:page\_facing\_up:(Zhong et al. 2022)](https://arxiv.org/abs/2210.07197) | [:octocat:](https://github.com/maszhongming/UniEval) |
|
| 31 |
+
| 5 | SummaC-CONV | 81.0 | 78.7 | 34.2 | 64.6 | [:page\_facing\_up:(Laban et al. 2022)](https://arxiv.org/abs/2111.09525) | [:octocat:](https://github.com/tingofurro/summac) |
|
| 32 |
+
| 6 | BARTScore | 80.9 | 73.4 | 34.8 | 63.0 | [:page\_facing\_up:(Yuan et al. 2022)](https://arxiv.org/abs/2106.11520) | [:octocat:](https://github.com/neulab/BARTScore) |
|
| 33 |
+
| 7 | CTC | 81.2 | 72.4 | 35.3 | 63.0 | [:page\_facing\_up:(Deng et al. 2022)](https://arxiv.org/abs/2109.06379) | [:octocat:](https://github.com/tanyuqian/ctc-gen-eval) |
|
| 34 |
+
| 8 | SummaC-ZS | 79.0 | 78.2 | 30.4 | 62.5 | [:page\_facing\_up:(Laban et al. 2022)](https://arxiv.org/abs/2111.09525) | [:octocat:](https://github.com/tingofurro/summac) |
|
| 35 |
+
| 9 | ROUGE-2 | 78.1 | 72.4 | 27.9 | 59.5 | [:page\_facing\_up:(Lin 2004)](https://aclanthology.org/W04-1013/) | [:octocat:](https://github.com/pltrdy/rouge) |
|
| 36 |
+
| 10 | ROUGE-1 | 77.4 | 72.0 | 28.6 | 59.3 | [:page\_facing\_up:(Lin 2004)](https://aclanthology.org/W04-1013/) | [:octocat:](https://github.com/pltrdy/rouge) |
|
| 37 |
+
| 11 | ROUGE-L | 77.3 | 71.8 | 28.3 | 59.1 | [:page\_facing\_up:(Lin 2004)](https://aclanthology.org/W04-1013/) | [:octocat:](https://github.com/pltrdy/rouge) |
|
| 38 |
+
| 12 | QuestEval | 72.5 | 71.4 | 25.0 | 56.3 | [:page\_facing\_up:(Scialom et al. 2021)](https://arxiv.org/abs/2103.12693) | [:octocat:](https://github.com/ThomasScialom/QuestEval) |
|
| 39 |
+
| 13 | BLEU | 76.3 | 67.3 | 24.6 | 56.1 | [:page\_facing\_up:(Papineni et al. 2002)](https://aclanthology.org/P02-1040/) | [:octocat:](https://www.nltk.org/_modules/nltk/translate/bleu_score.html) |
|
| 40 |
+
| 14 | DAE | 66.8 | 65.7 | 35.1 | 55.8 | [:page\_facing\_up:(Goyal and Durrett 2020)](https://aclanthology.org/2020.findings-emnlp.322/) | [:octocat:](https://github.com/tagoyal/dae-factuality) |
|
| 41 |
+
| 15 | BLEURT | 69.2 | 71.9 | 24.9 | 55.4 | [:page\_facing\_up:(Sellam et al. 2020)](https://arxiv.org/abs/2004.04696) | [:octocat:](https://github.com/google-research/bleurt) |
|
| 42 |
+
| 16 | BERTScore | 72.1 | 68.6 | 21.9 | 54.2 | [:page\_facing\_up:(Zhang et al. 2020)](https://arxiv.org/abs/1904.09675) | [:octocat:](https://github.com/Tiiiger/bert_score) |
|
| 43 |
+
| 17 | SimCSE | 67.4 | 70.3 | 23.8 | 53.8 | [:page\_facing\_up:(Gao et al. 2021)](https://arxiv.org/abs/2104.08821) | [:octocat:](https://github.com/princeton-nlp/SimCSE) |
|
| 44 |
+
| 18 | FactCC | 68.8 | 62.7 | 21.2 | 50.9 | [:page\_facing\_up:(Kryscinski et al. 2020)](https://arxiv.org/abs/1910.12840) | [:octocat:](https://github.com/salesforce/factCC) |
|
| 45 |
+
| 19 | BLANC | 65.1 | 64.0 | 14.4 | 47.8 | [:page\_facing\_up:(Vasilyev et al. 2020)](https://arxiv.org/abs/2002.09836) | [:octocat:](https://github.com/PrimerAI/blanc) |
|
| 46 |
+
| 20 | NER-Overlap | 60.4 | 59.3 | 18.9 | 46.2 | [:page\_facing\_up:(Laban et al. 2022)](https://arxiv.org/abs/2111.09525) | [:octocat:](https://github.com/tingofurro/summac) |
|
| 47 |
+
| 21 | MNLI | 47.9 | 60.4 | 3.1 | 37.2 | [:page\_facing\_up:(Williams et al. 2018)](https://arxiv.org/abs/1704.05426) | [:octocat:](https://github.com/nyu-mll/multiNLI) |
|
| 48 |
+
| 22 | FEQA | 48.3 | 52.2 | -1.9 | 32.9 | [:page\_facing\_up:(Durmus et al. 2020)](https://arxiv.org/abs/2005.03754) | [:octocat:](https://github.com/esdurmus/feqa) |
|
| 49 |
+
|
| 50 |
+
\* SummaC Benchmark: [\[Paper\]](https://arxiv.org/abs/2111.09525) \| [\[Github\]](https://github.com/tingofurro/summac). We report AUC ROC on the SummaC benchmark.
|
| 51 |
+
|
| 52 |
+
** TRUE Benchmark: [\[Paper\]](https://arxiv.org/abs/2204.04991) \| [\[Github\]](https://github.com/google-research/true). We report AUC ROC on the TRUE benchmark.
|
| 53 |
+
|
| 54 |
+
*** Besides the SummaC and TRUE benchmarks, we also include other popular factual consistency evaluation datasets: [XSumFaith](https://doi.org/10.18653/v1/2020.acl-main.173), [SummEval](https://doi.org/10.1162/tacl_a_00373), [QAGS-XSum](https://doi.org/10.18653/v1/2020.acl-main.450), [QAGS-CNNDM](https://doi.org/10.18653/v1/2020.acl-main.450), [FRANK-XSum](https://doi.org/10.18653/v1/2021.naacl-main.383), [FRANK-CNNDM](https://doi.org/10.18653/v1/2021.naacl-main.383) and [SamSum](https://doi.org/10.18653/v1/D19-5409). We compute the Spearman Correlation coefficients between the human annotated score and the metric predicted score, following common practice.
|
| 55 |
+
|
| 56 |
+
**** To rank these metrics, we simply compute the average performance of SummaC, TRUE and Other Datasets.
|
| 57 |
+
|
| 58 |
+
## Leaderboard --- compare with LLM-based metrics
|
| 59 |
+
|
| 60 |
+
We also show the performance comparison with large-language-model based metrics below. The rank is based on the average Spearman Correlation coefficients on SummEval, QAGS-XSum and QAGS-CNNDM datasets.*
|
| 61 |
+
|
| 62 |
+
| Rank | Metrics | Base Model | SummEval | QAGS-XSUM | QAGS-CNNDM | Average | Paper | Code |
|
| 63 |
+
| :--- | :-------------------- | :----------------------------------------------------------- | :------: | :-------: | :--------: | :--: | :----------------------------------------------------------: | :----------------------------------------------------------: |
|
| 64 |
+
| 1 | **AlignScore-large** | RoBERTa-l (355M) | 46.6 | 57.2 | 73.9 | 59.3 | [:page\_facing\_up:(Zha et al. 2023)](https://arxiv.org/pdf/2305.16739.pdf) | [:octocat:](https://github.com/yuh-zha/AlignScore) |
|
| 65 |
+
| 2 | G-EVAL-4 | GPT4 | 50.7 | 53.7 | 68.5 | 57.6 | [:page\_facing\_up:(Liu et al. 2023)](https://arxiv.org/pdf/2303.16634.pdf) | [:octocat:](https://github.com/nlpyang/geval) |
|
| 66 |
+
| 3 | **AlignScore-base** | RoBERTa-b (125M) | 43.4 | 51.9 | 69.0 | 54.8 | [:page\_facing\_up:(Zha et al. 2023)](https://arxiv.org/pdf/2305.16739.pdf) | [:octocat:](https://github.com/yuh-zha/AlignScore) |
|
| 67 |
+
| 4 | FActScore (modified)** | GPT3.5-d03 + GPT3.5-turbo | 52.6 | 51.2 | 57.6 | 53.8 | [:page\_facing\_up:(Min et al. 2023)](https://arxiv.org/pdf/2305.14251.pdf) | [:octocat:](https://github.com/shmsw25/FActScore)* |
|
| 68 |
+
| 5 | ChatGPT (Chen et al. 2023) | GPT3.5-turbo | 42.7 | 53.3 | 52.7 | 49.6 | [:page\_facing\_up:(Yi Chen et al. 2023)](https://arxiv.org/pdf/2305.14069.pdf) | [:octocat:](https://github.com/SJTU-LIT/llmeval_sum_factual) |
|
| 69 |
+
| 6 | GPTScore | GPT3.5-d03 | 45.9 | 22.7 | 64.4 | 44.3 | [:page\_facing\_up:(Fu et al. 2023)](https://arxiv.org/pdf/2302.04166.pdf) | [:octocat:](https://github.com/jinlanfu/GPTScore) |
|
| 70 |
+
| 7 | GPTScore | GPT3-d01 | 46.1 | 22.3 | 63.9 | 44.1 | [:page\_facing\_up:(Fu et al. 2023)](https://arxiv.org/pdf/2302.04166.pdf) | [:octocat:](https://github.com/jinlanfu/GPTScore) |
|
| 71 |
+
| 8 | G-EVAL-3.5 | GPT3.5-d03 | 38.6 | 40.6 | 51.6 | 43.6 | [:page\_facing\_up:(Liu et al. 2023)](https://arxiv.org/pdf/2303.16634.pdf) | [:octocat:](https://github.com/nlpyang/geval) |
|
| 72 |
+
| 9 | ChatGPT (Gao et al. 2023) | GPT3.5-turbo | 41.6 | 30.4 | 48.9 | 40.3 | [:page\_facing\_up:(Gao et al. 2023)](https://arxiv.org/pdf/2304.02554.pdf) | - |
|
| 73 |
+
|
| 74 |
+
\* We notice that evaluating factual consistency using GPT-based models is expensive and slow. And we need human labor to interpret the response (generally text) to numerical scores. Therefore, we only benchmark on 3 popular factual consistency evaluation datasets: SummEval, QAGS-XSum and QAGS-CNNDM.
|
| 75 |
+
|
| 76 |
+
*\* We use a modified version of FActScore `retrieval+ChatGPT` where we skip the retrieval stage and use the context documents in SummEval, QAGS-XSUM, and QAGS-CNNDM directly. As samples in theses datasets do not have "topics", we make a small modification to the original FActScore prompt and do not mention `topic` when not available. See [our fork of FActScore](https://github.com/yichi-yang/FActScore) for more details.
|
| 77 |
+
|
| 78 |
+
# Introduction
|
| 79 |
+
|
| 80 |
+
The AlignScore metric is an automatic factual consistency evaluation metric built with the following parts:
|
| 81 |
+
|
| 82 |
+
* Unified information alignment function between two arbitrary text pieces: It is trained on 4.7 million training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic textual similarity and summarization)
|
| 83 |
+
|
| 84 |
+
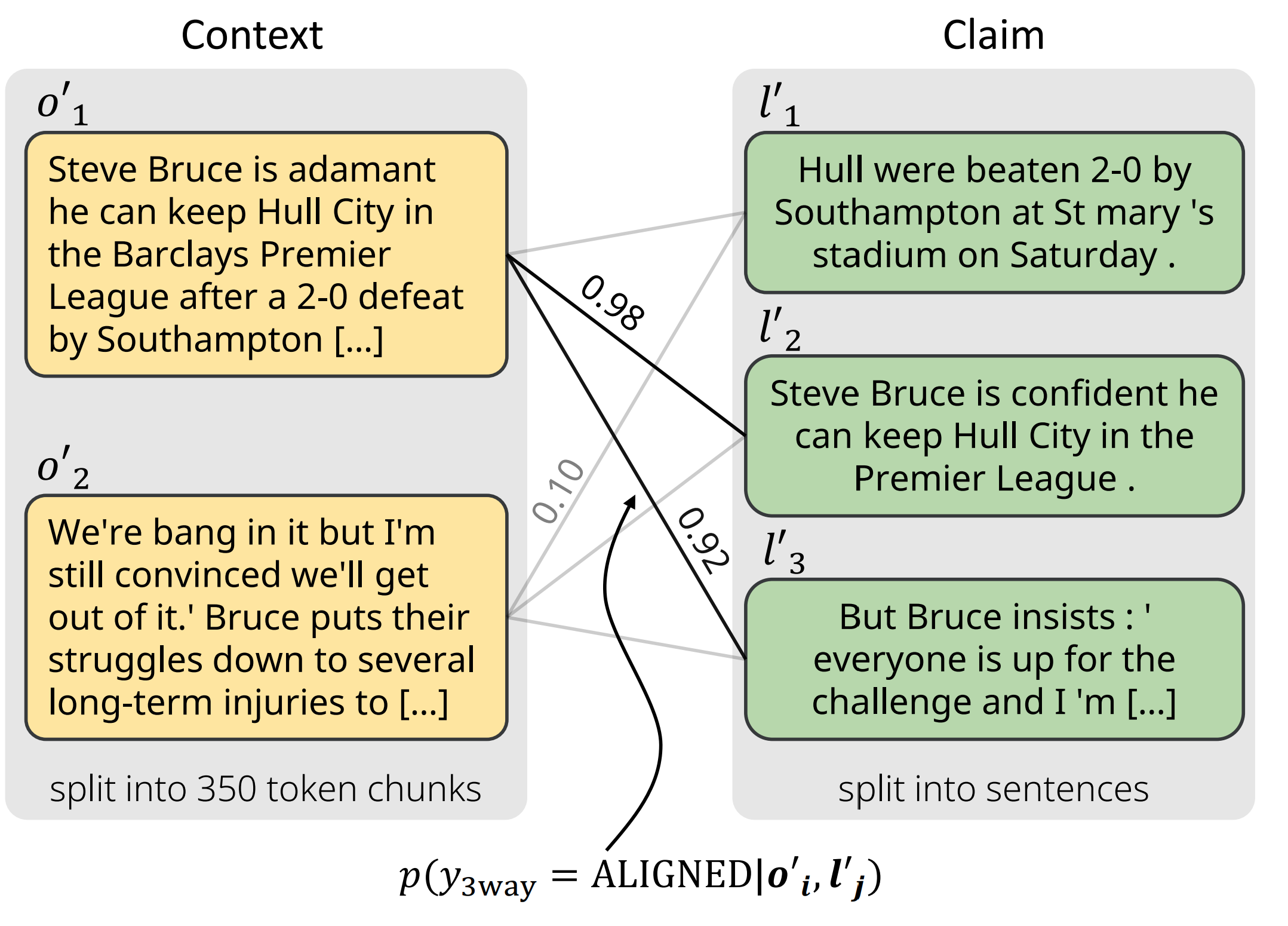
* The chunk-sentence splitting method: The input context is splitted into chunks (contains roughly 350 tokens each) and the input claim is splitted into sentences. With the help of the alignment function, it's possible to know the alignment score between chunks and sentences. We pick the maximum alignment score for each sentence and then average these scores to get the example-level factual consistency score (AlignScore).
|
| 85 |
+
|
| 86 |
+
<div align=center>
|
| 87 |
+
<img src="./alignscore_fig.png" alt="alignscore_fig" width="500px" />
|
| 88 |
+
</div>
|
| 89 |
+
|
| 90 |
+
We assume there are two inputs to the metric, namely `context` and `claim`. And the metric evaluates whether the `claim` is factual consistent with the `context`. The output of AlignScore is a single numerical value, which shows the degree of the factual consistency.
|
| 91 |
+
# Installation
|
| 92 |
+
|
| 93 |
+
Our models are trained and evaluated using PyTorch 1.12.1. We recommend using this version to reproduce the results.
|
| 94 |
+
|
| 95 |
+
1. Please first install the right version of PyTorch before installing `alignscore`.
|
| 96 |
+
2. You can install `alignscore` by cloning this repository and `pip install .`.
|
| 97 |
+
3. After installing `alignscore`, please use `python -m spacy download en_core_web_sm` to install the required spaCy model (we use `spaCy` for sentenization).
|
| 98 |
+
|
| 99 |
+
# Evaluating Factual Consistency
|
| 100 |
+
To evaluate the factual consistency of the `claim` w.r.t. the `context`, simply use the score method of `AlignScore`.
|
| 101 |
+
```python
|
| 102 |
+
from alignscore import AlignScore
|
| 103 |
+
|
| 104 |
+
scorer = AlignScore(model='roberta-base', batch_size=32, device='cuda:0', ckpt_path='/path/to/checkpoint', evaluation_mode='nli_sp')
|
| 105 |
+
score = scorer.score(contexts=['hello world.'], claims=['hello world.'])
|
| 106 |
+
```
|
| 107 |
+
`model`: the backbone model of the metric. Now, we only provide the metric trained on RoBERTa
|
| 108 |
+
|
| 109 |
+
`batch_size`: the batch size of the inference
|
| 110 |
+
|
| 111 |
+
`device`: which device to run the metric
|
| 112 |
+
|
| 113 |
+
`ckpt_path`: the path to the checkpoint
|
| 114 |
+
|
| 115 |
+
`evaluation_mode`: choose from `'nli_sp', 'nli', 'bin_sp', 'bin'`. `nli` and `bin` refer to the 3-way and binary classficiation head, respectively. `sp` indicates if the chunk-sentence splitting method is used. `nli_sp` is the default setting of AlignScore
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
# Checkpoints
|
| 119 |
+
We provide two versions of the AlignScore checkpoints: `AlignScore-base` and `AlignScore-large`. The `-base` model is based on RoBERTa-base and has 125M parameters. The `-large` model is based on RoBERTa-large and has 355M parameters.
|
| 120 |
+
|
| 121 |
+
**AlignScore-base**:
|
| 122 |
+
https://huggingface.co/yzha/AlignScore/resolve/main/AlignScore-base.ckpt
|
| 123 |
+
|
| 124 |
+
**AlignScore-large**:
|
| 125 |
+
https://huggingface.co/yzha/AlignScore/resolve/main/AlignScore-large.ckpt
|
| 126 |
+
|
| 127 |
+
# Training
|
| 128 |
+
You can use the above checkpoints directly for factual consistency evaluation. However, if you wish to train an alignment model from scratch / on your own data, use `train.py`.
|
| 129 |
+
```python
|
| 130 |
+
python train.py --seed 2022 --batch-size 32 \
|
| 131 |
+
--num-epoch 3 --devices 0 1 2 3 \
|
| 132 |
+
--model-name roberta-large -- ckpt-save-path ./ckpt/ \
|
| 133 |
+
--data-path ./data/training_sets/ \
|
| 134 |
+
--max-samples-per-dataset 500000
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
`--seed`: the random seed for initialization
|
| 138 |
+
|
| 139 |
+
`--batch-size`: the batch size for training
|
| 140 |
+
|
| 141 |
+
`--num-epoch`: training epochs
|
| 142 |
+
|
| 143 |
+
`--devices`: which devices to train the metric, a list of GPU ids
|
| 144 |
+
|
| 145 |
+
`--model-name`: the backbone model name of the metric, default RoBERTa-large
|
| 146 |
+
|
| 147 |
+
`--ckpt-save-path`: the path to save the checkpoint
|
| 148 |
+
|
| 149 |
+
`--training-datasets`: the names of the training datasets
|
| 150 |
+
|
| 151 |
+
`--data-path`: the path to the training datasets
|
| 152 |
+
|
| 153 |
+
`--max-samples-per-dataset`: the maximum number of samples from a dataset
|
| 154 |
+
|
| 155 |
+
# Benchmarking
|
| 156 |
+
Our benchmark includes the TRUE and SummaC benchmark as well as several popular factual consistency evaluation datasets.
|
| 157 |
+
|
| 158 |
+
To run the benchmark, a few additional dependencies are required and can be installed with `pip install -r requirements.txt`.
|
| 159 |
+
Additionally, some depedencies are not available as packages and need to be downloaded manually (please see `python benchmark.py --help` for instructions).
|
| 160 |
+
|
| 161 |
+
Note installing `summac` may cause dependency conflicts with `alignscore`. Please reinstall `alignscore` to force the correct dependency versions.
|
| 162 |
+
|
| 163 |
+
The relevant arguments for evaluating AlignScore are:
|
| 164 |
+
|
| 165 |
+
`--alignscore`: evaluation the AlignScore metric
|
| 166 |
+
|
| 167 |
+
`--alignscore-model`: the name of the backbone model (either 'roberta-base' or 'roberta-large')
|
| 168 |
+
|
| 169 |
+
`--alignscore-ckpt`: the path to the saved checkpoint
|
| 170 |
+
|
| 171 |
+
`--alignscore-eval-mode`: the evaluation mode, defaults to `nli_sp`
|
| 172 |
+
|
| 173 |
+
`--device`: which device to run the metric, defaults to `cuda:0`
|
| 174 |
+
|
| 175 |
+
`--tasks`: which tasks to benchmark, e.g., SummEval, QAGS-CNNDM, ...
|
| 176 |
+
|
| 177 |
+
For the baselines, please see `python benchmark.py --help` for details.
|
| 178 |
+
|
| 179 |
+
## Training datasets download
|
| 180 |
+
Most datasets are downloadable from Huggingface (refer to [`generate_training_data.py`](https://github.com/yuh-zha/AlignScore/blob/main/generate_training_data.py)). Some datasets that needed to be imported manually are now also avaialable on Huggingface (See [Issue](https://github.com/yuh-zha/AlignScore/issues/6#issuecomment-1695448614)).
|
| 181 |
+
|
| 182 |
+
## Evaluation datasets download
|
| 183 |
+
|
| 184 |
+
The following table shows the links to the evaluation datasets mentioned in the paper
|
| 185 |
+
|
| 186 |
+
| Benchmark/Dataset | Link |
|
| 187 |
+
| ----------------- | ------------------------------------------------------------ |
|
| 188 |
+
| SummaC | https://github.com/tingofurro/summac |
|
| 189 |
+
| TRUE | https://github.com/google-research/true |
|
| 190 |
+
| XSumFaith | https://github.com/google-research-datasets/xsum_hallucination_annotations |
|
| 191 |
+
| SummEval | https://github.com/tanyuqian/ctc-gen-eval/blob/master/train/data/summeval.json |
|
| 192 |
+
| QAGS-Xsum | https://github.com/tanyuqian/ctc-gen-eval/blob/master/train/data/qags_xsum.json |
|
| 193 |
+
| QAGS-CNNDM | https://github.com/tanyuqian/ctc-gen-eval/blob/master/train/data/qags_cnndm.json |
|
| 194 |
+
| FRANK-XSum | https://github.com/artidoro/frank |
|
| 195 |
+
| FRANK-CNNDM | https://github.com/artidoro/frank |
|
| 196 |
+
| SamSum | https://github.com/skgabriel/GoFigure/blob/main/human_eval/samsum.jsonl |
|
| 197 |
+
|
| 198 |
+
# Citation
|
| 199 |
+
If you find the metric and this repo helpful, please consider cite:
|
| 200 |
+
```
|
| 201 |
+
@inproceedings{zha-etal-2023-alignscore,
|
| 202 |
+
title = "{A}lign{S}core: Evaluating Factual Consistency with A Unified Alignment Function",
|
| 203 |
+
author = "Zha, Yuheng and
|
| 204 |
+
Yang, Yichi and
|
| 205 |
+
Li, Ruichen and
|
| 206 |
+
Hu, Zhiting",
|
| 207 |
+
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
|
| 208 |
+
month = jul,
|
| 209 |
+
year = "2023",
|
| 210 |
+
address = "Toronto, Canada",
|
| 211 |
+
publisher = "Association for Computational Linguistics",
|
| 212 |
+
url = "https://aclanthology.org/2023.acl-long.634",
|
| 213 |
+
pages = "11328--11348",
|
| 214 |
+
abstract = "Many text generation applications require the generated text to be factually consistent with input information. Automatic evaluation of factual consistency is challenging. Previous work has developed various metrics that often depend on specific functions, such as natural language inference (NLI) or question answering (QA), trained on limited data. Those metrics thus can hardly assess diverse factual inconsistencies (e.g., contradictions, hallucinations) that occur in varying inputs/outputs (e.g., sentences, documents) from different tasks. In this paper, we propose AlignScore, a new holistic metric that applies to a variety of factual inconsistency scenarios as above. AlignScore is based on a general function of information alignment between two arbitrary text pieces. Crucially, we develop a unified training framework of the alignment function by integrating a large diversity of data sources, resulting in 4.7M training examples from 7 well-established tasks (NLI, QA, paraphrasing, fact verification, information retrieval, semantic similarity, and summarization). We conduct extensive experiments on large-scale benchmarks including 22 evaluation datasets, where 19 of the datasets were never seen in the alignment training. AlignScore achieves substantial improvement over a wide range of previous metrics. Moreover, AlignScore (355M parameters) matches or even outperforms metrics based on ChatGPT and GPT-4 that are orders of magnitude larger.",
|
| 215 |
+
}
|
| 216 |
+
```
|
alignscore/alignscore_fig.png
ADDED
|
alignscore/baselines.py
ADDED
|
@@ -0,0 +1,704 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from logging import warning
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import numpy as np
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
import spacy
|
| 7 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 8 |
+
from nltk.tokenize import sent_tokenize
|
| 9 |
+
import json
|
| 10 |
+
|
| 11 |
+
class CTCScorer():
|
| 12 |
+
def __init__(self, model_type) -> None:
|
| 13 |
+
self.model_type = model_type
|
| 14 |
+
import nltk
|
| 15 |
+
nltk.download('stopwords')
|
| 16 |
+
|
| 17 |
+
from ctc_score import StyleTransferScorer, SummarizationScorer, DialogScorer
|
| 18 |
+
if model_type == 'D-cnndm':
|
| 19 |
+
self.scorer = SummarizationScorer(align='D-cnndm')
|
| 20 |
+
elif model_type =='E-roberta':
|
| 21 |
+
self.scorer = SummarizationScorer(align='E-roberta')
|
| 22 |
+
elif model_type == 'R-cnndm':
|
| 23 |
+
self.scorer = SummarizationScorer(align='R-cnndm')
|
| 24 |
+
def score(self, premise: list, hypo: list):
|
| 25 |
+
assert len(premise) == len(hypo), "Premise and hypothesis should have the same length"
|
| 26 |
+
|
| 27 |
+
output_scores = []
|
| 28 |
+
for one_pre, one_hypo in tqdm(zip(premise, hypo), total=len(premise), desc="Evaluating by ctc"):
|
| 29 |
+
score_for_this_example = self.scorer.score(doc=one_pre, refs=[], hypo=one_hypo, aspect='consistency')
|
| 30 |
+
if score_for_this_example is not None:
|
| 31 |
+
output_scores.append(score_for_this_example)
|
| 32 |
+
else:
|
| 33 |
+
output_scores.append(1e-8)
|
| 34 |
+
output = None, torch.tensor(output_scores), None
|
| 35 |
+
|
| 36 |
+
return output
|
| 37 |
+
|
| 38 |
+
class SimCSEScorer():
|
| 39 |
+
def __init__(self, model_type, device) -> None:
|
| 40 |
+
self.model_type = model_type
|
| 41 |
+
self.device = device
|
| 42 |
+
from transformers import AutoModel, AutoTokenizer
|
| 43 |
+
|
| 44 |
+
# refer to the model list on https://github.com/princeton-nlp/SimCSE for the list of models
|
| 45 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model_type)
|
| 46 |
+
self.model = AutoModel.from_pretrained(model_type).to(self.device)
|
| 47 |
+
self.spacy = spacy.load('en_core_web_sm')
|
| 48 |
+
|
| 49 |
+
self.batch_size = 64
|
| 50 |
+
|
| 51 |
+
def score(self, premise: list, hypo: list):
|
| 52 |
+
assert len(premise) == len(hypo)
|
| 53 |
+
|
| 54 |
+
output_scores = []
|
| 55 |
+
premise_sents = []
|
| 56 |
+
premise_index = [0]
|
| 57 |
+
hypo_sents = []
|
| 58 |
+
hypo_index = [0]
|
| 59 |
+
|
| 60 |
+
for one_pre, one_hypo in tqdm(zip(premise, hypo), desc="Sentenizing", total=len(premise)):
|
| 61 |
+
premise_sent = sent_tokenize(one_pre) #[each.text for each in self.spacy(one_pre).sents]
|
| 62 |
+
hypo_sent = sent_tokenize(one_hypo) #[each.text for each in self.spacy(one_hypo).sents]
|
| 63 |
+
premise_sents.extend(premise_sent)
|
| 64 |
+
premise_index.append(len(premise_sents))
|
| 65 |
+
|
| 66 |
+
hypo_sents.extend(hypo_sent)
|
| 67 |
+
hypo_index.append(len(hypo_sents))
|
| 68 |
+
|
| 69 |
+
all_sents = premise_sents + hypo_sents
|
| 70 |
+
embeddings = []
|
| 71 |
+
with torch.no_grad():
|
| 72 |
+
for batch in tqdm(self.chunks(all_sents, self.batch_size), total=int(len(all_sents)/self.batch_size), desc="Evaluating by SimCSE"):
|
| 73 |
+
inputs = self.tokenizer(batch, padding=True, truncation=True, return_tensors="pt").to(self.device)
|
| 74 |
+
embeddings.append(self.model(**inputs, output_hidden_states=True, return_dict=True).pooler_output)
|
| 75 |
+
embeddings = torch.cat(embeddings)
|
| 76 |
+
|
| 77 |
+
assert len(premise_index) == len(hypo_index)
|
| 78 |
+
for i in range(len(premise_index)-1):
|
| 79 |
+
premise_embeddings = embeddings[premise_index[i]: premise_index[i+1]]
|
| 80 |
+
hypo_embeddings = embeddings[len(premise_sents)+hypo_index[i]:len(premise_sents)+hypo_index[i+1]]
|
| 81 |
+
cos_sim = cosine_similarity(premise_embeddings.cpu(), hypo_embeddings.cpu())
|
| 82 |
+
score_p = cos_sim.max(axis=0).mean()
|
| 83 |
+
score_r = cos_sim.max(axis=1).mean()
|
| 84 |
+
score_f = 2 * score_p * score_r / (score_p + score_r)
|
| 85 |
+
output_scores.append(score_f)
|
| 86 |
+
|
| 87 |
+
return torch.Tensor(output_scores), torch.Tensor(output_scores), None
|
| 88 |
+
|
| 89 |
+
def chunks(self, lst, n):
|
| 90 |
+
"""Yield successive n-sized chunks from lst."""
|
| 91 |
+
for i in range(0, len(lst), n):
|
| 92 |
+
yield lst[i:i + n]
|
| 93 |
+
|
| 94 |
+
class BleurtScorer():
|
| 95 |
+
def __init__(self, checkpoint) -> None:
|
| 96 |
+
self.checkpoint = checkpoint
|
| 97 |
+
|
| 98 |
+
from bleurt import score
|
| 99 |
+
# BLEURT-20 can also be switched to other checkpoints to improve time
|
| 100 |
+
# No avaliable api to specify cuda number
|
| 101 |
+
self.model = score.BleurtScorer(self.checkpoint)
|
| 102 |
+
|
| 103 |
+
def scorer(self, premise:list, hypo: list):
|
| 104 |
+
assert len(premise) == len(hypo)
|
| 105 |
+
|
| 106 |
+
output_scores = self.model.score(references=premise, candidates=hypo, batch_size=8)
|
| 107 |
+
output_scores = [s for s in output_scores]
|
| 108 |
+
return torch.Tensor(output_scores), torch.Tensor(output_scores), torch.Tensor(output_scores)
|
| 109 |
+
|
| 110 |
+
class BertScoreScorer():
|
| 111 |
+
def __init__(self, model_type, metric, device, batch_size) -> None:
|
| 112 |
+
self.model_type = model_type
|
| 113 |
+
self.device = device
|
| 114 |
+
self.metric = metric
|
| 115 |
+
self.batch_size = batch_size
|
| 116 |
+
|
| 117 |
+
from bert_score import score
|
| 118 |
+
self.model = score
|
| 119 |
+
|
| 120 |
+
def scorer(self, premise: list, hypo: list):
|
| 121 |
+
assert len(premise) == len(hypo)
|
| 122 |
+
|
| 123 |
+
precision, recall, f1 = self.model(premise, hypo, model_type=self.model_type, lang='en', rescale_with_baseline=True, verbose=True, device=self.device, batch_size=self.batch_size)
|
| 124 |
+
|
| 125 |
+
f1 = [f for f in f1]
|
| 126 |
+
precision = [p for p in precision]
|
| 127 |
+
recall = [r for r in recall]
|
| 128 |
+
|
| 129 |
+
if self.metric == 'f1':
|
| 130 |
+
return torch.Tensor(f1), torch.Tensor(f1), None
|
| 131 |
+
elif self.metric == 'precision':
|
| 132 |
+
return torch.Tensor(precision), torch.Tensor(precision), None
|
| 133 |
+
elif self.metric == 'recall':
|
| 134 |
+
return torch.Tensor(recall), torch.Tensor(recall), None
|
| 135 |
+
else:
|
| 136 |
+
ValueError("metric type not in f1, precision or recall.")
|
| 137 |
+
|
| 138 |
+
class BartScoreScorer():
|
| 139 |
+
def __init__(self, checkpoint, device) -> None:
|
| 140 |
+
self.checkpoint = checkpoint
|
| 141 |
+
self.device = device
|
| 142 |
+
import os, sys
|
| 143 |
+
sys.path.append('baselines/BARTScore')
|
| 144 |
+
from bart_score import BARTScorer
|
| 145 |
+
self.model = BARTScorer(device=self.device, checkpoint=self.checkpoint)
|
| 146 |
+
|
| 147 |
+
def scorer(self, premise: list, hypo: list):
|
| 148 |
+
assert len(premise) == len(hypo)
|
| 149 |
+
|
| 150 |
+
output_scores = self.model.score(premise, hypo, batch_size=4)
|
| 151 |
+
normed_score = torch.exp(torch.Tensor(output_scores))
|
| 152 |
+
|
| 153 |
+
return normed_score, normed_score, normed_score
|
| 154 |
+
|
| 155 |
+
### Below are baselines in SummaC
|
| 156 |
+
### MNLI, NER, FactCC, DAE, FEQA, QuestEval, SummaC-ZS, SummaC-Conv
|
| 157 |
+
class MNLIScorer():
|
| 158 |
+
def __init__(self, model="roberta-large-mnli", device='cuda:0', batch_size=32) -> None:
|
| 159 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 160 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model)
|
| 161 |
+
self.model = AutoModelForSequenceClassification.from_pretrained(model).to(device)
|
| 162 |
+
self.device = device
|
| 163 |
+
self.softmax = nn.Softmax(dim=-1)
|
| 164 |
+
self.batch_size = batch_size
|
| 165 |
+
|
| 166 |
+
def scorer(self, premise: list, hypo: list):
|
| 167 |
+
if isinstance(premise, str) and isinstance(hypo, str):
|
| 168 |
+
premise = [premise]
|
| 169 |
+
hypo = [hypo]
|
| 170 |
+
|
| 171 |
+
batch = self.batch_tokenize(premise, hypo)
|
| 172 |
+
output_score_tri = []
|
| 173 |
+
|
| 174 |
+
for mini_batch in tqdm(batch, desc="Evaluating MNLI"):
|
| 175 |
+
# for mini_batch in batch:
|
| 176 |
+
mini_batch = mini_batch.to(self.device)
|
| 177 |
+
with torch.no_grad():
|
| 178 |
+
model_output = self.model(**mini_batch)
|
| 179 |
+
model_output_tri = model_output.logits
|
| 180 |
+
model_output_tri = self.softmax(model_output_tri).cpu()
|
| 181 |
+
|
| 182 |
+
output_score_tri.append(model_output_tri[:,2])
|
| 183 |
+
|
| 184 |
+
output_score_tri = torch.cat(output_score_tri)
|
| 185 |
+
|
| 186 |
+
return output_score_tri, output_score_tri, output_score_tri
|
| 187 |
+
|
| 188 |
+
def batch_tokenize(self, premise, hypo):
|
| 189 |
+
"""
|
| 190 |
+
input premise and hypos are lists
|
| 191 |
+
"""
|
| 192 |
+
assert isinstance(premise, list) and isinstance(hypo, list)
|
| 193 |
+
assert len(premise) == len(hypo), "premise and hypo should be in the same length."
|
| 194 |
+
|
| 195 |
+
batch = []
|
| 196 |
+
for mini_batch_pre, mini_batch_hypo in zip(self.chunks(premise, self.batch_size), self.chunks(hypo, self.batch_size)):
|
| 197 |
+
try:
|
| 198 |
+
mini_batch = self.tokenizer(mini_batch_pre, mini_batch_hypo, truncation='only_first', padding='max_length', max_length=self.tokenizer.model_max_length, return_tensors='pt')
|
| 199 |
+
except:
|
| 200 |
+
warning('text_b too long...')
|
| 201 |
+
mini_batch = self.tokenizer(mini_batch_pre, mini_batch_hypo, truncation=True, padding='max_length', max_length=self.tokenizer.model_max_length, return_tensors='pt')
|
| 202 |
+
batch.append(mini_batch)
|
| 203 |
+
|
| 204 |
+
return batch
|
| 205 |
+
|
| 206 |
+
def chunks(self, lst, n):
|
| 207 |
+
"""Yield successive n-sized chunks from lst."""
|
| 208 |
+
for i in range(0, len(lst), n):
|
| 209 |
+
yield lst[i:i + n]
|
| 210 |
+
|
| 211 |
+
class NERScorer():
|
| 212 |
+
def __init__(self) -> None:
|
| 213 |
+
import os, sys
|
| 214 |
+
sys.path.append('baselines/summac/summac')
|
| 215 |
+
from model_guardrails import NERInaccuracyPenalty
|
| 216 |
+
self.ner = NERInaccuracyPenalty()
|
| 217 |
+
|
| 218 |
+
def scorer(self, premise, hypo):
|
| 219 |
+
score_return = self.ner.score(premise, hypo)['scores']
|
| 220 |
+
oppo_score = [float(not each) for each in score_return]
|
| 221 |
+
|
| 222 |
+
tensor_score = torch.tensor(oppo_score)
|
| 223 |
+
|
| 224 |
+
return tensor_score, tensor_score, tensor_score
|
| 225 |
+
class UniEvalScorer():
|
| 226 |
+
def __init__(self, task='fact', device='cuda:0') -> None:
|
| 227 |
+
import os, sys
|
| 228 |
+
sys.path.append('baselines/UniEval')
|
| 229 |
+
from metric.evaluator import get_evaluator
|
| 230 |
+
|
| 231 |
+
self.evaluator = get_evaluator(task, device=device)
|
| 232 |
+
|
| 233 |
+
def scorer(self, premise, hypo):
|
| 234 |
+
from utils import convert_to_json
|
| 235 |
+
# Prepare data for pre-trained evaluators
|
| 236 |
+
data = convert_to_json(output_list=hypo, src_list=premise)
|
| 237 |
+
# Initialize evaluator for a specific task
|
| 238 |
+
|
| 239 |
+
# Get factual consistency scores
|
| 240 |
+
eval_scores = self.evaluator.evaluate(data, print_result=True)
|
| 241 |
+
score_list = [each['consistency'] for each in eval_scores]
|
| 242 |
+
|
| 243 |
+
return torch.tensor(score_list), torch.tensor(score_list), torch.tensor(score_list)
|
| 244 |
+
|
| 245 |
+
class FEQAScorer():
|
| 246 |
+
def __init__(self) -> None:
|
| 247 |
+
import os, sys
|
| 248 |
+
sys.path.append('baselines/feqa')
|
| 249 |
+
import benepar
|
| 250 |
+
import nltk
|
| 251 |
+
|
| 252 |
+
benepar.download('benepar_en3')
|
| 253 |
+
nltk.download('stopwords')
|
| 254 |
+
|
| 255 |
+
from feqa import FEQA
|
| 256 |
+
self.feqa_model = FEQA(squad_dir=os.path.abspath('baselines/feqa/qa_models/squad1.0'), bart_qa_dir=os.path.abspath('baselines/feqa/bart_qg/checkpoints/'), use_gpu=True)
|
| 257 |
+
|
| 258 |
+
def scorer(self, premise, hypo):
|
| 259 |
+
eval_score = self.feqa_model.compute_score(premise, hypo, aggregate=False)
|
| 260 |
+
|
| 261 |
+
return torch.tensor(eval_score), torch.tensor(eval_score), torch.tensor(eval_score)
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class QuestEvalScorer():
|
| 265 |
+
def __init__(self) -> None:
|
| 266 |
+
import os, sys
|
| 267 |
+
sys.path.append('baselines/QuestEval')
|
| 268 |
+
from questeval.questeval_metric import QuestEval
|
| 269 |
+
self.questeval = QuestEval(no_cuda=False)
|
| 270 |
+
|
| 271 |
+
def scorer(self, premise, hypo):
|
| 272 |
+
score = self.questeval.corpus_questeval(
|
| 273 |
+
hypothesis=hypo,
|
| 274 |
+
sources=premise
|
| 275 |
+
)
|
| 276 |
+
final_score = score['ex_level_scores']
|
| 277 |
+
|
| 278 |
+
return torch.tensor(final_score), torch.tensor(final_score), torch.tensor(final_score)
|
| 279 |
+
|
| 280 |
+
class QAFactEvalScorer():
|
| 281 |
+
def __init__(self, model_folder, device='cuda:0') -> None:
|
| 282 |
+
import os, sys
|
| 283 |
+
sys.path.append('baselines/QAFactEval')
|
| 284 |
+
sys.path.append(os.path.abspath('baselines/qaeval/'))
|
| 285 |
+
from qafacteval import QAFactEval
|
| 286 |
+
kwargs = {"cuda_device": int(device.split(':')[-1]), "use_lerc_quip": True, \
|
| 287 |
+
"verbose": True, "generation_batch_size": 32, \
|
| 288 |
+
"answering_batch_size": 32, "lerc_batch_size": 8}
|
| 289 |
+
|
| 290 |
+
self.metric = QAFactEval(
|
| 291 |
+
lerc_quip_path=f"{model_folder}/quip-512-mocha",
|
| 292 |
+
generation_model_path=f"{model_folder}/generation/model.tar.gz",
|
| 293 |
+
answering_model_dir=f"{model_folder}/answering",
|
| 294 |
+
lerc_model_path=f"{model_folder}/lerc/model.tar.gz",
|
| 295 |
+
lerc_pretrained_model_path=f"{model_folder}/lerc/pretraining.tar.gz",
|
| 296 |
+
**kwargs
|
| 297 |
+
)
|
| 298 |
+
def scorer(self, premise, hypo):
|
| 299 |
+
results = self.metric.score_batch_qafacteval(premise, [[each] for each in hypo], return_qa_pairs=True)
|
| 300 |
+
score = [result[0]['qa-eval']['lerc_quip'] for result in results]
|
| 301 |
+
return torch.tensor(score), torch.tensor(score), torch.tensor(score)
|
| 302 |
+
|
| 303 |
+
class MoverScorer():
|
| 304 |
+
def __init__(self) -> None:
|
| 305 |
+
pass
|
| 306 |
+
|
| 307 |
+
class BERTScoreFFCIScorer():
|
| 308 |
+
def __init__(self) -> None:
|
| 309 |
+
pass
|
| 310 |
+
|
| 311 |
+
class DAEScorer():
|
| 312 |
+
def __init__(self, model_dir, device=0) -> None:
|
| 313 |
+
import os, sys
|
| 314 |
+
sys.path.insert(0, "baselines/factuality-datasets/")
|
| 315 |
+
from evaluate_generated_outputs import daefact
|
| 316 |
+
self.dae = daefact(model_dir, model_type='electra_dae', gpu_device=device)
|
| 317 |
+
|
| 318 |
+
def scorer(self, premise, hypo):
|
| 319 |
+
return_score = torch.tensor(self.dae.score_multi_doc(premise, hypo))
|
| 320 |
+
|
| 321 |
+
return return_score, return_score, return_score
|
| 322 |
+
|
| 323 |
+
class SummaCScorer():
|
| 324 |
+
def __init__(self, summac_type='conv', device='cuda:0') -> None:
|
| 325 |
+
self.summac_type = summac_type
|
| 326 |
+
import os, sys
|
| 327 |
+
sys.path.append("baselines/summac")
|
| 328 |
+
from summac.model_summac import SummaCZS, SummaCConv
|
| 329 |
+
|
| 330 |
+
if summac_type == 'conv':
|
| 331 |
+
self.model = SummaCConv(models=["vitc"], bins='percentile', granularity="sentence", nli_labels="e", device=device, start_file="default", agg="mean")
|
| 332 |
+
elif summac_type == 'zs':
|
| 333 |
+
self.model = SummaCZS(granularity="sentence", model_name="vitc", device=device) # If you have a GPU: switch to: device="cuda"
|
| 334 |
+
|
| 335 |
+
def scorer(self, premise, hypo):
|
| 336 |
+
assert len(premise) == len(hypo)
|
| 337 |
+
scores = self.model.score(premise, hypo)['scores']
|
| 338 |
+
return_score = torch.tensor(scores)
|
| 339 |
+
|
| 340 |
+
return return_score, return_score, return_score
|
| 341 |
+
|
| 342 |
+
class FactCCScorer():
|
| 343 |
+
def __init__(self, script_path, test_data_path,result_path) -> None:
|
| 344 |
+
self.script_path = script_path
|
| 345 |
+
self.result_path = result_path
|
| 346 |
+
self.test_data_path = test_data_path
|
| 347 |
+
def scorer(self, premise, hypo):
|
| 348 |
+
import subprocess
|
| 349 |
+
import pickle
|
| 350 |
+
|
| 351 |
+
self.generate_json_file(premise, hypo)
|
| 352 |
+
subprocess.call(f"sh {self.script_path}", shell=True)
|
| 353 |
+
print("Finishing FactCC")
|
| 354 |
+
results = pickle.load(open(self.result_path, 'rb'))
|
| 355 |
+
results = [-each+1 for each in results]
|
| 356 |
+
|
| 357 |
+
return torch.tensor(results), torch.tensor(results), torch.tensor(results)
|
| 358 |
+
|
| 359 |
+
def generate_json_file(self, premise, hypo):
|
| 360 |
+
output = []
|
| 361 |
+
assert len(premise) == len(hypo)
|
| 362 |
+
i = 0
|
| 363 |
+
for one_premise, one_hypo in zip(premise, hypo):
|
| 364 |
+
example = dict()
|
| 365 |
+
example['id'] = i
|
| 366 |
+
example['text'] = one_premise
|
| 367 |
+
example['claim'] = one_hypo
|
| 368 |
+
example['label'] = 'CORRECT'
|
| 369 |
+
|
| 370 |
+
i += 1
|
| 371 |
+
output.append(example)
|
| 372 |
+
with open(self.test_data_path, 'w', encoding='utf8') as f:
|
| 373 |
+
for each in output:
|
| 374 |
+
json.dump(each, f, ensure_ascii=False)
|
| 375 |
+
f.write('\n')
|
| 376 |
+
|
| 377 |
+
class BLANCScorer():
|
| 378 |
+
def __init__(self, device='cuda', batch_size=64) -> None:
|
| 379 |
+
from blanc import BlancHelp, BlancTune
|
| 380 |
+
self.blanc_help = BlancHelp(device=device, inference_batch_size=batch_size)
|
| 381 |
+
|
| 382 |
+
|
| 383 |
+
def scorer(self, premise, hypo):
|
| 384 |
+
score = self.blanc_help.eval_pairs(premise, hypo)
|
| 385 |
+
|
| 386 |
+
return_score = torch.tensor(score)
|
| 387 |
+
|
| 388 |
+
return return_score, return_score, return_score
|
| 389 |
+
|
| 390 |
+
|
| 391 |
+
class BLEUScorer():
|
| 392 |
+
def __init__(self, n_grams=1) -> None:
|
| 393 |
+
self.n_grams = n_grams
|
| 394 |
+
self.n_gram_map = {
|
| 395 |
+
1: (1,0,0,0),
|
| 396 |
+
2: (0.5,0.5,0,0),
|
| 397 |
+
3: (1./3,1./3,1./3,0),
|
| 398 |
+
4: (0.25,0.25,0.25,0.25)
|
| 399 |
+
}
|
| 400 |
+
|
| 401 |
+
def scorer(self, premise, hypo):
|
| 402 |
+
from nltk.translate.bleu_score import sentence_bleu
|
| 403 |
+
assert len(premise) == len(hypo), "premise and hypothesis should be the same length!"
|
| 404 |
+
|
| 405 |
+
output_score = []
|
| 406 |
+
|
| 407 |
+
for one_pre, one_hypo in tqdm(zip(premise, hypo), desc=f"Evaluating BLEU-{self.n_grams}", total=len(premise)):
|
| 408 |
+
scores = []
|
| 409 |
+
pre_sents = sent_tokenize(one_pre)
|
| 410 |
+
references = [[each for each in sent.split()] for sent in pre_sents]
|
| 411 |
+
for hypo_sent in sent_tokenize(one_hypo):
|
| 412 |
+
hypothesis = [each for each in hypo_sent.split()]
|
| 413 |
+
scores.append(sentence_bleu(references=references, hypothesis=hypothesis, weights=self.n_gram_map[self.n_grams]))
|
| 414 |
+
output_score.append(sum(scores)/len(scores) if len(scores)>0 else 0.)
|
| 415 |
+
|
| 416 |
+
return torch.tensor(output_score), torch.tensor(output_score), torch.tensor(output_score)
|
| 417 |
+
|
| 418 |
+
class ROUGEScorer():
|
| 419 |
+
def __init__(self, rouge_type='1') -> None:
|
| 420 |
+
from rouge import Rouge
|
| 421 |
+
self.rouge = Rouge()
|
| 422 |
+
self.rouge_type = rouge_type
|
| 423 |
+
|
| 424 |
+
def scorer(self, premise, hypo):
|
| 425 |
+
|
| 426 |
+
assert len(premise) == len(hypo), "premise and hypothesis should be the same length!"
|
| 427 |
+
|
| 428 |
+
output_score = []
|
| 429 |
+
|
| 430 |
+
for one_pre, one_hypo in tqdm(zip(premise, hypo), desc=f"Evaluating ROUGE-{self.rouge_type}", total=len(premise)):
|
| 431 |
+
scores = []
|
| 432 |
+
for pre_sent in sent_tokenize(one_pre):
|
| 433 |
+
for hypo_sent in sent_tokenize(one_hypo):
|
| 434 |
+
try:
|
| 435 |
+
scores.append(self.rouge.get_scores(pre_sent, hypo_sent)[0][f"rouge-{self.rouge_type}"]['f'])
|
| 436 |
+
except:
|
| 437 |
+
if len(pre_sent.strip()) == 0:
|
| 438 |
+
print('premise sent is empty')
|
| 439 |
+
elif len(hypo_sent.strip()) == 0:
|
| 440 |
+
print('hypo sent is empty')
|
| 441 |
+
scores.append(0.0)
|
| 442 |
+
scores = np.array(scores)
|
| 443 |
+
scores = scores.reshape((len(sent_tokenize(one_pre)), len(sent_tokenize(one_hypo))))
|
| 444 |
+
scores = scores.max(axis=0).mean()
|
| 445 |
+
output_score.append(scores.item())
|
| 446 |
+
|
| 447 |
+
return torch.tensor(output_score), torch.tensor(output_score), torch.tensor(output_score)
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
class GPTScoreScorer():
|
| 451 |
+
def __init__(self, api_key, gpt_model='davinci003') -> None:
|
| 452 |
+
import os, sys
|
| 453 |
+
sys.path.append('../BaselineForNLGEval/GPTScore')
|
| 454 |
+
from gpt3_score import gpt3score
|
| 455 |
+
|
| 456 |
+
self.gpt3score = gpt3score
|
| 457 |
+
self.api_key = api_key
|
| 458 |
+
self.gpt_model = gpt_model
|
| 459 |
+
|
| 460 |
+
self.consistency_prefix = "Generate factually consistent summary for the following text: "
|
| 461 |
+
self.consistency_suffix = " \n\nTl;dr "
|
| 462 |
+
|
| 463 |
+
|
| 464 |
+
def scorer(self, premise: list, hypothesis: list):
|
| 465 |
+
assert len(premise) == len(hypothesis)
|
| 466 |
+
output_score = []
|
| 467 |
+
for p, h in tqdm(zip(premise, hypothesis), total=len(premise), desc="Evaluating GPTScore"):
|
| 468 |
+
score = self.gpt3score(input=self.consistency_prefix + p + self.consistency_suffix, output=h, gpt3model=self.gpt_model, api_key=self.api_key)
|
| 469 |
+
output_score.append(score)
|
| 470 |
+
|
| 471 |
+
output_score = torch.tensor(output_score)
|
| 472 |
+
|
| 473 |
+
return None, output_score, None
|
| 474 |
+
|
| 475 |
+
class ChatGPTLuo2023Scorer():
|
| 476 |
+
def __init__(self, task, api_key, chat_model='gpt-3.5-turbo') -> None:
|
| 477 |
+
openai.api_key = api_key
|
| 478 |
+
assert isinstance(task, list) and len(task) == 1
|
| 479 |
+
|
| 480 |
+
self.task = task[0]
|
| 481 |
+
self.chat_model = chat_model
|
| 482 |
+
self.instruct = """Score the following summary given the corresponding article with respect to consistency from 1 to 10. Note that consistency measures how much information included in the summary is present in the source article. 10 points indicate the summary contains only statements that are entailed by the source document."""
|
| 483 |
+
|
| 484 |
+
def scorer(self, premise: list, hypothesis: list):
|
| 485 |
+
import time
|
| 486 |
+
assert len(premise) == len(hypothesis)
|
| 487 |
+
output_score = []
|
| 488 |
+
i = -1
|
| 489 |
+
|
| 490 |
+
for p, h in tqdm(zip(premise, hypothesis), total=len(premise), desc="Evaluating ChatGPTLuo2023"):
|
| 491 |
+
i += 1
|
| 492 |
+
if i <= -1: continue
|
| 493 |
+
|
| 494 |
+
attempt = 0
|
| 495 |
+
max_attempt = 5
|
| 496 |
+
while attempt < max_attempt:
|
| 497 |
+
try:
|
| 498 |
+
response = openai.ChatCompletion.create(
|
| 499 |
+
model=self.chat_model,
|
| 500 |
+
messages=[
|
| 501 |
+
# {"role": "system", "content": "You are a helpful assistant."},
|
| 502 |
+
{"role": "user", "content": f"""Score the following summary given the corresponding article with respect to consistency from 1 to 10. Note that consistency measures how much information included in the summary is present in the source article. 10 points indicate the summary contains only statements that are entailed by the source document.
|
| 503 |
+
|
| 504 |
+
Summary: {h}
|
| 505 |
+
|
| 506 |
+
Article: {p} """},
|
| 507 |
+
],
|
| 508 |
+
temperature=0,
|
| 509 |
+
max_tokens=10
|
| 510 |
+
)
|
| 511 |
+
res_content = response['choices'][0]['message']['content']
|
| 512 |
+
break
|
| 513 |
+
except:
|
| 514 |
+
attempt += 1
|
| 515 |
+
print("openai api failed")
|
| 516 |
+
if max_attempt == attempt:
|
| 517 |
+
print("maximum failed attempts reached. exiting...")
|
| 518 |
+
exit()
|
| 519 |
+
json.dump({i: res_content}, open(f'exp_results/nlg_eval_fact/baselines/ChatGPTLuo2023-output/{self.task}.json', 'a'))
|
| 520 |
+
with open(f'exp_results/nlg_eval_fact/baselines/ChatGPTLuo2023-output/{self.task}.json', 'a') as f:
|
| 521 |
+
f.write('\n')
|
| 522 |
+
|
| 523 |
+
try:
|
| 524 |
+
score = int(res_content)
|
| 525 |
+
except:
|
| 526 |
+
print("unknown score")
|
| 527 |
+
score = 0.0
|
| 528 |
+
output_score.append(score)
|
| 529 |
+
# time.sleep(1)
|
| 530 |
+
|
| 531 |
+
output_score = torch.tensor(output_score)
|
| 532 |
+
|
| 533 |
+
return None, output_score, None
|
| 534 |
+
|
| 535 |
+
class ChatGPTGao2023Scorer():
|
| 536 |
+
def __init__(self, task, api_key, chat_model='gpt-3.5-turbo') -> None:
|
| 537 |
+
openai.api_key = api_key
|
| 538 |
+
assert isinstance(task, list) and len(task) == 1
|
| 539 |
+
|
| 540 |
+
self.task = task[0]
|
| 541 |
+
self.chat_model = chat_model
|
| 542 |
+
|
| 543 |
+
def scorer(self, premise: list, hypothesis: list):
|
| 544 |
+
import time
|
| 545 |
+
assert len(premise) == len(hypothesis)
|
| 546 |
+
output_score = []
|
| 547 |
+
i = -1
|
| 548 |
+
|
| 549 |
+
for p, h in tqdm(zip(premise, hypothesis), total=len(premise), desc="Evaluating ChatGPTGao2023"):
|
| 550 |
+
i += 1
|
| 551 |
+
if i <= -1: continue
|
| 552 |
+
|
| 553 |
+
attempt = 0
|
| 554 |
+
max_attempt = 5
|
| 555 |
+
while attempt < max_attempt:
|
| 556 |
+
try:
|
| 557 |
+
response = openai.ChatCompletion.create(
|
| 558 |
+
model=self.chat_model,
|
| 559 |
+
messages=[
|
| 560 |
+
# {"role": "system", "content": "You are a human annotator that rates the quality of summaries"},
|
| 561 |
+
# {"role": "user", "content": f"""Imagine you are a human annotator now. You will evaluate the quality of summaries written for a news article. Please follow these steps:\n\n 1. Carefully read the news article, and be aware of the information it contains.\n 2. Read the proposed summary.\n 3. Rate the summary on four dimensions: relevance, consistency, fluency, and coherence. You should rate on a scale from 1 (worst) to 5 (best).\n\n Definitions are as follows:\n Relevance: The rating measures how well the summary captures the key points of the article. Consider whether all and only the important aspects are contained in the summary.\n Consistency: The rating measures whether the facts in the summary are consistent with the facts in the original article. Consider whether the summary does reproduce all facts accurately and does not make up untrue information.\n Fluency: This rating measures the quality of individual sentences, whether they are well-written and grammatically correct. Consider the quality of individual sentences.\n Coherence: The rating measures the quality of all sentences collectively, to fit together and sound natural. Consider the quality of the summary as a whole.\n\n The article and the summary are given below:\n Article: {p}\n Summary: {h}"""},
|
| 562 |
+
{"role": "user", "content": f"""Evaluate the quality of summaries written for a news article. Rate each summary on four dimensions: relevance, faithfulness, fluency, and coherence. You should rate on a scale from 1 (worst) to 5 (best).\n\n Article: {p}\n Summary: {h}"""},
|
| 563 |
+
],
|
| 564 |
+
temperature=0,
|
| 565 |
+
# max_tokens=10
|
| 566 |
+
)
|
| 567 |
+
res_content = response['choices'][0]['message']['content']
|
| 568 |
+
break
|
| 569 |
+
except:
|
| 570 |
+
attempt += 1
|
| 571 |
+
print("openai api failed")
|
| 572 |
+
if max_attempt == attempt:
|
| 573 |
+
print("maximum failed attempts reached. exiting...")
|
| 574 |
+
exit()
|
| 575 |
+
json.dump({i: res_content}, open(f'exp_results/nlg_eval_fact/baselines/ChatGPTGao2023-output/{self.task}.json', 'a'))
|
| 576 |
+
with open(f'exp_results/nlg_eval_fact/baselines/ChatGPTGao2023-output/{self.task}.json', 'a') as f:
|
| 577 |
+
f.write('\n')
|
| 578 |
+
|
| 579 |
+
try:
|
| 580 |
+
score = int(res_content)
|
| 581 |
+
except:
|
| 582 |
+
print("unknown score")
|
| 583 |
+
score = 0.0
|
| 584 |
+
output_score.append(score)
|
| 585 |
+
# time.sleep(1)
|
| 586 |
+
|
| 587 |
+
output_score = torch.tensor(output_score)
|
| 588 |
+
|
| 589 |
+
return None, output_score, None
|
| 590 |
+
|
| 591 |
+
class ChatGPTYiChen2023Scorer():
|
| 592 |
+
def __init__(self, task, api_key, chat_model='gpt-3.5-turbo') -> None:
|
| 593 |
+
### Explicit score by ChatGPT
|
| 594 |
+
openai.api_key = api_key
|
| 595 |
+
assert isinstance(task, list) and len(task) == 1
|
| 596 |
+
|
| 597 |
+
self.task = task[0]
|
| 598 |
+
self.chat_model = chat_model
|
| 599 |
+
|
| 600 |
+
def scorer(self, premise: list, hypothesis: list):
|
| 601 |
+
import time
|
| 602 |
+
assert len(premise) == len(hypothesis)
|
| 603 |
+
output_score = []
|
| 604 |
+
i = -1
|
| 605 |
+
|
| 606 |
+
for p, h in tqdm(zip(premise, hypothesis), total=len(premise), desc="Evaluating ChatGPTYiChen2023"):
|
| 607 |
+
i += 1
|
| 608 |
+
if i <= -1: continue
|
| 609 |
+
|
| 610 |
+
attempt = 0
|
| 611 |
+
max_attempt = 5
|
| 612 |
+
while attempt < max_attempt:
|
| 613 |
+
try:
|
| 614 |
+
response = openai.ChatCompletion.create(
|
| 615 |
+
model=self.chat_model,
|
| 616 |
+
messages=[
|
| 617 |
+
# {"role": "system", "content": "You are a human annotator that rates the quality of summaries"},
|
| 618 |
+
# {"role": "user", "content": f"""Imagine you are a human annotator now. You will evaluate the quality of summaries written for a news article. Please follow these steps:\n\n 1. Carefully read the news article, and be aware of the information it contains.\n 2. Read the proposed summary.\n 3. Rate the summary on four dimensions: relevance, consistency, fluency, and coherence. You should rate on a scale from 1 (worst) to 5 (best).\n\n Definitions are as follows:\n Relevance: The rating measures how well the summary captures the key points of the article. Consider whether all and only the important aspects are contained in the summary.\n Consistency: The rating measures whether the facts in the summary are consistent with the facts in the original article. Consider whether the summary does reproduce all facts accurately and does not make up untrue information.\n Fluency: This rating measures the quality of individual sentences, whether they are well-written and grammatically correct. Consider the quality of individual sentences.\n Coherence: The rating measures the quality of all sentences collectively, to fit together and sound natural. Consider the quality of the summary as a whole.\n\n The article and the summary are given below:\n Article: {p}\n Summary: {h}"""},
|
| 619 |
+
{"role": "user", "content": f"""Score the following storyline given the beginning of the story on a continual scale from 0 (worst) to 100 (best), where score of 0 means "The storyline makes no sense and is totally not understandable" and score of 100 means "The storyline is perfect-written and highly consistent with the given beginning of the story". \n\n The beginning of the story: {p} \n\n Storyline: {h} \n\n Score: """},
|
| 620 |
+
],
|
| 621 |
+
temperature=0,
|
| 622 |
+
# max_tokens=10
|
| 623 |
+
)
|
| 624 |
+
res_content = response['choices'][0]['message']['content']
|
| 625 |
+
break
|
| 626 |
+
except:
|
| 627 |
+
attempt += 1
|
| 628 |
+
print("openai api failed")
|
| 629 |
+
if max_attempt == attempt:
|
| 630 |
+
print("maximum failed attempts reached. exiting...")
|
| 631 |
+
exit()
|
| 632 |
+
json.dump({i: res_content}, open(f'exp_results/nlg_eval_fact/baselines/ChatGPTYiChen2023-output/{self.task}.json', 'a'))
|
| 633 |
+
with open(f'exp_results/nlg_eval_fact/baselines/ChatGPTYiChen2023-output/{self.task}.json', 'a') as f:
|
| 634 |
+
f.write('\n')
|
| 635 |
+
|
| 636 |
+
try:
|
| 637 |
+
score = int(res_content)
|
| 638 |
+
except:
|
| 639 |
+
print("unknown score")
|
| 640 |
+
score = 0.0
|
| 641 |
+
output_score.append(score)
|
| 642 |
+
# time.sleep(1)
|
| 643 |
+
|
| 644 |
+
output_score = torch.tensor(output_score)
|
| 645 |
+
|
| 646 |
+
return None, output_score, None
|
| 647 |
+
|
| 648 |
+
class ChatGPTShiqiChen2023Scorer():
|
| 649 |
+
def __init__(self, task, api_key, chat_model='gpt-3.5-turbo') -> None:
|
| 650 |
+
### Explicit score by ChatGPT
|
| 651 |
+
openai.api_key = api_key
|
| 652 |
+
assert isinstance(task, list) and len(task) == 1
|
| 653 |
+
|
| 654 |
+
self.task = task[0]
|
| 655 |
+
self.chat_model = chat_model
|
| 656 |
+
|
| 657 |
+
def scorer(self, premise: list, hypothesis: list):
|
| 658 |
+
import time
|
| 659 |
+
assert len(premise) == len(hypothesis)
|
| 660 |
+
output_score = []
|
| 661 |
+
i = -1
|
| 662 |
+
|
| 663 |
+
for p, h in tqdm(zip(premise, hypothesis), total=len(premise), desc="Evaluating ChatGPTShiqiChen2023"):
|
| 664 |
+
i += 1
|
| 665 |
+
if i <= -1: continue
|
| 666 |
+
hypo_sents = sent_tokenize(h)
|
| 667 |
+
hypo_sents = ' \n '.join([f"{i+1}. "+each for i, each in enumerate(hypo_sents)])
|
| 668 |
+
attempt = 0
|
| 669 |
+
max_attempt = 5
|
| 670 |
+
while attempt < max_attempt:
|
| 671 |
+
try:
|
| 672 |
+
response = openai.ChatCompletion.create(
|
| 673 |
+
model=self.chat_model,
|
| 674 |
+
messages=[
|
| 675 |
+
# {"role": "system", "content": "You are a human annotator that rates the quality of summaries"},
|
| 676 |
+
# {"role": "user", "content": f"""Imagine you are a human annotator now. You will evaluate the quality of summaries written for a news article. Please follow these steps:\n\n 1. Carefully read the news article, and be aware of the information it contains.\n 2. Read the proposed summary.\n 3. Rate the summary on four dimensions: relevance, consistency, fluency, and coherence. You should rate on a scale from 1 (worst) to 5 (best).\n\n Definitions are as follows:\n Relevance: The rating measures how well the summary captures the key points of the article. Consider whether all and only the important aspects are contained in the summary.\n Consistency: The rating measures whether the facts in the summary are consistent with the facts in the original article. Consider whether the summary does reproduce all facts accurately and does not make up untrue information.\n Fluency: This rating measures the quality of individual sentences, whether they are well-written and grammatically correct. Consider the quality of individual sentences.\n Coherence: The rating measures the quality of all sentences collectively, to fit together and sound natural. Consider the quality of the summary as a whole.\n\n The article and the summary are given below:\n Article: {p}\n Summary: {h}"""},
|
| 677 |
+
{"role": "user", "content": f"""Source Document: \n {p} \n\n Q: Can the following statement be inferred from the above document? Yes or No?\n {hypo_sents} \n A: 1. """},
|
| 678 |
+
],
|
| 679 |
+
temperature=0,
|
| 680 |
+
# max_tokens=10
|
| 681 |
+
)
|
| 682 |
+
res_content = response['choices'][0]['message']['content']
|
| 683 |
+
break
|
| 684 |
+
except:
|
| 685 |
+
attempt += 1
|
| 686 |
+
print("openai api failed")
|
| 687 |
+
if max_attempt == attempt:
|
| 688 |
+
print("maximum failed attempts reached. exiting...")
|
| 689 |
+
exit()
|
| 690 |
+
json.dump({i: res_content}, open(f'exp_results/nlg_eval_fact/baselines/ChatGPTShiqiChen2023-output/{self.task}.json', 'a'))
|
| 691 |
+
with open(f'exp_results/nlg_eval_fact/baselines/ChatGPTShiqiChen2023-output/{self.task}.json', 'a') as f:
|
| 692 |
+
f.write('\n')
|
| 693 |
+
|
| 694 |
+
try:
|
| 695 |
+
score = int(res_content)
|
| 696 |
+
except:
|
| 697 |
+
print("unknown score")
|
| 698 |
+
score = 0.0
|
| 699 |
+
output_score.append(score)
|
| 700 |
+
# time.sleep(1)
|
| 701 |
+
|
| 702 |
+
output_score = torch.tensor(output_score)
|
| 703 |
+
|
| 704 |
+
return None, output_score, None
|
alignscore/benchmark.py
ADDED
|
@@ -0,0 +1,494 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from evaluate import Evaluator, ALL_TASKS
|
| 2 |
+
from baselines import *
|
| 3 |
+
from alignscore.inference import Inferencer
|
| 4 |
+
import time
|
| 5 |
+
import json
|
| 6 |
+
import os
|
| 7 |
+
from argparse import ArgumentParser
|
| 8 |
+
|
| 9 |
+
SAVE_ALL_TABLES = True
|
| 10 |
+
SAVE_AND_PRINT_TIMER = False
|
| 11 |
+
|
| 12 |
+
class Timer():
|
| 13 |
+
def __init__(self) -> None:
|
| 14 |
+
self.t0 = time.time()
|
| 15 |
+
self.save_path = 'exp_results/time.json'
|
| 16 |
+
|
| 17 |
+
def finish(self, display_name):
|
| 18 |
+
t1 = time.time()
|
| 19 |
+
time_pass = t1 - self.t0
|
| 20 |
+
if SAVE_AND_PRINT_TIMER:
|
| 21 |
+
print(f"Evalautor {display_name} finished in {time_pass} secs.")
|
| 22 |
+
with open(self.save_path, 'a', encoding='utf8') as f:
|
| 23 |
+
json.dump({display_name: time_pass}, f)
|
| 24 |
+
f.write('\n')
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def eval_ctc(model_type, tasks=ALL_TASKS):
|
| 28 |
+
ctc_scorer = CTCScorer(model_type)
|
| 29 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=ctc_scorer.score, save_all_tables=SAVE_ALL_TABLES)
|
| 30 |
+
evaluator.result_save_name = f"baselines/CTC-{model_type}"
|
| 31 |
+
|
| 32 |
+
timer = Timer()
|
| 33 |
+
evaluator.evaluate()
|
| 34 |
+
timer.finish(f"CTC-{model_type}")
|
| 35 |
+
|
| 36 |
+
def eval_simcse(model_type, device, tasks=ALL_TASKS):
|
| 37 |
+
simcse_scorer = SimCSEScorer(model_type, device)
|
| 38 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=simcse_scorer.score, save_all_tables=SAVE_ALL_TABLES)
|
| 39 |
+
evaluator.result_save_name = f"baselines/{model_type.split('/')[-1]}_f"
|
| 40 |
+
|
| 41 |
+
timer = Timer()
|
| 42 |
+
evaluator.evaluate()
|
| 43 |
+
timer.finish(f"{model_type.split('/')[-1]}_f")
|
| 44 |
+
|
| 45 |
+
def eval_bleurt(checkpoint, tasks=ALL_TASKS):
|
| 46 |
+
bleurt_scorer = BleurtScorer(checkpoint)
|
| 47 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=bleurt_scorer.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 48 |
+
evaluator.result_save_name = f"baselines/BLEURT"
|
| 49 |
+
|
| 50 |
+
timer = Timer()
|
| 51 |
+
evaluator.evaluate()
|
| 52 |
+
timer.finish(f"BLEURT")
|
| 53 |
+
|
| 54 |
+
def eval_bertscore(model_type, device, batch_size, tasks=ALL_TASKS):
|
| 55 |
+
bertscore_scorer = BertScoreScorer(model_type=model_type, metric='f1', device=device, batch_size=batch_size)
|
| 56 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=bertscore_scorer.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 57 |
+
evaluator.result_save_name = f"baselines/bertscore_{model_type.replace('/', '-')}_f"
|
| 58 |
+
|
| 59 |
+
timer = Timer()
|
| 60 |
+
evaluator.evaluate()
|
| 61 |
+
timer.finish(f"bertscore_{model_type.replace('/', '-')}_f")
|
| 62 |
+
|
| 63 |
+
def eval_bartscore(checkpoint, device, tasks=ALL_TASKS):
|
| 64 |
+
bartscore_scorer = BartScoreScorer(checkpoint, device)
|
| 65 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=bartscore_scorer.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 66 |
+
evaluator.result_save_name = f"baselines/bartscore-{checkpoint.replace('/','-')}"
|
| 67 |
+
|
| 68 |
+
timer = Timer()
|
| 69 |
+
evaluator.evaluate()
|
| 70 |
+
timer.finish(f"bartscore-{checkpoint.replace('/','-')}")
|
| 71 |
+
|
| 72 |
+
### Below are Baselines for SummaC
|
| 73 |
+
def eval_mnli(model="roberta-large-mnli", device='cuda:0', tasks=ALL_TASKS):
|
| 74 |
+
mnli_scorer = MNLIScorer(model=model, device=device)
|
| 75 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=mnli_scorer.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 76 |
+
evaluator.result_save_name = f"baselines/mnli-{model}"
|
| 77 |
+
|
| 78 |
+
timer = Timer()
|
| 79 |
+
evaluator.evaluate()
|
| 80 |
+
timer.finish(f"mnli-{model}")
|
| 81 |
+
|
| 82 |
+
def eval_ner(tasks=ALL_TASKS):
|
| 83 |
+
ner_scorer = NERScorer()
|
| 84 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=ner_scorer.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 85 |
+
evaluator.result_save_name = f"baselines/NER"
|
| 86 |
+
|
| 87 |
+
timer = Timer()
|
| 88 |
+
evaluator.evaluate()
|
| 89 |
+
timer.finish(f"NER")
|
| 90 |
+
|
| 91 |
+
def eval_unieval(tasks=ALL_TASKS, device='cuda:0'):
|
| 92 |
+
unieval = UniEvalScorer(task='fact', device=device)
|
| 93 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=unieval.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 94 |
+
evaluator.result_save_name = f"baselines/UniEval"
|
| 95 |
+
|
| 96 |
+
timer = Timer()
|
| 97 |
+
evaluator.evaluate()
|
| 98 |
+
timer.finish(f"UniEval")
|
| 99 |
+
|
| 100 |
+
def eval_feqa(tasks=ALL_TASKS):
|
| 101 |
+
feqa = FEQAScorer()
|
| 102 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=feqa.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 103 |
+
evaluator.result_save_name = f"baselines/FEQA"
|
| 104 |
+
|
| 105 |
+
timer = Timer()
|
| 106 |
+
evaluator.evaluate()
|
| 107 |
+
timer.finish(f"FEQA")
|
| 108 |
+
|
| 109 |
+
def eval_questeval(tasks=ALL_TASKS):
|
| 110 |
+
questeval = QuestEvalScorer()
|
| 111 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=questeval.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 112 |
+
evaluator.result_save_name = f"baselines/QuestEval"
|
| 113 |
+
|
| 114 |
+
timer = Timer()
|
| 115 |
+
evaluator.evaluate()
|
| 116 |
+
timer.finish(f"QuestEval")
|
| 117 |
+
|
| 118 |
+
def eval_qafacteval(tasks=ALL_TASKS, device='cuda:0'):
|
| 119 |
+
import os, sys
|
| 120 |
+
warning("using conda env qaeval!!!")
|
| 121 |
+
qafacteval = QAFactEvalScorer(device=device, model_folder=os.path.abspath('../BaselineForNLGEval/QAFactEval/models'))
|
| 122 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=qafacteval.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 123 |
+
evaluator.result_save_name = f"baselines/QAFactEval"
|
| 124 |
+
evaluator.evaluate()
|
| 125 |
+
|
| 126 |
+
def eval_dae(tasks=ALL_TASKS, model_dir=None, device=0):
|
| 127 |
+
dae = DAEScorer(model_dir=model_dir, device=device)
|
| 128 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=dae.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 129 |
+
evaluator.result_save_name = f"baselines/DAE"
|
| 130 |
+
|
| 131 |
+
timer = Timer()
|
| 132 |
+
evaluator.evaluate()
|
| 133 |
+
timer.finish(f"DAE")
|
| 134 |
+
|
| 135 |
+
def eval_bleu(tasks=ALL_TASKS, n_grams=1):
|
| 136 |
+
bleu = BLEUScorer(n_grams=n_grams)
|
| 137 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=bleu.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 138 |
+
evaluator.result_save_name = f"baselines/BLEU-{n_grams}"
|
| 139 |
+
|
| 140 |
+
timer = Timer()
|
| 141 |
+
evaluator.evaluate()
|
| 142 |
+
timer.finish(f"BLEU-{n_grams}")
|
| 143 |
+
|
| 144 |
+
def eval_rouge(tasks=ALL_TASKS, rouge_type='1'):
|
| 145 |
+
rouge = ROUGEScorer(rouge_type=rouge_type)
|
| 146 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=rouge.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 147 |
+
evaluator.result_save_name = f"baselines/ROUGE-{rouge_type}"
|
| 148 |
+
|
| 149 |
+
timer = Timer()
|
| 150 |
+
evaluator.evaluate()
|
| 151 |
+
timer.finish(f"ROUGE-{rouge_type}")
|
| 152 |
+
|
| 153 |
+
def eval_factcc(script_path, test_data_path,result_path, tasks=ALL_TASKS):
|
| 154 |
+
factcc = FactCCScorer(script_path=script_path, test_data_path=test_data_path, result_path=result_path)
|
| 155 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=factcc.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 156 |
+
evaluator.result_save_name = f"baselines/FactCC"
|
| 157 |
+
|
| 158 |
+
timer = Timer()
|
| 159 |
+
evaluator.evaluate()
|
| 160 |
+
timer.finish(f"FactCC")
|
| 161 |
+
|
| 162 |
+
def eval_blanc(tasks=ALL_TASKS, device='cuda:0', batch_size=64):
|
| 163 |
+
blanc = BLANCScorer(device=device, batch_size=batch_size)
|
| 164 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=blanc.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 165 |
+
evaluator.result_save_name = f"baselines/BLANC"
|
| 166 |
+
|
| 167 |
+
timer = Timer()
|
| 168 |
+
evaluator.evaluate()
|
| 169 |
+
timer.finish(f"BLANC")
|
| 170 |
+
|
| 171 |
+
def eval_summac(tasks=ALL_TASKS, summac_type='conv', device='cuda:0'):
|
| 172 |
+
summac = SummaCScorer(summac_type=summac_type, device=device)
|
| 173 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=summac.scorer, save_all_tables=SAVE_ALL_TABLES)
|
| 174 |
+
evaluator.result_save_name = f"baselines/SummaC-{summac_type}"
|
| 175 |
+
|
| 176 |
+
timer = Timer()
|
| 177 |
+
evaluator.evaluate()
|
| 178 |
+
timer.finish(f"SummaC-{summac_type}")
|
| 179 |
+
|
| 180 |
+
def eval_align_nlg(ckpt_path, comment='', base_model='roberta-large', batch_size=32, device='cuda:0', tasks=ALL_TASKS, nlg_eval_mode='nli_sp'):
|
| 181 |
+
align = Inferencer(ckpt_path=ckpt_path, model=base_model, batch_size=batch_size, device=device)
|
| 182 |
+
if 'smart' in nlg_eval_mode:
|
| 183 |
+
align.smart_type = nlg_eval_mode
|
| 184 |
+
else:
|
| 185 |
+
align.nlg_eval_mode = nlg_eval_mode
|
| 186 |
+
|
| 187 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=align.nlg_eval, save_all_tables=SAVE_ALL_TABLES)
|
| 188 |
+
name = f'AlignScore-{nlg_eval_mode}-{base_model}'
|
| 189 |
+
if comment:
|
| 190 |
+
name += '_' + comment
|
| 191 |
+
evaluator.result_save_name = f"align_eval/{name}"
|
| 192 |
+
|
| 193 |
+
timer = Timer()
|
| 194 |
+
evaluator.evaluate()
|
| 195 |
+
timer.finish(name)
|
| 196 |
+
|
| 197 |
+
def eval_gptscore(api_key, gpt_model='davinci003', tasks=ALL_TASKS):
|
| 198 |
+
gptscore = GPTScoreScorer(api_key=api_key, gpt_model=gpt_model)
|
| 199 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=gptscore.scorer, is_save_all_tables=IS_SAVE_ALL_TABLES)
|
| 200 |
+
evaluator.result_save_name = f"nlg_eval_fact/baselines/GPTScore-{gpt_model}"
|
| 201 |
+
evaluator.evaluate()
|
| 202 |
+
|
| 203 |
+
def eval_chatgptluo2023(api_key, chat_model='gpt-3.5-turbo', tasks=['qags_cnndm']):
|
| 204 |
+
chatgpt = ChatGPTLuo2023Scorer(task=tasks, api_key=api_key, chat_model=chat_model)
|
| 205 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=chatgpt.scorer, is_save_all_tables=IS_SAVE_ALL_TABLES)
|
| 206 |
+
evaluator.result_save_name = f"nlg_eval_fact/baselines/ChatGPTLuo2023-{chat_model}"
|
| 207 |
+
evaluator.evaluate()
|
| 208 |
+
|
| 209 |
+
def eval_chatgptgao2023(api_key, chat_model='gpt-3.5-turbo', tasks=['qags_cnndm']):
|
| 210 |
+
chatgpt = ChatGPTGao2023Scorer(task=tasks, api_key=api_key, chat_model=chat_model)
|
| 211 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=chatgpt.scorer, is_save_all_tables=IS_SAVE_ALL_TABLES)
|
| 212 |
+
evaluator.result_save_name = f"nlg_eval_fact/baselines/ChatGPTGao2023-{chat_model}"
|
| 213 |
+
evaluator.evaluate()
|
| 214 |
+
|
| 215 |
+
def eval_chatgptyichen2023(api_key, chat_model='gpt-3.5-turbo', tasks=['qags_cnndm']):
|
| 216 |
+
chatgpt = ChatGPTYiChen2023Scorer(task=tasks, api_key=api_key, chat_model=chat_model)
|
| 217 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=chatgpt.scorer, is_save_all_tables=IS_SAVE_ALL_TABLES)
|
| 218 |
+
evaluator.result_save_name = f"nlg_eval_fact/baselines/ChatGPTYiChen2023-{chat_model}"
|
| 219 |
+
evaluator.evaluate()
|
| 220 |
+
|
| 221 |
+
def eval_chatgptshiqichen2023(api_key, chat_model='gpt-3.5-turbo', tasks=['qags_cnndm']):
|
| 222 |
+
chatgpt = ChatGPTShiqiChen2023Scorer(task=tasks, api_key=api_key, chat_model=chat_model)
|
| 223 |
+
evaluator = Evaluator(eval_tasks=tasks, align_func=chatgpt.scorer, is_save_all_tables=IS_SAVE_ALL_TABLES)
|
| 224 |
+
evaluator.result_save_name = f"nlg_eval_fact/baselines/ChatGPTShiqiChen2023-{chat_model}"
|
| 225 |
+
evaluator.evaluate()
|
| 226 |
+
|
| 227 |
+
def run_benchmarks(args, argugment_error):
|
| 228 |
+
os.makedirs('exp_results/baselines', exist_ok=True)
|
| 229 |
+
os.makedirs('exp_results/align_eval', exist_ok=True)
|
| 230 |
+
|
| 231 |
+
if args.alignscore:
|
| 232 |
+
if not all((args.alignscore_model, args.alignscore_ckpt, args.alignscore_eval_mode)):
|
| 233 |
+
argugment_error('--alignscore-model, --alignscore-model, and --alignscore-ckpt must be specified to run AlignScore')
|
| 234 |
+
eval_align_nlg(
|
| 235 |
+
nlg_eval_mode=args.alignscore_eval_mode,
|
| 236 |
+
ckpt_path=args.alignscore_ckpt,
|
| 237 |
+
base_model=args.alignscore_model,
|
| 238 |
+
device=args.device, tasks=args.tasks,
|
| 239 |
+
comment=args.alignscore_comment
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
if args.ctc:
|
| 243 |
+
if not args.ctc_type:
|
| 244 |
+
argugment_error('--ctc-type must be specified to run CTC baseline')
|
| 245 |
+
for type in args.ctc_type:
|
| 246 |
+
eval_ctc(type, tasks=args.tasks)
|
| 247 |
+
|
| 248 |
+
if args.simcse:
|
| 249 |
+
if not args.simcse_ckpt:
|
| 250 |
+
argugment_error('--simcse-ckpt must be specified to run SimCSE baseline')
|
| 251 |
+
for ckpt in args.simcse_ckpt:
|
| 252 |
+
eval_simcse(ckpt, device=args.device, tasks=args.tasks)
|
| 253 |
+
|
| 254 |
+
if args.bleurt:
|
| 255 |
+
if not args.bleurt_ckpt:
|
| 256 |
+
argugment_error('--bleurt-ckpt must be specified to run BLEURT baseline')
|
| 257 |
+
eval_bleurt(args.bleurt_ckpt, tasks=args.tasks)
|
| 258 |
+
|
| 259 |
+
if args.bertscore:
|
| 260 |
+
if not args.bertscore_ckpt or not args.bertscore_batch_size:
|
| 261 |
+
argugment_error('--bertscore-ckpt and --bertscore-batch-size must be specified to run BERTScore baseline')
|
| 262 |
+
for ckpt in args.bertscore_ckpt:
|
| 263 |
+
eval_bertscore(ckpt, device=args.device, tasks=args.tasks, batch_size=args.bertscore_batch_size)
|
| 264 |
+
|
| 265 |
+
if args.bartscore:
|
| 266 |
+
if not args.bartscore_ckpt:
|
| 267 |
+
argugment_error('--bartscore-ckpt must be specified to run BARTScore baseline')
|
| 268 |
+
for ckpt in args.bartscore_ckpt:
|
| 269 |
+
eval_bartscore(ckpt, device=args.device, tasks=args.tasks)
|
| 270 |
+
|
| 271 |
+
if args.mnli:
|
| 272 |
+
if not args.mnli_ckpt:
|
| 273 |
+
argugment_error('--mnli-ckpt must be specified to run MNLI baseline')
|
| 274 |
+
for ckpt in args.mnli_ckpt:
|
| 275 |
+
eval_mnli(model=ckpt, device=args.device, tasks=args.tasks)
|
| 276 |
+
|
| 277 |
+
if args.ner:
|
| 278 |
+
eval_ner(tasks=args.tasks)
|
| 279 |
+
|
| 280 |
+
if args.unieval:
|
| 281 |
+
eval_unieval(tasks=args.tasks, device=args.device)
|
| 282 |
+
|
| 283 |
+
if args.feqa:
|
| 284 |
+
eval_feqa(tasks=args.tasks)
|
| 285 |
+
|
| 286 |
+
if args.questeval:
|
| 287 |
+
eval_questeval(tasks=args.tasks)
|
| 288 |
+
|
| 289 |
+
if args.qafacteval:
|
| 290 |
+
eval_qafacteval(tasks=args.tasks)
|
| 291 |
+
|
| 292 |
+
if args.bleu:
|
| 293 |
+
if not args.bleu_ngram:
|
| 294 |
+
argugment_error('--bleu-ngram must be specified to run BLEU baseline')
|
| 295 |
+
for n in args.bleu_ngram:
|
| 296 |
+
eval_bleu(tasks=args.tasks, n_grams=n)
|
| 297 |
+
|
| 298 |
+
if args.rouge:
|
| 299 |
+
if not args.rouge_type:
|
| 300 |
+
argugment_error('--rouge-type must be specified to run ROUGE baseline')
|
| 301 |
+
for type in args.rouge_type:
|
| 302 |
+
eval_rouge(tasks=args.tasks, rouge_type=type)
|
| 303 |
+
|
| 304 |
+
if args.dae:
|
| 305 |
+
if not args.dae_ckpt:
|
| 306 |
+
argugment_error('--dae-ckpt must be specified to run DAE baseline')
|
| 307 |
+
eval_dae(tasks=args.tasks, model_dir=os.path.abspath(args.dae_ckpt))
|
| 308 |
+
|
| 309 |
+
if args.factcc:
|
| 310 |
+
if not all((args.factcc_script, args.factcc_test_data, args.factcc_result_path)):
|
| 311 |
+
argugment_error('--factcc-script, --factcc-test-data, and --factcc-result-path must be specified to run FactCC baseline')
|
| 312 |
+
eval_factcc(
|
| 313 |
+
tasks=args.tasks,
|
| 314 |
+
script_path=os.path.abspath(args.factcc_script),
|
| 315 |
+
test_data_path=os.path.abspath(args.factcc_test_data),
|
| 316 |
+
result_path=os.path.abspath(args.factcc_result_path)
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
if args.blanc:
|
| 320 |
+
if not args.blanc_batch_size:
|
| 321 |
+
argugment_error('--blanc-batch-size must be specified to run BLANC baseline')
|
| 322 |
+
eval_blanc(tasks=args.tasks, device=args.device, batch_size=args.blanc_batch_size)
|
| 323 |
+
|
| 324 |
+
if args.summac:
|
| 325 |
+
if not args.summac_type:
|
| 326 |
+
argugment_error('--summac-type must be specified to run SummaC baseline')
|
| 327 |
+
for type in args.summac_type:
|
| 328 |
+
eval_summac(tasks=args.tasks, device=args.device, summac_type=type)
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
if __name__ == "__main__":
|
| 332 |
+
FACT_EVAL_TASKS = ['summac', 'true','xsumfaith', 'summeval', 'qags_xsum', 'qags_cnndm', 'newsroom', 'rank19', 'frank', 'samsum']
|
| 333 |
+
|
| 334 |
+
parser = ArgumentParser()
|
| 335 |
+
parser.add_argument('--tasks', nargs='+', type=str, default=FACT_EVAL_TASKS, choices=FACT_EVAL_TASKS)
|
| 336 |
+
parser.add_argument('--device', type=str, default='cuda:0')
|
| 337 |
+
parser.add_argument('--timer', action='store_true', help='Time all metric runs')
|
| 338 |
+
|
| 339 |
+
alignscore_parser = parser.add_argument_group('AlignScore')
|
| 340 |
+
alignscore_parser.add_argument('--alignscore', action='store_true', help='Run AlignScore benchmark')
|
| 341 |
+
alignscore_parser.add_argument('--alignscore-model', type=str, choices=['roberta-base', 'roberta-large'])
|
| 342 |
+
alignscore_parser.add_argument('--alignscore-ckpt', type=str)
|
| 343 |
+
alignscore_parser.add_argument(
|
| 344 |
+
'--alignscore-eval-mode',
|
| 345 |
+
type=str,
|
| 346 |
+
choices=['bin', 'bin_sp', 'nli', 'nli_sp', 'reg', 'reg_sp', 'smart-n', 'smart-l'],
|
| 347 |
+
default='nli_sp'
|
| 348 |
+
)
|
| 349 |
+
alignscore_parser.add_argument('--alignscore-comment', type=str, default='')
|
| 350 |
+
|
| 351 |
+
ctc_parser = parser.add_argument_group('Baseline - CTC')
|
| 352 |
+
ctc_parser.add_argument('--ctc', action='store_true', help='Run CTC baseline')
|
| 353 |
+
ctc_parser.add_argument(
|
| 354 |
+
'--ctc-type',
|
| 355 |
+
nargs='*',
|
| 356 |
+
type=str,
|
| 357 |
+
choices=['D-cnndm', 'E-roberta', 'R-cnndm'],
|
| 358 |
+
default=['D-cnndm']
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
simcse_parser = parser.add_argument_group('Baseline - SimCSE')
|
| 362 |
+
simcse_models = [
|
| 363 |
+
'princeton-nlp/unsup-simcse-bert-base-uncased',
|
| 364 |
+
'princeton-nlp/unsup-simcse-bert-large-uncased',
|
| 365 |
+
'princeton-nlp/unsup-simcse-roberta-base',
|
| 366 |
+
'princeton-nlp/unsup-simcse-roberta-large',
|
| 367 |
+
'princeton-nlp/sup-simcse-bert-base-uncased',
|
| 368 |
+
'princeton-nlp/sup-simcse-bert-large-uncased',
|
| 369 |
+
'princeton-nlp/sup-simcse-roberta-base',
|
| 370 |
+
'princeton-nlp/sup-simcse-roberta-large'
|
| 371 |
+
]
|
| 372 |
+
simcse_parser.add_argument('--simcse', action='store_true', help='Run SimCSE baseline')
|
| 373 |
+
simcse_parser.add_argument(
|
| 374 |
+
'--simcse-ckpt',
|
| 375 |
+
nargs='*',
|
| 376 |
+
type=str,
|
| 377 |
+
choices=simcse_models,
|
| 378 |
+
default=['princeton-nlp/sup-simcse-roberta-large']
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
bleurt_parser = parser.add_argument_group('Baseline - BLEURT')
|
| 382 |
+
bleurt_parser.add_argument('--bleurt', action='store_true', help='Run BLEURT baseline')
|
| 383 |
+
bleurt_parser.add_argument('--bleurt-ckpt', type=str)
|
| 384 |
+
|
| 385 |
+
bertscore_parser = parser.add_argument_group('Baseline - BERTScore')
|
| 386 |
+
bertscore_parser.add_argument('--bertscore', action='store_true', help='Run BERTScore baseline')
|
| 387 |
+
bertscore_parser.add_argument(
|
| 388 |
+
'--bertscore-ckpt',
|
| 389 |
+
nargs='*',
|
| 390 |
+
type=str,
|
| 391 |
+
default=['microsoft/deberta-xlarge-mnli']
|
| 392 |
+
)
|
| 393 |
+
bertscore_parser.add_argument('--bertscore-batch-size', type=int, default=16)
|
| 394 |
+
|
| 395 |
+
bartscore_parser = parser.add_argument_group(
|
| 396 |
+
'Baseline - BARTScore',
|
| 397 |
+
description='Please clone https://github.com/neulab/BARTScore to baselines/BARTScore.'
|
| 398 |
+
)
|
| 399 |
+
bartscore_parser.add_argument('--bartscore', action='store_true', help='Run BARTScore baseline')
|
| 400 |
+
bartscore_parser.add_argument(
|
| 401 |
+
'--bartscore-ckpt',
|
| 402 |
+
type=str,
|
| 403 |
+
nargs='*',
|
| 404 |
+
default=['facebook/bart-large-cnn']
|
| 405 |
+
)
|
| 406 |
+
|
| 407 |
+
mnli_parser = parser.add_argument_group('Baseline - MNLI')
|
| 408 |
+
mnli_parser.add_argument('--mnli', action='store_true', help='Run MNLI baseline')
|
| 409 |
+
mnli_parser.add_argument(
|
| 410 |
+
'--mnli-ckpt',
|
| 411 |
+
nargs='*',
|
| 412 |
+
type=str,
|
| 413 |
+
default=['roberta-large-mnli']
|
| 414 |
+
)
|
| 415 |
+
|
| 416 |
+
ner_parser = parser.add_argument_group(
|
| 417 |
+
'Baseline - NER overlap',
|
| 418 |
+
description='Please clone https://github.com/tingofurro/summac to baselines/summac.'
|
| 419 |
+
)
|
| 420 |
+
ner_parser.add_argument('--ner', action='store_true', help='Run NER overlap baseline')
|
| 421 |
+
|
| 422 |
+
unieval_parser = parser.add_argument_group(
|
| 423 |
+
'Baseline - UniEval',
|
| 424 |
+
description='Please clone https://github.com/maszhongming/UniEval to baselines/UniEval.'
|
| 425 |
+
)
|
| 426 |
+
unieval_parser.add_argument('--unieval', action='store_true', help='Run UniEval baseline')
|
| 427 |
+
|
| 428 |
+
feqa_parser = parser.add_argument_group(
|
| 429 |
+
'Baseline - FEQA',
|
| 430 |
+
description='Please clone https://github.com/esdurmus/feqa to baselines/feqa'
|
| 431 |
+
)
|
| 432 |
+
feqa_parser.add_argument('--feqa', action='store_true', help='Run FEQA baseline')
|
| 433 |
+
|
| 434 |
+
questeval_parser = parser.add_argument_group(
|
| 435 |
+
'Baseline - QuestEval',
|
| 436 |
+
description='Please clone https://github.com/ThomasScialom/QuestEval to baselines/QuestEval.'
|
| 437 |
+
)
|
| 438 |
+
questeval_parser.add_argument('--questeval', action='store_true', help='Run QuestEval baseline')
|
| 439 |
+
|
| 440 |
+
qafacteval_parser = parser.add_argument_group(
|
| 441 |
+
'Baseline - QAFactEval',
|
| 442 |
+
description='Please clone https://github.com/salesforce/QAFactEval to baselines/QAFactEval.'
|
| 443 |
+
)
|
| 444 |
+
qafacteval_parser.add_argument('--qafacteval', action='store_true', help='Run QAFactEval baseline')
|
| 445 |
+
|
| 446 |
+
bleu_parser = parser.add_argument_group('Baseline - BLEU')
|
| 447 |
+
bleu_parser.add_argument('--bleu', action='store_true', help='Run BLEU baseline')
|
| 448 |
+
bleu_parser.add_argument(
|
| 449 |
+
'--bleu-ngram',
|
| 450 |
+
nargs='*',
|
| 451 |
+
type=int,
|
| 452 |
+
choices=[1, 2, 3, 4],
|
| 453 |
+
default=[1, 2, 3, 4]
|
| 454 |
+
)
|
| 455 |
+
|
| 456 |
+
rouge_parser = parser.add_argument_group('Baseline - ROUGE')
|
| 457 |
+
rouge_parser.add_argument('--rouge', action='store_true', help='Run ROUGE baseline')
|
| 458 |
+
rouge_parser.add_argument(
|
| 459 |
+
'--rouge-type',
|
| 460 |
+
nargs='*',
|
| 461 |
+
type=str,
|
| 462 |
+
choices=['1', '2', 'l'],
|
| 463 |
+
default=['1', '2', 'l']
|
| 464 |
+
)
|
| 465 |
+
|
| 466 |
+
dae_parser = parser.add_argument_group('Baseline - DAE')
|
| 467 |
+
dae_parser.add_argument('--dae', action='store_true', help='Run DAE baseline')
|
| 468 |
+
dae_parser.add_argument('--dae-ckpt', type=str)
|
| 469 |
+
|
| 470 |
+
factcc_parser = parser.add_argument_group('Baseline - FactCC')
|
| 471 |
+
factcc_parser.add_argument('--factcc', action='store_true', help='Run FactCC baseline')
|
| 472 |
+
factcc_parser.add_argument('--factcc-script', type=str)
|
| 473 |
+
factcc_parser.add_argument('--factcc-test-data', type=str)
|
| 474 |
+
factcc_parser.add_argument('--factcc-result-path', type=str)
|
| 475 |
+
|
| 476 |
+
blanc_parser = parser.add_argument_group('Baseline - BLANC')
|
| 477 |
+
blanc_parser.add_argument('--blanc', action='store_true', help='Run BLANC baseline')
|
| 478 |
+
blanc_parser.add_argument('--blanc-batch-size', type=int, default=64)
|
| 479 |
+
|
| 480 |
+
summac_parser = parser.add_argument_group(
|
| 481 |
+
'Baseline - SummaC',
|
| 482 |
+
description='Please clone https://github.com/tingofurro/summac to baselines/summac.'
|
| 483 |
+
)
|
| 484 |
+
summac_parser.add_argument('--summac', action='store_true', help='Run SummaC baseline')
|
| 485 |
+
summac_parser.add_argument('--summac-type', nargs='*', type=str, choices=['conv', 'zs'], default=['conv', 'zs'])
|
| 486 |
+
|
| 487 |
+
args = parser.parse_args()
|
| 488 |
+
if args.timer:
|
| 489 |
+
SAVE_AND_PRINT_TIMER = True
|
| 490 |
+
|
| 491 |
+
def argugment_error(msg):
|
| 492 |
+
parser.error(msg)
|
| 493 |
+
|
| 494 |
+
run_benchmarks(args, argugment_error)
|
alignscore/evaluate.py
ADDED
|
@@ -0,0 +1,1793 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from logging import warning
|
| 2 |
+
from datasets import load_dataset
|
| 3 |
+
from alignscore.inference import Inferencer
|
| 4 |
+
import numpy as np
|
| 5 |
+
from scipy.stats import pearsonr, kendalltau, spearmanr
|
| 6 |
+
from sklearn.metrics import accuracy_score, roc_auc_score, f1_score, balanced_accuracy_score, matthews_corrcoef
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import torch
|
| 9 |
+
import json
|
| 10 |
+
import pickle
|
| 11 |
+
import os
|
| 12 |
+
|
| 13 |
+
HUGGINGFACE_DATASETS = {
|
| 14 |
+
'stsb': ['glue', 'stsb', 'validation'],
|
| 15 |
+
'mrpc': ['glue', 'mrpc', 'test'],
|
| 16 |
+
'axb': ['super_glue', 'axb', 'test'],
|
| 17 |
+
'axg': ['super_glue', 'axg', 'test'],
|
| 18 |
+
'cb': ['super_glue', 'cb', 'validation'],
|
| 19 |
+
'rte': ['super_glue', 'rte', 'validation'],
|
| 20 |
+
'wnli': ['SetFit/wnli', 'validation'],
|
| 21 |
+
'paws': ['paws', 'labeled_final', 'test'],
|
| 22 |
+
'mnli_matched': ['multi_nli', 'validation_matched'],
|
| 23 |
+
'mnli_mismatched': ['multi_nli', 'validation_mismatched'],
|
| 24 |
+
'nli_fever': ['pietrolesci/nli_fever', 'dev'],
|
| 25 |
+
'doc_nli': ['saattrupdan/doc-nli', 'test'],
|
| 26 |
+
'sem_eval': ['sem_eval_2014_task_1', 'test'],
|
| 27 |
+
'sick': ['sick', 'default', 'test'],
|
| 28 |
+
'race_m': ['race', 'middle', 'test'],
|
| 29 |
+
'race_h': ['race', 'high', 'test'],
|
| 30 |
+
'boolq': ['boolq', 'validation'],
|
| 31 |
+
'anli_1': ['anli', 'test_r1'],
|
| 32 |
+
'anli_2': ['anli', 'test_r2'],
|
| 33 |
+
'anli_3': ['anli', 'test_r3'],
|
| 34 |
+
'snli': ['snli', 'test'],
|
| 35 |
+
'vitaminc': ['tals/vitaminc', 'test'],
|
| 36 |
+
'qqp': ['glue', 'qqp', 'validation'],
|
| 37 |
+
# below are tasks from https://arxiv.org/pdf/2104.14690.pdf
|
| 38 |
+
'sst2': ['SetFit/sst2', 'test'],
|
| 39 |
+
# can't find MR
|
| 40 |
+
'cr': ['SetFit/SentEval-CR', 'test'],
|
| 41 |
+
# can't find MPQA
|
| 42 |
+
'subj': ['SetFit/subj', 'test'],
|
| 43 |
+
# can't find OS
|
| 44 |
+
'imdb': ['SetFit/imdb', 'test'], # note: I can't confirm if this is the same dataset used in that paper
|
| 45 |
+
# The original dataset is no longer accessiable
|
| 46 |
+
'cola': ['glue', 'cola', 'validation'],
|
| 47 |
+
'yelp_efl': ['SetFit/yelp_review_full', 'test'],
|
| 48 |
+
'ag_news': ['SetFit/ag_news', 'test'],
|
| 49 |
+
'trec': ['SetFit/TREC-QC', 'test',],
|
| 50 |
+
'dream': ['dream', 'test'],
|
| 51 |
+
'quartz': ['quartz', 'test'],
|
| 52 |
+
'eraser_multi_rc': ['eraser_multi_rc', 'test'],
|
| 53 |
+
'quail': ['quail', 'challenge'],
|
| 54 |
+
'sciq': ['sciq', 'test'],
|
| 55 |
+
'gap': ['gap', 'test'],
|
| 56 |
+
'qnli': ['glue', 'qnli', 'validation']
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
PICKLE_DATASETS = [
|
| 60 |
+
'newsroom',
|
| 61 |
+
'rank19',
|
| 62 |
+
'bagel',
|
| 63 |
+
'sfhot',
|
| 64 |
+
'sfres'
|
| 65 |
+
]
|
| 66 |
+
|
| 67 |
+
ALL_TASKS = { # enumerate all possible tasks
|
| 68 |
+
'stsb': 0, ### using which output: regression, binary, tri-label
|
| 69 |
+
'sick': 0,
|
| 70 |
+
'race_m': 1,
|
| 71 |
+
'race_h': 1,
|
| 72 |
+
'boolq': 1,
|
| 73 |
+
'anli_1': 2,
|
| 74 |
+
'anli_2': 2,
|
| 75 |
+
'anli_3': 2,
|
| 76 |
+
'snli': 2,
|
| 77 |
+
'vitaminc': 2,
|
| 78 |
+
'mrpc': 1,
|
| 79 |
+
'paws': 1,
|
| 80 |
+
'mnli_matched': 2,
|
| 81 |
+
'mnli_mismatched': 2,
|
| 82 |
+
'sem_eval': 1,
|
| 83 |
+
'summeval': 1,
|
| 84 |
+
'qags_xsum': 1,
|
| 85 |
+
'qags_cnndm': 1,
|
| 86 |
+
'frank': 1,
|
| 87 |
+
'xsumfaith': 1,
|
| 88 |
+
'samsum': 1,
|
| 89 |
+
'yelp': 1,
|
| 90 |
+
'persona_chat': 1,
|
| 91 |
+
'topical_chat': 1,
|
| 92 |
+
'paws_qqp': 1,
|
| 93 |
+
'qqp': 1,
|
| 94 |
+
'newsroom': 1,
|
| 95 |
+
'rank19': 1,
|
| 96 |
+
'bagel': 1,
|
| 97 |
+
'sfhot': 1,
|
| 98 |
+
'sfres': 1,
|
| 99 |
+
'wmt17': 0,
|
| 100 |
+
'wmt18': 0,
|
| 101 |
+
'wmt19': 0,
|
| 102 |
+
'sst2': 1,
|
| 103 |
+
'cr': 1,
|
| 104 |
+
'subj': 1,
|
| 105 |
+
'imdb': 1,
|
| 106 |
+
'cola': 1,
|
| 107 |
+
'yelp_efl': 1,
|
| 108 |
+
'ag_news': 1,
|
| 109 |
+
'trec': 1,
|
| 110 |
+
'axb': 1,
|
| 111 |
+
'axg': 1,
|
| 112 |
+
'cb': 2,
|
| 113 |
+
'rte': 2,
|
| 114 |
+
'wnli': 2,
|
| 115 |
+
'dream': 1,
|
| 116 |
+
'quartz': 1,
|
| 117 |
+
'nli_fever': 2,
|
| 118 |
+
'doc_nli': 1,
|
| 119 |
+
'eraser_multi_rc': 1,
|
| 120 |
+
'quail': 1,
|
| 121 |
+
'sciq': 1,
|
| 122 |
+
'gap': 1,
|
| 123 |
+
'qnli': 1
|
| 124 |
+
}
|
| 125 |
+
|
| 126 |
+
FEW_SHOT_N = 8
|
| 127 |
+
FEW_SHOT_SEEDS = [30247, 38252, 29050, 1091, 35554, 25309, 79319, 35079, 35256, 46744]
|
| 128 |
+
|
| 129 |
+
class Evaluator():
|
| 130 |
+
def __init__(self, eval_tasks, align_func, save_all_tables=False, clean_data=True) -> None:
|
| 131 |
+
self.align_func = align_func
|
| 132 |
+
self.eval_tasks = eval_tasks # ['stsb', 'paws', ...]
|
| 133 |
+
self.result_save_name = "Default_result_name"
|
| 134 |
+
self.result_tables = []
|
| 135 |
+
self.result_dicts = []
|
| 136 |
+
self.clean_data = clean_data
|
| 137 |
+
self.init_eval_dataset()
|
| 138 |
+
|
| 139 |
+
self.should_save_all_tables = save_all_tables
|
| 140 |
+
warning(f"Saving the result is: {self.should_save_all_tables}")
|
| 141 |
+
|
| 142 |
+
def init_eval_dataset(self):
|
| 143 |
+
self.dataset = dict()
|
| 144 |
+
for eval_task in self.eval_tasks:
|
| 145 |
+
if eval_task in HUGGINGFACE_DATASETS:
|
| 146 |
+
if len(HUGGINGFACE_DATASETS[eval_task]) == 3:
|
| 147 |
+
self.dataset[eval_task] = load_dataset(HUGGINGFACE_DATASETS[eval_task][0], HUGGINGFACE_DATASETS[eval_task][1])[HUGGINGFACE_DATASETS[eval_task][2]]
|
| 148 |
+
elif len(HUGGINGFACE_DATASETS[eval_task]) == 2:
|
| 149 |
+
if isinstance(HUGGINGFACE_DATASETS[eval_task][1], tuple):
|
| 150 |
+
dataset = load_dataset(HUGGINGFACE_DATASETS[eval_task][0])
|
| 151 |
+
self.dataset[eval_task] = {split:dataset[split] for split in HUGGINGFACE_DATASETS[eval_task][1]}
|
| 152 |
+
else:
|
| 153 |
+
self.dataset[eval_task] = load_dataset(HUGGINGFACE_DATASETS[eval_task][0])[HUGGINGFACE_DATASETS[eval_task][1]]
|
| 154 |
+
|
| 155 |
+
elif eval_task == 'paws_qqp':
|
| 156 |
+
self.dataset[eval_task] = pd.read_csv('data/paws_qqp/output/dev_and_test.tsv', sep='\t')
|
| 157 |
+
elif eval_task == 'beir':
|
| 158 |
+
print("beir load by itself")
|
| 159 |
+
self.dataset[eval_task] = "BEIR Benchmark"
|
| 160 |
+
elif eval_task in PICKLE_DATASETS:
|
| 161 |
+
with open(f'data/eval/{eval_task}.pkl', 'rb') as f:
|
| 162 |
+
self.dataset[eval_task] = pickle.load(f)
|
| 163 |
+
elif 'wmt' in eval_task:
|
| 164 |
+
self.dataset[eval_task] = []
|
| 165 |
+
with open(f'data/eval/{eval_task}_eval.jsonl', 'r', encoding='utf8') as f:
|
| 166 |
+
for example in f:
|
| 167 |
+
self.dataset[eval_task].append(json.loads(example))
|
| 168 |
+
elif 'true' == eval_task:
|
| 169 |
+
for each_true_sub in os.listdir('data/eval/true'):
|
| 170 |
+
if 'qags' in each_true_sub:
|
| 171 |
+
each_true_sub_name = 'true_' + '_'.join(each_true_sub.split('_')[:2])
|
| 172 |
+
else:
|
| 173 |
+
each_true_sub_name = 'true_' + '_'.join(each_true_sub.split('_')[:1])
|
| 174 |
+
|
| 175 |
+
self.dataset[each_true_sub_name] = pd.read_csv(os.path.join('data/eval/true', each_true_sub))
|
| 176 |
+
elif 'summac' == eval_task:
|
| 177 |
+
from summac.benchmark import SummaCBenchmark
|
| 178 |
+
self.summac_validation_set = dict()
|
| 179 |
+
summac_benchmark = SummaCBenchmark(benchmark_folder="./data/eval/summac/benchmark", cut='test')
|
| 180 |
+
for each in summac_benchmark.datasets:
|
| 181 |
+
summac_dt_name = each['name']
|
| 182 |
+
self.dataset['summac_'+summac_dt_name] = each['dataset']
|
| 183 |
+
|
| 184 |
+
summac_benchmark_valid = SummaCBenchmark(benchmark_folder="./data/eval/summac/benchmark", cut='val')
|
| 185 |
+
for each in summac_benchmark_valid.datasets:
|
| 186 |
+
summac_dt_name = each['name']
|
| 187 |
+
self.summac_validation_set['summac_'+summac_dt_name] = each['dataset']
|
| 188 |
+
else:
|
| 189 |
+
f = open(f'data/eval/{eval_task}.json')
|
| 190 |
+
self.dataset[eval_task] = json.load(f)
|
| 191 |
+
f.close()
|
| 192 |
+
|
| 193 |
+
def print_result_table(self, table):
|
| 194 |
+
self.result_tables.append(pd.DataFrame(table).to_markdown())
|
| 195 |
+
self.result_dicts.append(table)
|
| 196 |
+
print(self.result_tables[-1])
|
| 197 |
+
|
| 198 |
+
def print_all_tables(self):
|
| 199 |
+
print("\n All Evaluation Results:")
|
| 200 |
+
for each in self.result_tables:
|
| 201 |
+
print(each)
|
| 202 |
+
print('='*100)
|
| 203 |
+
|
| 204 |
+
def save_all_tables(self):
|
| 205 |
+
with open(f'exp_results/{self.result_save_name}.pkl', 'wb') as f:
|
| 206 |
+
pickle.dump(self.result_dicts, f, protocol=pickle.HIGHEST_PROTOCOL)
|
| 207 |
+
|
| 208 |
+
def evaluate(self):
|
| 209 |
+
for each_task in self.dataset:
|
| 210 |
+
eval(f'self.evaluate_{each_task}()')
|
| 211 |
+
|
| 212 |
+
if self.should_save_all_tables:
|
| 213 |
+
self.save_all_tables()
|
| 214 |
+
|
| 215 |
+
def get_accuracy(self, true_score, pred_score):
|
| 216 |
+
return [accuracy_score(true_score, [m>0.5 for m in pred_score])]
|
| 217 |
+
|
| 218 |
+
def get_balanced_accuracy(self, true_score, pred_score, thres=0.5):
|
| 219 |
+
return [balanced_accuracy_score(true_score, [m>thres for m in pred_score])]
|
| 220 |
+
|
| 221 |
+
def get_f1(self, true_score, pred_score):
|
| 222 |
+
return [f1_score(true_score, [m>0.5 for m in pred_score])]
|
| 223 |
+
|
| 224 |
+
def get_3label_f1(self, true_score, pred_score):
|
| 225 |
+
return [f1_score(true_score, pred_score, average='micro')]
|
| 226 |
+
|
| 227 |
+
def get_pearson(self, true_score, pred_score):
|
| 228 |
+
return pearsonr(pred_score, true_score)
|
| 229 |
+
|
| 230 |
+
def get_kendalltau(self, true_score, pred_score):
|
| 231 |
+
return kendalltau(pred_score, true_score)
|
| 232 |
+
|
| 233 |
+
def get_spearman(self, true_score, pred_score):
|
| 234 |
+
return spearmanr(pred_score, true_score)
|
| 235 |
+
|
| 236 |
+
def get_matthews_corr(self, true_score, pred_score):
|
| 237 |
+
return [matthews_corrcoef(true_score, [s>0.5 for s in pred_score])]
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
def clean_text(self, context, claims):
|
| 241 |
+
from nltk.tokenize import sent_tokenize
|
| 242 |
+
|
| 243 |
+
if not self.clean_data:
|
| 244 |
+
return claims
|
| 245 |
+
|
| 246 |
+
word_cases = {token.lower():token for token in context.strip().split()}
|
| 247 |
+
|
| 248 |
+
def clean(text):
|
| 249 |
+
text = ' '.join(word_cases.get(token.lower(), token) for token in text.strip().split())
|
| 250 |
+
text = text.replace('“', '"').replace('”', '"').replace('’', '\'').replace('‘', '\'').replace('`', '\'').replace('-lrb-', '(').replace('-rrb-', ')')
|
| 251 |
+
text= ' '.join(each.strip()[0].capitalize()+each.strip()[1:] for each in sent_tokenize(text))
|
| 252 |
+
return text
|
| 253 |
+
|
| 254 |
+
if isinstance(claims, str):
|
| 255 |
+
return clean(claims)
|
| 256 |
+
|
| 257 |
+
return [clean(text) for text in claims]
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def evaluate_newsroom(self):
|
| 261 |
+
true_score = []
|
| 262 |
+
true_score_rel = []
|
| 263 |
+
true_score_binary = []
|
| 264 |
+
sent1 = []
|
| 265 |
+
sent2 = []
|
| 266 |
+
|
| 267 |
+
for sample in self.dataset['newsroom'].values():
|
| 268 |
+
summaries, informativeness, relevance = zip(*(
|
| 269 |
+
(s['sys_summ'], s['scores']['informativeness'], s['scores']['relevance'])
|
| 270 |
+
for s in sample['sys_summs'].values()
|
| 271 |
+
))
|
| 272 |
+
cleaned_summaries = self.clean_text(sample['src'], summaries)
|
| 273 |
+
for summary, inf_score, rel_score in zip(cleaned_summaries, informativeness, relevance):
|
| 274 |
+
sent1.append(sample['src'])
|
| 275 |
+
sent2.append(summary)
|
| 276 |
+
true_score.append(inf_score)
|
| 277 |
+
true_score_rel.append(rel_score)
|
| 278 |
+
true_score_binary.append(int(inf_score >= 4))
|
| 279 |
+
|
| 280 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['newsroom']].tolist()
|
| 281 |
+
|
| 282 |
+
self.print_result_table({
|
| 283 |
+
'Dataset_name': 'newsroom',
|
| 284 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 285 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 286 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 287 |
+
'AUC': roc_auc_score(true_score_binary, pred_score),
|
| 288 |
+
'Pearson_rel': self.get_pearson(true_score_rel, pred_score),
|
| 289 |
+
'Spearman_rel': self.get_spearman(true_score_rel, pred_score),
|
| 290 |
+
'Kendall_rel': self.get_kendalltau(true_score_rel, pred_score),
|
| 291 |
+
})
|
| 292 |
+
|
| 293 |
+
def evaluate_rank19(self):
|
| 294 |
+
def chunks(lst, n):
|
| 295 |
+
"""Yield successive n-sized chunks from lst."""
|
| 296 |
+
for i in range(0, len(lst), n):
|
| 297 |
+
yield lst[i:i + n]
|
| 298 |
+
true_score = []
|
| 299 |
+
sent1 = []
|
| 300 |
+
sent2 = []
|
| 301 |
+
|
| 302 |
+
for example in self.dataset['rank19']:
|
| 303 |
+
for example_summs in self.dataset['rank19'][example]['sys_summs']:
|
| 304 |
+
sent1.append(self.dataset['rank19'][example]['src'])
|
| 305 |
+
sent2.append(self.dataset['rank19'][example]['sys_summs'][example_summs]['sys_summ'])
|
| 306 |
+
true_score.append(self.dataset['rank19'][example]['sys_summs'][example_summs]['scores']['fact'])
|
| 307 |
+
|
| 308 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['rank19']].tolist()
|
| 309 |
+
pred_score_bin = []
|
| 310 |
+
assert len(pred_score) % 2 == 0
|
| 311 |
+
for i, pair in enumerate(chunks(pred_score, 2)):
|
| 312 |
+
pred_score_bin.extend([0, 1] if pair[1] > pair[0] else [1, 0])
|
| 313 |
+
|
| 314 |
+
self.print_result_table({
|
| 315 |
+
'Dataset_name': 'rank19',
|
| 316 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 317 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 318 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 319 |
+
'Accuracy': self.get_accuracy(true_score, pred_score_bin)[0],
|
| 320 |
+
'AUC': roc_auc_score(true_score, pred_score_bin)
|
| 321 |
+
})
|
| 322 |
+
|
| 323 |
+
def evaluate_bagel(self):
|
| 324 |
+
true_score = []
|
| 325 |
+
true_score_binary = []
|
| 326 |
+
sent1 = []
|
| 327 |
+
sent2 = []
|
| 328 |
+
pred_score = []
|
| 329 |
+
|
| 330 |
+
for example in self.dataset['bagel']:
|
| 331 |
+
sent1.append(' '.join(self.dataset['bagel'][example]['ref_summs']))
|
| 332 |
+
sent2.append(self.dataset['bagel'][example]['sys_summ'])
|
| 333 |
+
true_score.append(self.dataset['bagel'][example]['scores']['informativeness'])
|
| 334 |
+
|
| 335 |
+
if(self.dataset['bagel'][example]['scores']['informativeness'] >= 4.0):
|
| 336 |
+
true_score_binary.append(1)
|
| 337 |
+
else:
|
| 338 |
+
true_score_binary.append(0)
|
| 339 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['bagel']].tolist()
|
| 340 |
+
|
| 341 |
+
self.print_result_table({
|
| 342 |
+
'Dataset_name': 'bagel',
|
| 343 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 344 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 345 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 346 |
+
'AUC': roc_auc_score(true_score_binary, pred_score)
|
| 347 |
+
})
|
| 348 |
+
|
| 349 |
+
def evaluate_sfhot(self):
|
| 350 |
+
true_score = []
|
| 351 |
+
sent1 = []
|
| 352 |
+
sent2 = []
|
| 353 |
+
pred_score = []
|
| 354 |
+
|
| 355 |
+
for example in self.dataset['sfhot']:
|
| 356 |
+
for ref in self.dataset['sfhot'][example]['ref_summs']:
|
| 357 |
+
sent1.append(self.dataset['sfhot'][example]['sys_summ'])
|
| 358 |
+
sent2.append(ref)
|
| 359 |
+
pred_score.append(max(self.align_func(sent1, sent2)[ALL_TASKS['sfhot']].tolist()))
|
| 360 |
+
sent1 = []
|
| 361 |
+
sent2 = []
|
| 362 |
+
if(self.dataset['sfhot'][example]['scores']['quality'] >= 4.0):
|
| 363 |
+
true_score.append(1)
|
| 364 |
+
else:
|
| 365 |
+
true_score.append(0)
|
| 366 |
+
|
| 367 |
+
self.print_result_table({
|
| 368 |
+
'Dataset_name': 'sfhot',
|
| 369 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 370 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 371 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 372 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 373 |
+
})
|
| 374 |
+
|
| 375 |
+
def evaluate_sfres(self):
|
| 376 |
+
true_score = []
|
| 377 |
+
sent1 = []
|
| 378 |
+
sent2 = []
|
| 379 |
+
pred_score = []
|
| 380 |
+
|
| 381 |
+
for example in self.dataset['sfres']:
|
| 382 |
+
for ref in self.dataset['sfres'][example]['ref_summs']:
|
| 383 |
+
sent1.append(self.dataset['sfres'][example]['sys_summ'])
|
| 384 |
+
sent2.append(ref)
|
| 385 |
+
pred_score.append(max(self.align_func(sent1, sent2)[ALL_TASKS['sfres']].tolist()))
|
| 386 |
+
sent1 = []
|
| 387 |
+
sent2 = []
|
| 388 |
+
if(self.dataset['sfres'][example]['scores']['quality'] >= 4.0):
|
| 389 |
+
true_score.append(1)
|
| 390 |
+
else:
|
| 391 |
+
true_score.append(0)
|
| 392 |
+
|
| 393 |
+
self.print_result_table({
|
| 394 |
+
'Dataset_name': 'sfres',
|
| 395 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 396 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 397 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 398 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 399 |
+
})
|
| 400 |
+
|
| 401 |
+
|
| 402 |
+
def evaluate_stsb(self):
|
| 403 |
+
true_score = []
|
| 404 |
+
sent1 = []
|
| 405 |
+
sent2 = []
|
| 406 |
+
for example in self.dataset['stsb']:
|
| 407 |
+
sent1.append(example['sentence1'])
|
| 408 |
+
sent2.append(example['sentence2'])
|
| 409 |
+
true_score.append(example['label'])
|
| 410 |
+
|
| 411 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['stsb']].tolist()
|
| 412 |
+
|
| 413 |
+
self.print_result_table({
|
| 414 |
+
'Dataset_name': 'stsb',
|
| 415 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 416 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 417 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 418 |
+
})
|
| 419 |
+
|
| 420 |
+
def evaluate_sick(self):
|
| 421 |
+
true_score = []
|
| 422 |
+
sent1 = []
|
| 423 |
+
sent2 = []
|
| 424 |
+
for example in self.dataset['sick']:
|
| 425 |
+
sent1.append(example['sentence_A'])
|
| 426 |
+
sent2.append(example['sentence_B'])
|
| 427 |
+
true_score.append(example['relatedness_score'])
|
| 428 |
+
|
| 429 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['sick']].tolist()
|
| 430 |
+
|
| 431 |
+
self.print_result_table({
|
| 432 |
+
'Dataset_name': 'sick-r',
|
| 433 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 434 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 435 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 436 |
+
})
|
| 437 |
+
|
| 438 |
+
def evaluate_race_m(self):
|
| 439 |
+
true_score = []
|
| 440 |
+
article = []
|
| 441 |
+
qa = []
|
| 442 |
+
|
| 443 |
+
for example in self.dataset['race_m']:
|
| 444 |
+
for i, option in enumerate(example['options']):
|
| 445 |
+
article.append(example['article'])
|
| 446 |
+
qa.append(example['question']+" "+option+" " if "_" not in example['question'] else ' '.join(example['question'].replace("_", " "+option+" ").split()))
|
| 447 |
+
if i == ord(example['answer'])-65:
|
| 448 |
+
true_score.append(i) # 0,1,2,3
|
| 449 |
+
|
| 450 |
+
pred_score = []
|
| 451 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['race_m']].tolist()
|
| 452 |
+
for a, b, c, d in zip(*[iter(pred_score_temp)]*4):
|
| 453 |
+
arr = [0]*4
|
| 454 |
+
pred_score.append(np.argmax([a,b,c,d]))
|
| 455 |
+
|
| 456 |
+
assert len(pred_score) == len(true_score)
|
| 457 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 458 |
+
acc = sum(acc) / len(acc)
|
| 459 |
+
|
| 460 |
+
self.print_result_table({
|
| 461 |
+
'Dataset_name': 'race-m',
|
| 462 |
+
'Accuracy': [acc],
|
| 463 |
+
})
|
| 464 |
+
|
| 465 |
+
def evaluate_race_h(self):
|
| 466 |
+
true_score = []
|
| 467 |
+
article = []
|
| 468 |
+
qa = []
|
| 469 |
+
|
| 470 |
+
for example in self.dataset['race_h']:
|
| 471 |
+
for i, option in enumerate(example['options']):
|
| 472 |
+
article.append(example['article'])
|
| 473 |
+
qa.append(example['question']+" "+option+" " if "_" not in example['question'] else ' '.join(example['question'].replace("_", " "+option+" ").split()))
|
| 474 |
+
if i == ord(example['answer'])-65:
|
| 475 |
+
true_score.append(i) # 0,1,2,3
|
| 476 |
+
|
| 477 |
+
pred_score = []
|
| 478 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['race_h']].tolist()
|
| 479 |
+
for a, b, c, d in zip(*[iter(pred_score_temp)]*4):
|
| 480 |
+
pred_score.append(np.argmax([a,b,c,d]))
|
| 481 |
+
|
| 482 |
+
assert len(pred_score) == len(true_score)
|
| 483 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 484 |
+
acc = sum(acc) / len(acc)
|
| 485 |
+
|
| 486 |
+
self.print_result_table({
|
| 487 |
+
'Dataset_name': 'race-h',
|
| 488 |
+
'Accuracy': [acc]
|
| 489 |
+
})
|
| 490 |
+
|
| 491 |
+
# How to combine passage, question, and single answer for boolq
|
| 492 |
+
def evaluate_boolq(self):
|
| 493 |
+
true_score = []
|
| 494 |
+
article = []
|
| 495 |
+
qa = []
|
| 496 |
+
for example in self.dataset['boolq']:
|
| 497 |
+
for i in range(2):
|
| 498 |
+
article.append(example['passage'])
|
| 499 |
+
if i == 0:
|
| 500 |
+
qa.append(example['question']+" "+"No.") # 0
|
| 501 |
+
else:
|
| 502 |
+
qa.append(example['question']+" "+"Yes.") # 1
|
| 503 |
+
true_score.append(int(example['answer']))
|
| 504 |
+
|
| 505 |
+
pred_score = []
|
| 506 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['boolq']].tolist()
|
| 507 |
+
for a, b in zip(*[iter(pred_score_temp)]*2):
|
| 508 |
+
pred_score.append(np.argmax([a,b]))
|
| 509 |
+
|
| 510 |
+
assert len(pred_score) == len(true_score)
|
| 511 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 512 |
+
acc = sum(acc) / len(acc)
|
| 513 |
+
self.print_result_table({
|
| 514 |
+
'Dataset_name': 'boolq',
|
| 515 |
+
'Accuracy': [acc]
|
| 516 |
+
})
|
| 517 |
+
|
| 518 |
+
def evaluate_anli_1(self):
|
| 519 |
+
true_score = []
|
| 520 |
+
sent1 = []
|
| 521 |
+
sent2 = []
|
| 522 |
+
for example in self.dataset['anli_1']:
|
| 523 |
+
sent1.append(example['premise'])
|
| 524 |
+
sent2.append(example['hypothesis'])
|
| 525 |
+
true_score.append(example['label'] if example['label']!=-1 else 1)
|
| 526 |
+
|
| 527 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['anli_1']], dim=-1).tolist()
|
| 528 |
+
|
| 529 |
+
self.print_result_table({
|
| 530 |
+
'Dataset_name': 'anli-1',
|
| 531 |
+
'Accuracy': [accuracy_score(true_score, pred_score)]
|
| 532 |
+
})
|
| 533 |
+
|
| 534 |
+
def evaluate_anli_2(self):
|
| 535 |
+
true_score = []
|
| 536 |
+
sent1 = []
|
| 537 |
+
sent2 = []
|
| 538 |
+
for example in self.dataset['anli_2']:
|
| 539 |
+
sent1.append(example['premise'])
|
| 540 |
+
sent2.append(example['hypothesis'])
|
| 541 |
+
true_score.append(example['label'] if example['label']!=-1 else 1)
|
| 542 |
+
|
| 543 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['anli_2']], dim=-1).tolist()
|
| 544 |
+
|
| 545 |
+
self.print_result_table({
|
| 546 |
+
'Dataset_name': 'anli-2',
|
| 547 |
+
'Accuracy': [accuracy_score(true_score, pred_score)]
|
| 548 |
+
})
|
| 549 |
+
|
| 550 |
+
def evaluate_anli_3(self):
|
| 551 |
+
true_score = []
|
| 552 |
+
sent1 = []
|
| 553 |
+
sent2 = []
|
| 554 |
+
for example in self.dataset['anli_3']:
|
| 555 |
+
sent1.append(example['premise'])
|
| 556 |
+
sent2.append(example['hypothesis'])
|
| 557 |
+
true_score.append(example['label'] if example['label']!=-1 else 1)
|
| 558 |
+
|
| 559 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['anli_3']], dim=-1).tolist()
|
| 560 |
+
|
| 561 |
+
self.print_result_table({
|
| 562 |
+
'Dataset_name': 'anli-3',
|
| 563 |
+
'Accuracy': [accuracy_score(true_score, pred_score)]
|
| 564 |
+
})
|
| 565 |
+
|
| 566 |
+
def evaluate_nli_fever(self):
|
| 567 |
+
true_score = []
|
| 568 |
+
sent1 = []
|
| 569 |
+
sent2 = []
|
| 570 |
+
for example in self.dataset['nli_fever']:
|
| 571 |
+
sent1.append(example['hypothesis']) # the original dataset flipped
|
| 572 |
+
sent2.append(example['premise'])
|
| 573 |
+
true_score.append(example['label'] if example['label']!=-1 else 1)
|
| 574 |
+
|
| 575 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['nli_fever']], dim=-1).tolist()
|
| 576 |
+
|
| 577 |
+
self.print_result_table({
|
| 578 |
+
'Dataset_name': 'nli_fever',
|
| 579 |
+
'Accuracy': [accuracy_score(true_score, pred_score)]
|
| 580 |
+
})
|
| 581 |
+
|
| 582 |
+
def evaluate_snli(self):
|
| 583 |
+
true_score = []
|
| 584 |
+
sent1 = []
|
| 585 |
+
sent2 = []
|
| 586 |
+
for example in self.dataset['snli']:
|
| 587 |
+
sent1.append(example['premise'])
|
| 588 |
+
sent2.append(example['hypothesis'])
|
| 589 |
+
true_score.append(example['label'] if example['label']!=-1 else 1)
|
| 590 |
+
|
| 591 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['snli']], dim=-1).tolist()
|
| 592 |
+
|
| 593 |
+
self.print_result_table({
|
| 594 |
+
'Dataset_name': 'snli',
|
| 595 |
+
'Accuracy': [accuracy_score(true_score, pred_score)]
|
| 596 |
+
})
|
| 597 |
+
|
| 598 |
+
def evaluate_axb(self):
|
| 599 |
+
true_score = []
|
| 600 |
+
sent1 = []
|
| 601 |
+
sent2 = []
|
| 602 |
+
for example in self.dataset['axb']:
|
| 603 |
+
sent1.append(example['sentence1'])
|
| 604 |
+
sent2.append(example['sentence2'])
|
| 605 |
+
|
| 606 |
+
true_score.append(1 if example['label']==0 else 0)
|
| 607 |
+
|
| 608 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['axb']].tolist()
|
| 609 |
+
|
| 610 |
+
self.print_result_table({
|
| 611 |
+
'Dataset_name': 'axb',
|
| 612 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 613 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 614 |
+
'AUC': [roc_auc_score(true_score, pred_score)],
|
| 615 |
+
'Matthews': self.get_matthews_corr(true_score, pred_score)
|
| 616 |
+
})
|
| 617 |
+
|
| 618 |
+
def evaluate_axg(self):
|
| 619 |
+
true_score = []
|
| 620 |
+
sent1 = []
|
| 621 |
+
sent2 = []
|
| 622 |
+
for example in self.dataset['axg']:
|
| 623 |
+
sent1.append(example['premise'])
|
| 624 |
+
sent2.append(example['hypothesis'])
|
| 625 |
+
|
| 626 |
+
true_score.append(1 if example['label']==0 else 0)
|
| 627 |
+
|
| 628 |
+
pred_score = self.align_func(sent1, sent2)[2][:,0].tolist()
|
| 629 |
+
|
| 630 |
+
self.print_result_table({
|
| 631 |
+
'Dataset_name': 'axg',
|
| 632 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 633 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 634 |
+
'AUC': [roc_auc_score(true_score, pred_score)],
|
| 635 |
+
})
|
| 636 |
+
|
| 637 |
+
def evaluate_cb(self):
|
| 638 |
+
true_score = []
|
| 639 |
+
sent1 = []
|
| 640 |
+
sent2 = []
|
| 641 |
+
|
| 642 |
+
for example in self.dataset['cb']:
|
| 643 |
+
sent1.append(example['premise'])
|
| 644 |
+
sent2.append(example['hypothesis'])
|
| 645 |
+
|
| 646 |
+
if example['label'] == 0:
|
| 647 |
+
label = 0
|
| 648 |
+
elif example['label'] == 1:
|
| 649 |
+
label = 2
|
| 650 |
+
elif example['label'] == 2:
|
| 651 |
+
label = 1
|
| 652 |
+
|
| 653 |
+
true_score.append(label)
|
| 654 |
+
|
| 655 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['cb']], dim=-1).tolist()
|
| 656 |
+
|
| 657 |
+
self.print_result_table({
|
| 658 |
+
'Dataset_name': 'cb',
|
| 659 |
+
'Accuracy': [accuracy_score(true_score, pred_score)],
|
| 660 |
+
})
|
| 661 |
+
|
| 662 |
+
def evaluate_rte(self):
|
| 663 |
+
true_score = []
|
| 664 |
+
sent1 = []
|
| 665 |
+
sent2 = []
|
| 666 |
+
for example in self.dataset['rte']:
|
| 667 |
+
sent1.append(example['premise'])
|
| 668 |
+
sent2.append(example['hypothesis'])
|
| 669 |
+
|
| 670 |
+
true_score.append(1 if example['label']==0 else 0)
|
| 671 |
+
|
| 672 |
+
pred_score = self.align_func(sent1, sent2)[2][:,0].tolist()
|
| 673 |
+
|
| 674 |
+
self.print_result_table({
|
| 675 |
+
'Dataset_name': 'rte',
|
| 676 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 677 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 678 |
+
'AUC': [roc_auc_score(true_score, pred_score)],
|
| 679 |
+
})
|
| 680 |
+
|
| 681 |
+
def evaluate_wnli(self):
|
| 682 |
+
true_score = []
|
| 683 |
+
sent1 = []
|
| 684 |
+
sent2 = []
|
| 685 |
+
for example in self.dataset['wnli']:
|
| 686 |
+
sent1.append(example['text1'])
|
| 687 |
+
sent2.append(example['text2'])
|
| 688 |
+
|
| 689 |
+
true_score.append(example['label'])
|
| 690 |
+
|
| 691 |
+
pred_score = self.align_func(sent1, sent2)[2][:,0].tolist()
|
| 692 |
+
|
| 693 |
+
self.print_result_table({
|
| 694 |
+
'Dataset_name': 'wnli',
|
| 695 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 696 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 697 |
+
'AUC': [roc_auc_score(true_score, pred_score)],
|
| 698 |
+
})
|
| 699 |
+
|
| 700 |
+
def evaluate_doc_nli(self):
|
| 701 |
+
true_score = []
|
| 702 |
+
sent1 = []
|
| 703 |
+
sent2 = []
|
| 704 |
+
for example in self.dataset['doc_nli']:
|
| 705 |
+
sent1.append(example['premise'])
|
| 706 |
+
sent2.append(example['hypothesis'])
|
| 707 |
+
|
| 708 |
+
true_score.append(1 if example['label'] == 'entailment' else 0)
|
| 709 |
+
|
| 710 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['doc_nli']].tolist()
|
| 711 |
+
|
| 712 |
+
self.print_result_table({
|
| 713 |
+
'Dataset_name': 'doc_nli',
|
| 714 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 715 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 716 |
+
'AUC': [roc_auc_score(true_score, pred_score)],
|
| 717 |
+
})
|
| 718 |
+
|
| 719 |
+
def evaluate_qnli(self):
|
| 720 |
+
true_score = []
|
| 721 |
+
sent1 = []
|
| 722 |
+
sent2 = []
|
| 723 |
+
for example in self.dataset['qnli']:
|
| 724 |
+
sent1.append(example['sentence'])
|
| 725 |
+
sent2.append(example['question'])
|
| 726 |
+
|
| 727 |
+
true_score.append(1 if example['label'] == 0 else 0)
|
| 728 |
+
|
| 729 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['qnli']].tolist()
|
| 730 |
+
|
| 731 |
+
self.print_result_table({
|
| 732 |
+
'Dataset_name': 'qnli',
|
| 733 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 734 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 735 |
+
'AUC': [roc_auc_score(true_score, pred_score)],
|
| 736 |
+
})
|
| 737 |
+
|
| 738 |
+
def evaluate_dream(self):
|
| 739 |
+
true_score = []
|
| 740 |
+
article = []
|
| 741 |
+
qa = []
|
| 742 |
+
|
| 743 |
+
for example in self.dataset['dream']:
|
| 744 |
+
for i, option in enumerate(example['choice']):
|
| 745 |
+
article.append(' '.join(example['dialogue']))
|
| 746 |
+
qa.append(example['question']+" "+option+" ")
|
| 747 |
+
if option == example['answer']:
|
| 748 |
+
true_score.append(i) # 0,1,2,3
|
| 749 |
+
|
| 750 |
+
pred_score = []
|
| 751 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['dream']].tolist()
|
| 752 |
+
for a, b, c in zip(*[iter(pred_score_temp)]*3):
|
| 753 |
+
arr = [0]*3
|
| 754 |
+
pred_score.append(np.argmax([a,b,c]))
|
| 755 |
+
|
| 756 |
+
assert len(pred_score) == len(true_score)
|
| 757 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 758 |
+
acc = sum(acc) / len(acc)
|
| 759 |
+
|
| 760 |
+
self.print_result_table({
|
| 761 |
+
'Dataset_name': 'dream',
|
| 762 |
+
'Accuracy': [acc],
|
| 763 |
+
})
|
| 764 |
+
|
| 765 |
+
def evaluate_quartz(self):
|
| 766 |
+
true_score = []
|
| 767 |
+
article = []
|
| 768 |
+
qa = []
|
| 769 |
+
|
| 770 |
+
for example in self.dataset['quartz']:
|
| 771 |
+
for i, option in enumerate(example['choices']['text']):
|
| 772 |
+
article.append(example['para'])
|
| 773 |
+
qa.append(example['question']+" "+option+" ")
|
| 774 |
+
if i == ord(example['answerKey'])-65:
|
| 775 |
+
true_score.append(i) # 0,1,2,3
|
| 776 |
+
|
| 777 |
+
pred_score = []
|
| 778 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['quartz']].tolist()
|
| 779 |
+
for a, b in zip(*[iter(pred_score_temp)]*2):
|
| 780 |
+
arr = [0]*2
|
| 781 |
+
pred_score.append(np.argmax([a,b]))
|
| 782 |
+
|
| 783 |
+
assert len(pred_score) == len(true_score)
|
| 784 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 785 |
+
acc = sum(acc) / len(acc)
|
| 786 |
+
|
| 787 |
+
self.print_result_table({
|
| 788 |
+
'Dataset_name': 'quartz',
|
| 789 |
+
'Accuracy': [acc],
|
| 790 |
+
})
|
| 791 |
+
def evaluate_eraser_multi_rc(self):
|
| 792 |
+
true_score = []
|
| 793 |
+
sent1 = []
|
| 794 |
+
sent2 = []
|
| 795 |
+
for example in self.dataset['eraser_multi_rc']:
|
| 796 |
+
sent1.append(example['passage'])
|
| 797 |
+
sent2.append(example['query_and_answer'].replace("|", ""))
|
| 798 |
+
true_score.append(example['label'])
|
| 799 |
+
|
| 800 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['eraser_multi_rc']].tolist()
|
| 801 |
+
|
| 802 |
+
self.print_result_table({
|
| 803 |
+
'Dataset_name': 'eraser_multi_rc',
|
| 804 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 805 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 806 |
+
'AUC': [roc_auc_score(true_score, pred_score)]
|
| 807 |
+
})
|
| 808 |
+
|
| 809 |
+
def evaluate_quail(self):
|
| 810 |
+
true_score = []
|
| 811 |
+
article = []
|
| 812 |
+
qa = []
|
| 813 |
+
|
| 814 |
+
for example in self.dataset['quail']:
|
| 815 |
+
for i, option in enumerate(example['answers']):
|
| 816 |
+
article.append(example['context'])
|
| 817 |
+
qa.append(example['question']+" "+option+" ")
|
| 818 |
+
if i == example['correct_answer_id']:
|
| 819 |
+
true_score.append(i) # 0,1,2,3
|
| 820 |
+
|
| 821 |
+
pred_score = []
|
| 822 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['quail']].tolist()
|
| 823 |
+
for a, b, c, d in zip(*[iter(pred_score_temp)]*4):
|
| 824 |
+
arr = [0]*4
|
| 825 |
+
pred_score.append(np.argmax([a,b,c,d]))
|
| 826 |
+
|
| 827 |
+
assert len(pred_score) == len(true_score)
|
| 828 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 829 |
+
acc = sum(acc) / len(acc)
|
| 830 |
+
|
| 831 |
+
self.print_result_table({
|
| 832 |
+
'Dataset_name': 'quail',
|
| 833 |
+
'Accuracy': [acc],
|
| 834 |
+
})
|
| 835 |
+
|
| 836 |
+
def evaluate_sciq(self):
|
| 837 |
+
true_score = []
|
| 838 |
+
article = []
|
| 839 |
+
qa = []
|
| 840 |
+
|
| 841 |
+
for example in self.dataset['sciq']:
|
| 842 |
+
options = [example['correct_answer'], example['distractor1'], example['distractor2'], example['distractor3']]
|
| 843 |
+
for i, option in enumerate(options):
|
| 844 |
+
article.append(example['support'])
|
| 845 |
+
qa.append(example['question']+" "+option+" ")
|
| 846 |
+
if i == 0:
|
| 847 |
+
true_score.append(i) # 0,1,2,3, always 0
|
| 848 |
+
|
| 849 |
+
pred_score = []
|
| 850 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['sciq']].tolist()
|
| 851 |
+
for a, b, c, d in zip(*[iter(pred_score_temp)]*4):
|
| 852 |
+
arr = [0]*4
|
| 853 |
+
pred_score.append(np.argmax([a,b,c,d]))
|
| 854 |
+
|
| 855 |
+
assert len(pred_score) == len(true_score)
|
| 856 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 857 |
+
acc = sum(acc) / len(acc)
|
| 858 |
+
|
| 859 |
+
self.print_result_table({
|
| 860 |
+
'Dataset_name': 'sciq',
|
| 861 |
+
'Accuracy': [acc],
|
| 862 |
+
})
|
| 863 |
+
|
| 864 |
+
def evaluate_gap(self):
|
| 865 |
+
true_score = []
|
| 866 |
+
article = []
|
| 867 |
+
qa = []
|
| 868 |
+
|
| 869 |
+
for example in self.dataset['gap']:
|
| 870 |
+
options = [example['Text'][:example['Pronoun-offset']]+example['A']+example['Text'][(example['Pronoun-offset']+len(example['Pronoun'])):],
|
| 871 |
+
example['Text'][:example['Pronoun-offset']]+example['B']+example['Text'][(example['Pronoun-offset']+len(example['Pronoun'])):]]
|
| 872 |
+
for i, option in enumerate(options):
|
| 873 |
+
article.append(example['Text'])
|
| 874 |
+
qa.append(option)
|
| 875 |
+
|
| 876 |
+
true_score.append(1 if example['B-coref'] else 0) # 0,1,2,3, always 0
|
| 877 |
+
|
| 878 |
+
pred_score = []
|
| 879 |
+
pred_score_temp = self.align_func(article, qa)[ALL_TASKS['gap']].tolist()
|
| 880 |
+
for a, b in zip(*[iter(pred_score_temp)]*2):
|
| 881 |
+
pred_score.append(np.argmax([a,b]))
|
| 882 |
+
|
| 883 |
+
assert len(pred_score) == len(true_score)
|
| 884 |
+
acc = [int(p==t) for p, t in zip(pred_score, true_score)]
|
| 885 |
+
acc = sum(acc) / len(acc)
|
| 886 |
+
|
| 887 |
+
self.print_result_table({
|
| 888 |
+
'Dataset_name': 'gap',
|
| 889 |
+
'Accuracy': [acc],
|
| 890 |
+
})
|
| 891 |
+
|
| 892 |
+
# How to group fact checking
|
| 893 |
+
def evaluate_vitaminc(self):
|
| 894 |
+
true_score = []
|
| 895 |
+
sent1 = []
|
| 896 |
+
sent2 = []
|
| 897 |
+
for example in self.dataset['vitaminc']:
|
| 898 |
+
sent1.append(example['evidence'])
|
| 899 |
+
sent2.append(example['claim'])
|
| 900 |
+
if example['label'] == 'SUPPORTS':
|
| 901 |
+
true_score.append(0)
|
| 902 |
+
elif example['label'] == 'REFUTES':
|
| 903 |
+
true_score.append(2)
|
| 904 |
+
else:
|
| 905 |
+
true_score.append(1)
|
| 906 |
+
|
| 907 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['vitaminc']], dim=-1).tolist()
|
| 908 |
+
|
| 909 |
+
self.print_result_table({
|
| 910 |
+
'Dataset_name': 'vitaminc',
|
| 911 |
+
'F1': self.get_3label_f1(true_score, pred_score),
|
| 912 |
+
'Accuracy': [accuracy_score(true_score, pred_score)],
|
| 913 |
+
})
|
| 914 |
+
|
| 915 |
+
def evaluate_mrpc(self):
|
| 916 |
+
true_score = []
|
| 917 |
+
sent1 = []
|
| 918 |
+
sent2 = []
|
| 919 |
+
for example in self.dataset['mrpc']:
|
| 920 |
+
sent1.append(example['sentence1'])
|
| 921 |
+
sent2.append(example['sentence2'])
|
| 922 |
+
true_score.append(example['label'])
|
| 923 |
+
|
| 924 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['mrpc']].tolist()
|
| 925 |
+
|
| 926 |
+
self.print_result_table({
|
| 927 |
+
'Dataset_name': 'mrpc',
|
| 928 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 929 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 930 |
+
'AUC': [roc_auc_score(true_score, pred_score)]
|
| 931 |
+
})
|
| 932 |
+
|
| 933 |
+
def evaluate_paws(self):
|
| 934 |
+
true_score = []
|
| 935 |
+
sent1 = []
|
| 936 |
+
sent2 = []
|
| 937 |
+
for example in self.dataset['paws']:
|
| 938 |
+
sent1.append(example['sentence1'])
|
| 939 |
+
sent2.append(example['sentence2'])
|
| 940 |
+
true_score.append(example['label'])
|
| 941 |
+
|
| 942 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['paws']].tolist()
|
| 943 |
+
|
| 944 |
+
self.print_result_table({
|
| 945 |
+
'Dataset_name': 'paws',
|
| 946 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 947 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 948 |
+
'AUC': [roc_auc_score(true_score, pred_score)]
|
| 949 |
+
})
|
| 950 |
+
|
| 951 |
+
def evaluate_mnli_matched(self):
|
| 952 |
+
true_score = []
|
| 953 |
+
sent1 = []
|
| 954 |
+
sent2 = []
|
| 955 |
+
for example in self.dataset['mnli_matched']:
|
| 956 |
+
sent1.append(example['premise'])
|
| 957 |
+
sent2.append(example['hypothesis'])
|
| 958 |
+
true_score.append(example['label'] if example['label']!=-1 else 1)
|
| 959 |
+
|
| 960 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['mnli_matched']], dim=-1).tolist()
|
| 961 |
+
|
| 962 |
+
self.print_result_table({
|
| 963 |
+
'Dataset_name': 'mnli_matched',
|
| 964 |
+
'Accuracy': [accuracy_score(true_score, pred_score)]
|
| 965 |
+
})
|
| 966 |
+
|
| 967 |
+
def evaluate_mnli_mismatched(self):
|
| 968 |
+
true_score = []
|
| 969 |
+
sent1 = []
|
| 970 |
+
sent2 = []
|
| 971 |
+
for example in self.dataset['mnli_mismatched']:
|
| 972 |
+
sent1.append(example['premise'])
|
| 973 |
+
sent2.append(example['hypothesis'])
|
| 974 |
+
true_score.append(example['label'] if example['label']!=-1 else 1)
|
| 975 |
+
|
| 976 |
+
pred_score = torch.argmax(self.align_func(sent1, sent2)[ALL_TASKS['mnli_mismatched']], dim=-1).tolist()
|
| 977 |
+
|
| 978 |
+
self.print_result_table({
|
| 979 |
+
'Dataset_name': 'mnli_mismatched',
|
| 980 |
+
'Accuracy': [accuracy_score(true_score, pred_score)]
|
| 981 |
+
})
|
| 982 |
+
|
| 983 |
+
def evaluate_sem_eval(self):
|
| 984 |
+
print('Reached here')
|
| 985 |
+
true_score = []
|
| 986 |
+
sent1 = []
|
| 987 |
+
sent2 = []
|
| 988 |
+
for example in self.dataset['sem_eval']:
|
| 989 |
+
sent1.append(example['premise'])
|
| 990 |
+
sent2.append(example['hypothesis'])
|
| 991 |
+
if example['entailment_judgment'] == 1:
|
| 992 |
+
true_score.append(1)
|
| 993 |
+
else:
|
| 994 |
+
true_score.append(0)
|
| 995 |
+
|
| 996 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['sem_eval']].tolist()
|
| 997 |
+
|
| 998 |
+
self.print_result_table({
|
| 999 |
+
'Dataset_name': 'sem_eval',
|
| 1000 |
+
'Accuracy': self.get_accuracy(true_score, pred_score)
|
| 1001 |
+
})
|
| 1002 |
+
|
| 1003 |
+
def evaluate_summeval(self):
|
| 1004 |
+
true_score = []
|
| 1005 |
+
true_score_rel = []
|
| 1006 |
+
true_score_binary = []
|
| 1007 |
+
pred_score = []
|
| 1008 |
+
sent1 = []
|
| 1009 |
+
sent2 = []
|
| 1010 |
+
for example in self.dataset['summeval']:
|
| 1011 |
+
cleaned_summary = self.clean_text(example['document'], example['summary'])
|
| 1012 |
+
sent1.append(example['document'])
|
| 1013 |
+
sent2.append(cleaned_summary)
|
| 1014 |
+
true_score.append(example['consistency'])
|
| 1015 |
+
true_score_rel.append(example['relevance'])
|
| 1016 |
+
true_score_binary.append(1 if example['consistency'] == 5.0 else 0)
|
| 1017 |
+
|
| 1018 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['summeval']].tolist()
|
| 1019 |
+
|
| 1020 |
+
self.print_result_table({
|
| 1021 |
+
'Dataset_name': 'summeval',
|
| 1022 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1023 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1024 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 1025 |
+
'AUC': roc_auc_score(true_score_binary, pred_score),
|
| 1026 |
+
'Pearson_rel': self.get_pearson(true_score_rel, pred_score),
|
| 1027 |
+
'Spearman_rel': self.get_spearman(true_score_rel, pred_score),
|
| 1028 |
+
'Kendall_rel': self.get_kendalltau(true_score_rel, pred_score),
|
| 1029 |
+
})
|
| 1030 |
+
|
| 1031 |
+
def evaluate_qags_xsum(self):
|
| 1032 |
+
true_score = []
|
| 1033 |
+
pred_score = []
|
| 1034 |
+
sent1 = []
|
| 1035 |
+
sent2 = []
|
| 1036 |
+
for example in self.dataset['qags_xsum']:
|
| 1037 |
+
sent1.append(example['document'])
|
| 1038 |
+
sent2.append(example['summary'])
|
| 1039 |
+
true_score.append(example['consistency'])
|
| 1040 |
+
|
| 1041 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['qags_xsum']].tolist()
|
| 1042 |
+
|
| 1043 |
+
self.print_result_table({
|
| 1044 |
+
'Dataset_name': 'qags_xsum',
|
| 1045 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1046 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1047 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 1048 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1049 |
+
})
|
| 1050 |
+
|
| 1051 |
+
def evaluate_qags_cnndm(self):
|
| 1052 |
+
true_score = []
|
| 1053 |
+
pred_score = []
|
| 1054 |
+
sent1 = []
|
| 1055 |
+
sent2 = []
|
| 1056 |
+
true_score_binary = []
|
| 1057 |
+
for example in self.dataset['qags_cnndm']:
|
| 1058 |
+
sent1.append(example['document'])
|
| 1059 |
+
sent2.append(example['summary'])
|
| 1060 |
+
true_score.append(example['consistency'])
|
| 1061 |
+
true_score_binary.append(1 if example['consistency'] == 1.0 else 0)
|
| 1062 |
+
|
| 1063 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['qags_cnndm']].tolist()
|
| 1064 |
+
|
| 1065 |
+
self.print_result_table({
|
| 1066 |
+
'Dataset_name': 'qags_cnndm',
|
| 1067 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1068 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1069 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 1070 |
+
'AUC': roc_auc_score(true_score_binary, pred_score)
|
| 1071 |
+
})
|
| 1072 |
+
|
| 1073 |
+
def evaluate_frank(self):
|
| 1074 |
+
from spacy.lang.en import English
|
| 1075 |
+
nlp = English()
|
| 1076 |
+
nlp.add_pipe("sentencizer")
|
| 1077 |
+
for d in self.dataset['frank']:
|
| 1078 |
+
if d['dataset'] == 'cnndm':
|
| 1079 |
+
continue
|
| 1080 |
+
d['document'] = ' '.join([each.text for each in nlp(d['document']).sents])
|
| 1081 |
+
|
| 1082 |
+
true_score_xsum = []
|
| 1083 |
+
true_score_cnndm = []
|
| 1084 |
+
pred_score_xsum = []
|
| 1085 |
+
pred_score_cnndm = []
|
| 1086 |
+
sent1_xsum = []
|
| 1087 |
+
sent1_cnndm = []
|
| 1088 |
+
sent2_xsum = []
|
| 1089 |
+
sent2_cnndm = []
|
| 1090 |
+
true_score_binary_cnndm = []
|
| 1091 |
+
true_score_binary_xsum = []
|
| 1092 |
+
for example in self.dataset['frank']:
|
| 1093 |
+
if example['dataset'] == 'cnndm':
|
| 1094 |
+
sent1_cnndm.append(example['document'])
|
| 1095 |
+
sent2_cnndm.append(self.clean_text(example['document'], example['summary']))
|
| 1096 |
+
true_score_cnndm.append(example['score'])
|
| 1097 |
+
true_score_binary_cnndm.append(1 if example['score'] == 1.0 else 0)
|
| 1098 |
+
elif example['dataset'] == 'xsum':
|
| 1099 |
+
sent1_xsum.append(example['document'])
|
| 1100 |
+
sent2_xsum.append(self.clean_text(example['document'], example['summary']))
|
| 1101 |
+
true_score_xsum.append(example['score'])
|
| 1102 |
+
true_score_binary_xsum.append(1 if example['score'] == 1.0 else 0)
|
| 1103 |
+
|
| 1104 |
+
pred_score_xsum = self.align_func(sent1_xsum, sent2_xsum)[ALL_TASKS['frank']].tolist() #
|
| 1105 |
+
pred_score_cnndm = self.align_func(sent1_cnndm, sent2_cnndm)[ALL_TASKS['frank']].tolist() #
|
| 1106 |
+
|
| 1107 |
+
self.print_result_table({
|
| 1108 |
+
'Dataset_name': 'frank-xsum',
|
| 1109 |
+
'Pearson': self.get_pearson(true_score_xsum, pred_score_xsum),
|
| 1110 |
+
'Spearman': self.get_spearman(true_score_xsum, pred_score_xsum),
|
| 1111 |
+
'Kendall': self.get_kendalltau(true_score_xsum, pred_score_xsum),
|
| 1112 |
+
'AUC': roc_auc_score(true_score_binary_xsum, pred_score_xsum)
|
| 1113 |
+
})
|
| 1114 |
+
|
| 1115 |
+
self.print_result_table({
|
| 1116 |
+
'Dataset_name': 'frank-cnndm',
|
| 1117 |
+
'Pearson': self.get_pearson(true_score_cnndm, pred_score_cnndm),
|
| 1118 |
+
'Spearman': self.get_spearman(true_score_cnndm, pred_score_cnndm),
|
| 1119 |
+
'Kendall': self.get_kendalltau(true_score_cnndm, pred_score_cnndm),
|
| 1120 |
+
'AUC': roc_auc_score(true_score_binary_cnndm, pred_score_cnndm)
|
| 1121 |
+
})
|
| 1122 |
+
|
| 1123 |
+
self.print_result_table({
|
| 1124 |
+
'Dataset_name': 'frank-all',
|
| 1125 |
+
'Pearson': self.get_pearson(true_score_xsum+true_score_cnndm, pred_score_xsum+pred_score_cnndm),
|
| 1126 |
+
'Spearman': self.get_spearman(true_score_xsum+true_score_cnndm, pred_score_xsum+pred_score_cnndm),
|
| 1127 |
+
'Kendall': self.get_kendalltau(true_score_xsum+true_score_cnndm, pred_score_xsum+pred_score_cnndm),
|
| 1128 |
+
'AUC': roc_auc_score(true_score_binary_xsum+true_score_binary_cnndm, pred_score_xsum+pred_score_cnndm)
|
| 1129 |
+
})
|
| 1130 |
+
|
| 1131 |
+
def evaluate_xsumfaith(self):
|
| 1132 |
+
dataset_name = 'xsumfaith'
|
| 1133 |
+
|
| 1134 |
+
true_score = []
|
| 1135 |
+
pred_score = []
|
| 1136 |
+
sent1 = []
|
| 1137 |
+
sent2 = []
|
| 1138 |
+
for example in self.dataset[dataset_name]:
|
| 1139 |
+
sent1.append(example['document'])
|
| 1140 |
+
sent2.append(self.clean_text(example['document'], example['claim']))
|
| 1141 |
+
true_score.append(example['label'])
|
| 1142 |
+
|
| 1143 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS[dataset_name]].tolist()
|
| 1144 |
+
|
| 1145 |
+
self.print_result_table({
|
| 1146 |
+
'Dataset_name': dataset_name,
|
| 1147 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1148 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1149 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 1150 |
+
})
|
| 1151 |
+
|
| 1152 |
+
def evaluate_samsum(self):
|
| 1153 |
+
dataset_name = 'samsum'
|
| 1154 |
+
|
| 1155 |
+
label_mapping = {
|
| 1156 |
+
'factual': 1,
|
| 1157 |
+
'factually incorrect': 0,
|
| 1158 |
+
'too incoherent': 0
|
| 1159 |
+
}
|
| 1160 |
+
import string
|
| 1161 |
+
printable = set(string.printable)
|
| 1162 |
+
|
| 1163 |
+
|
| 1164 |
+
true_score = []
|
| 1165 |
+
pred_score = []
|
| 1166 |
+
sent1 = []
|
| 1167 |
+
sent2 = []
|
| 1168 |
+
for example in self.dataset[dataset_name]:
|
| 1169 |
+
cleaned_doc = ''.join(filter(lambda x: x in printable, example['article']))
|
| 1170 |
+
sent1.append(cleaned_doc)
|
| 1171 |
+
sent2.append(example['summary'])
|
| 1172 |
+
true_score.append(label_mapping[example['label']])
|
| 1173 |
+
|
| 1174 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS[dataset_name]].tolist()
|
| 1175 |
+
|
| 1176 |
+
self.print_result_table({
|
| 1177 |
+
'Dataset_name': dataset_name,
|
| 1178 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1179 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1180 |
+
'Kendall': self.get_kendalltau(true_score, pred_score),
|
| 1181 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1182 |
+
})
|
| 1183 |
+
def evaluate_yelp(self):
|
| 1184 |
+
true_score = []
|
| 1185 |
+
sent1 = []
|
| 1186 |
+
sent2 = []
|
| 1187 |
+
for example in self.dataset['yelp']:
|
| 1188 |
+
sent1.append(example['input_sent'])
|
| 1189 |
+
sent2.append(example['output_sent'])
|
| 1190 |
+
true_score.append(example['preservation'])
|
| 1191 |
+
|
| 1192 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['yelp']].tolist()
|
| 1193 |
+
|
| 1194 |
+
self.print_result_table({
|
| 1195 |
+
'Dataset_name': 'yelp',
|
| 1196 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1197 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1198 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1199 |
+
})
|
| 1200 |
+
|
| 1201 |
+
def evaluate_persona_chat(self):
|
| 1202 |
+
true_score = []
|
| 1203 |
+
pred_score = []
|
| 1204 |
+
premise = []
|
| 1205 |
+
hypothesis = []
|
| 1206 |
+
for example in self.dataset['persona_chat']:
|
| 1207 |
+
premise.append(example['dialog_history']+example['fact'])
|
| 1208 |
+
hypothesis.append(example['response'])
|
| 1209 |
+
true_score.append(example['engaging'])
|
| 1210 |
+
pred_score = self.align_func(premise, hypothesis)[ALL_TASKS['persona_chat']].tolist()
|
| 1211 |
+
|
| 1212 |
+
self.print_result_table({
|
| 1213 |
+
'Dataset_name': 'persona_chat_eng',
|
| 1214 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1215 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1216 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1217 |
+
})
|
| 1218 |
+
|
| 1219 |
+
true_score = []
|
| 1220 |
+
pred_score = []
|
| 1221 |
+
premise = []
|
| 1222 |
+
hypothesis = []
|
| 1223 |
+
for example in self.dataset['persona_chat']:
|
| 1224 |
+
premise.append(example['fact'])
|
| 1225 |
+
hypothesis.append(example['response'])
|
| 1226 |
+
true_score.append(example['uses_knowledge'])
|
| 1227 |
+
pred_score = self.align_func(premise, hypothesis)[ALL_TASKS['persona_chat']].tolist()
|
| 1228 |
+
|
| 1229 |
+
self.print_result_table({
|
| 1230 |
+
'Dataset_name': 'persona_chat_grd',
|
| 1231 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1232 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1233 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1234 |
+
})
|
| 1235 |
+
|
| 1236 |
+
def evaluate_topical_chat(self):
|
| 1237 |
+
true_score = []
|
| 1238 |
+
pred_score = []
|
| 1239 |
+
premise = []
|
| 1240 |
+
hypothesis = []
|
| 1241 |
+
for example in self.dataset['topical_chat']:
|
| 1242 |
+
premise.append(example['dialog_history']+example['fact'])
|
| 1243 |
+
hypothesis.append(example['response'])
|
| 1244 |
+
true_score.append(example['engaging'])
|
| 1245 |
+
pred_score = self.align_func(premise, hypothesis)[ALL_TASKS['topical_chat']].tolist()
|
| 1246 |
+
|
| 1247 |
+
self.print_result_table({
|
| 1248 |
+
'Dataset_name': 'topical_chat_eng',
|
| 1249 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1250 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1251 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1252 |
+
})
|
| 1253 |
+
|
| 1254 |
+
true_score = []
|
| 1255 |
+
pred_score = []
|
| 1256 |
+
premise = []
|
| 1257 |
+
hypothesis = []
|
| 1258 |
+
for example in self.dataset['topical_chat']:
|
| 1259 |
+
premise.append(example['fact'])
|
| 1260 |
+
hypothesis.append(example['response'])
|
| 1261 |
+
true_score.append(example['uses_knowledge'])
|
| 1262 |
+
pred_score = self.align_func(premise, hypothesis)[ALL_TASKS['topical_chat']].tolist()
|
| 1263 |
+
|
| 1264 |
+
self.print_result_table({
|
| 1265 |
+
'Dataset_name': 'topical_chat_grd',
|
| 1266 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1267 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1268 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1269 |
+
})
|
| 1270 |
+
|
| 1271 |
+
def evaluate_paws_qqp(self):
|
| 1272 |
+
sent1 = []
|
| 1273 |
+
sent2 = []
|
| 1274 |
+
true_score = []
|
| 1275 |
+
for i in range(self.dataset['paws_qqp']['label'].size):
|
| 1276 |
+
sent1.append(self.dataset['paws_qqp']['sentence1'][i][2:-1])
|
| 1277 |
+
sent2.append(self.dataset['paws_qqp']['sentence2'][i][2:-1])
|
| 1278 |
+
true_score.append(self.dataset['paws_qqp']['label'][i])
|
| 1279 |
+
|
| 1280 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['paws_qqp']].tolist()
|
| 1281 |
+
roc_auc = roc_auc_score(true_score, pred_score)
|
| 1282 |
+
|
| 1283 |
+
self.print_result_table({
|
| 1284 |
+
'Dataset_name': 'paws_qqp',
|
| 1285 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1286 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1287 |
+
'AUC': [roc_auc]
|
| 1288 |
+
})
|
| 1289 |
+
|
| 1290 |
+
def evaluate_qqp(self):
|
| 1291 |
+
true_score = []
|
| 1292 |
+
sent1 = []
|
| 1293 |
+
sent2 = []
|
| 1294 |
+
for example in self.dataset['qqp']:
|
| 1295 |
+
sent1.append(example['question1'])
|
| 1296 |
+
sent2.append(example['question2'])
|
| 1297 |
+
true_score.append(example['label'])
|
| 1298 |
+
|
| 1299 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['qqp']].tolist()
|
| 1300 |
+
|
| 1301 |
+
self.print_result_table({
|
| 1302 |
+
'Dataset_name': 'qqp',
|
| 1303 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1304 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1305 |
+
'AUC': [roc_auc_score(true_score, pred_score)]
|
| 1306 |
+
})
|
| 1307 |
+
|
| 1308 |
+
def evaluate_wmt17(self):
|
| 1309 |
+
lang_pair = list(set([each['lang'] for each in self.dataset['wmt17']]))
|
| 1310 |
+
|
| 1311 |
+
for each_lang_pair in lang_pair:
|
| 1312 |
+
true_score = []
|
| 1313 |
+
premise = []
|
| 1314 |
+
hypothesis = []
|
| 1315 |
+
for example in self.dataset['wmt17']:
|
| 1316 |
+
if example['lang'] != each_lang_pair:
|
| 1317 |
+
continue
|
| 1318 |
+
premise.append(example['reference'])
|
| 1319 |
+
hypothesis.append(example['candidate'])
|
| 1320 |
+
true_score.append(example['score'])
|
| 1321 |
+
pred_score = self.align_func(premise, hypothesis)[ALL_TASKS['wmt17']].tolist()
|
| 1322 |
+
|
| 1323 |
+
self.print_result_table({
|
| 1324 |
+
'Dataset_name': f'wmt17-{each_lang_pair}',
|
| 1325 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1326 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1327 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1328 |
+
})
|
| 1329 |
+
|
| 1330 |
+
def evaluate_wmt18(self):
|
| 1331 |
+
lang_pair = list(set([each['lang'] for each in self.dataset['wmt18']]))
|
| 1332 |
+
|
| 1333 |
+
for each_lang_pair in lang_pair:
|
| 1334 |
+
true_score = []
|
| 1335 |
+
premise = []
|
| 1336 |
+
hypothesis = []
|
| 1337 |
+
for example in self.dataset['wmt18']:
|
| 1338 |
+
if example['lang'] != each_lang_pair:
|
| 1339 |
+
continue
|
| 1340 |
+
premise.append(example['reference'])
|
| 1341 |
+
hypothesis.append(example['candidate'])
|
| 1342 |
+
true_score.append(example['score'])
|
| 1343 |
+
pred_score = self.align_func(premise, hypothesis)[ALL_TASKS['wmt18']].tolist()
|
| 1344 |
+
|
| 1345 |
+
self.print_result_table({
|
| 1346 |
+
'Dataset_name': f'wmt18-{each_lang_pair}',
|
| 1347 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1348 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1349 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1350 |
+
})
|
| 1351 |
+
def evaluate_wmt19(self):
|
| 1352 |
+
lang_pair = list(set([each['lang'] for each in self.dataset['wmt19']]))
|
| 1353 |
+
|
| 1354 |
+
for each_lang_pair in lang_pair:
|
| 1355 |
+
true_score = []
|
| 1356 |
+
premise = []
|
| 1357 |
+
hypothesis = []
|
| 1358 |
+
for example in self.dataset['wmt19']:
|
| 1359 |
+
if example['lang'] != each_lang_pair:
|
| 1360 |
+
continue
|
| 1361 |
+
premise.append(example['reference'])
|
| 1362 |
+
hypothesis.append(example['candidate'])
|
| 1363 |
+
true_score.append(example['score'])
|
| 1364 |
+
pred_score = self.align_func(premise, hypothesis)[ALL_TASKS['wmt19']].tolist()
|
| 1365 |
+
|
| 1366 |
+
self.print_result_table({
|
| 1367 |
+
'Dataset_name': f'wmt19-{each_lang_pair}',
|
| 1368 |
+
'Pearson': self.get_pearson(true_score, pred_score),
|
| 1369 |
+
'Spearman': self.get_spearman(true_score, pred_score),
|
| 1370 |
+
'Kendall': self.get_kendalltau(true_score, pred_score)
|
| 1371 |
+
})
|
| 1372 |
+
|
| 1373 |
+
def evaluate_sst2(self):
|
| 1374 |
+
true_score = []
|
| 1375 |
+
sent1 = []
|
| 1376 |
+
sent2 = []
|
| 1377 |
+
for example in self.dataset['sst2']:
|
| 1378 |
+
sent1.append(example['text'])
|
| 1379 |
+
sent2.append('It was great.')
|
| 1380 |
+
true_score.append(int(example['label_text'] == 'positive'))
|
| 1381 |
+
|
| 1382 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['sst2']].tolist()
|
| 1383 |
+
|
| 1384 |
+
self.print_result_table({
|
| 1385 |
+
'Dataset_name': 'sst2',
|
| 1386 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1387 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1388 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1389 |
+
})
|
| 1390 |
+
|
| 1391 |
+
def evaluate_cr(self):
|
| 1392 |
+
true_score = []
|
| 1393 |
+
sent1 = []
|
| 1394 |
+
sent2 = []
|
| 1395 |
+
for example in self.dataset['cr']:
|
| 1396 |
+
sent1.append(example['text'])
|
| 1397 |
+
sent2.append('It was great.')
|
| 1398 |
+
true_score.append(int(example['label_text'] == 'positive'))
|
| 1399 |
+
|
| 1400 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['cr']].tolist()
|
| 1401 |
+
|
| 1402 |
+
self.print_result_table({
|
| 1403 |
+
'Dataset_name': 'cr',
|
| 1404 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1405 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1406 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1407 |
+
})
|
| 1408 |
+
|
| 1409 |
+
def evaluate_subj(self):
|
| 1410 |
+
true_score = []
|
| 1411 |
+
sent1 = []
|
| 1412 |
+
sent2 = []
|
| 1413 |
+
for example in self.dataset['subj']:
|
| 1414 |
+
sent1.append(example['text'])
|
| 1415 |
+
sent2.append('It was objective.')
|
| 1416 |
+
true_score.append(int(example['label_text'] == 'objective'))
|
| 1417 |
+
|
| 1418 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['subj']].tolist()
|
| 1419 |
+
|
| 1420 |
+
self.print_result_table({
|
| 1421 |
+
'Dataset_name': 'subj',
|
| 1422 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1423 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1424 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1425 |
+
})
|
| 1426 |
+
|
| 1427 |
+
def evaluate_imdb(self):
|
| 1428 |
+
true_score = []
|
| 1429 |
+
sent1 = []
|
| 1430 |
+
sent2 = []
|
| 1431 |
+
for example in self.dataset['imdb']:
|
| 1432 |
+
sent1.append(example['text'])
|
| 1433 |
+
sent2.append('It was great.')
|
| 1434 |
+
true_score.append(int(example['label_text'] == 'positive'))
|
| 1435 |
+
|
| 1436 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['imdb']].tolist()
|
| 1437 |
+
|
| 1438 |
+
self.print_result_table({
|
| 1439 |
+
'Dataset_name': 'imdb',
|
| 1440 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1441 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1442 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1443 |
+
})
|
| 1444 |
+
|
| 1445 |
+
def evaluate_imdb_knn(self):
|
| 1446 |
+
true_score = []
|
| 1447 |
+
sent1 = []
|
| 1448 |
+
sent2 = []
|
| 1449 |
+
for example in self.dataset['imdb']:
|
| 1450 |
+
sent1.append(example['text'])
|
| 1451 |
+
sent2.append('It was great.')
|
| 1452 |
+
true_score.append(int(example['label_text'] == 'positive'))
|
| 1453 |
+
|
| 1454 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['imdb']].tolist()
|
| 1455 |
+
|
| 1456 |
+
self.print_result_table({
|
| 1457 |
+
'Dataset_name': 'imdb',
|
| 1458 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1459 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1460 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1461 |
+
})
|
| 1462 |
+
|
| 1463 |
+
def evaluate_cola(self):
|
| 1464 |
+
true_score = []
|
| 1465 |
+
sent1 = []
|
| 1466 |
+
sent2 = []
|
| 1467 |
+
for example in self.dataset['cola']:
|
| 1468 |
+
sent1.append(example['sentence'])
|
| 1469 |
+
sent2.append('It was correct.')
|
| 1470 |
+
true_score.append(example['label'])
|
| 1471 |
+
|
| 1472 |
+
pred_score = self.align_func(sent1, sent2)[ALL_TASKS['cola']].tolist()
|
| 1473 |
+
|
| 1474 |
+
self.print_result_table({
|
| 1475 |
+
'Dataset_name': 'cola',
|
| 1476 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1477 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1478 |
+
'AUC': roc_auc_score(true_score, pred_score)
|
| 1479 |
+
})
|
| 1480 |
+
|
| 1481 |
+
def evaluate_yelp_efl(self):
|
| 1482 |
+
sent = []
|
| 1483 |
+
label = []
|
| 1484 |
+
for example in self.dataset['yelp_efl']:
|
| 1485 |
+
sent.append(example['text'])
|
| 1486 |
+
label.append(example['label'])
|
| 1487 |
+
templates = [
|
| 1488 |
+
'It was terrible.',
|
| 1489 |
+
'It was bad.',
|
| 1490 |
+
'It was ok.',
|
| 1491 |
+
'It was good.',
|
| 1492 |
+
'It was great.',
|
| 1493 |
+
]
|
| 1494 |
+
template_lists = [[template] * len(sent) for template in templates]
|
| 1495 |
+
predictions = [
|
| 1496 |
+
self.align_func(sent, template_list)[ALL_TASKS['yelp_efl']]
|
| 1497 |
+
for template_list in template_lists
|
| 1498 |
+
]
|
| 1499 |
+
|
| 1500 |
+
pred_label = torch.argmax(torch.stack(predictions), dim=0).tolist()
|
| 1501 |
+
|
| 1502 |
+
self.print_result_table({
|
| 1503 |
+
'Dataset_name': 'yelp_efl',
|
| 1504 |
+
'Accuracy': [accuracy_score(label, pred_label)]
|
| 1505 |
+
})
|
| 1506 |
+
|
| 1507 |
+
def evaluate_ag_news(self):
|
| 1508 |
+
sent = []
|
| 1509 |
+
label = []
|
| 1510 |
+
for example in self.dataset['ag_news']:
|
| 1511 |
+
sent.append(example['text'])
|
| 1512 |
+
label.append(example['label'])
|
| 1513 |
+
templates = [
|
| 1514 |
+
'It is world news.',
|
| 1515 |
+
'It is sports news.',
|
| 1516 |
+
'It is business news.',
|
| 1517 |
+
'It is science news.',
|
| 1518 |
+
]
|
| 1519 |
+
template_lists = [[template] * len(sent) for template in templates]
|
| 1520 |
+
predictions = [
|
| 1521 |
+
self.align_func(sent, template_list)[ALL_TASKS['ag_news']]
|
| 1522 |
+
for template_list in template_lists
|
| 1523 |
+
]
|
| 1524 |
+
|
| 1525 |
+
pred_label = torch.argmax(torch.stack(predictions), dim=0).tolist()
|
| 1526 |
+
|
| 1527 |
+
self.print_result_table({
|
| 1528 |
+
'Dataset_name': 'ag_news',
|
| 1529 |
+
'Accuracy': [accuracy_score(label, pred_label)]
|
| 1530 |
+
})
|
| 1531 |
+
|
| 1532 |
+
def evaluate_trec(self):
|
| 1533 |
+
sent = []
|
| 1534 |
+
label = []
|
| 1535 |
+
for example in self.dataset['trec']:
|
| 1536 |
+
sent.append(example['text'])
|
| 1537 |
+
label.append(example['label_coarse'])
|
| 1538 |
+
templates = [
|
| 1539 |
+
'It is description.',
|
| 1540 |
+
'It is entity.',
|
| 1541 |
+
'It is expression.',
|
| 1542 |
+
'It is human.',
|
| 1543 |
+
'It is number.',
|
| 1544 |
+
'It is location.',
|
| 1545 |
+
]
|
| 1546 |
+
template_lists = [[template] * len(sent) for template in templates]
|
| 1547 |
+
predictions = [
|
| 1548 |
+
self.align_func(sent, template_list)[ALL_TASKS['trec']]
|
| 1549 |
+
for template_list in template_lists
|
| 1550 |
+
]
|
| 1551 |
+
|
| 1552 |
+
pred_label = torch.argmax(torch.stack(predictions), dim=0).tolist()
|
| 1553 |
+
|
| 1554 |
+
self.print_result_table({
|
| 1555 |
+
'Dataset_name': 'trec',
|
| 1556 |
+
'Accuracy': [accuracy_score(label, pred_label)]
|
| 1557 |
+
})
|
| 1558 |
+
|
| 1559 |
+
def true_task_helper(self, dataset_name):
|
| 1560 |
+
sent1 = []
|
| 1561 |
+
sent2 = []
|
| 1562 |
+
true_score = []
|
| 1563 |
+
for i in range(len(self.dataset[dataset_name])):
|
| 1564 |
+
context = self.dataset[dataset_name].iloc[i]['grounding']
|
| 1565 |
+
claim = self.dataset[dataset_name].iloc[i]['generated_text']
|
| 1566 |
+
sent1.append(context)
|
| 1567 |
+
sent2.append(self.clean_text(context, claim))
|
| 1568 |
+
true_score.append(self.dataset[dataset_name].iloc[i]['label'])
|
| 1569 |
+
|
| 1570 |
+
pred_score = self.align_func(sent1, sent2)[1].tolist()
|
| 1571 |
+
roc_auc = roc_auc_score(true_score, pred_score)
|
| 1572 |
+
|
| 1573 |
+
self.print_result_table({
|
| 1574 |
+
'Dataset_name': dataset_name,
|
| 1575 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1576 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1577 |
+
'AUC': [roc_auc]
|
| 1578 |
+
})
|
| 1579 |
+
|
| 1580 |
+
def evaluate_true_begin(self):
|
| 1581 |
+
dataset_name = 'true_begin'
|
| 1582 |
+
self.true_task_helper(dataset_name)
|
| 1583 |
+
|
| 1584 |
+
|
| 1585 |
+
def evaluate_true_dialfact(self):
|
| 1586 |
+
dataset_name = 'true_dialfact'
|
| 1587 |
+
self.true_task_helper(dataset_name)
|
| 1588 |
+
|
| 1589 |
+
def evaluate_true_fever(self):
|
| 1590 |
+
dataset_name = 'true_fever'
|
| 1591 |
+
self.true_task_helper(dataset_name)
|
| 1592 |
+
|
| 1593 |
+
def evaluate_true_frank(self):
|
| 1594 |
+
dataset_name = 'true_frank'
|
| 1595 |
+
self.true_task_helper(dataset_name)
|
| 1596 |
+
|
| 1597 |
+
def evaluate_true_mnbm(self):
|
| 1598 |
+
dataset_name = 'true_mnbm'
|
| 1599 |
+
self.true_task_helper(dataset_name)
|
| 1600 |
+
|
| 1601 |
+
def evaluate_true_paws(self):
|
| 1602 |
+
dataset_name = 'true_paws'
|
| 1603 |
+
self.true_task_helper(dataset_name)
|
| 1604 |
+
|
| 1605 |
+
def evaluate_true_q2(self):
|
| 1606 |
+
dataset_name = 'true_q2'
|
| 1607 |
+
self.true_task_helper(dataset_name)
|
| 1608 |
+
|
| 1609 |
+
def evaluate_true_qags_cnndm(self):
|
| 1610 |
+
dataset_name = 'true_qags_cnndm'
|
| 1611 |
+
self.true_task_helper(dataset_name)
|
| 1612 |
+
|
| 1613 |
+
def evaluate_true_qags_xsum(self):
|
| 1614 |
+
dataset_name = 'true_qags_xsum'
|
| 1615 |
+
self.true_task_helper(dataset_name)
|
| 1616 |
+
|
| 1617 |
+
def evaluate_true_summeval(self):
|
| 1618 |
+
dataset_name = 'true_summeval'
|
| 1619 |
+
self.true_task_helper(dataset_name)
|
| 1620 |
+
|
| 1621 |
+
def evaluate_true_vitc(self):
|
| 1622 |
+
dataset_name = 'true_vitc'
|
| 1623 |
+
self.true_task_helper(dataset_name)
|
| 1624 |
+
|
| 1625 |
+
def get_summac_thres(self, dataset_name):
|
| 1626 |
+
sent1 = []
|
| 1627 |
+
sent2 = []
|
| 1628 |
+
true_score = []
|
| 1629 |
+
for example in self.summac_validation_set[dataset_name]:
|
| 1630 |
+
sent1.append(example['document'])
|
| 1631 |
+
sent2.append(self.clean_text(example['document'], example['claim'])) #
|
| 1632 |
+
true_score.append(example['label'])
|
| 1633 |
+
|
| 1634 |
+
pred_score = self.align_func(sent1, sent2)[1].tolist()
|
| 1635 |
+
|
| 1636 |
+
thres_result = []
|
| 1637 |
+
for i in range(1001):
|
| 1638 |
+
thres = i / 1000
|
| 1639 |
+
thres_result.append((thres, balanced_accuracy_score(true_score, [p>thres for p in pred_score])))
|
| 1640 |
+
|
| 1641 |
+
best_thres = sorted(thres_result, key=lambda x: x[1], reverse=True)[0]
|
| 1642 |
+
print(f"best thres for {dataset_name} is {best_thres[0]} @ {best_thres[1]}")
|
| 1643 |
+
|
| 1644 |
+
return best_thres[0]
|
| 1645 |
+
|
| 1646 |
+
def summac_task_helper(self, dataset_name):
|
| 1647 |
+
sent1 = []
|
| 1648 |
+
sent2 = []
|
| 1649 |
+
true_score = []
|
| 1650 |
+
for example in self.dataset[dataset_name]:
|
| 1651 |
+
sent1.append(example['document'])
|
| 1652 |
+
sent2.append(self.clean_text(example['document'], example['claim']))
|
| 1653 |
+
true_score.append(example['label'])
|
| 1654 |
+
|
| 1655 |
+
pred_score = self.align_func(sent1, sent2)[1].tolist()
|
| 1656 |
+
roc_auc = roc_auc_score(true_score, pred_score)
|
| 1657 |
+
|
| 1658 |
+
balanced_acc_thres = self.get_summac_thres(dataset_name)
|
| 1659 |
+
|
| 1660 |
+
self.print_result_table({
|
| 1661 |
+
'Dataset_name': dataset_name,
|
| 1662 |
+
'F1': self.get_f1(true_score, pred_score),
|
| 1663 |
+
'Accuracy': self.get_accuracy(true_score, pred_score),
|
| 1664 |
+
'BalancedAcc': self.get_balanced_accuracy(true_score, pred_score, thres=balanced_acc_thres),
|
| 1665 |
+
'threshold': balanced_acc_thres,
|
| 1666 |
+
'AUC': [roc_auc]
|
| 1667 |
+
})
|
| 1668 |
+
|
| 1669 |
+
def evaluate_summac_cogensumm(self):
|
| 1670 |
+
dataset_name = 'summac_cogensumm'
|
| 1671 |
+
self.summac_task_helper(dataset_name)
|
| 1672 |
+
|
| 1673 |
+
def evaluate_summac_xsumfaith(self):
|
| 1674 |
+
dataset_name = 'summac_xsumfaith'
|
| 1675 |
+
self.summac_task_helper(dataset_name)
|
| 1676 |
+
|
| 1677 |
+
def evaluate_summac_polytope(self):
|
| 1678 |
+
dataset_name = 'summac_polytope'
|
| 1679 |
+
self.summac_task_helper(dataset_name)
|
| 1680 |
+
|
| 1681 |
+
def evaluate_summac_factcc(self):
|
| 1682 |
+
dataset_name = 'summac_factcc'
|
| 1683 |
+
self.summac_task_helper(dataset_name)
|
| 1684 |
+
|
| 1685 |
+
def evaluate_summac_summeval(self):
|
| 1686 |
+
dataset_name = 'summac_summeval'
|
| 1687 |
+
self.summac_task_helper(dataset_name)
|
| 1688 |
+
|
| 1689 |
+
def evaluate_summac_frank(self):
|
| 1690 |
+
dataset_name = 'summac_frank'
|
| 1691 |
+
self.summac_task_helper(dataset_name)
|
| 1692 |
+
|
| 1693 |
+
def evaluate_beir(self):
|
| 1694 |
+
from beir import util, LoggingHandler
|
| 1695 |
+
from beir.datasets.data_loader import GenericDataLoader
|
| 1696 |
+
from beir.retrieval.evaluation import EvaluateRetrieval
|
| 1697 |
+
from beir.retrieval.search.lexical import BM25Search as BM25
|
| 1698 |
+
from beir.reranking.models import CrossEncoder
|
| 1699 |
+
from beir.reranking import Rerank
|
| 1700 |
+
|
| 1701 |
+
import pathlib, os
|
| 1702 |
+
import logging
|
| 1703 |
+
import random
|
| 1704 |
+
|
| 1705 |
+
#### Just some code to print debug information to stdout
|
| 1706 |
+
logging.basicConfig(format='%(asctime)s - %(message)s',
|
| 1707 |
+
datefmt='%Y-%m-%d %H:%M:%S',
|
| 1708 |
+
level=logging.INFO,
|
| 1709 |
+
handlers=[LoggingHandler()])
|
| 1710 |
+
#### /print debug information to stdout
|
| 1711 |
+
|
| 1712 |
+
#### Download trec-covid.zip dataset and unzip the dataset
|
| 1713 |
+
for beir_dataset_name in ['msmarco', 'trec-covid', 'nfcorpus', 'nq', 'hotpotqa', 'fiqa',
|
| 1714 |
+
'arguana', 'webis-touche2020', 'cqadupstack', 'quora',
|
| 1715 |
+
'dbpedia-entity', 'scidocs', 'fever', 'climate-fever', 'scifact']:
|
| 1716 |
+
# for beir_dataset_name in ['fever']:
|
| 1717 |
+
url = "https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/{}.zip".format(beir_dataset_name)
|
| 1718 |
+
# out_dir = os.path.join(pathlib.Path(__file__).parent.absolute(), "datasets")
|
| 1719 |
+
out_dir = f"./data/eval/beir/{beir_dataset_name}/"
|
| 1720 |
+
data_path = util.download_and_unzip(url, out_dir)
|
| 1721 |
+
|
| 1722 |
+
#### Provide the data path where trec-covid has been downloaded and unzipped to the data loader
|
| 1723 |
+
# data folder would contain these files:
|
| 1724 |
+
# (1) trec-covid/corpus.jsonl (format: jsonlines)
|
| 1725 |
+
# (2) trec-covid/queries.jsonl (format: jsonlines)
|
| 1726 |
+
# (3) trec-covid/qrels/test.tsv (format: tsv ("\t"))
|
| 1727 |
+
|
| 1728 |
+
corpus, queries, qrels = GenericDataLoader(data_path).load(split="test")
|
| 1729 |
+
|
| 1730 |
+
#########################################
|
| 1731 |
+
#### (1) RETRIEVE Top-100 docs using BM25
|
| 1732 |
+
#########################################
|
| 1733 |
+
|
| 1734 |
+
#### Provide parameters for Elasticsearch
|
| 1735 |
+
# print(corpus)
|
| 1736 |
+
hostname = "localhost" #localhost
|
| 1737 |
+
index_name = beir_dataset_name # trec-covid
|
| 1738 |
+
initialize = True # False
|
| 1739 |
+
|
| 1740 |
+
model = BM25(index_name=index_name, hostname=hostname, initialize=initialize)
|
| 1741 |
+
retriever = EvaluateRetrieval(model, k_values=[1,3,5,10,100,1000])
|
| 1742 |
+
|
| 1743 |
+
#### Retrieve dense results (format of results is identical to qrels)
|
| 1744 |
+
results = retriever.retrieve(corpus, queries)
|
| 1745 |
+
|
| 1746 |
+
# Rerank top-100 results using the reranker provided
|
| 1747 |
+
reranker = Rerank(self.align_func)
|
| 1748 |
+
rerank_results = reranker.rerank(corpus, queries, results, top_k=100)
|
| 1749 |
+
|
| 1750 |
+
#### Evaluate your retrieval using NDCG@k, MAP@K ...
|
| 1751 |
+
ndcg, _map, recall, precision = EvaluateRetrieval.evaluate(qrels, rerank_results, retriever.k_values)
|
| 1752 |
+
|
| 1753 |
+
self.print_result_table({
|
| 1754 |
+
'Dataset_name': beir_dataset_name,
|
| 1755 |
+
'ndcg': ndcg,
|
| 1756 |
+
'map': _map,
|
| 1757 |
+
'recall': recall,
|
| 1758 |
+
'precision': precision
|
| 1759 |
+
})
|
| 1760 |
+
def evaluate_xxx(self):
|
| 1761 |
+
pass
|
| 1762 |
+
|
| 1763 |
+
class evaluateMultiCheckpoints:
|
| 1764 |
+
def __init__(self, config, device='cuda:0') -> None:
|
| 1765 |
+
sample_checkpoint = {
|
| 1766 |
+
'backbone': 'roberta-base',
|
| 1767 |
+
'task_name': 'align-wo-finetune | align-finetune | roberta-finetune-baseline | nli-wo-finetune | nli-finetune',
|
| 1768 |
+
'path': 'some path',
|
| 1769 |
+
'result_save_path': 'some path'
|
| 1770 |
+
}
|
| 1771 |
+
self.config = config ## a dictionary
|
| 1772 |
+
self.device = device
|
| 1773 |
+
|
| 1774 |
+
self.tasks = [
|
| 1775 |
+
'summeval', 'qags_xsum', 'qags_cnndm', 'persona_chat', 'topical_chat',
|
| 1776 |
+
'mnli_mismatched', 'mnli_matched',
|
| 1777 |
+
'sick', 'yelp', 'stsb',
|
| 1778 |
+
'anli_1','anli_2', 'anli_3', 'snli', 'vitaminc',
|
| 1779 |
+
'mrpc', 'paws', 'sem_eval', 'paws_qqp', 'qqp',
|
| 1780 |
+
'newsroom', 'rank19', 'bagel', 'race_m', 'race_h'
|
| 1781 |
+
]
|
| 1782 |
+
|
| 1783 |
+
def experimentForSlide1216(self):
|
| 1784 |
+
for ckpt in self.config:
|
| 1785 |
+
self.evaluateOneCheckpoint(ckpt)
|
| 1786 |
+
def evaluateOneCheckpoint(self, ckpt):
|
| 1787 |
+
model_name = ckpt['path'].split('/')[-1].split('.ckpt')[0]
|
| 1788 |
+
infer = Inferencer(ckpt_path=ckpt['path'],
|
| 1789 |
+
model=ckpt['backbone'], batch_size=32, device=self.device)
|
| 1790 |
+
evaluator = Evaluator(eval_tasks=self.tasks, align_func=infer.inference, save_all_tables=True)
|
| 1791 |
+
|
| 1792 |
+
evaluator.result_save_name = f"{ckpt['result_save_path']}{model_name}"
|
| 1793 |
+
evaluator.evaluate()
|
alignscore/generate_training_data.py
ADDED
|
@@ -0,0 +1,1519 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from logging import error
|
| 2 |
+
from datasets import load_dataset
|
| 3 |
+
import transformers
|
| 4 |
+
from random import sample
|
| 5 |
+
import random
|
| 6 |
+
import torch
|
| 7 |
+
import json
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from nltk.translate.bleu_score import sentence_bleu
|
| 10 |
+
import pandas as pd
|
| 11 |
+
import re
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
'''
|
| 15 |
+
data format
|
| 16 |
+
{text_a, text_b, label:None or 0_1, }
|
| 17 |
+
'''
|
| 18 |
+
DATASET_HUGGINGFACE = {
|
| 19 |
+
'cnndm': ['cnn_dailymail', '3.0.0', 'train'],
|
| 20 |
+
'mnli': ['multi_nli', 'default', 'train'],
|
| 21 |
+
'squad': ['squad', 'plain_text', 'train'],
|
| 22 |
+
'squad_v2': ['squad_v2', 'squad_v2', 'train'],
|
| 23 |
+
'paws': ['paws', 'labeled_final', 'train'],
|
| 24 |
+
'vitaminc': ['tals/vitaminc', 'v1.0', 'train'],
|
| 25 |
+
'xsum': ['xsum', 'default', 'train'],
|
| 26 |
+
'stsb': ['glue', 'stsb', 'train'],
|
| 27 |
+
'sick': ['sick', 'default', 'train'],
|
| 28 |
+
'race': ['race', 'all', 'train'],
|
| 29 |
+
'race_val': ['race', 'all', 'validation'],
|
| 30 |
+
'anli_r1': ['anli', 'plain_text', 'train_r1'],
|
| 31 |
+
'anli_r2': ['anli', 'plain_text', 'train_r2'],
|
| 32 |
+
'anli_r3': ['anli', 'plain_text', 'train_r3'],
|
| 33 |
+
'snli': ['snli', 'plain_text', 'train'],
|
| 34 |
+
'wikihow': ['wikihow', 'all', 'train'],
|
| 35 |
+
'mrpc': ['glue', 'mrpc', 'train'],
|
| 36 |
+
'msmarco': ['ms_marco', 'v2.1', 'train'],
|
| 37 |
+
'mrpc_val': ['glue', 'mrpc', 'validation'],
|
| 38 |
+
'paws_val': ['paws', 'labeled_final', 'validation'],
|
| 39 |
+
'paws_unlabeled': ['paws', 'unlabeled_final', 'train'],
|
| 40 |
+
'qqp': ['glue', 'qqp', 'train'],
|
| 41 |
+
'qqp_val': ['glue', 'qqp', 'validation'],
|
| 42 |
+
'squad_v2_new': ['squad_v2', 'squad_v2', 'train'],
|
| 43 |
+
'adversarial_qa': ['adversarial_qa', 'adversarialQA', 'train'],
|
| 44 |
+
'drop': ['drop', 'train'],
|
| 45 |
+
'duorc_self': ['duorc', 'SelfRC', 'train'],
|
| 46 |
+
'duorc_paraphrase': ['duorc', 'ParaphraseRC', 'train'],
|
| 47 |
+
'quoref': ['quoref', 'train'],
|
| 48 |
+
'hotpot_qa_distractor': ['hotpot_qa', 'distractor', 'train'],
|
| 49 |
+
'hotpot_qa_fullwiki': ['hotpot_qa', 'fullwiki', 'train'],
|
| 50 |
+
'ropes': ['ropes', 'train'],
|
| 51 |
+
'boolq': ['boolq', 'train'],
|
| 52 |
+
'eraser_multi_rc': ['eraser_multi_rc', 'train'],
|
| 53 |
+
'quail': ['quail', 'train'],
|
| 54 |
+
'sciq': ['sciq', 'train'],
|
| 55 |
+
'strategy_qa': ['metaeval/strategy-qa', 'train'],
|
| 56 |
+
'gap': ['gap', 'train'],
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
DATASET_CONFIG = {
|
| 60 |
+
'cnndm': {'task': 'summarization', 'text_a': 'article', 'text_b': 'highlights', 'label': None, 'huggingface': True},
|
| 61 |
+
'mnli': {'task': 'nli', 'text_a': 'premise', 'text_b': 'hypothesis', 'label': 'label', 'huggingface': True},
|
| 62 |
+
'nli_fever': {'task': 'fact_checking', 'text_a': 'context', 'text_b': 'query', 'label': 'label','huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json':True, 'data_path':'data/nli_fever/train_fitems.jsonl' },
|
| 63 |
+
'doc_nli': {'task': 'bin_nli', 'text_a': 'premise', 'text_b': 'hypothesis', 'label': 'label','huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json':True, 'data_path':'data/DocNLI_dataset/train.json' },
|
| 64 |
+
'squad': {'task': 'extractive_qa', 'text_a': 'context', 'text_b': ['question', 'answers'], 'label': None, 'huggingface': True},
|
| 65 |
+
'squad_v2': {'task': 'qa', 'text_a': 'context', 'text_b': ['question', 'answers'], 'label': None, 'huggingface': True},
|
| 66 |
+
'paws': {'task': 'paraphrase', 'text_a': 'sentence1', 'text_b': 'sentence2', 'label': 'label', 'huggingface': True},
|
| 67 |
+
'vitaminc': {'task': 'fact_checking', 'text_a': 'evidence', 'text_b': 'claim', 'label': 'label', 'huggingface': True},
|
| 68 |
+
'xsum': {'task': 'summarization', 'text_a': 'document', 'text_b': 'summary', 'label': None, 'huggingface': True, 'cliff_path': 'data/model_generated_data/cliff_summ/xsum_train.jsonl'},
|
| 69 |
+
'stsb': {'task': 'sts', 'text_a': 'sentence1', 'text_b': 'sentence2', 'label': 'label', 'huggingface': True},
|
| 70 |
+
'sick': {'task': 'sts', 'text_a': 'sentence_A', 'text_b': 'sentence_B', 'label': 'relatedness_score', 'huggingface': True},
|
| 71 |
+
'race': {'task': 'qa', 'text_a': 'article', 'text_b': ['question', 'options'], 'label': 'answer', 'huggingface': True},
|
| 72 |
+
'race_val': {'task': 'qa', 'text_a': 'article', 'text_b': ['question', 'options'], 'label': 'answer', 'huggingface': True},
|
| 73 |
+
'anli_r1': {'task': 'nli', 'text_a': 'premise', 'text_b': 'hypothesis', 'label': 'label', 'huggingface': True},
|
| 74 |
+
'anli_r2': {'task': 'nli', 'text_a': 'premise', 'text_b': 'hypothesis', 'label': 'label', 'huggingface': True},
|
| 75 |
+
'anli_r3': {'task': 'nli', 'text_a': 'premise', 'text_b': 'hypothesis', 'label': 'label', 'huggingface': True},
|
| 76 |
+
'snli': {'task': 'nli', 'text_a': 'premise', 'text_b': 'hypothesis', 'label': 'label', 'huggingface': True},
|
| 77 |
+
'wikihow': {'task': 'summarization', 'text_a': 'text', 'text_b': 'headline', 'label': None, 'huggingface': False, 'using_hf_api': True, 'data_dir': 'data/wikihow_raw'},
|
| 78 |
+
'mrpc': {'task': 'paraphrase', 'text_a': 'sentence1', 'text_b': 'sentence2', 'label': 'label','huggingface': True},
|
| 79 |
+
'mrpc_val': {'task': 'paraphrase', 'text_a': 'sentence1', 'text_b': 'sentence2', 'label': 'label','huggingface': True},
|
| 80 |
+
'paws_val': {'task': 'paraphrase', 'text_a': 'sentence1', 'text_b': 'sentence2', 'label': 'label', 'huggingface': True},
|
| 81 |
+
'paws_unlabeled': {'task': 'paraphrase', 'text_a': 'sentence1', 'text_b': 'sentence2', 'label': 'label', 'huggingface': True},
|
| 82 |
+
'msmarco': {'task': 'ir', 'text_a': 'passages', 'text_b': ['query', 'answers'], 'label': None,'huggingface': True},
|
| 83 |
+
'paws_qqp': {'task': 'paraphrase', 'text_a': 'sentence1', 'text_b': 'sentence2', 'label': None,'huggingface': False, 'using_hf_api': False, 'using_pandas': True, 'data_path':'paws_qqp/output/train.tsv' },
|
| 84 |
+
'wiki103': {'task': 'paraphrase', 'text_a': 'original_sent', 'text_b': 'paraphrase', 'label': None,'huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json': True, 'data_path':'data/model_generated_data/backtranslation/wiki103_single_sent_backtranslation.json'},
|
| 85 |
+
'qqp': {'task': 'paraphrase', 'text_a':'question1', 'text_b':'question2', 'label': 'label', 'huggingface': True},
|
| 86 |
+
'qqp_val': {'task': 'paraphrase', 'text_a':'question1', 'text_b':'question2', 'label': 'label', 'huggingface': True},
|
| 87 |
+
'wmt17xxx': {'task': 'wmt', 'text_a': 'ref', 'text_b': 'mt', 'label': 'score','huggingface': False, 'using_hf_api': False, 'using_pandas': True, 'data_path':'data/wmt/wmt17/2017-da.csv' },
|
| 88 |
+
'wmt15': {'task': 'wmt', 'text_a': 'ref', 'text_b': 'mt', 'label': 'score','huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json':True, 'data_path':'data/eval/wmt15_eval.jsonl' },
|
| 89 |
+
'wmt16': {'task': 'wmt', 'text_a': 'ref', 'text_b': 'mt', 'label': 'score','huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json':True, 'data_path':'data/eval/wmt16_eval.jsonl' },
|
| 90 |
+
'wmt17': {'task': 'wmt', 'text_a': 'ref', 'text_b': 'mt', 'label': 'score','huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json':True, 'data_path':'data/eval/wmt17_eval.jsonl' },
|
| 91 |
+
'wmt18': {'task': 'wmt', 'text_a': 'ref', 'text_b': 'mt', 'label': 'score','huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json':True, 'data_path':'data/eval/wmt18_eval.jsonl' },
|
| 92 |
+
'wmt19': {'task': 'wmt', 'text_a': 'ref', 'text_b': 'mt', 'label': 'score','huggingface': False, 'using_hf_api': False, 'using_pandas': False, 'using_json':True, 'data_path':'data/eval/wmt19_eval.jsonl' },
|
| 93 |
+
'squad_v2_new': {'task': 'qa', 'huggingface': True},
|
| 94 |
+
'adversarial_qa': {'task': 'qa', 'huggingface': True},
|
| 95 |
+
'drop': {'task': 'qa', 'huggingface': True},
|
| 96 |
+
'duorc_self': {'task': 'qa', 'huggingface': True},
|
| 97 |
+
'duorc_paraphrase': {'task': 'qa', 'huggingface': True},
|
| 98 |
+
'quoref': {'task': 'qa', 'huggingface': True},
|
| 99 |
+
'hotpot_qa_distractor': {'task': 'qa', 'huggingface': True},
|
| 100 |
+
'hotpot_qa_fullwiki': {'task': 'qa', 'huggingface': True},
|
| 101 |
+
'newsqa': {'task': 'qa', 'using_json': True, 'raw_json': True, 'data_path': 'data/newsqa_raw/combined-newsqa-data-v1.json'},
|
| 102 |
+
'ropes': {'task': 'qa', 'huggingface': True},
|
| 103 |
+
'boolq': {'task': 'qa', 'huggingface': True},
|
| 104 |
+
'eraser_multi_rc': {'task': 'qa', 'huggingface': True},
|
| 105 |
+
'quail': {'task': 'qa', 'huggingface': True},
|
| 106 |
+
'sciq': {'task': 'qa', 'huggingface': True},
|
| 107 |
+
'strategy_qa': {'task': 'qa', 'huggingface': True},
|
| 108 |
+
'gap': {'task': 'coreference', 'huggingface': True},
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class QA2D():
|
| 113 |
+
def __init__(self, batch_size=32, device='cuda', verbose=True) -> None:
|
| 114 |
+
from transformers import BartTokenizer, BartForConditionalGeneration
|
| 115 |
+
self.tokenizer = BartTokenizer.from_pretrained("MarkS/bart-base-qa2d")
|
| 116 |
+
self.model = BartForConditionalGeneration.from_pretrained("MarkS/bart-base-qa2d").to(device)
|
| 117 |
+
self.batch_size = batch_size
|
| 118 |
+
self.device=device
|
| 119 |
+
self.verbose = verbose
|
| 120 |
+
|
| 121 |
+
def generate(self, questions: list, answers: list):
|
| 122 |
+
assert len(questions) == len(answers)
|
| 123 |
+
qa_list = []
|
| 124 |
+
for q, a in zip(questions, answers):
|
| 125 |
+
qa_list.append(f"question: {q} answer: {a}")
|
| 126 |
+
output = []
|
| 127 |
+
for qa_pairs in tqdm(
|
| 128 |
+
self.chunks(qa_list, self.batch_size),
|
| 129 |
+
desc="QA to Declarative",
|
| 130 |
+
total=int(len(qa_list)/self.batch_size),
|
| 131 |
+
disable=(not self.verbose)
|
| 132 |
+
):
|
| 133 |
+
input_text = qa_pairs
|
| 134 |
+
input_token = self.tokenizer(
|
| 135 |
+
input_text, return_tensors='pt', padding=True, truncation=True).to(self.device)
|
| 136 |
+
dec_sents = self.model.generate(
|
| 137 |
+
input_token.input_ids, max_length=512)
|
| 138 |
+
result = self.tokenizer.batch_decode(
|
| 139 |
+
dec_sents, skip_special_tokens=True)
|
| 140 |
+
output.extend(result)
|
| 141 |
+
|
| 142 |
+
return output
|
| 143 |
+
|
| 144 |
+
def chunks(self, lst, n):
|
| 145 |
+
"""Yield successive n-sized chunks from lst."""
|
| 146 |
+
for i in range(0, len(lst), n):
|
| 147 |
+
yield lst[i:i + n]
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class QAnswering():
|
| 151 |
+
"""
|
| 152 |
+
To answer not-answerable questions
|
| 153 |
+
"""
|
| 154 |
+
|
| 155 |
+
def __init__(self, batch_size=32, device='cuda') -> None:
|
| 156 |
+
from transformers import T5Tokenizer, T5ForConditionalGeneration
|
| 157 |
+
self.tokenizer = T5Tokenizer.from_pretrained(
|
| 158 |
+
"valhalla/t5-base-qa-qg-hl")
|
| 159 |
+
self.model = T5ForConditionalGeneration.from_pretrained(
|
| 160 |
+
"valhalla/t5-base-qa-qg-hl").to(device)
|
| 161 |
+
self.batch_size = batch_size
|
| 162 |
+
self.device = device
|
| 163 |
+
|
| 164 |
+
def generate(self, questions: list, contexts: list):
|
| 165 |
+
assert len(questions) == len(contexts)
|
| 166 |
+
answers = []
|
| 167 |
+
for qs, cs in tqdm(zip(self.chunks(questions, self.batch_size), self.chunks(contexts, self.batch_size)), desc="Generating Answers for not answerable", total=int(len(questions)/self.batch_size)):
|
| 168 |
+
qc_pairs = []
|
| 169 |
+
assert len(qs) == len(cs)
|
| 170 |
+
for one_q, one_c in zip(qs, cs):
|
| 171 |
+
qc_pairs.append(f"""question: {one_q} context: {one_c}""")
|
| 172 |
+
input_ids = self.tokenizer(
|
| 173 |
+
qc_pairs, padding=True, truncation=True, return_tensors='pt').to(self.device).input_ids
|
| 174 |
+
outputs = self.model.generate(input_ids, max_length=512)
|
| 175 |
+
answers.extend(self.tokenizer.batch_decode(
|
| 176 |
+
outputs, skip_special_tokens=True))
|
| 177 |
+
|
| 178 |
+
return answers
|
| 179 |
+
|
| 180 |
+
def chunks(self, lst, n):
|
| 181 |
+
"""Yield successive n-sized chunks from lst."""
|
| 182 |
+
for i in range(0, len(lst), n):
|
| 183 |
+
yield lst[i:i + n]
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
class MLMGeneratorWithPairedData():
|
| 187 |
+
def __init__(self, corpra: list, device='cuda', batch_size=8, mask_percent=0.25) -> None:
|
| 188 |
+
self.device = device
|
| 189 |
+
self.tokenizer = transformers.DistilBertTokenizer.from_pretrained(
|
| 190 |
+
"distilbert-base-uncased")
|
| 191 |
+
self.model = transformers.DistilBertForMaskedLM.from_pretrained(
|
| 192 |
+
"distilbert-base-uncased").to(self.device)
|
| 193 |
+
self.mask_percent = mask_percent
|
| 194 |
+
self.batch_size = batch_size
|
| 195 |
+
|
| 196 |
+
self.dataset = corpra # text needs to be noised
|
| 197 |
+
|
| 198 |
+
def chunks(self, lst, n):
|
| 199 |
+
"""Yield successive n-sized chunks from lst."""
|
| 200 |
+
for i in range(0, len(lst), n):
|
| 201 |
+
yield lst[i:i + n]
|
| 202 |
+
|
| 203 |
+
def generate(self):
|
| 204 |
+
sents_output = []
|
| 205 |
+
for examples in tqdm(self.chunks(self.dataset, self.batch_size), total=int(len(self.dataset)/self.batch_size), desc="MLM Generating"):
|
| 206 |
+
sents_to_be_noised = [each for each in examples]
|
| 207 |
+
sents_noised = self.mlm_infiller(sents_to_be_noised)
|
| 208 |
+
|
| 209 |
+
sents_output.extend(sents_noised)
|
| 210 |
+
|
| 211 |
+
return sents_output
|
| 212 |
+
|
| 213 |
+
def mlm_infiller(self, batch):
|
| 214 |
+
"""
|
| 215 |
+
input a batch of sentences, list
|
| 216 |
+
"""
|
| 217 |
+
masked_batch = []
|
| 218 |
+
masked_batch_ids = []
|
| 219 |
+
for each_sent in batch:
|
| 220 |
+
sent_tokens = self.tokenizer.tokenize(each_sent)
|
| 221 |
+
sent_token_ids = self.tokenizer(each_sent)['input_ids']
|
| 222 |
+
mask_list = sample(list(range(len(sent_tokens))), int(
|
| 223 |
+
self.mask_percent * len(sent_tokens)))
|
| 224 |
+
sent_tokens = [
|
| 225 |
+
each if i not in mask_list else self.tokenizer.mask_token for i, each in enumerate(sent_tokens)]
|
| 226 |
+
masked_batch_ids.append(
|
| 227 |
+
[each if i-1 not in mask_list else self.tokenizer.mask_token_id for i, each in enumerate(sent_token_ids)])
|
| 228 |
+
masked_batch.append(' '.join(sent_tokens))
|
| 229 |
+
|
| 230 |
+
inputs = self.tokenizer(
|
| 231 |
+
masked_batch, padding=True, truncation=True, return_tensors="pt").to(self.device)
|
| 232 |
+
with torch.no_grad():
|
| 233 |
+
logits = self.model(**inputs).logits
|
| 234 |
+
|
| 235 |
+
infill_tokens = []
|
| 236 |
+
for i in range(len(masked_batch)):
|
| 237 |
+
mask_token_index = (inputs.input_ids == self.tokenizer.mask_token_id)[
|
| 238 |
+
i].nonzero(as_tuple=True)[0]
|
| 239 |
+
|
| 240 |
+
predicted_token_id = logits[i, mask_token_index].argmax(axis=-1)
|
| 241 |
+
infill_tokens.append(predicted_token_id)
|
| 242 |
+
|
| 243 |
+
infilled_sent = []
|
| 244 |
+
for masked_sent_ids, infill_token in zip(masked_batch_ids, infill_tokens):
|
| 245 |
+
for infill_one_token in infill_token:
|
| 246 |
+
for i, each_id in enumerate(masked_sent_ids):
|
| 247 |
+
if each_id == self.tokenizer.mask_token_id:
|
| 248 |
+
masked_sent_ids[i] = infill_one_token
|
| 249 |
+
break
|
| 250 |
+
infilled_sent.append(self.tokenizer.decode(
|
| 251 |
+
masked_sent_ids, skip_special_tokens=True))
|
| 252 |
+
|
| 253 |
+
return infilled_sent
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
class ExtractiveSummarizationGenerator():
|
| 257 |
+
def __init__(self) -> None:
|
| 258 |
+
pass
|
| 259 |
+
|
| 260 |
+
def generate(self, texts):
|
| 261 |
+
'''
|
| 262 |
+
texts: list of string
|
| 263 |
+
'''
|
| 264 |
+
from summa.summarizer import summarize
|
| 265 |
+
|
| 266 |
+
summaries = []
|
| 267 |
+
for text in tqdm(texts, desc="Extracting Summary"):
|
| 268 |
+
for prop in range(1, 20):
|
| 269 |
+
summ = summarize(text, ratio=prop/20.)
|
| 270 |
+
if len(summ) > 0:
|
| 271 |
+
break
|
| 272 |
+
summaries.append(summ)
|
| 273 |
+
|
| 274 |
+
return summaries
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
class DataGenerator():
|
| 278 |
+
def __init__(self, dataset_names) -> None:
|
| 279 |
+
self.dataset_names = dataset_names
|
| 280 |
+
self.datasets = dict()
|
| 281 |
+
self.t5_qa = None
|
| 282 |
+
self.t5_tokenizer = None
|
| 283 |
+
|
| 284 |
+
self.load_dataset_from_huggingface()
|
| 285 |
+
|
| 286 |
+
def load_dataset_from_huggingface(self):
|
| 287 |
+
for each_dataset in self.dataset_names:
|
| 288 |
+
if DATASET_CONFIG[each_dataset].get('huggingface'):
|
| 289 |
+
self.datasets[each_dataset] = load_dataset(
|
| 290 |
+
*DATASET_HUGGINGFACE[each_dataset][:-1])[DATASET_HUGGINGFACE[each_dataset][-1]]
|
| 291 |
+
elif DATASET_CONFIG[each_dataset].get('using_hf_api'):
|
| 292 |
+
self.datasets[each_dataset] = load_dataset(
|
| 293 |
+
*DATASET_HUGGINGFACE[each_dataset][:-1], data_dir=DATASET_CONFIG[each_dataset]['data_dir'])[DATASET_HUGGINGFACE[each_dataset][-1]]
|
| 294 |
+
elif DATASET_CONFIG[each_dataset].get('using_pandas'):
|
| 295 |
+
if DATASET_CONFIG[each_dataset]['data_path'].split('.')[-1] == 'tsv':
|
| 296 |
+
self.datasets[each_dataset] = pd.read_csv(
|
| 297 |
+
DATASET_CONFIG[each_dataset]['data_path'], sep='\t')
|
| 298 |
+
elif DATASET_CONFIG[each_dataset]['data_path'].split('.')[-1] == 'csv':
|
| 299 |
+
self.datasets[each_dataset] = pd.read_csv(
|
| 300 |
+
DATASET_CONFIG[each_dataset]['data_path'])
|
| 301 |
+
elif DATASET_CONFIG[each_dataset].get('using_json'):
|
| 302 |
+
self.datasets[each_dataset] = []
|
| 303 |
+
if DATASET_CONFIG[each_dataset].get('raw_json'):
|
| 304 |
+
with open(DATASET_CONFIG[each_dataset]['data_path'], 'r', encoding='utf8') as f:
|
| 305 |
+
self.datasets[each_dataset] = json.load(f)
|
| 306 |
+
else:
|
| 307 |
+
try:
|
| 308 |
+
json_file = json.load(
|
| 309 |
+
open(DATASET_CONFIG[each_dataset]['data_path'], 'r', encoding='utf8'))
|
| 310 |
+
for example in json_file:
|
| 311 |
+
self.datasets[each_dataset].append(example)
|
| 312 |
+
except:
|
| 313 |
+
with open(DATASET_CONFIG[each_dataset]['data_path'], 'r', encoding='utf8') as f:
|
| 314 |
+
for example in f:
|
| 315 |
+
self.datasets[each_dataset].append(
|
| 316 |
+
json.loads(example))
|
| 317 |
+
else:
|
| 318 |
+
error('unable to locate raw dataset...')
|
| 319 |
+
|
| 320 |
+
def process_squad(self):
|
| 321 |
+
from rake_nltk import Rake
|
| 322 |
+
r = Rake()
|
| 323 |
+
topk = 5
|
| 324 |
+
threshold = 0.6
|
| 325 |
+
|
| 326 |
+
output = []
|
| 327 |
+
label = -1
|
| 328 |
+
for example in tqdm(self.datasets['squad'], desc=f'Constructing squad'):
|
| 329 |
+
text_a = example[DATASET_CONFIG['squad']['text_a']]
|
| 330 |
+
question = example[DATASET_CONFIG['squad']['text_b'][0]]
|
| 331 |
+
answer = example[DATASET_CONFIG['squad']
|
| 332 |
+
['text_b'][1]]['text'] # a list
|
| 333 |
+
text_b = [question+' '+answer_ele for answer_ele in answer]
|
| 334 |
+
text_c = []
|
| 335 |
+
|
| 336 |
+
r.extract_keywords_from_text(text_a)
|
| 337 |
+
keywords_in_context = r.get_ranked_phrases()[:topk]
|
| 338 |
+
for each_keyword in keywords_in_context:
|
| 339 |
+
# then it is an incorrect answer
|
| 340 |
+
if sentence_bleu([answer_ele.lower().split() for answer_ele in answer], each_keyword.split(), weights=(0.33, 0.33, 0.33)) < threshold:
|
| 341 |
+
text_c.append(question+' '+each_keyword)
|
| 342 |
+
|
| 343 |
+
output.append({
|
| 344 |
+
'text_a': text_a,
|
| 345 |
+
'text_b': text_b,
|
| 346 |
+
'text_c': text_c,
|
| 347 |
+
'label': label
|
| 348 |
+
})
|
| 349 |
+
|
| 350 |
+
return output
|
| 351 |
+
|
| 352 |
+
def process_squad_v2(self):
|
| 353 |
+
# first collect answerable items
|
| 354 |
+
not_answerable_contexts = []
|
| 355 |
+
not_answerable_questions = []
|
| 356 |
+
not_answerable_answers = []
|
| 357 |
+
|
| 358 |
+
answerable_contexts = []
|
| 359 |
+
answerable_questions = []
|
| 360 |
+
answerable_answers = []
|
| 361 |
+
|
| 362 |
+
qa_generator = QAnswering(batch_size=32, device='cuda')
|
| 363 |
+
qa2d_generator = QA2D(batch_size=32, device='cuda')
|
| 364 |
+
|
| 365 |
+
for example in tqdm(self.datasets['squad_v2'], desc=f'Collecting (not)answerable examples'):
|
| 366 |
+
if len(example['answers']['text']) == 0:
|
| 367 |
+
not_answerable_contexts.append(example['context'])
|
| 368 |
+
not_answerable_questions.append(example['question'])
|
| 369 |
+
else:
|
| 370 |
+
answerable_contexts.append(example['context'])
|
| 371 |
+
answerable_questions.append(example['question'])
|
| 372 |
+
answerable_answers.append(example['answers']['text'][0])
|
| 373 |
+
|
| 374 |
+
not_answerable_answers = qa_generator.generate(
|
| 375 |
+
not_answerable_questions, not_answerable_contexts)
|
| 376 |
+
answerable_declarative_sents = qa2d_generator.generate(
|
| 377 |
+
answerable_questions, answerable_answers)
|
| 378 |
+
not_answerable_declarative_sents = qa2d_generator.generate(
|
| 379 |
+
not_answerable_questions, not_answerable_answers)
|
| 380 |
+
|
| 381 |
+
output = []
|
| 382 |
+
for i, dec_sent in enumerate(answerable_declarative_sents):
|
| 383 |
+
output.append({
|
| 384 |
+
'text_a': answerable_contexts[i],
|
| 385 |
+
'text_b': [dec_sent],
|
| 386 |
+
'text_c': [],
|
| 387 |
+
'label': 1
|
| 388 |
+
})
|
| 389 |
+
|
| 390 |
+
for i, dec_sent in enumerate(not_answerable_declarative_sents):
|
| 391 |
+
output.append({
|
| 392 |
+
'text_a': not_answerable_contexts[i],
|
| 393 |
+
'text_b': [dec_sent],
|
| 394 |
+
'text_c': [],
|
| 395 |
+
'label': 0
|
| 396 |
+
})
|
| 397 |
+
|
| 398 |
+
return output
|
| 399 |
+
|
| 400 |
+
def process_race(self):
|
| 401 |
+
qa2d_generator = QA2D(batch_size=32, device='cuda')
|
| 402 |
+
option_dict = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
|
| 403 |
+
output = []
|
| 404 |
+
|
| 405 |
+
correct_context = []
|
| 406 |
+
correct_question = []
|
| 407 |
+
correct_answer = []
|
| 408 |
+
|
| 409 |
+
wrong_context = []
|
| 410 |
+
wrong_question = []
|
| 411 |
+
wrong_answer = []
|
| 412 |
+
|
| 413 |
+
for example in tqdm(self.datasets['race'], desc=f'Constructing race'):
|
| 414 |
+
text_a = example[DATASET_CONFIG['race']['text_a']]
|
| 415 |
+
label = -1
|
| 416 |
+
question = example[DATASET_CONFIG['race']['text_b'][0]]
|
| 417 |
+
if "_" in question:
|
| 418 |
+
answer_id = option_dict[example[DATASET_CONFIG['race']['label']]]
|
| 419 |
+
for i, options in enumerate(example[DATASET_CONFIG['race']['text_b'][1]]):
|
| 420 |
+
if i == answer_id:
|
| 421 |
+
output.append({
|
| 422 |
+
'text_a': text_a,
|
| 423 |
+
'text_b': [' '.join(question.replace("_", " "+options+" ").split())],
|
| 424 |
+
'text_c': [],
|
| 425 |
+
'label': 1
|
| 426 |
+
})
|
| 427 |
+
else:
|
| 428 |
+
output.append({
|
| 429 |
+
'text_a': text_a,
|
| 430 |
+
'text_b': [' '.join(question.replace("_", " "+options+" ").split())],
|
| 431 |
+
'text_c': [],
|
| 432 |
+
'label': 0
|
| 433 |
+
})
|
| 434 |
+
else:
|
| 435 |
+
answer_id = option_dict[example[DATASET_CONFIG['race']['label']]]
|
| 436 |
+
for i, options in enumerate(example[DATASET_CONFIG['race']['text_b'][1]]):
|
| 437 |
+
if i == answer_id:
|
| 438 |
+
output.append({
|
| 439 |
+
'text_a': text_a,
|
| 440 |
+
'text_b': [question],
|
| 441 |
+
'text_c': [options],
|
| 442 |
+
'label': 1
|
| 443 |
+
})
|
| 444 |
+
else:
|
| 445 |
+
output.append({
|
| 446 |
+
'text_a': text_a,
|
| 447 |
+
'text_b': [question],
|
| 448 |
+
'text_c': [options],
|
| 449 |
+
'label': 0
|
| 450 |
+
})
|
| 451 |
+
|
| 452 |
+
return output
|
| 453 |
+
|
| 454 |
+
def process_race_val(self):
|
| 455 |
+
qa2d_generator = QA2D(batch_size=32, device='cuda')
|
| 456 |
+
option_dict = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
|
| 457 |
+
output = []
|
| 458 |
+
|
| 459 |
+
correct_context = []
|
| 460 |
+
correct_question = []
|
| 461 |
+
correct_answer = []
|
| 462 |
+
|
| 463 |
+
wrong_context = []
|
| 464 |
+
wrong_question = []
|
| 465 |
+
wrong_answer = []
|
| 466 |
+
|
| 467 |
+
for example in tqdm(self.datasets['race_val'], desc=f'Constructing race_val'):
|
| 468 |
+
text_a = example[DATASET_CONFIG['race_val']['text_a']]
|
| 469 |
+
label = -1
|
| 470 |
+
question = example[DATASET_CONFIG['race_val']['text_b'][0]]
|
| 471 |
+
if "_" in question:
|
| 472 |
+
answer_id = option_dict[example[DATASET_CONFIG['race_val']['label']]]
|
| 473 |
+
for i, options in enumerate(example[DATASET_CONFIG['race_val']['text_b'][1]]):
|
| 474 |
+
if i == answer_id:
|
| 475 |
+
output.append({
|
| 476 |
+
'text_a': text_a,
|
| 477 |
+
'text_b': [' '.join(question.replace("_", " "+options+" ").split())],
|
| 478 |
+
'text_c': [],
|
| 479 |
+
'label': 1
|
| 480 |
+
})
|
| 481 |
+
else:
|
| 482 |
+
output.append({
|
| 483 |
+
'text_a': text_a,
|
| 484 |
+
'text_b': [' '.join(question.replace("_", " "+options+" ").split())],
|
| 485 |
+
'text_c': [],
|
| 486 |
+
'label': 0
|
| 487 |
+
})
|
| 488 |
+
else:
|
| 489 |
+
answer_id = option_dict[example[DATASET_CONFIG['race_val']['label']]]
|
| 490 |
+
for i, options in enumerate(example[DATASET_CONFIG['race_val']['text_b'][1]]):
|
| 491 |
+
if i == answer_id:
|
| 492 |
+
correct_context.append(text_a)
|
| 493 |
+
correct_question.append(question)
|
| 494 |
+
correct_answer.append(options)
|
| 495 |
+
else:
|
| 496 |
+
wrong_context.append(text_a)
|
| 497 |
+
wrong_question.append(question)
|
| 498 |
+
wrong_answer.append(options)
|
| 499 |
+
|
| 500 |
+
correct_declarative = qa2d_generator.generate(
|
| 501 |
+
correct_question, correct_answer)
|
| 502 |
+
wrong_declarative = qa2d_generator.generate(
|
| 503 |
+
wrong_question, wrong_answer)
|
| 504 |
+
assert len(correct_context) == len(correct_declarative)
|
| 505 |
+
assert len(wrong_context) == len(wrong_declarative)
|
| 506 |
+
for context, dec in zip(correct_context, correct_declarative):
|
| 507 |
+
output.append({
|
| 508 |
+
'text_a': context,
|
| 509 |
+
'text_b': [dec],
|
| 510 |
+
'text_c': [],
|
| 511 |
+
'label': 1
|
| 512 |
+
})
|
| 513 |
+
|
| 514 |
+
for context, dec in zip(wrong_context, wrong_declarative):
|
| 515 |
+
output.append({
|
| 516 |
+
'text_a': context,
|
| 517 |
+
'text_b': [dec],
|
| 518 |
+
'text_c': [],
|
| 519 |
+
'label': 0
|
| 520 |
+
})
|
| 521 |
+
|
| 522 |
+
return output
|
| 523 |
+
|
| 524 |
+
def process_race_test(self):
|
| 525 |
+
option_dict = {'A': 0, 'B': 1, 'C': 2, 'D': 3}
|
| 526 |
+
output = []
|
| 527 |
+
for example in tqdm(self.datasets['race_test'], desc=f'Constructing race_test'):
|
| 528 |
+
text_a = example[DATASET_CONFIG['race_test']['text_a']]
|
| 529 |
+
text_b = [] # pos
|
| 530 |
+
text_c = [] # neg
|
| 531 |
+
label = -1
|
| 532 |
+
question = example[DATASET_CONFIG['race_test']['text_b'][0]]
|
| 533 |
+
if "_" in question:
|
| 534 |
+
answer_id = option_dict[example[DATASET_CONFIG['race_test']['label']]]
|
| 535 |
+
for i, options in enumerate(example[DATASET_CONFIG['race_test']['text_b'][1]]):
|
| 536 |
+
if i == answer_id:
|
| 537 |
+
text_b.append(' '.join(question.replace(
|
| 538 |
+
"_", " "+options+" ").split()))
|
| 539 |
+
else:
|
| 540 |
+
text_c.append(' '.join(question.replace(
|
| 541 |
+
"_", " "+options+" ").split()))
|
| 542 |
+
else:
|
| 543 |
+
answer_id = option_dict[example[DATASET_CONFIG['race_test']['label']]]
|
| 544 |
+
for i, options in enumerate(example[DATASET_CONFIG['race_test']['text_b'][1]]):
|
| 545 |
+
if i == answer_id:
|
| 546 |
+
text_b.append(question+" "+options+" ")
|
| 547 |
+
else:
|
| 548 |
+
text_c.append(question+" "+options+" ")
|
| 549 |
+
|
| 550 |
+
output.append({
|
| 551 |
+
'text_a': text_a,
|
| 552 |
+
'text_b': text_b,
|
| 553 |
+
'text_c': text_c,
|
| 554 |
+
'label': label
|
| 555 |
+
})
|
| 556 |
+
|
| 557 |
+
return output
|
| 558 |
+
|
| 559 |
+
def process_xsum(self):
|
| 560 |
+
'''
|
| 561 |
+
text_a: raw_text
|
| 562 |
+
text_b: raw_summary + ***extractive summ*** removed
|
| 563 |
+
text_c: cliff xsum + DistillBERT from raw_text_b + ***DistillBERT from extractive summ text_b***
|
| 564 |
+
'''
|
| 565 |
+
output = []
|
| 566 |
+
|
| 567 |
+
gold_summary = [example[DATASET_CONFIG['xsum']['text_b']]
|
| 568 |
+
for example in self.datasets['xsum']]
|
| 569 |
+
ext_summarizer = ExtractiveSummarizationGenerator()
|
| 570 |
+
extracted_summ = ext_summarizer.generate(
|
| 571 |
+
[example[DATASET_CONFIG['xsum']['text_a']] for example in self.datasets['xsum']])
|
| 572 |
+
|
| 573 |
+
mlm_hallucinator = MLMGeneratorWithPairedData(
|
| 574 |
+
corpra=gold_summary, device='cuda:0', batch_size=64, mask_percent=0.25)
|
| 575 |
+
gold_summary_hallucinated = mlm_hallucinator.generate()
|
| 576 |
+
|
| 577 |
+
mlm_hallucinator = MLMGeneratorWithPairedData(
|
| 578 |
+
corpra=extracted_summ, device='cuda:0', batch_size=64, mask_percent=0.25)
|
| 579 |
+
extracted_summ_hallucinated = mlm_hallucinator.generate()
|
| 580 |
+
|
| 581 |
+
assert len(self.datasets['xsum']) == len(gold_summary_hallucinated) and len(
|
| 582 |
+
self.datasets['xsum']) == len(extracted_summ_hallucinated)
|
| 583 |
+
|
| 584 |
+
for i, example in tqdm(enumerate(self.datasets['xsum']), desc="Constructing xsum", total=len(self.datasets['xsum'])):
|
| 585 |
+
text_a = example[DATASET_CONFIG['xsum']['text_a']]
|
| 586 |
+
text_b = [gold_summary[i], extracted_summ[i]]
|
| 587 |
+
text_c = [gold_summary_hallucinated[i],
|
| 588 |
+
extracted_summ_hallucinated[i]]
|
| 589 |
+
label = -1
|
| 590 |
+
|
| 591 |
+
output.append({
|
| 592 |
+
'text_a': text_a,
|
| 593 |
+
'text_b': text_b,
|
| 594 |
+
'text_c': text_c,
|
| 595 |
+
'label': label
|
| 596 |
+
})
|
| 597 |
+
|
| 598 |
+
return output
|
| 599 |
+
|
| 600 |
+
def process_cnndm(self):
|
| 601 |
+
'''
|
| 602 |
+
text_a: raw_text
|
| 603 |
+
text_b: raw_summary + ***extractive summ*** removed
|
| 604 |
+
text_c: DistillBERT from raw_text_b + ***DistillBERT from extractive summ text_b***
|
| 605 |
+
'''
|
| 606 |
+
# interpretation of fairseq-generate output: https://github.com/facebookresearch/fairseq/issues/3000
|
| 607 |
+
output = []
|
| 608 |
+
|
| 609 |
+
gold_summary = [example[DATASET_CONFIG['cnndm']['text_b']]
|
| 610 |
+
for example in self.datasets['cnndm']]
|
| 611 |
+
ext_summarizer = ExtractiveSummarizationGenerator()
|
| 612 |
+
extracted_summ = ext_summarizer.generate(
|
| 613 |
+
[example[DATASET_CONFIG['cnndm']['text_a']] for example in self.datasets['cnndm']])
|
| 614 |
+
|
| 615 |
+
mlm_hallucinator = MLMGeneratorWithPairedData(
|
| 616 |
+
corpra=gold_summary, device='cuda:0', batch_size=64, mask_percent=0.25)
|
| 617 |
+
gold_summary_hallucinated = mlm_hallucinator.generate()
|
| 618 |
+
|
| 619 |
+
mlm_hallucinator = MLMGeneratorWithPairedData(
|
| 620 |
+
corpra=extracted_summ, device='cuda:0', batch_size=64, mask_percent=0.25)
|
| 621 |
+
extracted_summ_hallucinated = mlm_hallucinator.generate()
|
| 622 |
+
|
| 623 |
+
assert len(self.datasets['cnndm']) == len(gold_summary_hallucinated) and len(
|
| 624 |
+
self.datasets['cnndm']) == len(extracted_summ_hallucinated)
|
| 625 |
+
|
| 626 |
+
for i, example in tqdm(enumerate(self.datasets['cnndm']), desc="Constructing cnndm", total=len(self.datasets['cnndm'])):
|
| 627 |
+
text_a = example[DATASET_CONFIG['cnndm']['text_a']]
|
| 628 |
+
text_b = [gold_summary[i], extracted_summ[i]]
|
| 629 |
+
text_c = [gold_summary_hallucinated[i],
|
| 630 |
+
extracted_summ_hallucinated[i]]
|
| 631 |
+
label = -1
|
| 632 |
+
|
| 633 |
+
output.append({
|
| 634 |
+
'text_a': text_a,
|
| 635 |
+
'text_b': text_b,
|
| 636 |
+
'text_c': text_c,
|
| 637 |
+
'label': label
|
| 638 |
+
})
|
| 639 |
+
|
| 640 |
+
return output
|
| 641 |
+
|
| 642 |
+
def process_wikihow(self):
|
| 643 |
+
'''
|
| 644 |
+
text_a: raw_text
|
| 645 |
+
text_b: raw_summary + ***extractive summ*** removed
|
| 646 |
+
text_c: DistillBERT from raw_text_b + ***DistillBERT from extractive summ text_b***
|
| 647 |
+
'''
|
| 648 |
+
# interpretation of fairseq-generate output: https://github.com/facebookresearch/fairseq/issues/3000
|
| 649 |
+
output = []
|
| 650 |
+
|
| 651 |
+
gold_summary = [example[DATASET_CONFIG['wikihow']['text_b']]
|
| 652 |
+
for example in self.datasets['wikihow']]
|
| 653 |
+
ext_summarizer = ExtractiveSummarizationGenerator()
|
| 654 |
+
extracted_summ = ext_summarizer.generate(
|
| 655 |
+
[example[DATASET_CONFIG['wikihow']['text_a']] for example in self.datasets['wikihow']])
|
| 656 |
+
|
| 657 |
+
mlm_hallucinator = MLMGeneratorWithPairedData(
|
| 658 |
+
corpra=gold_summary, device='cuda:0', batch_size=64, mask_percent=0.25)
|
| 659 |
+
gold_summary_hallucinated = mlm_hallucinator.generate()
|
| 660 |
+
|
| 661 |
+
mlm_hallucinator = MLMGeneratorWithPairedData(
|
| 662 |
+
corpra=extracted_summ, device='cuda:0', batch_size=64, mask_percent=0.25)
|
| 663 |
+
extracted_summ_hallucinated = mlm_hallucinator.generate()
|
| 664 |
+
|
| 665 |
+
assert len(self.datasets['wikihow']) == len(gold_summary_hallucinated) and len(
|
| 666 |
+
self.datasets['wikihow']) == len(extracted_summ_hallucinated)
|
| 667 |
+
|
| 668 |
+
for i, example in tqdm(enumerate(self.datasets['wikihow']), desc="Constructing wikihow", total=len(self.datasets['wikihow'])):
|
| 669 |
+
text_a = example[DATASET_CONFIG['wikihow']['text_a']]
|
| 670 |
+
text_b = [gold_summary[i], extracted_summ[i]]
|
| 671 |
+
text_c = [gold_summary_hallucinated[i],
|
| 672 |
+
extracted_summ_hallucinated[i]]
|
| 673 |
+
label = -1
|
| 674 |
+
|
| 675 |
+
output.append({
|
| 676 |
+
'text_a': text_a,
|
| 677 |
+
'text_b': text_b,
|
| 678 |
+
'text_c': text_c,
|
| 679 |
+
'label': label
|
| 680 |
+
})
|
| 681 |
+
|
| 682 |
+
return output
|
| 683 |
+
|
| 684 |
+
def process_wiki103(self):
|
| 685 |
+
output = []
|
| 686 |
+
|
| 687 |
+
paraphrases = [example[DATASET_CONFIG['wiki103']['text_b']]
|
| 688 |
+
for example in self.datasets['wiki103']]
|
| 689 |
+
mlm_hallucinator = MLMGeneratorWithPairedData(
|
| 690 |
+
corpra=paraphrases, device='cuda:3', batch_size=64, mask_percent=0.25)
|
| 691 |
+
paraphrase_hallucinated = mlm_hallucinator.generate()
|
| 692 |
+
|
| 693 |
+
assert len(self.datasets['wiki103']) == len(paraphrase_hallucinated)
|
| 694 |
+
|
| 695 |
+
for i, example in tqdm(enumerate(self.datasets['wiki103']), desc=f'Constructing wiki103'):
|
| 696 |
+
output.append({
|
| 697 |
+
'text_a': example[DATASET_CONFIG['wiki103']['text_a']],
|
| 698 |
+
'text_b': [example[DATASET_CONFIG['wiki103']['text_b']]],
|
| 699 |
+
'text_c': [],
|
| 700 |
+
'label': 1
|
| 701 |
+
})
|
| 702 |
+
output.append({
|
| 703 |
+
'text_a': example[DATASET_CONFIG['wiki103']['text_a']],
|
| 704 |
+
'text_b': [paraphrase_hallucinated[i]],
|
| 705 |
+
'text_c': [],
|
| 706 |
+
'label': 0
|
| 707 |
+
})
|
| 708 |
+
|
| 709 |
+
return output
|
| 710 |
+
|
| 711 |
+
def process_mnli(self):
|
| 712 |
+
output = []
|
| 713 |
+
for example in tqdm(self.datasets['mnli'], desc=f'Constructing mnli'):
|
| 714 |
+
text_a = example[DATASET_CONFIG['mnli']['text_a']]
|
| 715 |
+
text_b = [example[DATASET_CONFIG['mnli']['text_b']]]
|
| 716 |
+
text_c = []
|
| 717 |
+
label = example[DATASET_CONFIG['mnli']['label']]
|
| 718 |
+
|
| 719 |
+
output.append({
|
| 720 |
+
'text_a': text_a,
|
| 721 |
+
'text_b': text_b,
|
| 722 |
+
'text_c': text_c,
|
| 723 |
+
'label': label
|
| 724 |
+
})
|
| 725 |
+
|
| 726 |
+
return output
|
| 727 |
+
|
| 728 |
+
def process_nli_fever(self):
|
| 729 |
+
output = []
|
| 730 |
+
for example in tqdm(self.datasets['nli_fever'], desc=f'Constructing nli_fever'):
|
| 731 |
+
text_a = example[DATASET_CONFIG['nli_fever']['text_a']]
|
| 732 |
+
text_b = [example[DATASET_CONFIG['nli_fever']['text_b']]]
|
| 733 |
+
text_c = []
|
| 734 |
+
raw_label = example[DATASET_CONFIG['nli_fever']['label']]
|
| 735 |
+
if raw_label == 'SUPPORTS': # convert to nli style label
|
| 736 |
+
label = 0
|
| 737 |
+
elif raw_label == 'REFUTES':
|
| 738 |
+
label = 2
|
| 739 |
+
else:
|
| 740 |
+
label = 1
|
| 741 |
+
|
| 742 |
+
output.append({
|
| 743 |
+
'text_a': text_a,
|
| 744 |
+
'text_b': text_b,
|
| 745 |
+
'text_c': text_c,
|
| 746 |
+
'label': label
|
| 747 |
+
})
|
| 748 |
+
|
| 749 |
+
return output
|
| 750 |
+
|
| 751 |
+
def process_doc_nli(self):
|
| 752 |
+
output = []
|
| 753 |
+
for example in tqdm(self.datasets['doc_nli'], desc=f'Constructing doc_nli'):
|
| 754 |
+
text_a = example[DATASET_CONFIG['doc_nli']['text_a']]
|
| 755 |
+
text_b = [example[DATASET_CONFIG['doc_nli']['text_b']]]
|
| 756 |
+
text_c = []
|
| 757 |
+
raw_label = example[DATASET_CONFIG['doc_nli']['label']]
|
| 758 |
+
if raw_label == 'entailment': # convert to paraphrase style label
|
| 759 |
+
label = 1
|
| 760 |
+
else:
|
| 761 |
+
label = 0
|
| 762 |
+
|
| 763 |
+
output.append({
|
| 764 |
+
'text_a': text_a,
|
| 765 |
+
'text_b': text_b,
|
| 766 |
+
'text_c': text_c,
|
| 767 |
+
'label': label
|
| 768 |
+
})
|
| 769 |
+
|
| 770 |
+
return output
|
| 771 |
+
|
| 772 |
+
def process_anli_r1(self):
|
| 773 |
+
output = []
|
| 774 |
+
for example in tqdm(self.datasets['anli_r1'], desc=f'Constructing anli_r1'):
|
| 775 |
+
text_a = example[DATASET_CONFIG['anli_r1']['text_a']]
|
| 776 |
+
text_b = [example[DATASET_CONFIG['anli_r1']['text_b']]]
|
| 777 |
+
text_c = []
|
| 778 |
+
label = example[DATASET_CONFIG['anli_r1']['label']]
|
| 779 |
+
|
| 780 |
+
output.append({
|
| 781 |
+
'text_a': text_a,
|
| 782 |
+
'text_b': text_b,
|
| 783 |
+
'text_c': text_c,
|
| 784 |
+
'label': label
|
| 785 |
+
})
|
| 786 |
+
|
| 787 |
+
return output
|
| 788 |
+
|
| 789 |
+
def process_anli_r2(self):
|
| 790 |
+
output = []
|
| 791 |
+
for example in tqdm(self.datasets['anli_r2'], desc=f'Constructing anli_r2'):
|
| 792 |
+
text_a = example[DATASET_CONFIG['anli_r2']['text_a']]
|
| 793 |
+
text_b = [example[DATASET_CONFIG['anli_r2']['text_b']]]
|
| 794 |
+
text_c = []
|
| 795 |
+
label = example[DATASET_CONFIG['anli_r2']['label']]
|
| 796 |
+
|
| 797 |
+
output.append({
|
| 798 |
+
'text_a': text_a,
|
| 799 |
+
'text_b': text_b,
|
| 800 |
+
'text_c': text_c,
|
| 801 |
+
'label': label
|
| 802 |
+
})
|
| 803 |
+
|
| 804 |
+
return output
|
| 805 |
+
|
| 806 |
+
def process_anli_r3(self):
|
| 807 |
+
output = []
|
| 808 |
+
for example in tqdm(self.datasets['anli_r3'], desc=f'Constructing anli_r3'):
|
| 809 |
+
text_a = example[DATASET_CONFIG['anli_r3']['text_a']]
|
| 810 |
+
text_b = [example[DATASET_CONFIG['anli_r3']['text_b']]]
|
| 811 |
+
text_c = []
|
| 812 |
+
label = example[DATASET_CONFIG['anli_r3']['label']]
|
| 813 |
+
|
| 814 |
+
output.append({
|
| 815 |
+
'text_a': text_a,
|
| 816 |
+
'text_b': text_b,
|
| 817 |
+
'text_c': text_c,
|
| 818 |
+
'label': label
|
| 819 |
+
})
|
| 820 |
+
|
| 821 |
+
return output
|
| 822 |
+
|
| 823 |
+
def process_snli(self):
|
| 824 |
+
output = []
|
| 825 |
+
for example in tqdm(self.datasets['snli'], desc=f'Constructing snli'):
|
| 826 |
+
text_a = example[DATASET_CONFIG['snli']['text_a']]
|
| 827 |
+
text_b = [example[DATASET_CONFIG['snli']['text_b']]]
|
| 828 |
+
text_c = []
|
| 829 |
+
label = example[DATASET_CONFIG['snli']['label']]
|
| 830 |
+
|
| 831 |
+
output.append({
|
| 832 |
+
'text_a': text_a,
|
| 833 |
+
'text_b': text_b,
|
| 834 |
+
'text_c': text_c,
|
| 835 |
+
'label': label
|
| 836 |
+
})
|
| 837 |
+
|
| 838 |
+
return output
|
| 839 |
+
|
| 840 |
+
def process_paws(self):
|
| 841 |
+
output = []
|
| 842 |
+
for example in tqdm(self.datasets['paws'], desc=f'Constructing paws'):
|
| 843 |
+
text_a = example[DATASET_CONFIG['paws']['text_a']]
|
| 844 |
+
text_b = [example[DATASET_CONFIG['paws']['text_b']]]
|
| 845 |
+
text_c = []
|
| 846 |
+
label = example[DATASET_CONFIG['paws']['label']]
|
| 847 |
+
|
| 848 |
+
output.append({
|
| 849 |
+
'text_a': text_a,
|
| 850 |
+
'text_b': text_b,
|
| 851 |
+
'text_c': text_c,
|
| 852 |
+
'label': label
|
| 853 |
+
})
|
| 854 |
+
|
| 855 |
+
return output
|
| 856 |
+
|
| 857 |
+
def process_vitaminc(self):
|
| 858 |
+
output = []
|
| 859 |
+
for example in tqdm(self.datasets['vitaminc'], desc=f'Constructing vitaminc'):
|
| 860 |
+
text_a = example[DATASET_CONFIG['vitaminc']['text_a']]
|
| 861 |
+
text_b = [example[DATASET_CONFIG['vitaminc']['text_b']]]
|
| 862 |
+
text_c = []
|
| 863 |
+
raw_label = example[DATASET_CONFIG['vitaminc']['label']]
|
| 864 |
+
if raw_label == 'SUPPORTS': # convert to nli style label
|
| 865 |
+
label = 0
|
| 866 |
+
elif raw_label == 'REFUTES':
|
| 867 |
+
label = 2
|
| 868 |
+
else:
|
| 869 |
+
label = 1
|
| 870 |
+
|
| 871 |
+
output.append({
|
| 872 |
+
'text_a': text_a,
|
| 873 |
+
'text_b': text_b,
|
| 874 |
+
'text_c': text_c,
|
| 875 |
+
'label': label
|
| 876 |
+
})
|
| 877 |
+
|
| 878 |
+
return output
|
| 879 |
+
|
| 880 |
+
def process_stsb(self):
|
| 881 |
+
output = []
|
| 882 |
+
for example in tqdm(self.datasets['stsb'], desc=f'Constructing stsb'):
|
| 883 |
+
text_a = example[DATASET_CONFIG['stsb']['text_a']]
|
| 884 |
+
text_b = [example[DATASET_CONFIG['stsb']['text_b']]]
|
| 885 |
+
text_c = []
|
| 886 |
+
label = example[DATASET_CONFIG['stsb']['label']] / 5.0
|
| 887 |
+
|
| 888 |
+
output.append({
|
| 889 |
+
'text_a': text_a,
|
| 890 |
+
'text_b': text_b,
|
| 891 |
+
'text_c': text_c,
|
| 892 |
+
'label': label
|
| 893 |
+
})
|
| 894 |
+
|
| 895 |
+
return output
|
| 896 |
+
|
| 897 |
+
def process_sick(self):
|
| 898 |
+
output = []
|
| 899 |
+
for example in tqdm(self.datasets['sick'], desc=f'Constructing sick'):
|
| 900 |
+
text_a = example[DATASET_CONFIG['sick']['text_a']]
|
| 901 |
+
text_b = [example[DATASET_CONFIG['sick']['text_b']]]
|
| 902 |
+
text_c = []
|
| 903 |
+
label = example[DATASET_CONFIG['sick']['label']] / 5.0
|
| 904 |
+
|
| 905 |
+
output.append({
|
| 906 |
+
'text_a': text_a,
|
| 907 |
+
'text_b': text_b,
|
| 908 |
+
'text_c': text_c,
|
| 909 |
+
'label': label
|
| 910 |
+
})
|
| 911 |
+
|
| 912 |
+
return output
|
| 913 |
+
|
| 914 |
+
def process_mrpc(self):
|
| 915 |
+
output = []
|
| 916 |
+
for example in tqdm(self.datasets['mrpc'], desc=f'Constructing mrpc'):
|
| 917 |
+
text_a = example[DATASET_CONFIG['mrpc']['text_a']]
|
| 918 |
+
text_b = [example[DATASET_CONFIG['mrpc']['text_b']]]
|
| 919 |
+
text_c = []
|
| 920 |
+
label = example[DATASET_CONFIG['mrpc']['label']]
|
| 921 |
+
|
| 922 |
+
output.append({
|
| 923 |
+
'text_a': text_a,
|
| 924 |
+
'text_b': text_b,
|
| 925 |
+
'text_c': text_c,
|
| 926 |
+
'label': label
|
| 927 |
+
})
|
| 928 |
+
|
| 929 |
+
return output
|
| 930 |
+
|
| 931 |
+
def process_mrpc_val(self):
|
| 932 |
+
output = []
|
| 933 |
+
for example in tqdm(self.datasets['mrpc_val'], desc=f'Constructing mrpc_val'):
|
| 934 |
+
text_a = example[DATASET_CONFIG['mrpc_val']['text_a']]
|
| 935 |
+
text_b = [example[DATASET_CONFIG['mrpc_val']['text_b']]]
|
| 936 |
+
text_c = []
|
| 937 |
+
label = example[DATASET_CONFIG['mrpc_val']['label']]
|
| 938 |
+
|
| 939 |
+
output.append({
|
| 940 |
+
'text_a': text_a,
|
| 941 |
+
'text_b': text_b,
|
| 942 |
+
'text_c': text_c,
|
| 943 |
+
'label': label
|
| 944 |
+
})
|
| 945 |
+
|
| 946 |
+
return output
|
| 947 |
+
|
| 948 |
+
def process_paws_val(self):
|
| 949 |
+
output = []
|
| 950 |
+
for example in tqdm(self.datasets['paws_val'], desc=f'Constructing paws_val'):
|
| 951 |
+
text_a = example[DATASET_CONFIG['paws_val']['text_a']]
|
| 952 |
+
text_b = [example[DATASET_CONFIG['paws_val']['text_b']]]
|
| 953 |
+
text_c = []
|
| 954 |
+
label = example[DATASET_CONFIG['paws_val']['label']]
|
| 955 |
+
|
| 956 |
+
output.append({
|
| 957 |
+
'text_a': text_a,
|
| 958 |
+
'text_b': text_b,
|
| 959 |
+
'text_c': text_c,
|
| 960 |
+
'label': label
|
| 961 |
+
})
|
| 962 |
+
|
| 963 |
+
return output
|
| 964 |
+
|
| 965 |
+
def process_paws_unlabeled(self):
|
| 966 |
+
output = []
|
| 967 |
+
for example in tqdm(self.datasets['paws_unlabeled'], desc=f'Constructing paws_unlabeled'):
|
| 968 |
+
text_a = example[DATASET_CONFIG['paws_unlabeled']['text_a']]
|
| 969 |
+
text_b = [example[DATASET_CONFIG['paws_unlabeled']['text_b']]]
|
| 970 |
+
text_c = []
|
| 971 |
+
label = example[DATASET_CONFIG['paws_unlabeled']['label']]
|
| 972 |
+
|
| 973 |
+
output.append({
|
| 974 |
+
'text_a': text_a,
|
| 975 |
+
'text_b': text_b,
|
| 976 |
+
'text_c': text_c,
|
| 977 |
+
'label': label
|
| 978 |
+
})
|
| 979 |
+
|
| 980 |
+
return output
|
| 981 |
+
|
| 982 |
+
def process_qqp(self):
|
| 983 |
+
output = []
|
| 984 |
+
for example in tqdm(self.datasets['qqp'], desc=f'Constructing qqp'):
|
| 985 |
+
text_a = example[DATASET_CONFIG['qqp']['text_a']]
|
| 986 |
+
text_b = [example[DATASET_CONFIG['qqp']['text_b']]]
|
| 987 |
+
text_c = []
|
| 988 |
+
label = example[DATASET_CONFIG['qqp']['label']]
|
| 989 |
+
|
| 990 |
+
output.append({
|
| 991 |
+
'text_a': text_a,
|
| 992 |
+
'text_b': text_b,
|
| 993 |
+
'text_c': text_c,
|
| 994 |
+
'label': label
|
| 995 |
+
})
|
| 996 |
+
|
| 997 |
+
return output
|
| 998 |
+
|
| 999 |
+
def process_qqp_val(self):
|
| 1000 |
+
output = []
|
| 1001 |
+
for example in tqdm(self.datasets['qqp_val'], desc=f'Constructing qqp_val'):
|
| 1002 |
+
text_a = example[DATASET_CONFIG['qqp_val']['text_a']]
|
| 1003 |
+
text_b = [example[DATASET_CONFIG['qqp_val']['text_b']]]
|
| 1004 |
+
text_c = []
|
| 1005 |
+
label = example[DATASET_CONFIG['qqp_val']['label']]
|
| 1006 |
+
|
| 1007 |
+
output.append({
|
| 1008 |
+
'text_a': text_a,
|
| 1009 |
+
'text_b': text_b,
|
| 1010 |
+
'text_c': text_c,
|
| 1011 |
+
'label': label
|
| 1012 |
+
})
|
| 1013 |
+
|
| 1014 |
+
return output
|
| 1015 |
+
|
| 1016 |
+
def process_msmarco(self):
|
| 1017 |
+
qa2d_generator = QA2D(batch_size=32, device='cuda')
|
| 1018 |
+
output = []
|
| 1019 |
+
correct_contexts = []
|
| 1020 |
+
correct_questions = []
|
| 1021 |
+
correct_answers = []
|
| 1022 |
+
|
| 1023 |
+
wrong_contexts = []
|
| 1024 |
+
wrong_questions = []
|
| 1025 |
+
wrong_answers = []
|
| 1026 |
+
|
| 1027 |
+
filtered_examples = []
|
| 1028 |
+
questions = []
|
| 1029 |
+
answers = []
|
| 1030 |
+
declaratives = []
|
| 1031 |
+
|
| 1032 |
+
for example in tqdm(self.datasets['msmarco'], desc=f'Collecting msmarco'):
|
| 1033 |
+
if sum(example['passages']['is_selected']) > 0: # has answer
|
| 1034 |
+
questions.append(example['query'])
|
| 1035 |
+
answers.append(example['answers'][0] if len(
|
| 1036 |
+
example['wellFormedAnswers']) == 0 else example['wellFormedAnswers'][0])
|
| 1037 |
+
filtered_examples.append(example)
|
| 1038 |
+
|
| 1039 |
+
for example in filtered_examples:
|
| 1040 |
+
for i, is_selected in enumerate(example['passages']['is_selected']):
|
| 1041 |
+
if is_selected == 1:
|
| 1042 |
+
output.append({
|
| 1043 |
+
'text_a': example['passages']['passage_text'][i],
|
| 1044 |
+
'text_b': [example['query']],
|
| 1045 |
+
'text_c': [],
|
| 1046 |
+
'label': 1
|
| 1047 |
+
}
|
| 1048 |
+
)
|
| 1049 |
+
else:
|
| 1050 |
+
output.append({
|
| 1051 |
+
'text_a': example['passages']['passage_text'][i],
|
| 1052 |
+
'text_b': [example['query']],
|
| 1053 |
+
'text_c': [],
|
| 1054 |
+
'label': 0
|
| 1055 |
+
}
|
| 1056 |
+
)
|
| 1057 |
+
return output
|
| 1058 |
+
|
| 1059 |
+
def process_paws_qqp(self):
|
| 1060 |
+
output = []
|
| 1061 |
+
|
| 1062 |
+
for i in range(len(self.datasets['paws_qqp'])):
|
| 1063 |
+
text_a = self.datasets['paws_qqp'].iloc[i]['sentence1'][2:-1]
|
| 1064 |
+
text_b = [self.datasets['paws_qqp'].iloc[i]['sentence2'][2:-1]]
|
| 1065 |
+
text_c = []
|
| 1066 |
+
label = self.datasets['paws_qqp'].iloc[i]['label']
|
| 1067 |
+
|
| 1068 |
+
output.append({
|
| 1069 |
+
'text_a': text_a,
|
| 1070 |
+
'text_b': text_b,
|
| 1071 |
+
'text_c': text_c,
|
| 1072 |
+
'label': int(label)
|
| 1073 |
+
})
|
| 1074 |
+
|
| 1075 |
+
return output
|
| 1076 |
+
|
| 1077 |
+
def process_wmt15(self):
|
| 1078 |
+
output = []
|
| 1079 |
+
|
| 1080 |
+
for example in self.datasets['wmt15']:
|
| 1081 |
+
text_a = example['reference']
|
| 1082 |
+
text_b = [example['candidate']]
|
| 1083 |
+
text_c = []
|
| 1084 |
+
label = example['score']
|
| 1085 |
+
|
| 1086 |
+
output.append({
|
| 1087 |
+
'text_a': text_a,
|
| 1088 |
+
'text_b': text_b,
|
| 1089 |
+
'text_c': text_c,
|
| 1090 |
+
'label': label
|
| 1091 |
+
})
|
| 1092 |
+
|
| 1093 |
+
return output
|
| 1094 |
+
|
| 1095 |
+
def process_wmt16(self):
|
| 1096 |
+
output = []
|
| 1097 |
+
|
| 1098 |
+
for example in self.datasets['wmt16']:
|
| 1099 |
+
text_a = example['reference']
|
| 1100 |
+
text_b = [example['candidate']]
|
| 1101 |
+
text_c = []
|
| 1102 |
+
label = example['score']
|
| 1103 |
+
|
| 1104 |
+
output.append({
|
| 1105 |
+
'text_a': text_a,
|
| 1106 |
+
'text_b': text_b,
|
| 1107 |
+
'text_c': text_c,
|
| 1108 |
+
'label': label
|
| 1109 |
+
})
|
| 1110 |
+
|
| 1111 |
+
return output
|
| 1112 |
+
|
| 1113 |
+
def process_wmt17(self):
|
| 1114 |
+
|
| 1115 |
+
output = []
|
| 1116 |
+
|
| 1117 |
+
for example in self.datasets['wmt17']:
|
| 1118 |
+
text_a = example['reference']
|
| 1119 |
+
text_b = [example['candidate']]
|
| 1120 |
+
text_c = []
|
| 1121 |
+
label = example['score']
|
| 1122 |
+
|
| 1123 |
+
output.append({
|
| 1124 |
+
'text_a': text_a,
|
| 1125 |
+
'text_b': text_b,
|
| 1126 |
+
'text_c': text_c,
|
| 1127 |
+
'label': label
|
| 1128 |
+
})
|
| 1129 |
+
|
| 1130 |
+
return output
|
| 1131 |
+
|
| 1132 |
+
def process_wmt18(self):
|
| 1133 |
+
output = []
|
| 1134 |
+
|
| 1135 |
+
for example in self.datasets['wmt18']:
|
| 1136 |
+
text_a = example['reference']
|
| 1137 |
+
text_b = [example['candidate']]
|
| 1138 |
+
text_c = []
|
| 1139 |
+
label = example['score']
|
| 1140 |
+
|
| 1141 |
+
output.append({
|
| 1142 |
+
'text_a': text_a,
|
| 1143 |
+
'text_b': text_b,
|
| 1144 |
+
'text_c': text_c,
|
| 1145 |
+
'label': label
|
| 1146 |
+
})
|
| 1147 |
+
|
| 1148 |
+
return output
|
| 1149 |
+
|
| 1150 |
+
def process_wmt19(self):
|
| 1151 |
+
output = []
|
| 1152 |
+
|
| 1153 |
+
for example in self.datasets['wmt19']:
|
| 1154 |
+
text_a = example['reference']
|
| 1155 |
+
text_b = [example['candidate']]
|
| 1156 |
+
text_c = []
|
| 1157 |
+
label = example['score']
|
| 1158 |
+
|
| 1159 |
+
output.append({
|
| 1160 |
+
'text_a': text_a,
|
| 1161 |
+
'text_b': text_b,
|
| 1162 |
+
'text_c': text_c,
|
| 1163 |
+
'label': label
|
| 1164 |
+
})
|
| 1165 |
+
|
| 1166 |
+
return output
|
| 1167 |
+
|
| 1168 |
+
def process_boolq(self):
|
| 1169 |
+
output = []
|
| 1170 |
+
|
| 1171 |
+
for example in self.datasets['boolq']:
|
| 1172 |
+
text_a = example['passage']
|
| 1173 |
+
text_b = [example['question']]
|
| 1174 |
+
text_c = ["Yes." if example['answer'] else "No."]
|
| 1175 |
+
label = 1
|
| 1176 |
+
|
| 1177 |
+
output.append({
|
| 1178 |
+
'text_a': text_a,
|
| 1179 |
+
'text_b': text_b,
|
| 1180 |
+
'text_c': text_c,
|
| 1181 |
+
'label': label
|
| 1182 |
+
})
|
| 1183 |
+
|
| 1184 |
+
text_a = example['passage']
|
| 1185 |
+
text_b = [example['question']]
|
| 1186 |
+
text_c = ["Yes." if not example['answer'] else "No."]
|
| 1187 |
+
label = 0
|
| 1188 |
+
|
| 1189 |
+
output.append({
|
| 1190 |
+
'text_a': text_a,
|
| 1191 |
+
'text_b': text_b,
|
| 1192 |
+
'text_c': text_c,
|
| 1193 |
+
'label': label
|
| 1194 |
+
})
|
| 1195 |
+
|
| 1196 |
+
return output
|
| 1197 |
+
|
| 1198 |
+
def process_eraser_multi_rc(self):
|
| 1199 |
+
output = []
|
| 1200 |
+
|
| 1201 |
+
for example in self.datasets['eraser_multi_rc']:
|
| 1202 |
+
text_a = example['passage']
|
| 1203 |
+
text_b = [example['query_and_answer'].replace("|", "")]
|
| 1204 |
+
text_c = []
|
| 1205 |
+
label = int(example['label'])
|
| 1206 |
+
|
| 1207 |
+
output.append({
|
| 1208 |
+
'text_a': text_a,
|
| 1209 |
+
'text_b': text_b,
|
| 1210 |
+
'text_c': text_c,
|
| 1211 |
+
'label': label
|
| 1212 |
+
})
|
| 1213 |
+
|
| 1214 |
+
return output
|
| 1215 |
+
|
| 1216 |
+
def process_quail(self):
|
| 1217 |
+
output = []
|
| 1218 |
+
|
| 1219 |
+
for example in self.datasets['quail']:
|
| 1220 |
+
for i, ans in enumerate(example['answers']):
|
| 1221 |
+
text_a = example['context']
|
| 1222 |
+
text_b = [example['question']]
|
| 1223 |
+
text_c = [ans]
|
| 1224 |
+
label = 1 if i == example['correct_answer_id'] else 0
|
| 1225 |
+
|
| 1226 |
+
output.append({
|
| 1227 |
+
'text_a': text_a,
|
| 1228 |
+
'text_b': text_b,
|
| 1229 |
+
'text_c': text_c,
|
| 1230 |
+
'label': label
|
| 1231 |
+
})
|
| 1232 |
+
|
| 1233 |
+
return output
|
| 1234 |
+
|
| 1235 |
+
def process_sciq(self):
|
| 1236 |
+
output = []
|
| 1237 |
+
|
| 1238 |
+
for example in self.datasets['sciq']:
|
| 1239 |
+
text_a = example['support']
|
| 1240 |
+
|
| 1241 |
+
output.append({
|
| 1242 |
+
'text_a': text_a,
|
| 1243 |
+
'text_b': [example['question']],
|
| 1244 |
+
'text_c': [example['distractor1']],
|
| 1245 |
+
'label': 0
|
| 1246 |
+
})
|
| 1247 |
+
output.append({
|
| 1248 |
+
'text_a': text_a,
|
| 1249 |
+
'text_b': [example['question']],
|
| 1250 |
+
'text_c': [example['distractor2']],
|
| 1251 |
+
'label': 0
|
| 1252 |
+
})
|
| 1253 |
+
output.append({
|
| 1254 |
+
'text_a': text_a,
|
| 1255 |
+
'text_b': [example['question']],
|
| 1256 |
+
'text_c': [example['distractor3']],
|
| 1257 |
+
'label': 0
|
| 1258 |
+
})
|
| 1259 |
+
output.append({
|
| 1260 |
+
'text_a': text_a,
|
| 1261 |
+
'text_b': [example['question']],
|
| 1262 |
+
'text_c': [example['correct_answer']],
|
| 1263 |
+
'label': 1
|
| 1264 |
+
})
|
| 1265 |
+
|
| 1266 |
+
return output
|
| 1267 |
+
|
| 1268 |
+
def process_strategy_qa(self):
|
| 1269 |
+
output = []
|
| 1270 |
+
|
| 1271 |
+
for example in self.datasets['strategy_qa']:
|
| 1272 |
+
text_a = ' '.join(example['facts'])
|
| 1273 |
+
text_b = [example['question']]
|
| 1274 |
+
text_c = ["Yes." if example['answer'] else "No."]
|
| 1275 |
+
label = 1
|
| 1276 |
+
|
| 1277 |
+
output.append({
|
| 1278 |
+
'text_a': text_a,
|
| 1279 |
+
'text_b': text_b,
|
| 1280 |
+
'text_c': text_c,
|
| 1281 |
+
'label': label
|
| 1282 |
+
})
|
| 1283 |
+
|
| 1284 |
+
text_a = ' '.join(example['facts'])
|
| 1285 |
+
text_b = [example['question']]
|
| 1286 |
+
text_c = ["Yes." if not example['answer'] else "No."]
|
| 1287 |
+
label = 0
|
| 1288 |
+
|
| 1289 |
+
output.append({
|
| 1290 |
+
'text_a': text_a,
|
| 1291 |
+
'text_b': text_b,
|
| 1292 |
+
'text_c': text_c,
|
| 1293 |
+
'label': label
|
| 1294 |
+
})
|
| 1295 |
+
|
| 1296 |
+
return output
|
| 1297 |
+
|
| 1298 |
+
def process_gap(self):
|
| 1299 |
+
output = []
|
| 1300 |
+
|
| 1301 |
+
for example in self.datasets['gap']:
|
| 1302 |
+
text_a = example['Text']
|
| 1303 |
+
text_b = [example['Text'][:example['Pronoun-offset']]+example['A']+example['Text'][(example['Pronoun-offset']+len(example['Pronoun'])):]]
|
| 1304 |
+
text_c = []
|
| 1305 |
+
label = 1 if example['A-coref'] else 0
|
| 1306 |
+
|
| 1307 |
+
output.append({
|
| 1308 |
+
'text_a': text_a,
|
| 1309 |
+
'text_b': text_b,
|
| 1310 |
+
'text_c': text_c,
|
| 1311 |
+
'label': label
|
| 1312 |
+
})
|
| 1313 |
+
|
| 1314 |
+
text_a = example['Text']
|
| 1315 |
+
text_b = [example['Text'][:example['Pronoun-offset']]+example['B']+example['Text'][(example['Pronoun-offset']+len(example['Pronoun'])):]]
|
| 1316 |
+
text_c = []
|
| 1317 |
+
label = 1 if example['B-coref'] else 0
|
| 1318 |
+
|
| 1319 |
+
output.append({
|
| 1320 |
+
'text_a': text_a,
|
| 1321 |
+
'text_b': text_b,
|
| 1322 |
+
'text_c': text_c,
|
| 1323 |
+
'label': label
|
| 1324 |
+
})
|
| 1325 |
+
|
| 1326 |
+
return output
|
| 1327 |
+
|
| 1328 |
+
def init_qa_t5(self):
|
| 1329 |
+
from transformers import T5Tokenizer, T5ForConditionalGeneration
|
| 1330 |
+
if self.t5_qa is None:
|
| 1331 |
+
self.t5_tokenizer = T5Tokenizer.from_pretrained(
|
| 1332 |
+
"t5-base", model_max_length=800)
|
| 1333 |
+
self.t5_qa = T5ForConditionalGeneration.from_pretrained("t5-base")
|
| 1334 |
+
self.t5_qa.to('cuda:1')
|
| 1335 |
+
self.t5_qa.eval()
|
| 1336 |
+
|
| 1337 |
+
@staticmethod
|
| 1338 |
+
def mask_answer(context, answers):
|
| 1339 |
+
answers = sorted(answers, key=len, reverse=True)
|
| 1340 |
+
for answer in answers:
|
| 1341 |
+
pattern = f'(?<![\w\\-\u2013]){re.escape(answer)}(?![\w\\-\u2013])'
|
| 1342 |
+
context = re.sub(pattern, '', context, flags=re.IGNORECASE)
|
| 1343 |
+
return context
|
| 1344 |
+
|
| 1345 |
+
def generate_fake_answer(self, context, question, answers):
|
| 1346 |
+
self.init_qa_t5()
|
| 1347 |
+
|
| 1348 |
+
context_no_answer = self.mask_answer(context, answers)
|
| 1349 |
+
|
| 1350 |
+
input_ids = self.t5_tokenizer(
|
| 1351 |
+
f'question: {question} context: {context_no_answer}',
|
| 1352 |
+
return_tensors="pt",
|
| 1353 |
+
truncation='only_first'
|
| 1354 |
+
).input_ids.to(self.t5_qa.device)
|
| 1355 |
+
|
| 1356 |
+
outputs = self.t5_qa.generate(
|
| 1357 |
+
input_ids,
|
| 1358 |
+
max_new_tokens=40,
|
| 1359 |
+
remove_invalid_values=True
|
| 1360 |
+
)
|
| 1361 |
+
|
| 1362 |
+
return self.t5_tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 1363 |
+
|
| 1364 |
+
def negative_sample_qa(self, samples, negative_sample_no_ans_only=True):
|
| 1365 |
+
outputs = []
|
| 1366 |
+
for context, question, answers in samples:
|
| 1367 |
+
if answers:
|
| 1368 |
+
outputs.append({
|
| 1369 |
+
'text_a': context,
|
| 1370 |
+
'text_b': [question],
|
| 1371 |
+
'text_c': answers,
|
| 1372 |
+
'label': 1
|
| 1373 |
+
})
|
| 1374 |
+
if not answers or not negative_sample_no_ans_only:
|
| 1375 |
+
fake_answer = self.generate_fake_answer(
|
| 1376 |
+
context, question, answers)
|
| 1377 |
+
outputs.append({
|
| 1378 |
+
'text_a': context,
|
| 1379 |
+
'text_b': [question],
|
| 1380 |
+
'text_c': [fake_answer],
|
| 1381 |
+
'label': 0
|
| 1382 |
+
})
|
| 1383 |
+
|
| 1384 |
+
return outputs
|
| 1385 |
+
|
| 1386 |
+
def process_squad_v2_new(self):
|
| 1387 |
+
samples = (
|
| 1388 |
+
(sample['context'], sample['question'], sample['answers']['text'])
|
| 1389 |
+
for sample in tqdm(self.datasets['squad_v2_new'], desc=f'squad_v2_new')
|
| 1390 |
+
)
|
| 1391 |
+
return self.negative_sample_qa(samples)
|
| 1392 |
+
|
| 1393 |
+
def process_adversarial_qa(self):
|
| 1394 |
+
samples = (
|
| 1395 |
+
(sample['context'], sample['question'], sample['answers']['text'])
|
| 1396 |
+
for sample in tqdm(self.datasets['adversarial_qa'], desc=f'adversarial_qa')
|
| 1397 |
+
)
|
| 1398 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1399 |
+
|
| 1400 |
+
def process_drop(self):
|
| 1401 |
+
samples = (
|
| 1402 |
+
(sample['passage'], sample['question'],
|
| 1403 |
+
sample['answers_spans']['spans'])
|
| 1404 |
+
for sample in tqdm(self.datasets['drop'], desc=f'drop')
|
| 1405 |
+
)
|
| 1406 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1407 |
+
|
| 1408 |
+
def process_duorc_self(self):
|
| 1409 |
+
samples = (
|
| 1410 |
+
(sample['plot'], sample['question'],
|
| 1411 |
+
sample['answers'])
|
| 1412 |
+
for sample in tqdm(self.datasets['duorc_self'], desc=f'duorc_self')
|
| 1413 |
+
)
|
| 1414 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1415 |
+
|
| 1416 |
+
def process_duorc_paraphrase(self):
|
| 1417 |
+
samples = (
|
| 1418 |
+
(sample['plot'], sample['question'],
|
| 1419 |
+
sample['answers'])
|
| 1420 |
+
for sample in tqdm(self.datasets['duorc_paraphrase'], desc=f'duorc_paraphrase')
|
| 1421 |
+
)
|
| 1422 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1423 |
+
|
| 1424 |
+
def process_quoref(self):
|
| 1425 |
+
samples = (
|
| 1426 |
+
(sample['context'], sample['question'], sample['answers']['text'])
|
| 1427 |
+
for sample in tqdm(self.datasets['quoref'], desc=f'quoref')
|
| 1428 |
+
)
|
| 1429 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1430 |
+
|
| 1431 |
+
@staticmethod
|
| 1432 |
+
def prepare_hotpot_qa_samples(dateset):
|
| 1433 |
+
for sample in dateset:
|
| 1434 |
+
question = sample['question']
|
| 1435 |
+
answer = sample['answer']
|
| 1436 |
+
supporting_docs = set(sample['supporting_facts']['title'])
|
| 1437 |
+
irrelevant_docs = []
|
| 1438 |
+
context_paragraphs = []
|
| 1439 |
+
for title, setences in zip(sample['context']['title'], sample['context']['sentences']):
|
| 1440 |
+
doc = ''.join(setences)
|
| 1441 |
+
if title in supporting_docs:
|
| 1442 |
+
context_paragraphs.append(doc)
|
| 1443 |
+
else:
|
| 1444 |
+
irrelevant_docs.append(doc)
|
| 1445 |
+
# Add some irrelevant documents
|
| 1446 |
+
if irrelevant_docs and len(context_paragraphs) < 4:
|
| 1447 |
+
context_paragraphs.append(random.choice(irrelevant_docs))
|
| 1448 |
+
random.shuffle(context_paragraphs)
|
| 1449 |
+
yield '\n'.join(context_paragraphs), question, [answer]
|
| 1450 |
+
|
| 1451 |
+
def process_hotpot_qa_distractor(self):
|
| 1452 |
+
samples = self.prepare_hotpot_qa_samples(
|
| 1453 |
+
tqdm(self.datasets['hotpot_qa_distractor'],
|
| 1454 |
+
desc=f'hotpot_qa_distractor')
|
| 1455 |
+
)
|
| 1456 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1457 |
+
|
| 1458 |
+
def process_hotpot_qa_fullwiki(self):
|
| 1459 |
+
samples = self.prepare_hotpot_qa_samples(
|
| 1460 |
+
tqdm(self.datasets['hotpot_qa_fullwiki'],
|
| 1461 |
+
desc=f'hotpot_qa_fullwiki')
|
| 1462 |
+
)
|
| 1463 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1464 |
+
|
| 1465 |
+
def process_newsqa(self):
|
| 1466 |
+
def get_samples(dataset):
|
| 1467 |
+
for story in tqdm(dataset['data'], desc='newsqa'):
|
| 1468 |
+
if story['type'] != 'train':
|
| 1469 |
+
continue
|
| 1470 |
+
context = story['text']
|
| 1471 |
+
for question in story['questions']:
|
| 1472 |
+
if question.get('isQuestionBad', 0.) > 0.2:
|
| 1473 |
+
continue
|
| 1474 |
+
answers = []
|
| 1475 |
+
if 's' in question['consensus']:
|
| 1476 |
+
start = question['consensus']['s']
|
| 1477 |
+
end = question['consensus']['e']
|
| 1478 |
+
answers.append(context[start:end].strip())
|
| 1479 |
+
yield context, question['q'], answers
|
| 1480 |
+
samples = get_samples(self.datasets['newsqa'])
|
| 1481 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1482 |
+
|
| 1483 |
+
def process_ropes(self):
|
| 1484 |
+
samples = (
|
| 1485 |
+
(
|
| 1486 |
+
sample['situation'] + ' ' + sample['background'],
|
| 1487 |
+
sample['question'], sample['answers']['text']
|
| 1488 |
+
)
|
| 1489 |
+
for sample in tqdm(self.datasets['ropes'], desc=f'ropes')
|
| 1490 |
+
)
|
| 1491 |
+
return self.negative_sample_qa(samples, negative_sample_no_ans_only=False)
|
| 1492 |
+
|
| 1493 |
+
def generate(self):
|
| 1494 |
+
for each_dataset in self.datasets:
|
| 1495 |
+
with open(f'./data/training/{each_dataset}.json', 'w', encoding='utf8') as outfile:
|
| 1496 |
+
outfile.write("")
|
| 1497 |
+
for each_dataset in self.datasets:
|
| 1498 |
+
outputs = eval(f'self.process_{each_dataset}()')
|
| 1499 |
+
|
| 1500 |
+
for each_output in outputs:
|
| 1501 |
+
dict_write_to_file = {
|
| 1502 |
+
'task': DATASET_CONFIG[each_dataset]['task'],
|
| 1503 |
+
'text_a': each_output['text_a'], # string
|
| 1504 |
+
# list of positive examples
|
| 1505 |
+
'text_b': each_output['text_b'],
|
| 1506 |
+
# list of negative examples
|
| 1507 |
+
'text_c': each_output['text_c'],
|
| 1508 |
+
# original label, if -1 only has positive pairs and negative pairs
|
| 1509 |
+
'orig_label': each_output['label']
|
| 1510 |
+
}
|
| 1511 |
+
with open(f'./data/training/{each_dataset}.json', 'a', encoding='utf8') as outfile:
|
| 1512 |
+
json.dump(dict_write_to_file, outfile, ensure_ascii=False)
|
| 1513 |
+
outfile.write('\n')
|
| 1514 |
+
|
| 1515 |
+
|
| 1516 |
+
if __name__ == "__main__":
|
| 1517 |
+
random.seed(42)
|
| 1518 |
+
gen = DataGenerator(list(DATASET_CONFIG.keys()))
|
| 1519 |
+
gen.generate()
|
alignscore/pyproject.toml
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["hatchling"]
|
| 3 |
+
build-backend = "hatchling.build"
|
| 4 |
+
|
| 5 |
+
[project]
|
| 6 |
+
name = "alignscore"
|
| 7 |
+
version = "0.1.3"
|
| 8 |
+
authors = [
|
| 9 |
+
{ name = "Yuheng Zha", email = "yzha@ucsd.edu" },
|
| 10 |
+
{ name = "Yichi Yang", email = "yiy067@ucsd.edu" },
|
| 11 |
+
{ name = "Ruichen Li", email = "rul014@ucsd.edu" },
|
| 12 |
+
{ name = "Zhiting Hu", email = "zhh019@ucsd.edu" },
|
| 13 |
+
]
|
| 14 |
+
description = "An automatic factual consistency evaluation metric based on a unifined alignment function"
|
| 15 |
+
readme = "README.md"
|
| 16 |
+
requires-python = ">=3.8"
|
| 17 |
+
classifiers = [
|
| 18 |
+
"Programming Language :: Python :: 3",
|
| 19 |
+
"License :: OSI Approved :: MIT License",
|
| 20 |
+
"Operating System :: OS Independent",
|
| 21 |
+
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
| 22 |
+
]
|
| 23 |
+
dependencies = [
|
| 24 |
+
"spacy>=3.4.0,<4",
|
| 25 |
+
"nltk>=3.7,<4",
|
| 26 |
+
"torch>=1.12.1,<2",
|
| 27 |
+
"transformers>=4.20.1,<5",
|
| 28 |
+
"tqdm>=4.64.0,<5",
|
| 29 |
+
"jsonlines>=2.0.0,<3",
|
| 30 |
+
"numpy>=1.23.1,<2",
|
| 31 |
+
"datasets>=2.3.2,<3",
|
| 32 |
+
"scikit-learn>=1.1.2,<2",
|
| 33 |
+
"pytorch_lightning>=1.7.7,<2",
|
| 34 |
+
"scipy>=1.8.1,<2",
|
| 35 |
+
"tensorboard>=2.12.0,<3",
|
| 36 |
+
"protobuf<=3.20"
|
| 37 |
+
]
|
| 38 |
+
|
| 39 |
+
[project.urls]
|
| 40 |
+
"Homepage" = "https://github.com/yuh-zha/AlignScore"
|
| 41 |
+
"Bug Tracker" = "https://github.com/yuh-zha/AlignScore/issues"
|
alignscore/requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
alignscore>=0.1
|
| 2 |
+
ctc_score==0.1.3
|
| 3 |
+
BLEURT @ git+https://github.com/google-research/bleurt@cebe7e6f996b40910cfaa520a63db47807e3bf5c
|
| 4 |
+
bert_score==0.3.11
|
| 5 |
+
rake_nltk==1.0.6
|
| 6 |
+
summa==1.2.0
|
| 7 |
+
benepar==0.2.0
|
| 8 |
+
summac==0.0.3
|
| 9 |
+
tabulate>=0.9.0,<1
|
alignscore/src/alignscore/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .alignscore import AlignScore
|
alignscore/src/alignscore/alignscore.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .inference import Inferencer
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
class AlignScore:
|
| 5 |
+
def __init__(self, model: str, batch_size: int, device: int, ckpt_path: str, evaluation_mode='nli_sp', verbose=True) -> None:
|
| 6 |
+
self.model = Inferencer(
|
| 7 |
+
ckpt_path=ckpt_path,
|
| 8 |
+
model=model,
|
| 9 |
+
batch_size=batch_size,
|
| 10 |
+
device=device,
|
| 11 |
+
verbose=verbose
|
| 12 |
+
)
|
| 13 |
+
self.model.nlg_eval_mode = evaluation_mode
|
| 14 |
+
|
| 15 |
+
def score(self, contexts: List[str], claims: List[str]) -> List[float]:
|
| 16 |
+
return self.model.nlg_eval(contexts, claims)[1].tolist()
|
alignscore/src/alignscore/dataloader.py
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import random
|
| 4 |
+
from typing import Optional, Sized
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from pytorch_lightning import LightningDataModule
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from transformers import (
|
| 12 |
+
AutoConfig,
|
| 13 |
+
AutoTokenizer,
|
| 14 |
+
)
|
| 15 |
+
from torch.utils.data import Dataset, Sampler
|
| 16 |
+
import os
|
| 17 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 18 |
+
|
| 19 |
+
class DSTDataSet(Dataset):
|
| 20 |
+
def __init__(self, dataset, model_name='bert-base-uncased', need_mlm=True, tokenizer_max_length=512) -> None:
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 23 |
+
self.tokenizer_max_length = tokenizer_max_length
|
| 24 |
+
self.config = AutoConfig.from_pretrained(model_name)
|
| 25 |
+
self.dataset_type_dict = dict()
|
| 26 |
+
|
| 27 |
+
self.dataset = dataset
|
| 28 |
+
|
| 29 |
+
self.need_mlm = need_mlm
|
| 30 |
+
|
| 31 |
+
self.dataset_type_dict_init()
|
| 32 |
+
|
| 33 |
+
def dataset_type_dict_init(self):
|
| 34 |
+
for i, example in enumerate(self.dataset):
|
| 35 |
+
try:
|
| 36 |
+
self.dataset_type_dict[example['task']].append(i)
|
| 37 |
+
except:
|
| 38 |
+
self.dataset_type_dict[example['task']] = [i]
|
| 39 |
+
def random_word(self, tokens):
|
| 40 |
+
"""
|
| 41 |
+
Masking some random tokens for Language Model task with probabilities as in the original BERT paper.
|
| 42 |
+
:param tokens: list of str, tokenized sentence.
|
| 43 |
+
:param tokenizer: Tokenizer, object used for tokenization (we need it's vocab here)
|
| 44 |
+
:return: (list of str, list of int), masked tokens and related labels for LM prediction
|
| 45 |
+
"""
|
| 46 |
+
if not self.need_mlm: # disable masked language modeling
|
| 47 |
+
return tokens, [-100] * len(tokens)
|
| 48 |
+
|
| 49 |
+
output_label = []
|
| 50 |
+
|
| 51 |
+
for i, token in enumerate(tokens):
|
| 52 |
+
if token == self.tokenizer.pad_token_id:
|
| 53 |
+
output_label.append(-100) # PAD tokens ignore
|
| 54 |
+
continue
|
| 55 |
+
prob = random.random()
|
| 56 |
+
# mask token with 15% probability
|
| 57 |
+
if prob < 0.15:
|
| 58 |
+
prob /= 0.15
|
| 59 |
+
|
| 60 |
+
# 80% randomly change token to mask token
|
| 61 |
+
if prob < 0.8:
|
| 62 |
+
tokens[i] = self.tokenizer.mask_token_id
|
| 63 |
+
|
| 64 |
+
# 10% randomly change token to random token
|
| 65 |
+
elif prob < 0.9:
|
| 66 |
+
tokens[i] = random.choice(list(range(self.tokenizer.vocab_size)))
|
| 67 |
+
|
| 68 |
+
# -> rest 10% randomly keep current token
|
| 69 |
+
|
| 70 |
+
# append current token to output (we will predict these later)
|
| 71 |
+
output_label.append(token)
|
| 72 |
+
else:
|
| 73 |
+
# no masking token (will be ignored by loss function later)
|
| 74 |
+
output_label.append(-100)
|
| 75 |
+
|
| 76 |
+
return tokens, output_label
|
| 77 |
+
|
| 78 |
+
def process_nli(self, index):
|
| 79 |
+
text_a = self.dataset[index]['text_a']
|
| 80 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 81 |
+
tri_label = self.dataset[index]['orig_label'] if self.dataset[index]['orig_label'] != -1 else 1
|
| 82 |
+
|
| 83 |
+
rand_self_align = random.random()
|
| 84 |
+
if rand_self_align > 0.95: ### random self alignment
|
| 85 |
+
text_b = self.dataset[index]['text_a']
|
| 86 |
+
tri_label = 0
|
| 87 |
+
elif self.dataset[index]['orig_label'] == 2 and random.random() > 0.95:
|
| 88 |
+
text_a = self.dataset[index]['text_b'][0]
|
| 89 |
+
text_b = self.dataset[index]['text_a']
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
try:
|
| 93 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 94 |
+
except:
|
| 95 |
+
logging.warning('text_b too long...')
|
| 96 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 97 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 98 |
+
return (
|
| 99 |
+
torch.tensor(input_ids),
|
| 100 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 101 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 102 |
+
torch.tensor(-100), # align label, 2 class
|
| 103 |
+
torch.tensor(mlm_labels), # mlm label
|
| 104 |
+
torch.tensor(tri_label), # tri label, 3 class
|
| 105 |
+
torch.tensor(-100.0) # reg label, float
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
def process_paraphrase(self, index):
|
| 109 |
+
text_a = self.dataset[index]['text_a']
|
| 110 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 111 |
+
label = self.dataset[index]['orig_label']
|
| 112 |
+
|
| 113 |
+
rand_self_align = random.random()
|
| 114 |
+
if rand_self_align > 0.95: ### random self alignment
|
| 115 |
+
text_b = self.dataset[index]['text_a']
|
| 116 |
+
label = 1
|
| 117 |
+
elif random.random() > 0.95:
|
| 118 |
+
text_a = self.dataset[index]['text_b'][0]
|
| 119 |
+
text_b = self.dataset[index]['text_a']
|
| 120 |
+
|
| 121 |
+
try:
|
| 122 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 123 |
+
except:
|
| 124 |
+
logging.warning('text_b too long...')
|
| 125 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 126 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 127 |
+
return (
|
| 128 |
+
torch.tensor(input_ids),
|
| 129 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 130 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 131 |
+
torch.tensor(label), # align label, 2 class
|
| 132 |
+
torch.tensor(mlm_labels), # mlm label
|
| 133 |
+
torch.tensor(-100), # tri label, 3 class
|
| 134 |
+
torch.tensor(-100.0) # reg label, float
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
def process_qa(self, index):
|
| 138 |
+
text_a = self.dataset[index]['text_a']
|
| 139 |
+
if len(self.dataset[index]['text_c']) > 0:
|
| 140 |
+
text_b = self.dataset[index]['text_b'][0] + ' ' + self.dataset[index]['text_c'][0]
|
| 141 |
+
else:
|
| 142 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 143 |
+
label = self.dataset[index]['orig_label']
|
| 144 |
+
|
| 145 |
+
try:
|
| 146 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 147 |
+
except:
|
| 148 |
+
logging.warning('text_b too long...')
|
| 149 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 150 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 151 |
+
return (
|
| 152 |
+
torch.tensor(input_ids),
|
| 153 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 154 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 155 |
+
torch.tensor(label), # align label, 2 class
|
| 156 |
+
torch.tensor(mlm_labels), # mlm label
|
| 157 |
+
torch.tensor(-100), # tri label, 3 class
|
| 158 |
+
torch.tensor(-100.0) # reg label, float
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
def process_coreference(self, index):
|
| 162 |
+
text_a = self.dataset[index]['text_a']
|
| 163 |
+
if len(self.dataset[index]['text_c']) > 0:
|
| 164 |
+
text_b = self.dataset[index]['text_b'][0] + ' ' + self.dataset[index]['text_c'][0]
|
| 165 |
+
else:
|
| 166 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 167 |
+
label = self.dataset[index]['orig_label']
|
| 168 |
+
|
| 169 |
+
try:
|
| 170 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 171 |
+
except:
|
| 172 |
+
logging.warning('text_b too long...')
|
| 173 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 174 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 175 |
+
return (
|
| 176 |
+
torch.tensor(input_ids),
|
| 177 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 178 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 179 |
+
torch.tensor(label), # align label, 2 class
|
| 180 |
+
torch.tensor(mlm_labels), # mlm label
|
| 181 |
+
torch.tensor(-100), # tri label, 3 class
|
| 182 |
+
torch.tensor(-100.0) # reg label, float
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
def process_bin_nli(self, index):
|
| 186 |
+
text_a = self.dataset[index]['text_a']
|
| 187 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 188 |
+
label = self.dataset[index]['orig_label']
|
| 189 |
+
|
| 190 |
+
try:
|
| 191 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 192 |
+
except:
|
| 193 |
+
logging.warning('text_b too long...')
|
| 194 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 195 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 196 |
+
return (
|
| 197 |
+
torch.tensor(input_ids),
|
| 198 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 199 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 200 |
+
torch.tensor(label), # align label, 2 class
|
| 201 |
+
torch.tensor(mlm_labels), # mlm label
|
| 202 |
+
torch.tensor(-100), # tri label, 3 class
|
| 203 |
+
torch.tensor(-100.0) # reg label, float
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
def process_fact_checking(self, index):
|
| 207 |
+
text_a = self.dataset[index]['text_a']
|
| 208 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 209 |
+
tri_label = self.dataset[index]['orig_label'] if self.dataset[index]['orig_label'] != -1 else 1
|
| 210 |
+
|
| 211 |
+
rand_self_align = random.random()
|
| 212 |
+
if rand_self_align > 0.95: ### random self alignment
|
| 213 |
+
text_b = self.dataset[index]['text_a']
|
| 214 |
+
tri_label = 0
|
| 215 |
+
elif self.dataset[index]['orig_label'] == 2 and random.random() > 0.95:
|
| 216 |
+
text_a = self.dataset[index]['text_b'][0]
|
| 217 |
+
text_b = self.dataset[index]['text_a']
|
| 218 |
+
|
| 219 |
+
try:
|
| 220 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 221 |
+
except:
|
| 222 |
+
logging.warning('text_b too long...')
|
| 223 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 224 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 225 |
+
return (
|
| 226 |
+
torch.tensor(input_ids),
|
| 227 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 228 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 229 |
+
torch.tensor(-100), # align label, 2 class
|
| 230 |
+
torch.tensor(mlm_labels), # mlm label
|
| 231 |
+
torch.tensor(tri_label), # tri label, 3 class
|
| 232 |
+
torch.tensor(-100.0) # reg label, float
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
def process_summarization(self, index):
|
| 236 |
+
text_a = self.dataset[index]['text_a']
|
| 237 |
+
if random.random() > 0.5: # this will be a positive pair
|
| 238 |
+
random_pos_sample_id = random.randint(0, len(self.dataset[index]['text_b'])-1)
|
| 239 |
+
text_b = self.dataset[index]['text_b'][random_pos_sample_id]
|
| 240 |
+
label = 1
|
| 241 |
+
else: # this will be a negative pair
|
| 242 |
+
label = 0
|
| 243 |
+
if len(self.dataset[index]['text_c']) > 0:
|
| 244 |
+
random_neg_sample_id = random.randint(0, len(self.dataset[index]['text_c'])-1)
|
| 245 |
+
text_b = self.dataset[index]['text_c'][random_neg_sample_id]
|
| 246 |
+
else:
|
| 247 |
+
random_choose_from_entire_dataset_text_b = random.choice(self.dataset_type_dict['summarization'])
|
| 248 |
+
text_b = self.dataset[random_choose_from_entire_dataset_text_b]['text_b'][0]
|
| 249 |
+
|
| 250 |
+
try:
|
| 251 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 252 |
+
except:
|
| 253 |
+
logging.warning('text_b too long...')
|
| 254 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 255 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 256 |
+
|
| 257 |
+
return (
|
| 258 |
+
torch.tensor(input_ids),
|
| 259 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 260 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 261 |
+
torch.tensor(label), # align label, 2 class
|
| 262 |
+
torch.tensor(mlm_labels), # mlm label
|
| 263 |
+
torch.tensor(-100), # tri label, 3 class
|
| 264 |
+
torch.tensor(-100.0) # reg label, float
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
def process_multiple_choice_qa(self, index):
|
| 268 |
+
text_a = self.dataset[index]['text_a']
|
| 269 |
+
if random.random() > 0.5: # this will be a positive pair
|
| 270 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 271 |
+
label = 1
|
| 272 |
+
else: # this will be a negative pair
|
| 273 |
+
label = 0
|
| 274 |
+
if len(self.dataset[index]['text_c']) > 0:
|
| 275 |
+
random_neg_sample_id = random.randint(0, len(self.dataset[index]['text_c'])-1)
|
| 276 |
+
text_b = self.dataset[index]['text_c'][random_neg_sample_id]
|
| 277 |
+
else:
|
| 278 |
+
random_choose_from_entire_dataset_text_b = random.choice(self.dataset_type_dict['multiple_choice_qa'])
|
| 279 |
+
text_b = self.dataset[random_choose_from_entire_dataset_text_b]['text_b'][0]
|
| 280 |
+
|
| 281 |
+
try:
|
| 282 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 283 |
+
except:
|
| 284 |
+
logging.warning('text_b too long...')
|
| 285 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 286 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 287 |
+
|
| 288 |
+
return (
|
| 289 |
+
torch.tensor(input_ids),
|
| 290 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 291 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 292 |
+
torch.tensor(label), # align label, 2 class
|
| 293 |
+
torch.tensor(mlm_labels), # mlm label
|
| 294 |
+
torch.tensor(-100), # tri label, 3 class
|
| 295 |
+
torch.tensor(-100.0) # reg label, float
|
| 296 |
+
)
|
| 297 |
+
|
| 298 |
+
def process_extractive_qa(self, index):
|
| 299 |
+
text_a = self.dataset[index]['text_a']
|
| 300 |
+
if random.random() > 0.5: # this will be a positive pair
|
| 301 |
+
random_pos_sample_id = random.randint(0, len(self.dataset[index]['text_b'])-1)
|
| 302 |
+
text_b = self.dataset[index]['text_b'][random_pos_sample_id]
|
| 303 |
+
label = 1
|
| 304 |
+
else: # this will be a negative pair
|
| 305 |
+
label = 0
|
| 306 |
+
if len(self.dataset[index]['text_c']) > 0:
|
| 307 |
+
random_neg_sample_id = random.randint(0, len(self.dataset[index]['text_c'])-1)
|
| 308 |
+
text_b = self.dataset[index]['text_c'][random_neg_sample_id]
|
| 309 |
+
else:
|
| 310 |
+
random_choose_from_entire_dataset_text_b = random.choice(self.dataset_type_dict['extractive_qa'])
|
| 311 |
+
text_b = self.dataset[random_choose_from_entire_dataset_text_b]['text_b'][0]
|
| 312 |
+
|
| 313 |
+
try:
|
| 314 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 315 |
+
except:
|
| 316 |
+
logging.warning('text_b too long...')
|
| 317 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 318 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 319 |
+
|
| 320 |
+
return (
|
| 321 |
+
torch.tensor(input_ids),
|
| 322 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 323 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 324 |
+
torch.tensor(label), # align label, 2 class
|
| 325 |
+
torch.tensor(mlm_labels), # mlm label
|
| 326 |
+
torch.tensor(-100), # tri label, 3 class
|
| 327 |
+
torch.tensor(-100.0) # reg label, float
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
def process_ir(self, index):
|
| 331 |
+
text_a = self.dataset[index]['text_a']
|
| 332 |
+
text_b = self.dataset[index]['text_b'][random.randint(0, len(self.dataset[index]['text_b'])-1)]
|
| 333 |
+
label = self.dataset[index]['orig_label']
|
| 334 |
+
|
| 335 |
+
try:
|
| 336 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 337 |
+
except:
|
| 338 |
+
logging.warning('text_b too long...')
|
| 339 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 340 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 341 |
+
|
| 342 |
+
return (
|
| 343 |
+
torch.tensor(input_ids),
|
| 344 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 345 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 346 |
+
torch.tensor(label), # align label, 2 class
|
| 347 |
+
torch.tensor(mlm_labels), # mlm label
|
| 348 |
+
torch.tensor(-100), # tri label, 3 class
|
| 349 |
+
torch.tensor(-100.0) # reg label, float
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
def process_wmt(self, index):
|
| 353 |
+
text_a = self.dataset[index]['text_a']
|
| 354 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 355 |
+
reg_label = self.dataset[index]['orig_label']
|
| 356 |
+
|
| 357 |
+
try:
|
| 358 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 359 |
+
except:
|
| 360 |
+
logging.warning('text_b too long...')
|
| 361 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 362 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 363 |
+
|
| 364 |
+
return (
|
| 365 |
+
torch.tensor(input_ids),
|
| 366 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 367 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 368 |
+
torch.tensor(-100), # align label, 2 class
|
| 369 |
+
torch.tensor(mlm_labels), # mlm label
|
| 370 |
+
torch.tensor(-100), # tri label, 3 class
|
| 371 |
+
torch.tensor(reg_label) # reg label, float
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
def process_sts(self, index):
|
| 375 |
+
text_a = self.dataset[index]['text_a']
|
| 376 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 377 |
+
reg_label = self.dataset[index]['orig_label']
|
| 378 |
+
|
| 379 |
+
try:
|
| 380 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 381 |
+
except:
|
| 382 |
+
logging.warning('text_b too long...')
|
| 383 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 384 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 385 |
+
|
| 386 |
+
return (
|
| 387 |
+
torch.tensor(input_ids),
|
| 388 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 389 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 390 |
+
torch.tensor(-100), # align label, 2 class
|
| 391 |
+
torch.tensor(mlm_labels), # mlm label
|
| 392 |
+
torch.tensor(-100), # tri label, 3 class
|
| 393 |
+
torch.tensor(reg_label) # reg label, float
|
| 394 |
+
)
|
| 395 |
+
|
| 396 |
+
def process_ctc(self, index):
|
| 397 |
+
text_a = self.dataset[index]['text_a']
|
| 398 |
+
text_b = self.dataset[index]['text_b'][0]
|
| 399 |
+
reg_label = self.dataset[index]['orig_label']
|
| 400 |
+
|
| 401 |
+
try:
|
| 402 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation='only_first')
|
| 403 |
+
except:
|
| 404 |
+
logging.warning('text_b too long...')
|
| 405 |
+
tokenized_pair = self.tokenizer(text_a, text_b, padding='max_length', max_length=self.tokenizer_max_length, truncation=True)
|
| 406 |
+
input_ids, mlm_labels = self.random_word(tokenized_pair['input_ids'])
|
| 407 |
+
|
| 408 |
+
return (
|
| 409 |
+
torch.tensor(input_ids),
|
| 410 |
+
torch.tensor(tokenized_pair['attention_mask']),
|
| 411 |
+
torch.tensor(tokenized_pair['token_type_ids']) if 'token_type_ids' in tokenized_pair.keys() else None,
|
| 412 |
+
torch.tensor(-100), # align label, 2 class
|
| 413 |
+
torch.tensor(mlm_labels), # mlm label
|
| 414 |
+
torch.tensor(-100), # tri label, 3 class
|
| 415 |
+
torch.tensor(reg_label) # reg label, float
|
| 416 |
+
)
|
| 417 |
+
|
| 418 |
+
def __getitem__(self, index):
|
| 419 |
+
if self.dataset[index]['task'] == 'nli':
|
| 420 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_nli(index)
|
| 421 |
+
|
| 422 |
+
if self.dataset[index]['task'] == 'bin_nli':
|
| 423 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_bin_nli(index)
|
| 424 |
+
|
| 425 |
+
if self.dataset[index]['task'] == 'paraphrase':
|
| 426 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_paraphrase(index)
|
| 427 |
+
|
| 428 |
+
if self.dataset[index]['task'] == 'fact_checking':
|
| 429 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_fact_checking(index)
|
| 430 |
+
|
| 431 |
+
if self.dataset[index]['task'] == 'summarization':
|
| 432 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_summarization(index)
|
| 433 |
+
|
| 434 |
+
if self.dataset[index]['task'] == 'multiple_choice_qa':
|
| 435 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_multiple_choice_qa(index)
|
| 436 |
+
|
| 437 |
+
if self.dataset[index]['task'] == 'extractive_qa':
|
| 438 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_extractive_qa(index)
|
| 439 |
+
|
| 440 |
+
if self.dataset[index]['task'] == 'qa':
|
| 441 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_qa(index)
|
| 442 |
+
|
| 443 |
+
if self.dataset[index]['task'] == 'coreference':
|
| 444 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_coreference(index)
|
| 445 |
+
|
| 446 |
+
if self.dataset[index]['task'] == 'ir':
|
| 447 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_ir(index)
|
| 448 |
+
|
| 449 |
+
if self.dataset[index]['task'] == 'sts':
|
| 450 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_sts(index)
|
| 451 |
+
|
| 452 |
+
if self.dataset[index]['task'] == 'ctc':
|
| 453 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_ctc(index)
|
| 454 |
+
|
| 455 |
+
if self.dataset[index]['task'] == 'wmt':
|
| 456 |
+
input_ids, attention_mask, token_type_ids, align_label, mlm_labels, tri_label, reg_label = self.process_wmt(index)
|
| 457 |
+
|
| 458 |
+
if token_type_ids is not None:
|
| 459 |
+
return {
|
| 460 |
+
'input_ids': input_ids,
|
| 461 |
+
'attention_mask': attention_mask,
|
| 462 |
+
'token_type_ids': token_type_ids,
|
| 463 |
+
'align_label': align_label,
|
| 464 |
+
'mlm_label': mlm_labels,
|
| 465 |
+
'tri_label': tri_label,
|
| 466 |
+
'reg_label': reg_label
|
| 467 |
+
}
|
| 468 |
+
else:
|
| 469 |
+
return {
|
| 470 |
+
'input_ids': input_ids,
|
| 471 |
+
'attention_mask': attention_mask,
|
| 472 |
+
'align_label': align_label,
|
| 473 |
+
'mlm_label': mlm_labels,
|
| 474 |
+
'tri_label': tri_label,
|
| 475 |
+
'reg_label': reg_label
|
| 476 |
+
}
|
| 477 |
+
|
| 478 |
+
|
| 479 |
+
def __len__(self):
|
| 480 |
+
return len(self.dataset)
|
| 481 |
+
|
| 482 |
+
class PropSampler(Sampler[int]):
|
| 483 |
+
def __init__(self, data_source: Optional[Sized]) -> None:
|
| 484 |
+
super().__init__(data_source)
|
| 485 |
+
self.K = 500000
|
| 486 |
+
print("Initializing Prop Sampler")
|
| 487 |
+
|
| 488 |
+
self.data_positions = dict()
|
| 489 |
+
for i, example in tqdm(enumerate(data_source), desc="Initializing Sampler"):
|
| 490 |
+
if example['dataset_name'] in self.data_positions.keys():
|
| 491 |
+
self.data_positions[example['dataset_name']].append(i)
|
| 492 |
+
else:
|
| 493 |
+
self.data_positions[example['dataset_name']] = [i]
|
| 494 |
+
self.all_dataset_names = list(self.data_positions.keys())
|
| 495 |
+
self.dataset_lengths = {each:len(self.data_positions[each]) for each in self.data_positions}
|
| 496 |
+
|
| 497 |
+
self.dataset_props = {each: min(self.dataset_lengths[each], self.K) for each in self.dataset_lengths}
|
| 498 |
+
self.dataset_props_sum = sum([self.dataset_props[each] for each in self.dataset_props])
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
|
| 502 |
+
print("Finish Prop Sampler initialization.")
|
| 503 |
+
|
| 504 |
+
def __iter__(self):
|
| 505 |
+
iter_list = []
|
| 506 |
+
for each in self.dataset_props:
|
| 507 |
+
iter_list.extend(np.random.choice(self.data_positions[each], size=self.dataset_props[each], replace=False).tolist())
|
| 508 |
+
|
| 509 |
+
random.shuffle(iter_list)
|
| 510 |
+
|
| 511 |
+
yield from iter_list
|
| 512 |
+
|
| 513 |
+
def __len__(self):
|
| 514 |
+
return self.dataset_props_sum
|
| 515 |
+
|
| 516 |
+
class DSTDataLoader(LightningDataModule):
|
| 517 |
+
def __init__(self,dataset_config, val_dataset_config=None, sample_mode='seq', model_name='bert-base-uncased', is_finetune=False, need_mlm=True, tokenizer_max_length=512, train_batch_size=32, eval_batch_size=4, num_workers=16, train_eval_split=0.95, **kwargs):
|
| 518 |
+
super().__init__(**kwargs)
|
| 519 |
+
assert sample_mode in ['seq', 'proportion']
|
| 520 |
+
self.sample_mode = sample_mode
|
| 521 |
+
self.dataset_config = dataset_config
|
| 522 |
+
self.val_dataset_config = val_dataset_config
|
| 523 |
+
self.num_workers = num_workers
|
| 524 |
+
self.train_eval_split = train_eval_split
|
| 525 |
+
self.tokenizer_max_length = tokenizer_max_length
|
| 526 |
+
self.model_name = model_name
|
| 527 |
+
|
| 528 |
+
self.need_mlm = need_mlm
|
| 529 |
+
self.is_finetune = is_finetune
|
| 530 |
+
|
| 531 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 532 |
+
self.config = AutoConfig.from_pretrained(model_name)
|
| 533 |
+
|
| 534 |
+
self.train_bach_size = train_batch_size
|
| 535 |
+
self.eval_batch_size = eval_batch_size
|
| 536 |
+
|
| 537 |
+
self.dataset = None
|
| 538 |
+
|
| 539 |
+
def setup(self, stage: Optional[str] = None) -> None:
|
| 540 |
+
if self.dataset is not None:
|
| 541 |
+
print("Already Initilized LightningDataModule!")
|
| 542 |
+
return
|
| 543 |
+
|
| 544 |
+
self.init_training_set()
|
| 545 |
+
|
| 546 |
+
self.dataset = dict()
|
| 547 |
+
if not self.is_finetune:
|
| 548 |
+
self.dataset['train'] = DSTDataSet(dataset=self.raw_dataset[:int(self.train_eval_split*len(self.raw_dataset))], model_name=self.model_name, need_mlm=self.need_mlm)
|
| 549 |
+
self.dataset['test'] = DSTDataSet(dataset=self.raw_dataset[int(self.train_eval_split*len(self.raw_dataset)):], model_name=self.model_name, need_mlm=self.need_mlm)
|
| 550 |
+
else:
|
| 551 |
+
self.dataset['train'] = DSTDataSet(dataset=self.raw_dataset[:], model_name=self.model_name, need_mlm=self.need_mlm)
|
| 552 |
+
self.dataset['test'] = DSTDataSet(dataset=self.val_raw_dataset[:], model_name=self.model_name, need_mlm=self.need_mlm)
|
| 553 |
+
|
| 554 |
+
|
| 555 |
+
def init_training_set(self):
|
| 556 |
+
self.raw_dataset = []
|
| 557 |
+
if self.sample_mode == 'seq':
|
| 558 |
+
for each_dataset in self.dataset_config:
|
| 559 |
+
dataset_length = sum([1 for line in open(self.dataset_config[each_dataset]['data_path'], 'r', encoding='utf8')])
|
| 560 |
+
dataset_length_limit = self.dataset_config[each_dataset]['size'] if isinstance(self.dataset_config[each_dataset]['size'], int) else int(self.dataset_config[each_dataset]['size'] * dataset_length)
|
| 561 |
+
with open(self.dataset_config[each_dataset]['data_path'], 'r', encoding='utf8') as f:
|
| 562 |
+
try:
|
| 563 |
+
for i, example in enumerate(f):
|
| 564 |
+
if i >= dataset_length_limit:
|
| 565 |
+
break
|
| 566 |
+
self.raw_dataset.append(json.loads(example)) ## + dataset_name
|
| 567 |
+
except:
|
| 568 |
+
print(f"failed to load data from {each_dataset}.json, exiting...")
|
| 569 |
+
exit()
|
| 570 |
+
|
| 571 |
+
random.shuffle(self.raw_dataset)
|
| 572 |
+
|
| 573 |
+
elif self.sample_mode == 'proportion':
|
| 574 |
+
for each_dataset in tqdm(self.dataset_config, desc="Loading data from disk..."):
|
| 575 |
+
with open(self.dataset_config[each_dataset]['data_path'], 'r', encoding='utf8') as f:
|
| 576 |
+
try:
|
| 577 |
+
for i, example in enumerate(f):
|
| 578 |
+
jsonobj = json.loads(example)
|
| 579 |
+
jsonobj['dataset_name'] = each_dataset
|
| 580 |
+
self.raw_dataset.append(jsonobj) ## + dataset_name
|
| 581 |
+
except:
|
| 582 |
+
print(f"failed to load data from {each_dataset}.json, exiting...")
|
| 583 |
+
exit()
|
| 584 |
+
|
| 585 |
+
random.shuffle(self.raw_dataset)
|
| 586 |
+
|
| 587 |
+
if self.is_finetune:
|
| 588 |
+
self.val_raw_dataset = []
|
| 589 |
+
for each_dataset in self.val_dataset_config:
|
| 590 |
+
dataset_length = sum([1 for line in open(self.val_dataset_config[each_dataset]['data_path'], 'r', encoding='utf8')])
|
| 591 |
+
dataset_length_limit = self.val_dataset_config[each_dataset]['size'] if isinstance(self.val_dataset_config[each_dataset]['size'], int) else int(self.val_dataset_config[each_dataset]['size'] * dataset_length)
|
| 592 |
+
with open(self.val_dataset_config[each_dataset]['data_path'], 'r', encoding='utf8') as f:
|
| 593 |
+
for i, example in enumerate(f):
|
| 594 |
+
if i >= dataset_length_limit:
|
| 595 |
+
break
|
| 596 |
+
self.val_raw_dataset.append(json.loads(example))
|
| 597 |
+
|
| 598 |
+
random.shuffle(self.val_raw_dataset)
|
| 599 |
+
|
| 600 |
+
def prepare_data(self) -> None:
|
| 601 |
+
AutoTokenizer.from_pretrained(self.model_name)
|
| 602 |
+
|
| 603 |
+
def train_dataloader(self):
|
| 604 |
+
if self.sample_mode == 'seq':
|
| 605 |
+
return DataLoader(self.dataset['train'], batch_size=self.train_bach_size, shuffle=True, num_workers=self.num_workers)
|
| 606 |
+
elif self.sample_mode == 'proportion':
|
| 607 |
+
return DataLoader(self.dataset['train'], batch_size=self.train_bach_size, sampler=PropSampler(self.raw_dataset[:int(self.train_eval_split*len(self.raw_dataset))]), num_workers=self.num_workers)
|
| 608 |
+
|
| 609 |
+
def val_dataloader(self):
|
| 610 |
+
return DataLoader(self.dataset['test'], batch_size=self.eval_batch_size, shuffle=False, num_workers=self.num_workers)
|
alignscore/src/alignscore/inference.py
ADDED
|
@@ -0,0 +1,293 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from logging import warning
|
| 2 |
+
import spacy
|
| 3 |
+
from nltk.tokenize import sent_tokenize
|
| 4 |
+
import torch
|
| 5 |
+
from .model import BERTAlignModel
|
| 6 |
+
from transformers import AutoConfig, AutoTokenizer
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
class Inferencer():
|
| 11 |
+
def __init__(self, ckpt_path, model='bert-base-uncased', batch_size=32, device='cuda', verbose=True) -> None:
|
| 12 |
+
self.device = device
|
| 13 |
+
if ckpt_path is not None:
|
| 14 |
+
self.model = BERTAlignModel(model=model).load_from_checkpoint(checkpoint_path=ckpt_path, strict=False).to(self.device)
|
| 15 |
+
else:
|
| 16 |
+
warning('loading UNTRAINED model!')
|
| 17 |
+
self.model = BERTAlignModel(model=model).to(self.device)
|
| 18 |
+
self.model.eval()
|
| 19 |
+
self.batch_size = batch_size
|
| 20 |
+
|
| 21 |
+
self.config = AutoConfig.from_pretrained(model)
|
| 22 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model)
|
| 23 |
+
self.spacy = spacy.load('en_core_web_sm')
|
| 24 |
+
|
| 25 |
+
self.loss_fct = nn.CrossEntropyLoss(reduction='none')
|
| 26 |
+
self.softmax = nn.Softmax(dim=-1)
|
| 27 |
+
|
| 28 |
+
self.smart_type = 'smart-n'
|
| 29 |
+
self.smart_n_metric = 'f1'
|
| 30 |
+
|
| 31 |
+
self.disable_progress_bar_in_inference = False
|
| 32 |
+
|
| 33 |
+
self.nlg_eval_mode = None # bin, bin_sp, nli, nli_sp
|
| 34 |
+
self.verbose = verbose
|
| 35 |
+
|
| 36 |
+
def inference_example_batch(self, premise: list, hypo: list):
|
| 37 |
+
"""
|
| 38 |
+
inference a example,
|
| 39 |
+
premise: list
|
| 40 |
+
hypo: list
|
| 41 |
+
using self.inference to batch the process
|
| 42 |
+
|
| 43 |
+
SummaC Style aggregation
|
| 44 |
+
"""
|
| 45 |
+
self.disable_progress_bar_in_inference = True
|
| 46 |
+
assert len(premise) == len(hypo), "Premise must has the same length with Hypothesis!"
|
| 47 |
+
|
| 48 |
+
out_score = []
|
| 49 |
+
for one_pre, one_hypo in tqdm(zip(premise, hypo), desc="Evaluating", total=len(premise), disable=(not self.verbose)):
|
| 50 |
+
out_score.append(self.inference_per_example(one_pre, one_hypo))
|
| 51 |
+
|
| 52 |
+
return None, torch.tensor(out_score), None
|
| 53 |
+
|
| 54 |
+
def inference_per_example(self, premise:str, hypo: str):
|
| 55 |
+
"""
|
| 56 |
+
inference a example,
|
| 57 |
+
premise: string
|
| 58 |
+
hypo: string
|
| 59 |
+
using self.inference to batch the process
|
| 60 |
+
"""
|
| 61 |
+
def chunks(lst, n):
|
| 62 |
+
"""Yield successive n-sized chunks from lst."""
|
| 63 |
+
for i in range(0, len(lst), n):
|
| 64 |
+
yield ' '.join(lst[i:i + n])
|
| 65 |
+
|
| 66 |
+
premise_sents = sent_tokenize(premise)
|
| 67 |
+
premise_sents = premise_sents or ['']
|
| 68 |
+
|
| 69 |
+
n_chunk = len(premise.strip().split()) // 350 + 1
|
| 70 |
+
n_chunk = max(len(premise_sents) // n_chunk, 1)
|
| 71 |
+
premise_sents = [each for each in chunks(premise_sents, n_chunk)]
|
| 72 |
+
|
| 73 |
+
hypo_sents = sent_tokenize(hypo)
|
| 74 |
+
|
| 75 |
+
premise_sent_mat = []
|
| 76 |
+
hypo_sents_mat = []
|
| 77 |
+
for i in range(len(premise_sents)):
|
| 78 |
+
for j in range(len(hypo_sents)):
|
| 79 |
+
premise_sent_mat.append(premise_sents[i])
|
| 80 |
+
hypo_sents_mat.append(hypo_sents[j])
|
| 81 |
+
|
| 82 |
+
if self.nlg_eval_mode is not None:
|
| 83 |
+
if self.nlg_eval_mode == 'nli_sp':
|
| 84 |
+
output_score = self.inference(premise_sent_mat, hypo_sents_mat)[2][:,0] ### use NLI head OR ALIGN head
|
| 85 |
+
elif self.nlg_eval_mode == 'bin_sp':
|
| 86 |
+
output_score = self.inference(premise_sent_mat, hypo_sents_mat)[1] ### use NLI head OR ALIGN head
|
| 87 |
+
elif self.nlg_eval_mode == 'reg_sp':
|
| 88 |
+
output_score = self.inference(premise_sent_mat, hypo_sents_mat)[0] ### use NLI head OR ALIGN head
|
| 89 |
+
|
| 90 |
+
output_score = output_score.view(len(premise_sents), len(hypo_sents)).max(dim=0).values.mean().item() ### sum or mean depends on the task/aspect
|
| 91 |
+
return output_score
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
output_score = self.inference(premise_sent_mat, hypo_sents_mat)[2][:,0] ### use NLI head OR ALIGN head
|
| 95 |
+
output_score = output_score.view(len(premise_sents), len(hypo_sents)).max(dim=0).values.mean().item() ### sum or mean depends on the task/aspect
|
| 96 |
+
|
| 97 |
+
return output_score
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def inference(self, premise, hypo):
|
| 101 |
+
"""
|
| 102 |
+
inference a list of premise and hypo
|
| 103 |
+
|
| 104 |
+
Standard aggregation
|
| 105 |
+
"""
|
| 106 |
+
if isinstance(premise, str) and isinstance(hypo, str):
|
| 107 |
+
premise = [premise]
|
| 108 |
+
hypo = [hypo]
|
| 109 |
+
|
| 110 |
+
batch = self.batch_tokenize(premise, hypo)
|
| 111 |
+
output_score_reg = []
|
| 112 |
+
output_score_bin = []
|
| 113 |
+
output_score_tri = []
|
| 114 |
+
|
| 115 |
+
for mini_batch in tqdm(batch, desc="Evaluating", disable=not self.verbose or self.disable_progress_bar_in_inference):
|
| 116 |
+
mini_batch = mini_batch.to(self.device)
|
| 117 |
+
with torch.no_grad():
|
| 118 |
+
model_output = self.model(mini_batch)
|
| 119 |
+
model_output_reg = model_output.reg_label_logits.cpu()
|
| 120 |
+
model_output_bin = model_output.seq_relationship_logits # Temperature Scaling / 2.5
|
| 121 |
+
model_output_tri = model_output.tri_label_logits
|
| 122 |
+
|
| 123 |
+
model_output_bin = self.softmax(model_output_bin).cpu()
|
| 124 |
+
model_output_tri = self.softmax(model_output_tri).cpu()
|
| 125 |
+
output_score_reg.append(model_output_reg[:,0])
|
| 126 |
+
output_score_bin.append(model_output_bin[:,1])
|
| 127 |
+
output_score_tri.append(model_output_tri[:,:])
|
| 128 |
+
|
| 129 |
+
output_score_reg = torch.cat(output_score_reg)
|
| 130 |
+
output_score_bin = torch.cat(output_score_bin)
|
| 131 |
+
output_score_tri = torch.cat(output_score_tri)
|
| 132 |
+
|
| 133 |
+
if self.nlg_eval_mode is not None:
|
| 134 |
+
if self.nlg_eval_mode == 'nli':
|
| 135 |
+
output_score_nli = output_score_tri[:,0]
|
| 136 |
+
return None, output_score_nli, None
|
| 137 |
+
elif self.nlg_eval_mode == 'bin':
|
| 138 |
+
return None, output_score_bin, None
|
| 139 |
+
elif self.nlg_eval_mode == 'reg':
|
| 140 |
+
return None, output_score_reg, None
|
| 141 |
+
else:
|
| 142 |
+
ValueError("unrecognized nlg eval mode")
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
return output_score_reg, output_score_bin, output_score_tri
|
| 146 |
+
|
| 147 |
+
def inference_reg(self, premise, hypo):
|
| 148 |
+
"""
|
| 149 |
+
inference a list of premise and hypo
|
| 150 |
+
|
| 151 |
+
Standard aggregation
|
| 152 |
+
"""
|
| 153 |
+
self.model.is_reg_finetune = True
|
| 154 |
+
if isinstance(premise, str) and isinstance(hypo, str):
|
| 155 |
+
premise = [premise]
|
| 156 |
+
hypo = [hypo]
|
| 157 |
+
|
| 158 |
+
batch = self.batch_tokenize(premise, hypo)
|
| 159 |
+
output_score = []
|
| 160 |
+
|
| 161 |
+
for mini_batch in tqdm(batch, desc="Evaluating", disable=self.disable_progress_bar_in_inference):
|
| 162 |
+
mini_batch = mini_batch.to(self.device)
|
| 163 |
+
with torch.no_grad():
|
| 164 |
+
model_output = self.model(mini_batch).seq_relationship_logits.cpu().view(-1)
|
| 165 |
+
output_score.append(model_output)
|
| 166 |
+
output_score = torch.cat(output_score)
|
| 167 |
+
return output_score
|
| 168 |
+
|
| 169 |
+
def batch_tokenize(self, premise, hypo):
|
| 170 |
+
"""
|
| 171 |
+
input premise and hypos are lists
|
| 172 |
+
"""
|
| 173 |
+
assert isinstance(premise, list) and isinstance(hypo, list)
|
| 174 |
+
assert len(premise) == len(hypo), "premise and hypo should be in the same length."
|
| 175 |
+
|
| 176 |
+
batch = []
|
| 177 |
+
for mini_batch_pre, mini_batch_hypo in zip(self.chunks(premise, self.batch_size), self.chunks(hypo, self.batch_size)):
|
| 178 |
+
try:
|
| 179 |
+
mini_batch = self.tokenizer(mini_batch_pre, mini_batch_hypo, truncation='only_first', padding='max_length', max_length=self.tokenizer.model_max_length, return_tensors='pt')
|
| 180 |
+
except:
|
| 181 |
+
warning('text_b too long...')
|
| 182 |
+
mini_batch = self.tokenizer(mini_batch_pre, mini_batch_hypo, truncation=True, padding='max_length', max_length=self.tokenizer.model_max_length, return_tensors='pt')
|
| 183 |
+
batch.append(mini_batch)
|
| 184 |
+
|
| 185 |
+
return batch
|
| 186 |
+
def smart_doc(self, premise: list, hypo: list):
|
| 187 |
+
"""
|
| 188 |
+
inference a example,
|
| 189 |
+
premise: list
|
| 190 |
+
hypo: list
|
| 191 |
+
using self.inference to batch the process
|
| 192 |
+
|
| 193 |
+
SMART Style aggregation
|
| 194 |
+
"""
|
| 195 |
+
self.disable_progress_bar_in_inference = True
|
| 196 |
+
assert len(premise) == len(hypo), "Premise must has the same length with Hypothesis!"
|
| 197 |
+
assert self.smart_type in ['smart-n', 'smart-l']
|
| 198 |
+
|
| 199 |
+
out_score = []
|
| 200 |
+
for one_pre, one_hypo in tqdm(zip(premise, hypo), desc="Evaluating SMART", total=len(premise)):
|
| 201 |
+
out_score.append(self.smart_l(one_pre, one_hypo)[1] if self.smart_type == 'smart-l' else self.smart_n(one_pre, one_hypo)[1])
|
| 202 |
+
|
| 203 |
+
return None, torch.tensor(out_score), None
|
| 204 |
+
|
| 205 |
+
def smart_l(self, premise, hypo):
|
| 206 |
+
premise_sents = [each.text for each in self.spacy(premise).sents]
|
| 207 |
+
hypo_sents = [each.text for each in self.spacy(hypo).sents]
|
| 208 |
+
|
| 209 |
+
premise_sent_mat = []
|
| 210 |
+
hypo_sents_mat = []
|
| 211 |
+
for i in range(len(premise_sents)):
|
| 212 |
+
for j in range(len(hypo_sents)):
|
| 213 |
+
premise_sent_mat.append(premise_sents[i])
|
| 214 |
+
hypo_sents_mat.append(hypo_sents[j])
|
| 215 |
+
|
| 216 |
+
output_score = self.inference(premise_sent_mat, hypo_sents_mat)[2][:,0]
|
| 217 |
+
output_score = output_score.view(len(premise_sents), len(hypo_sents))
|
| 218 |
+
|
| 219 |
+
### smart-l
|
| 220 |
+
lcs = [[0] * (len(hypo_sents)+1)] * (len(premise_sents)+1)
|
| 221 |
+
for i in range(len(premise_sents)+1):
|
| 222 |
+
for j in range(len(hypo_sents)+1):
|
| 223 |
+
if i != 0 and j != 0:
|
| 224 |
+
m = output_score[i-1, j-1]
|
| 225 |
+
lcs[i][j] = max([lcs[i-1][j-1]+m,
|
| 226 |
+
lcs[i-1][j]+m,
|
| 227 |
+
lcs[i][j-1]])
|
| 228 |
+
|
| 229 |
+
return None, lcs[-1][-1] / len(premise_sents), None
|
| 230 |
+
|
| 231 |
+
def smart_n(self, premise, hypo):
|
| 232 |
+
### smart-n
|
| 233 |
+
n_gram = 1
|
| 234 |
+
|
| 235 |
+
premise_sents = [each.text for each in self.spacy(premise).sents]
|
| 236 |
+
hypo_sents = [each.text for each in self.spacy(hypo).sents]
|
| 237 |
+
|
| 238 |
+
premise_sent_mat = []
|
| 239 |
+
hypo_sents_mat = []
|
| 240 |
+
for i in range(len(premise_sents)):
|
| 241 |
+
for j in range(len(hypo_sents)):
|
| 242 |
+
premise_sent_mat.append(premise_sents[i])
|
| 243 |
+
hypo_sents_mat.append(hypo_sents[j])
|
| 244 |
+
|
| 245 |
+
output_score = self.inference(premise_sent_mat, hypo_sents_mat)[2][:,0]
|
| 246 |
+
output_score = output_score.view(len(premise_sents), len(hypo_sents))
|
| 247 |
+
|
| 248 |
+
prec = sum([max([sum([output_score[i+n, j+n]/n_gram for n in range(0, n_gram)]) for i in range(len(premise_sents)-n_gram+1)]) for j in range(len(hypo_sents)-n_gram+1)])
|
| 249 |
+
prec = prec / (len(hypo_sents) - n_gram + 1) if (len(hypo_sents) - n_gram + 1) > 0 else 0.
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
premise_sents = [each.text for each in self.spacy(hypo).sents]# simple change
|
| 253 |
+
hypo_sents = [each.text for each in self.spacy(premise).sents]#
|
| 254 |
+
|
| 255 |
+
premise_sent_mat = []
|
| 256 |
+
hypo_sents_mat = []
|
| 257 |
+
for i in range(len(premise_sents)):
|
| 258 |
+
for j in range(len(hypo_sents)):
|
| 259 |
+
premise_sent_mat.append(premise_sents[i])
|
| 260 |
+
hypo_sents_mat.append(hypo_sents[j])
|
| 261 |
+
|
| 262 |
+
output_score = self.inference(premise_sent_mat, hypo_sents_mat)[2][:,0]
|
| 263 |
+
output_score = output_score.view(len(premise_sents), len(hypo_sents))
|
| 264 |
+
|
| 265 |
+
recall = sum([max([sum([output_score[i+n, j+n]/n_gram for n in range(0, n_gram)]) for i in range(len(premise_sents)-n_gram+1)]) for j in range(len(hypo_sents)-n_gram+1)])
|
| 266 |
+
recall = prec / (len(hypo_sents) - n_gram + 1) if (len(hypo_sents) - n_gram + 1) > 0 else 0.
|
| 267 |
+
|
| 268 |
+
f1 = 2 * prec * recall / (prec + recall)
|
| 269 |
+
|
| 270 |
+
if self.smart_n_metric == 'f1':
|
| 271 |
+
return None, f1, None
|
| 272 |
+
elif self.smart_n_metric == 'precision':
|
| 273 |
+
return None, prec, None
|
| 274 |
+
elif self.smart_n_metric == 'recall':
|
| 275 |
+
return None, recall, None
|
| 276 |
+
else:
|
| 277 |
+
ValueError("SMART return type error")
|
| 278 |
+
|
| 279 |
+
def chunks(self, lst, n):
|
| 280 |
+
"""Yield successive n-sized chunks from lst."""
|
| 281 |
+
for i in range(0, len(lst), n):
|
| 282 |
+
yield lst[i:i + n]
|
| 283 |
+
|
| 284 |
+
def nlg_eval(self, premise, hypo):
|
| 285 |
+
assert self.nlg_eval_mode is not None, "Select NLG Eval mode!"
|
| 286 |
+
if (self.nlg_eval_mode == 'bin') or (self.nlg_eval_mode == 'nli') or (self.nlg_eval_mode == 'reg'):
|
| 287 |
+
return self.inference(premise, hypo)
|
| 288 |
+
|
| 289 |
+
elif (self.nlg_eval_mode == 'bin_sp') or (self.nlg_eval_mode == 'nli_sp') or (self.nlg_eval_mode == 'reg_sp'):
|
| 290 |
+
return self.inference_example_batch(premise, hypo)
|
| 291 |
+
|
| 292 |
+
else:
|
| 293 |
+
ValueError("Unrecognized NLG Eval mode!")
|
alignscore/src/alignscore/model.py
ADDED
|
@@ -0,0 +1,308 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Optional, Tuple
|
| 3 |
+
from transformers import AdamW, get_linear_schedule_with_warmup, AutoConfig
|
| 4 |
+
from transformers import BertForPreTraining, BertModel, RobertaModel, AlbertModel, AlbertForMaskedLM, RobertaForMaskedLM
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import pytorch_lightning as pl
|
| 8 |
+
from sklearn.metrics import f1_score
|
| 9 |
+
from dataclasses import dataclass
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class BERTAlignModel(pl.LightningModule):
|
| 14 |
+
def __init__(self, model='bert-base-uncased', using_pretrained=True, *args, **kwargs) -> None:
|
| 15 |
+
super().__init__()
|
| 16 |
+
# Already defined in lightning: self.device
|
| 17 |
+
self.save_hyperparameters()
|
| 18 |
+
self.model = model
|
| 19 |
+
|
| 20 |
+
if 'muppet' in model:
|
| 21 |
+
assert using_pretrained == True, "Only support pretrained muppet!"
|
| 22 |
+
self.base_model = RobertaModel.from_pretrained(model)
|
| 23 |
+
self.mlm_head = RobertaForMaskedLM(AutoConfig.from_pretrained(model)).lm_head
|
| 24 |
+
|
| 25 |
+
elif 'roberta' in model:
|
| 26 |
+
if using_pretrained:
|
| 27 |
+
self.base_model = RobertaModel.from_pretrained(model)
|
| 28 |
+
self.mlm_head = RobertaForMaskedLM.from_pretrained(model).lm_head
|
| 29 |
+
else:
|
| 30 |
+
self.base_model = RobertaModel(AutoConfig.from_pretrained(model))
|
| 31 |
+
self.mlm_head = RobertaForMaskedLM(AutoConfig.from_pretrained(model)).lm_head
|
| 32 |
+
|
| 33 |
+
elif 'albert' in model:
|
| 34 |
+
if using_pretrained:
|
| 35 |
+
self.base_model = AlbertModel.from_pretrained(model)
|
| 36 |
+
self.mlm_head = AlbertForMaskedLM.from_pretrained(model).predictions
|
| 37 |
+
else:
|
| 38 |
+
self.base_model = AlbertModel(AutoConfig.from_pretrained(model))
|
| 39 |
+
self.mlm_head = AlbertForMaskedLM(AutoConfig.from_pretrained(model)).predictions
|
| 40 |
+
|
| 41 |
+
elif 'bert' in model:
|
| 42 |
+
if using_pretrained:
|
| 43 |
+
self.base_model = BertModel.from_pretrained(model)
|
| 44 |
+
self.mlm_head = BertForPreTraining.from_pretrained(model).cls.predictions
|
| 45 |
+
else:
|
| 46 |
+
self.base_model = BertModel(AutoConfig.from_pretrained(model))
|
| 47 |
+
self.mlm_head = BertForPreTraining(AutoConfig.from_pretrained(model)).cls.predictions
|
| 48 |
+
|
| 49 |
+
elif 'electra' in model:
|
| 50 |
+
self.generator = BertModel(AutoConfig.from_pretrained('prajjwal1/bert-small'))
|
| 51 |
+
self.generator_mlm = BertForPreTraining(AutoConfig.from_pretrained('prajjwal1/bert-small')).cls.predictions
|
| 52 |
+
|
| 53 |
+
self.base_model = BertModel(AutoConfig.from_pretrained('bert-base-uncased'))
|
| 54 |
+
self.discriminator_predictor = ElectraDiscriminatorPredictions(self.base_model.config)
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
self.bin_layer = nn.Linear(self.base_model.config.hidden_size, 2)
|
| 58 |
+
self.tri_layer = nn.Linear(self.base_model.config.hidden_size, 3)
|
| 59 |
+
self.reg_layer = nn.Linear(self.base_model.config.hidden_size, 1)
|
| 60 |
+
|
| 61 |
+
self.dropout = nn.Dropout(p=0.1)
|
| 62 |
+
|
| 63 |
+
self.need_mlm = True
|
| 64 |
+
self.is_finetune = False
|
| 65 |
+
self.mlm_loss_factor = 0.5
|
| 66 |
+
|
| 67 |
+
self.softmax = nn.Softmax(dim=-1)
|
| 68 |
+
|
| 69 |
+
def forward(self, batch):
|
| 70 |
+
if 'electra' in self.model:
|
| 71 |
+
return self.electra_forward(batch)
|
| 72 |
+
base_model_output = self.base_model(
|
| 73 |
+
input_ids = batch['input_ids'],
|
| 74 |
+
attention_mask = batch['attention_mask'],
|
| 75 |
+
token_type_ids = batch['token_type_ids'] if 'token_type_ids' in batch.keys() else None
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
prediction_scores = self.mlm_head(base_model_output.last_hidden_state) ## sequence_output for mlm
|
| 79 |
+
seq_relationship_score = self.bin_layer(self.dropout(base_model_output.pooler_output)) ## pooled output for classification
|
| 80 |
+
tri_label_score = self.tri_layer(self.dropout(base_model_output.pooler_output))
|
| 81 |
+
reg_label_score = self.reg_layer(base_model_output.pooler_output)
|
| 82 |
+
|
| 83 |
+
total_loss = None
|
| 84 |
+
if 'mlm_label' in batch.keys(): ### 'mlm_label' and 'align_label' when training
|
| 85 |
+
ce_loss_fct = nn.CrossEntropyLoss(reduction='sum')
|
| 86 |
+
masked_lm_loss = ce_loss_fct(prediction_scores.view(-1, self.base_model.config.vocab_size), batch['mlm_label'].view(-1)) #/ self.con vocabulary
|
| 87 |
+
next_sentence_loss = ce_loss_fct(seq_relationship_score.view(-1, 2), batch['align_label'].view(-1)) / math.log(2)
|
| 88 |
+
tri_label_loss = ce_loss_fct(tri_label_score.view(-1, 3), batch['tri_label'].view(-1)) / math.log(3)
|
| 89 |
+
reg_label_loss = self.mse_loss(reg_label_score.view(-1), batch['reg_label'].view(-1), reduction='sum')
|
| 90 |
+
|
| 91 |
+
masked_lm_loss_num = torch.sum(batch['mlm_label'].view(-1) != -100)
|
| 92 |
+
next_sentence_loss_num = torch.sum(batch['align_label'].view(-1) != -100)
|
| 93 |
+
tri_label_loss_num = torch.sum(batch['tri_label'].view(-1) != -100)
|
| 94 |
+
reg_label_loss_num = torch.sum(batch['reg_label'].view(-1) != -100.0)
|
| 95 |
+
|
| 96 |
+
return ModelOutput(
|
| 97 |
+
loss=total_loss,
|
| 98 |
+
all_loss=[masked_lm_loss, next_sentence_loss, tri_label_loss, reg_label_loss] if 'mlm_label' in batch.keys() else None,
|
| 99 |
+
loss_nums=[masked_lm_loss_num, next_sentence_loss_num, tri_label_loss_num, reg_label_loss_num] if 'mlm_label' in batch.keys() else None,
|
| 100 |
+
prediction_logits=prediction_scores,
|
| 101 |
+
seq_relationship_logits=seq_relationship_score,
|
| 102 |
+
tri_label_logits=tri_label_score,
|
| 103 |
+
reg_label_logits=reg_label_score,
|
| 104 |
+
hidden_states=base_model_output.hidden_states,
|
| 105 |
+
attentions=base_model_output.attentions
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
def electra_forward(self, batch):
|
| 109 |
+
if 'mlm_label' in batch.keys():
|
| 110 |
+
ce_loss_fct = nn.CrossEntropyLoss()
|
| 111 |
+
generator_output = self.generator_mlm(self.generator(
|
| 112 |
+
input_ids = batch['input_ids'],
|
| 113 |
+
attention_mask = batch['attention_mask'],
|
| 114 |
+
token_type_ids = batch['token_type_ids'] if 'token_type_ids' in batch.keys() else None
|
| 115 |
+
).last_hidden_state)
|
| 116 |
+
masked_lm_loss = ce_loss_fct(generator_output.view(-1, self.generator.config.vocab_size), batch['mlm_label'].view(-1))
|
| 117 |
+
|
| 118 |
+
hallucinated_tokens = batch['input_ids'].clone()
|
| 119 |
+
|
| 120 |
+
hallucinated_tokens[batch['mlm_label']!=-100] = torch.argmax(generator_output, dim=-1)[batch['mlm_label']!=-100]
|
| 121 |
+
replaced_token_label = (batch['input_ids'] == hallucinated_tokens).long()#.type(torch.LongTensor) #[batch['mlm_label'] == -100] = -100
|
| 122 |
+
replaced_token_label[batch['mlm_label']!=-100] = (batch['mlm_label'] == hallucinated_tokens)[batch['mlm_label']!=-100].long()
|
| 123 |
+
replaced_token_label[batch['input_ids'] == 0] = -100 ### ignore paddings
|
| 124 |
+
|
| 125 |
+
base_model_output = self.base_model(
|
| 126 |
+
input_ids = hallucinated_tokens if 'mlm_label' in batch.keys() else batch['input_ids'],
|
| 127 |
+
attention_mask = batch['attention_mask'],
|
| 128 |
+
token_type_ids = batch['token_type_ids'] if 'token_type_ids' in batch.keys() else None
|
| 129 |
+
)
|
| 130 |
+
hallu_detect_score = self.discriminator_predictor(base_model_output.last_hidden_state)
|
| 131 |
+
seq_relationship_score = self.bin_layer(self.dropout(base_model_output.pooler_output)) ## pooled output for classification
|
| 132 |
+
tri_label_score = self.tri_layer(self.dropout(base_model_output.pooler_output))
|
| 133 |
+
reg_label_score = self.reg_layer(base_model_output.pooler_output)
|
| 134 |
+
|
| 135 |
+
total_loss = None
|
| 136 |
+
|
| 137 |
+
if 'mlm_label' in batch.keys(): ### 'mlm_label' and 'align_label' when training
|
| 138 |
+
total_loss = []
|
| 139 |
+
ce_loss_fct = nn.CrossEntropyLoss()
|
| 140 |
+
hallu_detect_loss = ce_loss_fct(hallu_detect_score.view(-1,2),replaced_token_label.view(-1))
|
| 141 |
+
next_sentence_loss = ce_loss_fct(seq_relationship_score.view(-1, 2), batch['align_label'].view(-1))
|
| 142 |
+
tri_label_loss = ce_loss_fct(tri_label_score.view(-1, 3), batch['tri_label'].view(-1))
|
| 143 |
+
reg_label_loss = self.mse_loss(reg_label_score.view(-1), batch['reg_label'].view(-1))
|
| 144 |
+
|
| 145 |
+
total_loss.append(10.0 * hallu_detect_loss if not torch.isnan(hallu_detect_loss).item() else 0.)
|
| 146 |
+
total_loss.append(0.2 * masked_lm_loss if (not torch.isnan(masked_lm_loss).item() and self.need_mlm) else 0.)
|
| 147 |
+
total_loss.append(next_sentence_loss if not torch.isnan(next_sentence_loss).item() else 0.)
|
| 148 |
+
total_loss.append(tri_label_loss if not torch.isnan(tri_label_loss).item() else 0.)
|
| 149 |
+
total_loss.append(reg_label_loss if not torch.isnan(reg_label_loss).item() else 0.)
|
| 150 |
+
|
| 151 |
+
total_loss = sum(total_loss)
|
| 152 |
+
|
| 153 |
+
return ModelOutput(
|
| 154 |
+
loss=total_loss,
|
| 155 |
+
all_loss=[masked_lm_loss, next_sentence_loss, tri_label_loss, reg_label_loss, hallu_detect_loss] if 'mlm_label' in batch.keys() else None,
|
| 156 |
+
prediction_logits=hallu_detect_score,
|
| 157 |
+
seq_relationship_logits=seq_relationship_score,
|
| 158 |
+
tri_label_logits=tri_label_score,
|
| 159 |
+
reg_label_logits=reg_label_score,
|
| 160 |
+
hidden_states=base_model_output.hidden_states,
|
| 161 |
+
attentions=base_model_output.attentions
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
def training_step(self, train_batch, batch_idx):
|
| 165 |
+
output = self(train_batch)
|
| 166 |
+
|
| 167 |
+
return {'losses': output.all_loss, 'loss_nums': output.loss_nums}
|
| 168 |
+
|
| 169 |
+
def training_step_end(self, step_output):
|
| 170 |
+
losses = step_output['losses']
|
| 171 |
+
loss_nums = step_output['loss_nums']
|
| 172 |
+
assert len(loss_nums) == len(losses), 'loss_num should be the same length as losses'
|
| 173 |
+
|
| 174 |
+
loss_mlm_num = torch.sum(loss_nums[0])
|
| 175 |
+
loss_bin_num = torch.sum(loss_nums[1])
|
| 176 |
+
loss_tri_num = torch.sum(loss_nums[2])
|
| 177 |
+
loss_reg_num = torch.sum(loss_nums[3])
|
| 178 |
+
|
| 179 |
+
loss_mlm = torch.sum(losses[0]) / loss_mlm_num if loss_mlm_num > 0 else 0.
|
| 180 |
+
loss_bin = torch.sum(losses[1]) / loss_bin_num if loss_bin_num > 0 else 0.
|
| 181 |
+
loss_tri = torch.sum(losses[2]) / loss_tri_num if loss_tri_num > 0 else 0.
|
| 182 |
+
loss_reg = torch.sum(losses[3]) / loss_reg_num if loss_reg_num > 0 else 0.
|
| 183 |
+
|
| 184 |
+
total_loss = self.mlm_loss_factor * loss_mlm + loss_bin + loss_tri + loss_reg
|
| 185 |
+
|
| 186 |
+
self.log('train_loss', total_loss)# , sync_dist=True
|
| 187 |
+
self.log('mlm_loss', loss_mlm)
|
| 188 |
+
self.log('bin_label_loss', loss_bin)
|
| 189 |
+
self.log('tri_label_loss', loss_tri)
|
| 190 |
+
self.log('reg_label_loss', loss_reg)
|
| 191 |
+
|
| 192 |
+
return total_loss
|
| 193 |
+
|
| 194 |
+
def validation_step(self, val_batch, batch_idx):
|
| 195 |
+
if not self.is_finetune:
|
| 196 |
+
with torch.no_grad():
|
| 197 |
+
output = self(val_batch)
|
| 198 |
+
|
| 199 |
+
return {'losses': output.all_loss, 'loss_nums': output.loss_nums}
|
| 200 |
+
|
| 201 |
+
with torch.no_grad():
|
| 202 |
+
output = self(val_batch)['seq_relationship_logits']
|
| 203 |
+
output = self.softmax(output)[:, 1].tolist()
|
| 204 |
+
pred = [int(align_prob>0.5) for align_prob in output]
|
| 205 |
+
|
| 206 |
+
labels = val_batch['align_label'].tolist()
|
| 207 |
+
|
| 208 |
+
return {"pred": pred, 'labels': labels}#, "preds":preds, "labels":x['labels']}
|
| 209 |
+
|
| 210 |
+
def validation_step_end(self, step_output):
|
| 211 |
+
losses = step_output['losses']
|
| 212 |
+
loss_nums = step_output['loss_nums']
|
| 213 |
+
assert len(loss_nums) == len(losses), 'loss_num should be the same length as losses'
|
| 214 |
+
|
| 215 |
+
loss_mlm_num = torch.sum(loss_nums[0])
|
| 216 |
+
loss_bin_num = torch.sum(loss_nums[1])
|
| 217 |
+
loss_tri_num = torch.sum(loss_nums[2])
|
| 218 |
+
loss_reg_num = torch.sum(loss_nums[3])
|
| 219 |
+
|
| 220 |
+
loss_mlm = torch.sum(losses[0]) / loss_mlm_num if loss_mlm_num > 0 else 0.
|
| 221 |
+
loss_bin = torch.sum(losses[1]) / loss_bin_num if loss_bin_num > 0 else 0.
|
| 222 |
+
loss_tri = torch.sum(losses[2]) / loss_tri_num if loss_tri_num > 0 else 0.
|
| 223 |
+
loss_reg = torch.sum(losses[3]) / loss_reg_num if loss_reg_num > 0 else 0.
|
| 224 |
+
|
| 225 |
+
total_loss = self.mlm_loss_factor * loss_mlm + loss_bin + loss_tri + loss_reg
|
| 226 |
+
|
| 227 |
+
self.log('train_loss', total_loss)# , sync_dist=True
|
| 228 |
+
self.log('mlm_loss', loss_mlm)
|
| 229 |
+
self.log('bin_label_loss', loss_bin)
|
| 230 |
+
self.log('tri_label_loss', loss_tri)
|
| 231 |
+
self.log('reg_label_loss', loss_reg)
|
| 232 |
+
|
| 233 |
+
return total_loss
|
| 234 |
+
|
| 235 |
+
def validation_epoch_end(self, outputs):
|
| 236 |
+
if not self.is_finetune:
|
| 237 |
+
total_loss = torch.stack(outputs).mean()
|
| 238 |
+
self.log("val_loss", total_loss, prog_bar=True, sync_dist=True)
|
| 239 |
+
|
| 240 |
+
else:
|
| 241 |
+
all_predictions = []
|
| 242 |
+
all_labels = []
|
| 243 |
+
for each_output in outputs:
|
| 244 |
+
all_predictions.extend(each_output['pred'])
|
| 245 |
+
all_labels.extend(each_output['labels'])
|
| 246 |
+
|
| 247 |
+
self.log("f1", f1_score(all_labels, all_predictions), prog_bar=True, sync_dist=True)
|
| 248 |
+
|
| 249 |
+
def configure_optimizers(self):
|
| 250 |
+
"""Prepare optimizer and schedule (linear warmup and decay)"""
|
| 251 |
+
no_decay = ["bias", "LayerNorm.weight"]
|
| 252 |
+
optimizer_grouped_parameters = [
|
| 253 |
+
{
|
| 254 |
+
"params": [p for n, p in self.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 255 |
+
"weight_decay": self.hparams.weight_decay,
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"params": [p for n, p in self.named_parameters() if any(nd in n for nd in no_decay)],
|
| 259 |
+
"weight_decay": 0.0,
|
| 260 |
+
},
|
| 261 |
+
]
|
| 262 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon)
|
| 263 |
+
|
| 264 |
+
scheduler = get_linear_schedule_with_warmup(
|
| 265 |
+
optimizer,
|
| 266 |
+
num_warmup_steps=int(self.hparams.warmup_steps_portion * self.trainer.estimated_stepping_batches),
|
| 267 |
+
num_training_steps=self.trainer.estimated_stepping_batches,
|
| 268 |
+
)
|
| 269 |
+
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
|
| 270 |
+
return [optimizer], [scheduler]
|
| 271 |
+
|
| 272 |
+
def mse_loss(self, input, target, ignored_index=-100.0, reduction='mean'):
|
| 273 |
+
mask = (target == ignored_index)
|
| 274 |
+
out = (input[~mask]-target[~mask])**2
|
| 275 |
+
if reduction == "mean":
|
| 276 |
+
return out.mean()
|
| 277 |
+
elif reduction == "sum":
|
| 278 |
+
return out.sum()
|
| 279 |
+
|
| 280 |
+
class ElectraDiscriminatorPredictions(nn.Module):
|
| 281 |
+
"""Prediction module for the discriminator, made up of two dense layers."""
|
| 282 |
+
|
| 283 |
+
def __init__(self, config):
|
| 284 |
+
super().__init__()
|
| 285 |
+
|
| 286 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 287 |
+
self.dense_prediction = nn.Linear(config.hidden_size, 2)
|
| 288 |
+
self.config = config
|
| 289 |
+
self.gelu = nn.GELU()
|
| 290 |
+
|
| 291 |
+
def forward(self, discriminator_hidden_states):
|
| 292 |
+
hidden_states = self.dense(discriminator_hidden_states)
|
| 293 |
+
hidden_states = self.gelu(hidden_states)
|
| 294 |
+
logits = self.dense_prediction(hidden_states).squeeze(-1)
|
| 295 |
+
|
| 296 |
+
return logits
|
| 297 |
+
|
| 298 |
+
@dataclass
|
| 299 |
+
class ModelOutput():
|
| 300 |
+
loss: Optional[torch.FloatTensor] = None
|
| 301 |
+
all_loss: Optional[list] = None
|
| 302 |
+
loss_nums: Optional[list] = None
|
| 303 |
+
prediction_logits: torch.FloatTensor = None
|
| 304 |
+
seq_relationship_logits: torch.FloatTensor = None
|
| 305 |
+
tri_label_logits: torch.FloatTensor = None
|
| 306 |
+
reg_label_logits: torch.FloatTensor = None
|
| 307 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 308 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
alignscore/train.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pytorch_lightning import Trainer, seed_everything
|
| 2 |
+
from alignscore.dataloader import DSTDataLoader
|
| 3 |
+
from alignscore.model import BERTAlignModel
|
| 4 |
+
from pytorch_lightning.callbacks import ModelCheckpoint
|
| 5 |
+
from argparse import ArgumentParser
|
| 6 |
+
import os
|
| 7 |
+
|
| 8 |
+
def train(datasets, args):
|
| 9 |
+
dm = DSTDataLoader(
|
| 10 |
+
dataset_config=datasets,
|
| 11 |
+
model_name=args.model_name,
|
| 12 |
+
sample_mode='seq',
|
| 13 |
+
train_batch_size=args.batch_size,
|
| 14 |
+
eval_batch_size=16,
|
| 15 |
+
num_workers=args.num_workers,
|
| 16 |
+
train_eval_split=0.95,
|
| 17 |
+
need_mlm=args.do_mlm
|
| 18 |
+
)
|
| 19 |
+
dm.setup()
|
| 20 |
+
|
| 21 |
+
model = BERTAlignModel(model=args.model_name, using_pretrained=args.use_pretrained_model,
|
| 22 |
+
adam_epsilon=args.adam_epsilon,
|
| 23 |
+
learning_rate=args.learning_rate,
|
| 24 |
+
weight_decay=args.weight_decay,
|
| 25 |
+
warmup_steps_portion=args.warm_up_proportion
|
| 26 |
+
)
|
| 27 |
+
model.need_mlm = args.do_mlm
|
| 28 |
+
|
| 29 |
+
training_dataset_used = '_'.join(datasets.keys())
|
| 30 |
+
checkpoint_name = '_'.join((
|
| 31 |
+
f"{args.ckpt_comment}{args.model_name.replace('/', '-')}",
|
| 32 |
+
f"{'scratch_' if not args.use_pretrained_model else ''}{'no_mlm_' if not args.do_mlm else ''}{training_dataset_used}",
|
| 33 |
+
str(args.max_samples_per_dataset),
|
| 34 |
+
f"{args.batch_size}x{len(args.devices)}x{args.accumulate_grad_batch}"
|
| 35 |
+
))
|
| 36 |
+
|
| 37 |
+
checkpoint_callback = ModelCheckpoint(
|
| 38 |
+
dirpath=args.ckpt_save_path,
|
| 39 |
+
filename=checkpoint_name + "_{epoch:02d}_{step}",
|
| 40 |
+
every_n_train_steps=10000,
|
| 41 |
+
save_top_k=1
|
| 42 |
+
)
|
| 43 |
+
trainer = Trainer(
|
| 44 |
+
accelerator='gpu',
|
| 45 |
+
max_epochs=args.num_epoch,
|
| 46 |
+
devices=args.devices,
|
| 47 |
+
strategy="dp",
|
| 48 |
+
precision=32,
|
| 49 |
+
callbacks=[checkpoint_callback],
|
| 50 |
+
accumulate_grad_batches=args.accumulate_grad_batch
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
trainer.fit(model, datamodule=dm)
|
| 54 |
+
trainer.save_checkpoint(os.path.join(args.ckpt_save_path, f"{checkpoint_name}_final.ckpt"))
|
| 55 |
+
|
| 56 |
+
print("Training is finished.")
|
| 57 |
+
|
| 58 |
+
if __name__ == "__main__":
|
| 59 |
+
ALL_TRAINING_DATASETS = {
|
| 60 |
+
### NLI
|
| 61 |
+
'mnli': {'task_type': 'nli', 'data_path': 'mnli.json'},
|
| 62 |
+
'doc_nli': {'task_type': 'bin_nli', 'data_path': 'doc_nli.json'},
|
| 63 |
+
'snli': {'task_type': 'nli', 'data_path': 'snli.json'},
|
| 64 |
+
'anli_r1': {'task_type': 'nli', 'data_path': 'anli_r1.json'},
|
| 65 |
+
'anli_r2': {'task_type': 'nli', 'data_path': 'anli_r2.json'},
|
| 66 |
+
'anli_r3': {'task_type': 'nli', 'data_path': 'anli_r3.json'},
|
| 67 |
+
|
| 68 |
+
### fact checking
|
| 69 |
+
'nli_fever': {'task_type': 'fact_checking', 'data_path': 'nli_fever.json'},
|
| 70 |
+
'vitaminc': {'task_type': 'fact_checking', 'data_path': 'vitaminc.json'},
|
| 71 |
+
|
| 72 |
+
### paraphrase
|
| 73 |
+
'paws': {'task_type': 'paraphrase', 'data_path': 'paws.json'},
|
| 74 |
+
'paws_qqp': {'task_type': 'paraphrase', 'data_path': 'paws_qqp.json'},
|
| 75 |
+
'paws_unlabeled': {'task_type': 'paraphrase', 'data_path': 'paws_unlabeled.json'},
|
| 76 |
+
'qqp': {'task_type': 'paraphrase', 'data_path': 'qqp.json'},
|
| 77 |
+
'wiki103': {'task_type': 'paraphrase', 'data_path': 'wiki103.json'},
|
| 78 |
+
|
| 79 |
+
### QA
|
| 80 |
+
'squad_v2': {'task_type': 'qa', 'data_path': 'squad_v2_new.json'},
|
| 81 |
+
'race': {'task_type': 'qa', 'data_path': 'race.json'},
|
| 82 |
+
'adversarial_qa': {'task_type': 'qa', 'data_path': 'adversarial_qa.json'},
|
| 83 |
+
'drop': {'task_type': 'qa', 'data_path': 'drop.json'},
|
| 84 |
+
'hotpot_qa_distractor': {'task_type': 'qa', 'data_path': 'hotpot_qa_distractor.json'},
|
| 85 |
+
'hotpot_qa_fullwiki': {'task_type': 'qa', 'data_path': 'hotpot_qa_fullwiki.json'},
|
| 86 |
+
'newsqa': {'task_type': 'qa', 'data_path': 'newsqa.json'},
|
| 87 |
+
'quoref': {'task_type': 'qa', 'data_path': 'quoref.json'},
|
| 88 |
+
'ropes': {'task_type': 'qa', 'data_path': 'ropes.json'},
|
| 89 |
+
'boolq': {'task_type': 'qa', 'data_path': 'boolq.json'},
|
| 90 |
+
'eraser_multi_rc': {'task_type': 'qa', 'data_path': 'eraser_multi_rc.json'},
|
| 91 |
+
'quail': {'task_type': 'qa', 'data_path': 'quail.json'},
|
| 92 |
+
'sciq': {'task_type': 'qa', 'data_path': 'sciq.json'},
|
| 93 |
+
'strategy_qa': {'task_type': 'qa', 'data_path': 'strategy_qa.json'},
|
| 94 |
+
|
| 95 |
+
### Coreference
|
| 96 |
+
'gap': {'task_type': 'coreference', 'data_path': 'gap.json'},
|
| 97 |
+
|
| 98 |
+
### Summarization
|
| 99 |
+
'wikihow': {'task_type': 'summarization', 'data_path': 'wikihow.json'},
|
| 100 |
+
|
| 101 |
+
### Information Retrieval
|
| 102 |
+
'msmarco': {'task_type': 'ir', 'data_path': 'msmarco.json'},
|
| 103 |
+
|
| 104 |
+
### STS
|
| 105 |
+
'stsb': {'task_type': 'sts', 'data_path': 'stsb.json'},
|
| 106 |
+
'sick': {'task_type': 'sts', 'data_path': 'sick.json'},
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
parser = ArgumentParser()
|
| 110 |
+
parser.add_argument('--seed', type=int, default=2022)
|
| 111 |
+
parser.add_argument('--batch-size', type=int, default=32)
|
| 112 |
+
parser.add_argument('--accumulate-grad-batch', type=int, default=1)
|
| 113 |
+
parser.add_argument('--num-epoch', type=int, default=3)
|
| 114 |
+
parser.add_argument('--num-workers', type=int, default=8)
|
| 115 |
+
parser.add_argument('--warm-up-proportion', type=float, default=0.06)
|
| 116 |
+
parser.add_argument('--adam-epsilon', type=float, default=1e-6)
|
| 117 |
+
parser.add_argument('--weight-decay', type=float, default=0.1)
|
| 118 |
+
parser.add_argument('--learning-rate', type=float, default=1e-5)
|
| 119 |
+
parser.add_argument('--val-check-interval', type=float, default=1. / 4)
|
| 120 |
+
parser.add_argument('--devices', nargs='+', type=int, required=True)
|
| 121 |
+
parser.add_argument('--model-name', type=str, default="roberta-large")
|
| 122 |
+
parser.add_argument('--ckpt-save-path', type=str, required=True)
|
| 123 |
+
parser.add_argument('--ckpt-comment', type=str, default="")
|
| 124 |
+
parser.add_argument('--trainin-datasets', nargs='+', type=str, default=list(ALL_TRAINING_DATASETS.keys()), choices=list(ALL_TRAINING_DATASETS.keys()))
|
| 125 |
+
parser.add_argument('--data-path', type=str, required=True)
|
| 126 |
+
parser.add_argument('--max-samples-per-dataset', type=int, default=500000)
|
| 127 |
+
parser.add_argument('--do-mlm', type=bool, default=False)
|
| 128 |
+
parser.add_argument('--use-pretrained-model', type=bool, default=True)
|
| 129 |
+
|
| 130 |
+
args = parser.parse_args()
|
| 131 |
+
|
| 132 |
+
seed_everything(args.seed)
|
| 133 |
+
|
| 134 |
+
datasets = {
|
| 135 |
+
name: {
|
| 136 |
+
**ALL_TRAINING_DATASETS[name],
|
| 137 |
+
"size": args.max_samples_per_dataset,
|
| 138 |
+
"data_path": os.path.join(args.data_path, ALL_TRAINING_DATASETS[name]['data_path'])
|
| 139 |
+
}
|
| 140 |
+
for name in args.trainin_datasets
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
train(datasets, args)
|
| 144 |
+
|