Spaces:
Running

Running
LinB203
commited on
Commit
•
5c98ca3
1
Parent(s):
c4ba24f
add project files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +132 -13
- a_cls/__pycache__/precision.cpython-38.pyc +0 -0
- a_cls/__pycache__/stats.cpython-38.pyc +0 -0
- a_cls/__pycache__/zero_shot.cpython-38.pyc +0 -0
- a_cls/__pycache__/zero_shot_classifier.cpython-38.pyc +0 -0
- a_cls/__pycache__/zero_shot_metadata.cpython-38.pyc +0 -0
- a_cls/__pycache__/zeroshot_cls.cpython-38.pyc +0 -0
- a_cls/class_labels_indices.csv +528 -0
- a_cls/dataloader.py +90 -0
- a_cls/datasets.py +93 -0
- a_cls/filter_eval_audio.py +21 -0
- a_cls/precision.py +12 -0
- a_cls/stats.py +57 -0
- a_cls/util.py +306 -0
- a_cls/zero_shot.py +234 -0
- a_cls/zero_shot_classifier.py +111 -0
- a_cls/zero_shot_metadata.py +183 -0
- a_cls/zeroshot_cls.py +46 -0
- app.py +327 -0
- assets/languagebind.jpg +0 -0
- assets/logo.png +0 -0
- assets/res1.jpg +0 -0
- assets/res2.jpg +0 -0
- d_cls/__pycache__/precision.cpython-38.pyc +0 -0
- d_cls/__pycache__/zero_shot.cpython-38.pyc +0 -0
- d_cls/__pycache__/zero_shot_classifier.cpython-38.pyc +0 -0
- d_cls/__pycache__/zero_shot_metadata.cpython-38.pyc +0 -0
- d_cls/__pycache__/zeroshot_cls.cpython-38.pyc +0 -0
- d_cls/cp_zero_shot_metadata.py +117 -0
- d_cls/datasets.py +20 -0
- d_cls/precision.py +12 -0
- d_cls/zero_shot.py +90 -0
- d_cls/zero_shot_classifier.py +111 -0
- d_cls/zero_shot_metadata.py +117 -0
- d_cls/zeroshot_cls.py +47 -0
- data/__pycache__/base_datasets.cpython-38.pyc +0 -0
- data/__pycache__/build_datasets.cpython-38.pyc +0 -0
- data/__pycache__/new_loadvat.cpython-38.pyc +0 -0
- data/__pycache__/process_audio.cpython-38.pyc +0 -0
- data/__pycache__/process_depth.cpython-38.pyc +0 -0
- data/__pycache__/process_image.cpython-38.pyc +0 -0
- data/__pycache__/process_text.cpython-38.pyc +0 -0
- data/__pycache__/process_thermal.cpython-38.pyc +0 -0
- data/__pycache__/process_video.cpython-38.pyc +0 -0
- data/base_datasets.py +159 -0
- data/bpe_simple_vocab_16e6.txt.gz +3 -0
- data/build_datasets.py +174 -0
- data/new_loadvat.py +498 -0
- data/process_audio.py +131 -0
- data/process_depth.py +55 -0
README.md
CHANGED
|
@@ -1,13 +1,132 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!---
|
| 2 |
+
Copyright 2023 The OFA-Sys Team.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
This source code is licensed under the Apache 2.0 license found in the LICENSE file in the root directory.
|
| 5 |
+
-->
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
<p align="center">
|
| 10 |
+
<img src="assets/logo.png" width="250" />
|
| 11 |
+
<p>
|
| 12 |
+
<h2 align="center"> LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment </h2>
|
| 13 |
+
|
| 14 |
+
<h5 align="center"> If you like our project, please give us a star ✨ on Github for latest update. </h2>
|
| 15 |
+
|
| 16 |
+
[//]: # (<p align="center">)
|
| 17 |
+
|
| 18 |
+
[//]: # ( 📖 <a href="https://arxiv.org/abs/2305.11172">Paper</a>  |  <a href="datasets.md">Datasets</a>)
|
| 19 |
+
|
| 20 |
+
[//]: # (</p>)
|
| 21 |
+
<br>
|
| 22 |
+
|
| 23 |
+
LanguageBind is a language-centric multimodal pretraining approach, taking the language as the bind across different modalities because the language modality is well-explored and contains rich semantics. As a result, **all modalities are mapped to a shared feature space**, implementing multimodal semantic alignment. While LanguageBind ensures that we can extend VL modalities to N modalities, we also need a high-quality dataset with alignment data pairs centered on language. We thus propose **VIDAL-10M with 10 Million data with Video, Infrared, Depth, Audio and their corresponding Language.** In our VIDAL-10M, all videos are from short video platforms with **complete semantics** rather than truncated segments from long videos, and all the video, depth, infrared, and audio modalities are aligned to their textual descriptions
|
| 24 |
+
|
| 25 |
+
We have **open-sourced the VIDAL-10M dataset**, which greatly expands the data beyond visual modalities. The following figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
|
| 26 |
+
|
| 27 |
+
<p align="center">
|
| 28 |
+
<img src="assets/languagebind.jpg" width=100%>
|
| 29 |
+
</p>
|
| 30 |
+
|
| 31 |
+
<br>
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# News
|
| 35 |
+
* **2023.10.02:** Released the code. Training & validating scripts and checkpoints.
|
| 36 |
+
<br></br>
|
| 37 |
+
# Online Demo
|
| 38 |
+
Coming soon...
|
| 39 |
+
|
| 40 |
+
# Models and Results
|
| 41 |
+
## Model Zoo
|
| 42 |
+
We list the parameters and pretrained checkpoints of LanguageBind below. Note that LanguageBind can be disassembled into different branches to handle different tasks.
|
| 43 |
+
The cache comes from OpenCLIP, which we downloaded from HuggingFace. Note that the original cache for pretrained weights is the Image-Language weights, just a few more HF profiles.
|
| 44 |
+
We additionally trained Video-Language with the LanguageBind method, which is stronger than on CLIP4Clip framework.
|
| 45 |
+
<table border="1" width="100%">
|
| 46 |
+
<tr align="center">
|
| 47 |
+
<th>Model</th><th>Ckpt</th><th>Params</th><th>Modality Hidden size</th><th>Modality Layers</th><th>Language Hidden size</th><th>Language Layers</th>
|
| 48 |
+
</tr>
|
| 49 |
+
<tr align="center">
|
| 50 |
+
<td>Video-Language</td><td>TODO</td><td>330M</td><td>1024</td><td>24</td><td>768</td><td>12</td>
|
| 51 |
+
</tr>
|
| 52 |
+
</tr>
|
| 53 |
+
<tr align="center">
|
| 54 |
+
<td>Audio-Language</td><td><a href="https://pan.baidu.com/s/1PFN8aGlnzsOkGjVk6Mzlfg?pwd=sisz">BaiDu</a></td><td>330M</td><td>1024</td><td>24</td><td>768</td><td>12</td>
|
| 55 |
+
</tr>
|
| 56 |
+
</tr>
|
| 57 |
+
<tr align="center">
|
| 58 |
+
<td>Depth-Language</td><td><a href="https://pan.baidu.com/s/1YWlaxqTRhpGvXqCyBbmhyg?pwd=olom">BaiDu</a></td><td>330M</td><td>1024</td><td>24</td><td>768</td><td>12</td>
|
| 59 |
+
</tr>
|
| 60 |
+
</tr>
|
| 61 |
+
<tr align="center">
|
| 62 |
+
<td>Thermal(Infrared)-Language</td><td><a href="https://pan.baidu.com/s/1luUyyKxhadKKc1nk1wizWg?pwd=raf5">BaiDu</a></td><td>330M</td><td>1024</td><td>24</td><td>768</td><td>12</td>
|
| 63 |
+
</tr>
|
| 64 |
+
</tr>
|
| 65 |
+
<tr align="center">
|
| 66 |
+
<td>Image-Language</td><td><a href="https://pan.baidu.com/s/1VBE4OjecMTeIzU08axfFHA?pwd=7j0m">BaiDu</a></td><td>330M</td><td>1024</td><td>24</td><td>768</td><td>12</td>
|
| 67 |
+
</tr>
|
| 68 |
+
</tr>
|
| 69 |
+
<tr align="center">
|
| 70 |
+
<td>Cache for pretrained weight</td><td><a href="https://pan.baidu.com/s/1Tytx5MDSo96rwUmQZVY1Ww?pwd=c7r0">BaiDu</a></td><td>330M</td><td>1024</td><td>24</td><td>768</td><td>12</td>
|
| 71 |
+
</tr>
|
| 72 |
+
|
| 73 |
+
</table>
|
| 74 |
+
<br>
|
| 75 |
+
|
| 76 |
+
## Results
|
| 77 |
+
Zero-shot Video-Text Retrieval Performance on MSR-VTT and MSVD datasets. We focus on reporting the parameters of the vision
|
| 78 |
+
encoder. Our experiments are based on 3 million video-text pairs of VIDAL-10M, and we train on the CLIP4Clip framework..
|
| 79 |
+
<p align="center">
|
| 80 |
+
<img src="assets/res1.jpg" width=100%>
|
| 81 |
+
</p>
|
| 82 |
+
Infrared-Language, Depth-Language, and Audio-Language zero-shot classification. We report the top-1 classification accuracy for all datasets.
|
| 83 |
+
<p align="center">
|
| 84 |
+
<img src="assets/res2.jpg" width=100%>
|
| 85 |
+
</p>
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
<br></br>
|
| 89 |
+
|
| 90 |
+
# Requirements and Installation
|
| 91 |
+
* Python >= 3.8
|
| 92 |
+
* Pytorch >= 1.13.0
|
| 93 |
+
* CUDA Version >= 10.2 (recommend 11.6)
|
| 94 |
+
* Install required packages:
|
| 95 |
+
```bash
|
| 96 |
+
git clone https://github.com/PKU-YuanGroup/LanguageBind
|
| 97 |
+
cd LanguageBind
|
| 98 |
+
pip install -r requirements.txt
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
<br></br>
|
| 102 |
+
|
| 103 |
+
# VIDAL-10M
|
| 104 |
+
Release the dataset after publication...
|
| 105 |
+
|
| 106 |
+
<br></br>
|
| 107 |
+
|
| 108 |
+
# Training & Inference
|
| 109 |
+
Release run scripts, details coming soon...
|
| 110 |
+
|
| 111 |
+
<br></br>
|
| 112 |
+
|
| 113 |
+
# Downstream datasets
|
| 114 |
+
Coming soon...
|
| 115 |
+
|
| 116 |
+
<br></br>
|
| 117 |
+
|
| 118 |
+
# Acknowledgement
|
| 119 |
+
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
|
| 120 |
+
|
| 121 |
+
<br></br>
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
# Citation
|
| 125 |
+
|
| 126 |
+
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
|
| 127 |
+
|
| 128 |
+
<br></br>
|
| 129 |
+
|
| 130 |
+
```BibTeX
|
| 131 |
+
|
| 132 |
+
```
|
a_cls/__pycache__/precision.cpython-38.pyc
ADDED
|
Binary file (582 Bytes). View file
|
|
|
a_cls/__pycache__/stats.cpython-38.pyc
ADDED
|
Binary file (1.45 kB). View file
|
|
|
a_cls/__pycache__/zero_shot.cpython-38.pyc
ADDED
|
Binary file (6.38 kB). View file
|
|
|
a_cls/__pycache__/zero_shot_classifier.cpython-38.pyc
ADDED
|
Binary file (4.25 kB). View file
|
|
|
a_cls/__pycache__/zero_shot_metadata.cpython-38.pyc
ADDED
|
Binary file (16.7 kB). View file
|
|
|
a_cls/__pycache__/zeroshot_cls.cpython-38.pyc
ADDED
|
Binary file (1.44 kB). View file
|
|
|
a_cls/class_labels_indices.csv
ADDED
|
@@ -0,0 +1,528 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
index,mid,display_name
|
| 2 |
+
0,/m/09x0r,"Speech"
|
| 3 |
+
1,/m/05zppz,"Male speech, man speaking"
|
| 4 |
+
2,/m/02zsn,"Female speech, woman speaking"
|
| 5 |
+
3,/m/0ytgt,"Child speech, kid speaking"
|
| 6 |
+
4,/m/01h8n0,"Conversation"
|
| 7 |
+
5,/m/02qldy,"Narration, monologue"
|
| 8 |
+
6,/m/0261r1,"Babbling"
|
| 9 |
+
7,/m/0brhx,"Speech synthesizer"
|
| 10 |
+
8,/m/07p6fty,"Shout"
|
| 11 |
+
9,/m/07q4ntr,"Bellow"
|
| 12 |
+
10,/m/07rwj3x,"Whoop"
|
| 13 |
+
11,/m/07sr1lc,"Yell"
|
| 14 |
+
12,/m/04gy_2,"Battle cry"
|
| 15 |
+
13,/t/dd00135,"Children shouting"
|
| 16 |
+
14,/m/03qc9zr,"Screaming"
|
| 17 |
+
15,/m/02rtxlg,"Whispering"
|
| 18 |
+
16,/m/01j3sz,"Laughter"
|
| 19 |
+
17,/t/dd00001,"Baby laughter"
|
| 20 |
+
18,/m/07r660_,"Giggle"
|
| 21 |
+
19,/m/07s04w4,"Snicker"
|
| 22 |
+
20,/m/07sq110,"Belly laugh"
|
| 23 |
+
21,/m/07rgt08,"Chuckle, chortle"
|
| 24 |
+
22,/m/0463cq4,"Crying, sobbing"
|
| 25 |
+
23,/t/dd00002,"Baby cry, infant cry"
|
| 26 |
+
24,/m/07qz6j3,"Whimper"
|
| 27 |
+
25,/m/07qw_06,"Wail, moan"
|
| 28 |
+
26,/m/07plz5l,"Sigh"
|
| 29 |
+
27,/m/015lz1,"Singing"
|
| 30 |
+
28,/m/0l14jd,"Choir"
|
| 31 |
+
29,/m/01swy6,"Yodeling"
|
| 32 |
+
30,/m/02bk07,"Chant"
|
| 33 |
+
31,/m/01c194,"Mantra"
|
| 34 |
+
32,/t/dd00003,"Male singing"
|
| 35 |
+
33,/t/dd00004,"Female singing"
|
| 36 |
+
34,/t/dd00005,"Child singing"
|
| 37 |
+
35,/t/dd00006,"Synthetic singing"
|
| 38 |
+
36,/m/06bxc,"Rapping"
|
| 39 |
+
37,/m/02fxyj,"Humming"
|
| 40 |
+
38,/m/07s2xch,"Groan"
|
| 41 |
+
39,/m/07r4k75,"Grunt"
|
| 42 |
+
40,/m/01w250,"Whistling"
|
| 43 |
+
41,/m/0lyf6,"Breathing"
|
| 44 |
+
42,/m/07mzm6,"Wheeze"
|
| 45 |
+
43,/m/01d3sd,"Snoring"
|
| 46 |
+
44,/m/07s0dtb,"Gasp"
|
| 47 |
+
45,/m/07pyy8b,"Pant"
|
| 48 |
+
46,/m/07q0yl5,"Snort"
|
| 49 |
+
47,/m/01b_21,"Cough"
|
| 50 |
+
48,/m/0dl9sf8,"Throat clearing"
|
| 51 |
+
49,/m/01hsr_,"Sneeze"
|
| 52 |
+
50,/m/07ppn3j,"Sniff"
|
| 53 |
+
51,/m/06h7j,"Run"
|
| 54 |
+
52,/m/07qv_x_,"Shuffle"
|
| 55 |
+
53,/m/07pbtc8,"Walk, footsteps"
|
| 56 |
+
54,/m/03cczk,"Chewing, mastication"
|
| 57 |
+
55,/m/07pdhp0,"Biting"
|
| 58 |
+
56,/m/0939n_,"Gargling"
|
| 59 |
+
57,/m/01g90h,"Stomach rumble"
|
| 60 |
+
58,/m/03q5_w,"Burping, eructation"
|
| 61 |
+
59,/m/02p3nc,"Hiccup"
|
| 62 |
+
60,/m/02_nn,"Fart"
|
| 63 |
+
61,/m/0k65p,"Hands"
|
| 64 |
+
62,/m/025_jnm,"Finger snapping"
|
| 65 |
+
63,/m/0l15bq,"Clapping"
|
| 66 |
+
64,/m/01jg02,"Heart sounds, heartbeat"
|
| 67 |
+
65,/m/01jg1z,"Heart murmur"
|
| 68 |
+
66,/m/053hz1,"Cheering"
|
| 69 |
+
67,/m/028ght,"Applause"
|
| 70 |
+
68,/m/07rkbfh,"Chatter"
|
| 71 |
+
69,/m/03qtwd,"Crowd"
|
| 72 |
+
70,/m/07qfr4h,"Hubbub, speech noise, speech babble"
|
| 73 |
+
71,/t/dd00013,"Children playing"
|
| 74 |
+
72,/m/0jbk,"Animal"
|
| 75 |
+
73,/m/068hy,"Domestic animals, pets"
|
| 76 |
+
74,/m/0bt9lr,"Dog"
|
| 77 |
+
75,/m/05tny_,"Bark"
|
| 78 |
+
76,/m/07r_k2n,"Yip"
|
| 79 |
+
77,/m/07qf0zm,"Howl"
|
| 80 |
+
78,/m/07rc7d9,"Bow-wow"
|
| 81 |
+
79,/m/0ghcn6,"Growling"
|
| 82 |
+
80,/t/dd00136,"Whimper (dog)"
|
| 83 |
+
81,/m/01yrx,"Cat"
|
| 84 |
+
82,/m/02yds9,"Purr"
|
| 85 |
+
83,/m/07qrkrw,"Meow"
|
| 86 |
+
84,/m/07rjwbb,"Hiss"
|
| 87 |
+
85,/m/07r81j2,"Caterwaul"
|
| 88 |
+
86,/m/0ch8v,"Livestock, farm animals, working animals"
|
| 89 |
+
87,/m/03k3r,"Horse"
|
| 90 |
+
88,/m/07rv9rh,"Clip-clop"
|
| 91 |
+
89,/m/07q5rw0,"Neigh, whinny"
|
| 92 |
+
90,/m/01xq0k1,"Cattle, bovinae"
|
| 93 |
+
91,/m/07rpkh9,"Moo"
|
| 94 |
+
92,/m/0239kh,"Cowbell"
|
| 95 |
+
93,/m/068zj,"Pig"
|
| 96 |
+
94,/t/dd00018,"Oink"
|
| 97 |
+
95,/m/03fwl,"Goat"
|
| 98 |
+
96,/m/07q0h5t,"Bleat"
|
| 99 |
+
97,/m/07bgp,"Sheep"
|
| 100 |
+
98,/m/025rv6n,"Fowl"
|
| 101 |
+
99,/m/09b5t,"Chicken, rooster"
|
| 102 |
+
100,/m/07st89h,"Cluck"
|
| 103 |
+
101,/m/07qn5dc,"Crowing, cock-a-doodle-doo"
|
| 104 |
+
102,/m/01rd7k,"Turkey"
|
| 105 |
+
103,/m/07svc2k,"Gobble"
|
| 106 |
+
104,/m/09ddx,"Duck"
|
| 107 |
+
105,/m/07qdb04,"Quack"
|
| 108 |
+
106,/m/0dbvp,"Goose"
|
| 109 |
+
107,/m/07qwf61,"Honk"
|
| 110 |
+
108,/m/01280g,"Wild animals"
|
| 111 |
+
109,/m/0cdnk,"Roaring cats (lions, tigers)"
|
| 112 |
+
110,/m/04cvmfc,"Roar"
|
| 113 |
+
111,/m/015p6,"Bird"
|
| 114 |
+
112,/m/020bb7,"Bird vocalization, bird call, bird song"
|
| 115 |
+
113,/m/07pggtn,"Chirp, tweet"
|
| 116 |
+
114,/m/07sx8x_,"Squawk"
|
| 117 |
+
115,/m/0h0rv,"Pigeon, dove"
|
| 118 |
+
116,/m/07r_25d,"Coo"
|
| 119 |
+
117,/m/04s8yn,"Crow"
|
| 120 |
+
118,/m/07r5c2p,"Caw"
|
| 121 |
+
119,/m/09d5_,"Owl"
|
| 122 |
+
120,/m/07r_80w,"Hoot"
|
| 123 |
+
121,/m/05_wcq,"Bird flight, flapping wings"
|
| 124 |
+
122,/m/01z5f,"Canidae, dogs, wolves"
|
| 125 |
+
123,/m/06hps,"Rodents, rats, mice"
|
| 126 |
+
124,/m/04rmv,"Mouse"
|
| 127 |
+
125,/m/07r4gkf,"Patter"
|
| 128 |
+
126,/m/03vt0,"Insect"
|
| 129 |
+
127,/m/09xqv,"Cricket"
|
| 130 |
+
128,/m/09f96,"Mosquito"
|
| 131 |
+
129,/m/0h2mp,"Fly, housefly"
|
| 132 |
+
130,/m/07pjwq1,"Buzz"
|
| 133 |
+
131,/m/01h3n,"Bee, wasp, etc."
|
| 134 |
+
132,/m/09ld4,"Frog"
|
| 135 |
+
133,/m/07st88b,"Croak"
|
| 136 |
+
134,/m/078jl,"Snake"
|
| 137 |
+
135,/m/07qn4z3,"Rattle"
|
| 138 |
+
136,/m/032n05,"Whale vocalization"
|
| 139 |
+
137,/m/04rlf,"Music"
|
| 140 |
+
138,/m/04szw,"Musical instrument"
|
| 141 |
+
139,/m/0fx80y,"Plucked string instrument"
|
| 142 |
+
140,/m/0342h,"Guitar"
|
| 143 |
+
141,/m/02sgy,"Electric guitar"
|
| 144 |
+
142,/m/018vs,"Bass guitar"
|
| 145 |
+
143,/m/042v_gx,"Acoustic guitar"
|
| 146 |
+
144,/m/06w87,"Steel guitar, slide guitar"
|
| 147 |
+
145,/m/01glhc,"Tapping (guitar technique)"
|
| 148 |
+
146,/m/07s0s5r,"Strum"
|
| 149 |
+
147,/m/018j2,"Banjo"
|
| 150 |
+
148,/m/0jtg0,"Sitar"
|
| 151 |
+
149,/m/04rzd,"Mandolin"
|
| 152 |
+
150,/m/01bns_,"Zither"
|
| 153 |
+
151,/m/07xzm,"Ukulele"
|
| 154 |
+
152,/m/05148p4,"Keyboard (musical)"
|
| 155 |
+
153,/m/05r5c,"Piano"
|
| 156 |
+
154,/m/01s0ps,"Electric piano"
|
| 157 |
+
155,/m/013y1f,"Organ"
|
| 158 |
+
156,/m/03xq_f,"Electronic organ"
|
| 159 |
+
157,/m/03gvt,"Hammond organ"
|
| 160 |
+
158,/m/0l14qv,"Synthesizer"
|
| 161 |
+
159,/m/01v1d8,"Sampler"
|
| 162 |
+
160,/m/03q5t,"Harpsichord"
|
| 163 |
+
161,/m/0l14md,"Percussion"
|
| 164 |
+
162,/m/02hnl,"Drum kit"
|
| 165 |
+
163,/m/0cfdd,"Drum machine"
|
| 166 |
+
164,/m/026t6,"Drum"
|
| 167 |
+
165,/m/06rvn,"Snare drum"
|
| 168 |
+
166,/m/03t3fj,"Rimshot"
|
| 169 |
+
167,/m/02k_mr,"Drum roll"
|
| 170 |
+
168,/m/0bm02,"Bass drum"
|
| 171 |
+
169,/m/011k_j,"Timpani"
|
| 172 |
+
170,/m/01p970,"Tabla"
|
| 173 |
+
171,/m/01qbl,"Cymbal"
|
| 174 |
+
172,/m/03qtq,"Hi-hat"
|
| 175 |
+
173,/m/01sm1g,"Wood block"
|
| 176 |
+
174,/m/07brj,"Tambourine"
|
| 177 |
+
175,/m/05r5wn,"Rattle (instrument)"
|
| 178 |
+
176,/m/0xzly,"Maraca"
|
| 179 |
+
177,/m/0mbct,"Gong"
|
| 180 |
+
178,/m/016622,"Tubular bells"
|
| 181 |
+
179,/m/0j45pbj,"Mallet percussion"
|
| 182 |
+
180,/m/0dwsp,"Marimba, xylophone"
|
| 183 |
+
181,/m/0dwtp,"Glockenspiel"
|
| 184 |
+
182,/m/0dwt5,"Vibraphone"
|
| 185 |
+
183,/m/0l156b,"Steelpan"
|
| 186 |
+
184,/m/05pd6,"Orchestra"
|
| 187 |
+
185,/m/01kcd,"Brass instrument"
|
| 188 |
+
186,/m/0319l,"French horn"
|
| 189 |
+
187,/m/07gql,"Trumpet"
|
| 190 |
+
188,/m/07c6l,"Trombone"
|
| 191 |
+
189,/m/0l14_3,"Bowed string instrument"
|
| 192 |
+
190,/m/02qmj0d,"String section"
|
| 193 |
+
191,/m/07y_7,"Violin, fiddle"
|
| 194 |
+
192,/m/0d8_n,"Pizzicato"
|
| 195 |
+
193,/m/01xqw,"Cello"
|
| 196 |
+
194,/m/02fsn,"Double bass"
|
| 197 |
+
195,/m/085jw,"Wind instrument, woodwind instrument"
|
| 198 |
+
196,/m/0l14j_,"Flute"
|
| 199 |
+
197,/m/06ncr,"Saxophone"
|
| 200 |
+
198,/m/01wy6,"Clarinet"
|
| 201 |
+
199,/m/03m5k,"Harp"
|
| 202 |
+
200,/m/0395lw,"Bell"
|
| 203 |
+
201,/m/03w41f,"Church bell"
|
| 204 |
+
202,/m/027m70_,"Jingle bell"
|
| 205 |
+
203,/m/0gy1t2s,"Bicycle bell"
|
| 206 |
+
204,/m/07n_g,"Tuning fork"
|
| 207 |
+
205,/m/0f8s22,"Chime"
|
| 208 |
+
206,/m/026fgl,"Wind chime"
|
| 209 |
+
207,/m/0150b9,"Change ringing (campanology)"
|
| 210 |
+
208,/m/03qjg,"Harmonica"
|
| 211 |
+
209,/m/0mkg,"Accordion"
|
| 212 |
+
210,/m/0192l,"Bagpipes"
|
| 213 |
+
211,/m/02bxd,"Didgeridoo"
|
| 214 |
+
212,/m/0l14l2,"Shofar"
|
| 215 |
+
213,/m/07kc_,"Theremin"
|
| 216 |
+
214,/m/0l14t7,"Singing bowl"
|
| 217 |
+
215,/m/01hgjl,"Scratching (performance technique)"
|
| 218 |
+
216,/m/064t9,"Pop music"
|
| 219 |
+
217,/m/0glt670,"Hip hop music"
|
| 220 |
+
218,/m/02cz_7,"Beatboxing"
|
| 221 |
+
219,/m/06by7,"Rock music"
|
| 222 |
+
220,/m/03lty,"Heavy metal"
|
| 223 |
+
221,/m/05r6t,"Punk rock"
|
| 224 |
+
222,/m/0dls3,"Grunge"
|
| 225 |
+
223,/m/0dl5d,"Progressive rock"
|
| 226 |
+
224,/m/07sbbz2,"Rock and roll"
|
| 227 |
+
225,/m/05w3f,"Psychedelic rock"
|
| 228 |
+
226,/m/06j6l,"Rhythm and blues"
|
| 229 |
+
227,/m/0gywn,"Soul music"
|
| 230 |
+
228,/m/06cqb,"Reggae"
|
| 231 |
+
229,/m/01lyv,"Country"
|
| 232 |
+
230,/m/015y_n,"Swing music"
|
| 233 |
+
231,/m/0gg8l,"Bluegrass"
|
| 234 |
+
232,/m/02x8m,"Funk"
|
| 235 |
+
233,/m/02w4v,"Folk music"
|
| 236 |
+
234,/m/06j64v,"Middle Eastern music"
|
| 237 |
+
235,/m/03_d0,"Jazz"
|
| 238 |
+
236,/m/026z9,"Disco"
|
| 239 |
+
237,/m/0ggq0m,"Classical music"
|
| 240 |
+
238,/m/05lls,"Opera"
|
| 241 |
+
239,/m/02lkt,"Electronic music"
|
| 242 |
+
240,/m/03mb9,"House music"
|
| 243 |
+
241,/m/07gxw,"Techno"
|
| 244 |
+
242,/m/07s72n,"Dubstep"
|
| 245 |
+
243,/m/0283d,"Drum and bass"
|
| 246 |
+
244,/m/0m0jc,"Electronica"
|
| 247 |
+
245,/m/08cyft,"Electronic dance music"
|
| 248 |
+
246,/m/0fd3y,"Ambient music"
|
| 249 |
+
247,/m/07lnk,"Trance music"
|
| 250 |
+
248,/m/0g293,"Music of Latin America"
|
| 251 |
+
249,/m/0ln16,"Salsa music"
|
| 252 |
+
250,/m/0326g,"Flamenco"
|
| 253 |
+
251,/m/0155w,"Blues"
|
| 254 |
+
252,/m/05fw6t,"Music for children"
|
| 255 |
+
253,/m/02v2lh,"New-age music"
|
| 256 |
+
254,/m/0y4f8,"Vocal music"
|
| 257 |
+
255,/m/0z9c,"A capella"
|
| 258 |
+
256,/m/0164x2,"Music of Africa"
|
| 259 |
+
257,/m/0145m,"Afrobeat"
|
| 260 |
+
258,/m/02mscn,"Christian music"
|
| 261 |
+
259,/m/016cjb,"Gospel music"
|
| 262 |
+
260,/m/028sqc,"Music of Asia"
|
| 263 |
+
261,/m/015vgc,"Carnatic music"
|
| 264 |
+
262,/m/0dq0md,"Music of Bollywood"
|
| 265 |
+
263,/m/06rqw,"Ska"
|
| 266 |
+
264,/m/02p0sh1,"Traditional music"
|
| 267 |
+
265,/m/05rwpb,"Independent music"
|
| 268 |
+
266,/m/074ft,"Song"
|
| 269 |
+
267,/m/025td0t,"Background music"
|
| 270 |
+
268,/m/02cjck,"Theme music"
|
| 271 |
+
269,/m/03r5q_,"Jingle (music)"
|
| 272 |
+
270,/m/0l14gg,"Soundtrack music"
|
| 273 |
+
271,/m/07pkxdp,"Lullaby"
|
| 274 |
+
272,/m/01z7dr,"Video game music"
|
| 275 |
+
273,/m/0140xf,"Christmas music"
|
| 276 |
+
274,/m/0ggx5q,"Dance music"
|
| 277 |
+
275,/m/04wptg,"Wedding music"
|
| 278 |
+
276,/t/dd00031,"Happy music"
|
| 279 |
+
277,/t/dd00032,"Funny music"
|
| 280 |
+
278,/t/dd00033,"Sad music"
|
| 281 |
+
279,/t/dd00034,"Tender music"
|
| 282 |
+
280,/t/dd00035,"Exciting music"
|
| 283 |
+
281,/t/dd00036,"Angry music"
|
| 284 |
+
282,/t/dd00037,"Scary music"
|
| 285 |
+
283,/m/03m9d0z,"Wind"
|
| 286 |
+
284,/m/09t49,"Rustling leaves"
|
| 287 |
+
285,/t/dd00092,"Wind noise (microphone)"
|
| 288 |
+
286,/m/0jb2l,"Thunderstorm"
|
| 289 |
+
287,/m/0ngt1,"Thunder"
|
| 290 |
+
288,/m/0838f,"Water"
|
| 291 |
+
289,/m/06mb1,"Rain"
|
| 292 |
+
290,/m/07r10fb,"Raindrop"
|
| 293 |
+
291,/t/dd00038,"Rain on surface"
|
| 294 |
+
292,/m/0j6m2,"Stream"
|
| 295 |
+
293,/m/0j2kx,"Waterfall"
|
| 296 |
+
294,/m/05kq4,"Ocean"
|
| 297 |
+
295,/m/034srq,"Waves, surf"
|
| 298 |
+
296,/m/06wzb,"Steam"
|
| 299 |
+
297,/m/07swgks,"Gurgling"
|
| 300 |
+
298,/m/02_41,"Fire"
|
| 301 |
+
299,/m/07pzfmf,"Crackle"
|
| 302 |
+
300,/m/07yv9,"Vehicle"
|
| 303 |
+
301,/m/019jd,"Boat, Water vehicle"
|
| 304 |
+
302,/m/0hsrw,"Sailboat, sailing ship"
|
| 305 |
+
303,/m/056ks2,"Rowboat, canoe, kayak"
|
| 306 |
+
304,/m/02rlv9,"Motorboat, speedboat"
|
| 307 |
+
305,/m/06q74,"Ship"
|
| 308 |
+
306,/m/012f08,"Motor vehicle (road)"
|
| 309 |
+
307,/m/0k4j,"Car"
|
| 310 |
+
308,/m/0912c9,"Vehicle horn, car horn, honking"
|
| 311 |
+
309,/m/07qv_d5,"Toot"
|
| 312 |
+
310,/m/02mfyn,"Car alarm"
|
| 313 |
+
311,/m/04gxbd,"Power windows, electric windows"
|
| 314 |
+
312,/m/07rknqz,"Skidding"
|
| 315 |
+
313,/m/0h9mv,"Tire squeal"
|
| 316 |
+
314,/t/dd00134,"Car passing by"
|
| 317 |
+
315,/m/0ltv,"Race car, auto racing"
|
| 318 |
+
316,/m/07r04,"Truck"
|
| 319 |
+
317,/m/0gvgw0,"Air brake"
|
| 320 |
+
318,/m/05x_td,"Air horn, truck horn"
|
| 321 |
+
319,/m/02rhddq,"Reversing beeps"
|
| 322 |
+
320,/m/03cl9h,"Ice cream truck, ice cream van"
|
| 323 |
+
321,/m/01bjv,"Bus"
|
| 324 |
+
322,/m/03j1ly,"Emergency vehicle"
|
| 325 |
+
323,/m/04qvtq,"Police car (siren)"
|
| 326 |
+
324,/m/012n7d,"Ambulance (siren)"
|
| 327 |
+
325,/m/012ndj,"Fire engine, fire truck (siren)"
|
| 328 |
+
326,/m/04_sv,"Motorcycle"
|
| 329 |
+
327,/m/0btp2,"Traffic noise, roadway noise"
|
| 330 |
+
328,/m/06d_3,"Rail transport"
|
| 331 |
+
329,/m/07jdr,"Train"
|
| 332 |
+
330,/m/04zmvq,"Train whistle"
|
| 333 |
+
331,/m/0284vy3,"Train horn"
|
| 334 |
+
332,/m/01g50p,"Railroad car, train wagon"
|
| 335 |
+
333,/t/dd00048,"Train wheels squealing"
|
| 336 |
+
334,/m/0195fx,"Subway, metro, underground"
|
| 337 |
+
335,/m/0k5j,"Aircraft"
|
| 338 |
+
336,/m/014yck,"Aircraft engine"
|
| 339 |
+
337,/m/04229,"Jet engine"
|
| 340 |
+
338,/m/02l6bg,"Propeller, airscrew"
|
| 341 |
+
339,/m/09ct_,"Helicopter"
|
| 342 |
+
340,/m/0cmf2,"Fixed-wing aircraft, airplane"
|
| 343 |
+
341,/m/0199g,"Bicycle"
|
| 344 |
+
342,/m/06_fw,"Skateboard"
|
| 345 |
+
343,/m/02mk9,"Engine"
|
| 346 |
+
344,/t/dd00065,"Light engine (high frequency)"
|
| 347 |
+
345,/m/08j51y,"Dental drill, dentist's drill"
|
| 348 |
+
346,/m/01yg9g,"Lawn mower"
|
| 349 |
+
347,/m/01j4z9,"Chainsaw"
|
| 350 |
+
348,/t/dd00066,"Medium engine (mid frequency)"
|
| 351 |
+
349,/t/dd00067,"Heavy engine (low frequency)"
|
| 352 |
+
350,/m/01h82_,"Engine knocking"
|
| 353 |
+
351,/t/dd00130,"Engine starting"
|
| 354 |
+
352,/m/07pb8fc,"Idling"
|
| 355 |
+
353,/m/07q2z82,"Accelerating, revving, vroom"
|
| 356 |
+
354,/m/02dgv,"Door"
|
| 357 |
+
355,/m/03wwcy,"Doorbell"
|
| 358 |
+
356,/m/07r67yg,"Ding-dong"
|
| 359 |
+
357,/m/02y_763,"Sliding door"
|
| 360 |
+
358,/m/07rjzl8,"Slam"
|
| 361 |
+
359,/m/07r4wb8,"Knock"
|
| 362 |
+
360,/m/07qcpgn,"Tap"
|
| 363 |
+
361,/m/07q6cd_,"Squeak"
|
| 364 |
+
362,/m/0642b4,"Cupboard open or close"
|
| 365 |
+
363,/m/0fqfqc,"Drawer open or close"
|
| 366 |
+
364,/m/04brg2,"Dishes, pots, and pans"
|
| 367 |
+
365,/m/023pjk,"Cutlery, silverware"
|
| 368 |
+
366,/m/07pn_8q,"Chopping (food)"
|
| 369 |
+
367,/m/0dxrf,"Frying (food)"
|
| 370 |
+
368,/m/0fx9l,"Microwave oven"
|
| 371 |
+
369,/m/02pjr4,"Blender"
|
| 372 |
+
370,/m/02jz0l,"Water tap, faucet"
|
| 373 |
+
371,/m/0130jx,"Sink (filling or washing)"
|
| 374 |
+
372,/m/03dnzn,"Bathtub (filling or washing)"
|
| 375 |
+
373,/m/03wvsk,"Hair dryer"
|
| 376 |
+
374,/m/01jt3m,"Toilet flush"
|
| 377 |
+
375,/m/012xff,"Toothbrush"
|
| 378 |
+
376,/m/04fgwm,"Electric toothbrush"
|
| 379 |
+
377,/m/0d31p,"Vacuum cleaner"
|
| 380 |
+
378,/m/01s0vc,"Zipper (clothing)"
|
| 381 |
+
379,/m/03v3yw,"Keys jangling"
|
| 382 |
+
380,/m/0242l,"Coin (dropping)"
|
| 383 |
+
381,/m/01lsmm,"Scissors"
|
| 384 |
+
382,/m/02g901,"Electric shaver, electric razor"
|
| 385 |
+
383,/m/05rj2,"Shuffling cards"
|
| 386 |
+
384,/m/0316dw,"Typing"
|
| 387 |
+
385,/m/0c2wf,"Typewriter"
|
| 388 |
+
386,/m/01m2v,"Computer keyboard"
|
| 389 |
+
387,/m/081rb,"Writing"
|
| 390 |
+
388,/m/07pp_mv,"Alarm"
|
| 391 |
+
389,/m/07cx4,"Telephone"
|
| 392 |
+
390,/m/07pp8cl,"Telephone bell ringing"
|
| 393 |
+
391,/m/01hnzm,"Ringtone"
|
| 394 |
+
392,/m/02c8p,"Telephone dialing, DTMF"
|
| 395 |
+
393,/m/015jpf,"Dial tone"
|
| 396 |
+
394,/m/01z47d,"Busy signal"
|
| 397 |
+
395,/m/046dlr,"Alarm clock"
|
| 398 |
+
396,/m/03kmc9,"Siren"
|
| 399 |
+
397,/m/0dgbq,"Civil defense siren"
|
| 400 |
+
398,/m/030rvx,"Buzzer"
|
| 401 |
+
399,/m/01y3hg,"Smoke detector, smoke alarm"
|
| 402 |
+
400,/m/0c3f7m,"Fire alarm"
|
| 403 |
+
401,/m/04fq5q,"Foghorn"
|
| 404 |
+
402,/m/0l156k,"Whistle"
|
| 405 |
+
403,/m/06hck5,"Steam whistle"
|
| 406 |
+
404,/t/dd00077,"Mechanisms"
|
| 407 |
+
405,/m/02bm9n,"Ratchet, pawl"
|
| 408 |
+
406,/m/01x3z,"Clock"
|
| 409 |
+
407,/m/07qjznt,"Tick"
|
| 410 |
+
408,/m/07qjznl,"Tick-tock"
|
| 411 |
+
409,/m/0l7xg,"Gears"
|
| 412 |
+
410,/m/05zc1,"Pulleys"
|
| 413 |
+
411,/m/0llzx,"Sewing machine"
|
| 414 |
+
412,/m/02x984l,"Mechanical fan"
|
| 415 |
+
413,/m/025wky1,"Air conditioning"
|
| 416 |
+
414,/m/024dl,"Cash register"
|
| 417 |
+
415,/m/01m4t,"Printer"
|
| 418 |
+
416,/m/0dv5r,"Camera"
|
| 419 |
+
417,/m/07bjf,"Single-lens reflex camera"
|
| 420 |
+
418,/m/07k1x,"Tools"
|
| 421 |
+
419,/m/03l9g,"Hammer"
|
| 422 |
+
420,/m/03p19w,"Jackhammer"
|
| 423 |
+
421,/m/01b82r,"Sawing"
|
| 424 |
+
422,/m/02p01q,"Filing (rasp)"
|
| 425 |
+
423,/m/023vsd,"Sanding"
|
| 426 |
+
424,/m/0_ksk,"Power tool"
|
| 427 |
+
425,/m/01d380,"Drill"
|
| 428 |
+
426,/m/014zdl,"Explosion"
|
| 429 |
+
427,/m/032s66,"Gunshot, gunfire"
|
| 430 |
+
428,/m/04zjc,"Machine gun"
|
| 431 |
+
429,/m/02z32qm,"Fusillade"
|
| 432 |
+
430,/m/0_1c,"Artillery fire"
|
| 433 |
+
431,/m/073cg4,"Cap gun"
|
| 434 |
+
432,/m/0g6b5,"Fireworks"
|
| 435 |
+
433,/g/122z_qxw,"Firecracker"
|
| 436 |
+
434,/m/07qsvvw,"Burst, pop"
|
| 437 |
+
435,/m/07pxg6y,"Eruption"
|
| 438 |
+
436,/m/07qqyl4,"Boom"
|
| 439 |
+
437,/m/083vt,"Wood"
|
| 440 |
+
438,/m/07pczhz,"Chop"
|
| 441 |
+
439,/m/07pl1bw,"Splinter"
|
| 442 |
+
440,/m/07qs1cx,"Crack"
|
| 443 |
+
441,/m/039jq,"Glass"
|
| 444 |
+
442,/m/07q7njn,"Chink, clink"
|
| 445 |
+
443,/m/07rn7sz,"Shatter"
|
| 446 |
+
444,/m/04k94,"Liquid"
|
| 447 |
+
445,/m/07rrlb6,"Splash, splatter"
|
| 448 |
+
446,/m/07p6mqd,"Slosh"
|
| 449 |
+
447,/m/07qlwh6,"Squish"
|
| 450 |
+
448,/m/07r5v4s,"Drip"
|
| 451 |
+
449,/m/07prgkl,"Pour"
|
| 452 |
+
450,/m/07pqc89,"Trickle, dribble"
|
| 453 |
+
451,/t/dd00088,"Gush"
|
| 454 |
+
452,/m/07p7b8y,"Fill (with liquid)"
|
| 455 |
+
453,/m/07qlf79,"Spray"
|
| 456 |
+
454,/m/07ptzwd,"Pump (liquid)"
|
| 457 |
+
455,/m/07ptfmf,"Stir"
|
| 458 |
+
456,/m/0dv3j,"Boiling"
|
| 459 |
+
457,/m/0790c,"Sonar"
|
| 460 |
+
458,/m/0dl83,"Arrow"
|
| 461 |
+
459,/m/07rqsjt,"Whoosh, swoosh, swish"
|
| 462 |
+
460,/m/07qnq_y,"Thump, thud"
|
| 463 |
+
461,/m/07rrh0c,"Thunk"
|
| 464 |
+
462,/m/0b_fwt,"Electronic tuner"
|
| 465 |
+
463,/m/02rr_,"Effects unit"
|
| 466 |
+
464,/m/07m2kt,"Chorus effect"
|
| 467 |
+
465,/m/018w8,"Basketball bounce"
|
| 468 |
+
466,/m/07pws3f,"Bang"
|
| 469 |
+
467,/m/07ryjzk,"Slap, smack"
|
| 470 |
+
468,/m/07rdhzs,"Whack, thwack"
|
| 471 |
+
469,/m/07pjjrj,"Smash, crash"
|
| 472 |
+
470,/m/07pc8lb,"Breaking"
|
| 473 |
+
471,/m/07pqn27,"Bouncing"
|
| 474 |
+
472,/m/07rbp7_,"Whip"
|
| 475 |
+
473,/m/07pyf11,"Flap"
|
| 476 |
+
474,/m/07qb_dv,"Scratch"
|
| 477 |
+
475,/m/07qv4k0,"Scrape"
|
| 478 |
+
476,/m/07pdjhy,"Rub"
|
| 479 |
+
477,/m/07s8j8t,"Roll"
|
| 480 |
+
478,/m/07plct2,"Crushing"
|
| 481 |
+
479,/t/dd00112,"Crumpling, crinkling"
|
| 482 |
+
480,/m/07qcx4z,"Tearing"
|
| 483 |
+
481,/m/02fs_r,"Beep, bleep"
|
| 484 |
+
482,/m/07qwdck,"Ping"
|
| 485 |
+
483,/m/07phxs1,"Ding"
|
| 486 |
+
484,/m/07rv4dm,"Clang"
|
| 487 |
+
485,/m/07s02z0,"Squeal"
|
| 488 |
+
486,/m/07qh7jl,"Creak"
|
| 489 |
+
487,/m/07qwyj0,"Rustle"
|
| 490 |
+
488,/m/07s34ls,"Whir"
|
| 491 |
+
489,/m/07qmpdm,"Clatter"
|
| 492 |
+
490,/m/07p9k1k,"Sizzle"
|
| 493 |
+
491,/m/07qc9xj,"Clicking"
|
| 494 |
+
492,/m/07rwm0c,"Clickety-clack"
|
| 495 |
+
493,/m/07phhsh,"Rumble"
|
| 496 |
+
494,/m/07qyrcz,"Plop"
|
| 497 |
+
495,/m/07qfgpx,"Jingle, tinkle"
|
| 498 |
+
496,/m/07rcgpl,"Hum"
|
| 499 |
+
497,/m/07p78v5,"Zing"
|
| 500 |
+
498,/t/dd00121,"Boing"
|
| 501 |
+
499,/m/07s12q4,"Crunch"
|
| 502 |
+
500,/m/028v0c,"Silence"
|
| 503 |
+
501,/m/01v_m0,"Sine wave"
|
| 504 |
+
502,/m/0b9m1,"Harmonic"
|
| 505 |
+
503,/m/0hdsk,"Chirp tone"
|
| 506 |
+
504,/m/0c1dj,"Sound effect"
|
| 507 |
+
505,/m/07pt_g0,"Pulse"
|
| 508 |
+
506,/t/dd00125,"Inside, small room"
|
| 509 |
+
507,/t/dd00126,"Inside, large room or hall"
|
| 510 |
+
508,/t/dd00127,"Inside, public space"
|
| 511 |
+
509,/t/dd00128,"Outside, urban or manmade"
|
| 512 |
+
510,/t/dd00129,"Outside, rural or natural"
|
| 513 |
+
511,/m/01b9nn,"Reverberation"
|
| 514 |
+
512,/m/01jnbd,"Echo"
|
| 515 |
+
513,/m/096m7z,"Noise"
|
| 516 |
+
514,/m/06_y0by,"Environmental noise"
|
| 517 |
+
515,/m/07rgkc5,"Static"
|
| 518 |
+
516,/m/06xkwv,"Mains hum"
|
| 519 |
+
517,/m/0g12c5,"Distortion"
|
| 520 |
+
518,/m/08p9q4,"Sidetone"
|
| 521 |
+
519,/m/07szfh9,"Cacophony"
|
| 522 |
+
520,/m/0chx_,"White noise"
|
| 523 |
+
521,/m/0cj0r,"Pink noise"
|
| 524 |
+
522,/m/07p_0gm,"Throbbing"
|
| 525 |
+
523,/m/01jwx6,"Vibration"
|
| 526 |
+
524,/m/07c52,"Television"
|
| 527 |
+
525,/m/06bz3,"Radio"
|
| 528 |
+
526,/m/07hvw1,"Field recording"
|
a_cls/dataloader.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
# @Time : 6/19/21 12:23 AM
|
| 3 |
+
# @Author : Yuan Gong
|
| 4 |
+
# @Affiliation : Massachusetts Institute of Technology
|
| 5 |
+
# @Email : yuangong@mit.edu
|
| 6 |
+
# @File : dataloader.py
|
| 7 |
+
|
| 8 |
+
# modified from:
|
| 9 |
+
# Author: David Harwath
|
| 10 |
+
# with some functions borrowed from https://github.com/SeanNaren/deepspeech.pytorch
|
| 11 |
+
|
| 12 |
+
import csv
|
| 13 |
+
import json
|
| 14 |
+
import logging
|
| 15 |
+
|
| 16 |
+
import torchaudio
|
| 17 |
+
import numpy as np
|
| 18 |
+
import torch
|
| 19 |
+
import torch.nn.functional
|
| 20 |
+
from torch.utils.data import Dataset
|
| 21 |
+
import random
|
| 22 |
+
|
| 23 |
+
def make_index_dict(label_csv):
|
| 24 |
+
index_lookup = {}
|
| 25 |
+
with open(label_csv, 'r') as f:
|
| 26 |
+
csv_reader = csv.DictReader(f)
|
| 27 |
+
line_count = 0
|
| 28 |
+
for row in csv_reader:
|
| 29 |
+
index_lookup[row['mid']] = row['index']
|
| 30 |
+
line_count += 1
|
| 31 |
+
return index_lookup
|
| 32 |
+
|
| 33 |
+
def make_name_dict(label_csv):
|
| 34 |
+
name_lookup = {}
|
| 35 |
+
with open(label_csv, 'r') as f:
|
| 36 |
+
csv_reader = csv.DictReader(f)
|
| 37 |
+
line_count = 0
|
| 38 |
+
for row in csv_reader:
|
| 39 |
+
name_lookup[row['index']] = row['display_name']
|
| 40 |
+
line_count += 1
|
| 41 |
+
return name_lookup
|
| 42 |
+
|
| 43 |
+
def lookup_list(index_list, label_csv):
|
| 44 |
+
label_list = []
|
| 45 |
+
table = make_name_dict(label_csv)
|
| 46 |
+
for item in index_list:
|
| 47 |
+
label_list.append(table[item])
|
| 48 |
+
return label_list
|
| 49 |
+
|
| 50 |
+
def preemphasis(signal,coeff=0.97):
|
| 51 |
+
"""perform preemphasis on the input signal.
|
| 52 |
+
|
| 53 |
+
:param signal: The signal to filter.
|
| 54 |
+
:param coeff: The preemphasis coefficient. 0 is none, default 0.97.
|
| 55 |
+
:returns: the filtered signal.
|
| 56 |
+
"""
|
| 57 |
+
return np.append(signal[0],signal[1:]-coeff*signal[:-1])
|
| 58 |
+
|
| 59 |
+
class AudiosetDataset(Dataset):
|
| 60 |
+
def __init__(self, dataset_json_file, audio_conf, label_csv=None):
|
| 61 |
+
"""
|
| 62 |
+
Dataset that manages audio recordings
|
| 63 |
+
:param audio_conf: Dictionary containing the audio loading and preprocessing settings
|
| 64 |
+
:param dataset_json_file
|
| 65 |
+
"""
|
| 66 |
+
self.datapath = dataset_json_file
|
| 67 |
+
with open(dataset_json_file, 'r') as fp:
|
| 68 |
+
data_json = json.load(fp)
|
| 69 |
+
self.data = data_json['data']
|
| 70 |
+
self.index_dict = make_index_dict(label_csv)
|
| 71 |
+
self.label_num = len(self.index_dict)
|
| 72 |
+
|
| 73 |
+
def __getitem__(self, index):
|
| 74 |
+
datum = self.data[index]
|
| 75 |
+
label_indices = np.zeros(self.label_num)
|
| 76 |
+
try:
|
| 77 |
+
fbank, mix_lambda = self._wav2fbank(datum['wav'])
|
| 78 |
+
except Exception as e:
|
| 79 |
+
logging.warning(f"Error at {datum['wav']} with \"{e}\"")
|
| 80 |
+
return self.__getitem__(random.randint(0, self.__len__()-1))
|
| 81 |
+
for label_str in datum['labels'].split(','):
|
| 82 |
+
label_indices[int(self.index_dict[label_str])] = 1.0
|
| 83 |
+
|
| 84 |
+
label_indices = torch.FloatTensor(label_indices)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
return fbank, label_indices
|
| 88 |
+
|
| 89 |
+
def __len__(self):
|
| 90 |
+
return len(self.data)
|
a_cls/datasets.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os.path
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
from data.build_datasets import DataInfo
|
| 6 |
+
from data.process_audio import get_audio_transform, torchaudio_loader
|
| 7 |
+
from torchvision import datasets
|
| 8 |
+
|
| 9 |
+
# -*- coding: utf-8 -*-
|
| 10 |
+
# @Time : 6/19/21 12:23 AM
|
| 11 |
+
# @Author : Yuan Gong
|
| 12 |
+
# @Affiliation : Massachusetts Institute of Technology
|
| 13 |
+
# @Email : yuangong@mit.edu
|
| 14 |
+
# @File : dataloader.py
|
| 15 |
+
|
| 16 |
+
# modified from:
|
| 17 |
+
# Author: David Harwath
|
| 18 |
+
# with some functions borrowed from https://github.com/SeanNaren/deepspeech.pytorch
|
| 19 |
+
|
| 20 |
+
import csv
|
| 21 |
+
import json
|
| 22 |
+
import logging
|
| 23 |
+
|
| 24 |
+
import torchaudio
|
| 25 |
+
import numpy as np
|
| 26 |
+
import torch
|
| 27 |
+
import torch.nn.functional
|
| 28 |
+
from torch.utils.data import Dataset
|
| 29 |
+
import random
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def make_index_dict(label_csv):
|
| 33 |
+
index_lookup = {}
|
| 34 |
+
with open(label_csv, 'r') as f:
|
| 35 |
+
csv_reader = csv.DictReader(f)
|
| 36 |
+
line_count = 0
|
| 37 |
+
for row in csv_reader:
|
| 38 |
+
index_lookup[row['mid']] = row['index']
|
| 39 |
+
line_count += 1
|
| 40 |
+
return index_lookup
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class AudiosetDataset(Dataset):
|
| 44 |
+
def __init__(self, args, transform, loader):
|
| 45 |
+
self.audio_root = '/apdcephfs_cq3/share_1311970/downstream_datasets/Audio/audioset/eval_segments'
|
| 46 |
+
dataset_json_file = '/apdcephfs_cq3/share_1311970/downstream_datasets/Audio/audioset/filter_eval.json'
|
| 47 |
+
label_csv = '/apdcephfs_cq3/share_1311970/downstream_datasets/Audio/audioset/class_labels_indices.csv'
|
| 48 |
+
with open(dataset_json_file, 'r') as fp:
|
| 49 |
+
data_json = json.load(fp)
|
| 50 |
+
self.data = data_json['data']
|
| 51 |
+
self.index_dict = make_index_dict(label_csv)
|
| 52 |
+
self.label_num = len(self.index_dict)
|
| 53 |
+
|
| 54 |
+
self.args = args
|
| 55 |
+
self.transform = transform
|
| 56 |
+
self.loader = loader
|
| 57 |
+
|
| 58 |
+
def __getitem__(self, index):
|
| 59 |
+
datum = self.data[index]
|
| 60 |
+
label_indices = np.zeros(self.label_num)
|
| 61 |
+
for label_str in datum['labels'].split(','):
|
| 62 |
+
label_indices[int(self.index_dict[label_str])] = 1.0
|
| 63 |
+
label_indices = torch.FloatTensor(label_indices)
|
| 64 |
+
|
| 65 |
+
audio = self.loader(os.path.join(self.audio_root, datum['wav']))
|
| 66 |
+
audio_data = self.transform(audio)
|
| 67 |
+
return audio_data, label_indices
|
| 68 |
+
|
| 69 |
+
def __len__(self):
|
| 70 |
+
return len(self.data)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def is_valid_file(path):
|
| 75 |
+
return True
|
| 76 |
+
|
| 77 |
+
def get_audio_dataset(args):
|
| 78 |
+
data_path = args.audio_data_path
|
| 79 |
+
transform = get_audio_transform(args)
|
| 80 |
+
|
| 81 |
+
if args.val_a_cls_data.lower() == 'audioset':
|
| 82 |
+
dataset = AudiosetDataset(args, transform=transform, loader=torchaudio_loader)
|
| 83 |
+
else:
|
| 84 |
+
dataset = datasets.ImageFolder(data_path, transform=transform, loader=torchaudio_loader, is_valid_file=is_valid_file)
|
| 85 |
+
|
| 86 |
+
dataloader = torch.utils.data.DataLoader(
|
| 87 |
+
dataset,
|
| 88 |
+
batch_size=args.batch_size,
|
| 89 |
+
num_workers=args.workers,
|
| 90 |
+
sampler=None,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
return DataInfo(dataloader=dataloader, sampler=None)
|
a_cls/filter_eval_audio.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os.path
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
|
| 5 |
+
with open(r"G:\audioset\audioset\zip_audios\16k\eval.json", 'r') as f:
|
| 6 |
+
data = json.load(f)['data']
|
| 7 |
+
|
| 8 |
+
new_data = []
|
| 9 |
+
total = 0
|
| 10 |
+
success = 0
|
| 11 |
+
for i in tqdm(data):
|
| 12 |
+
total += 1
|
| 13 |
+
video_id = os.path.basename(i['wav'])
|
| 14 |
+
new_video_id = 'Y' + video_id
|
| 15 |
+
i['wav'] = new_video_id
|
| 16 |
+
if os.path.exists(f"G:/audioset/audioset/zip_audios/eval_segments/{i['wav']}") and not video_id.startswith('mW3S0u8bj58'):
|
| 17 |
+
new_data.append(i)
|
| 18 |
+
success += 1
|
| 19 |
+
print(total, success, total-success)
|
| 20 |
+
with open(r"G:\audioset\audioset\zip_audios\16k\filter_eval.json", 'w') as f:
|
| 21 |
+
data = json.dump({'data': new_data}, f, indent=2)
|
a_cls/precision.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from contextlib import suppress
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def get_autocast(precision):
|
| 6 |
+
if precision == 'amp':
|
| 7 |
+
return torch.cuda.amp.autocast
|
| 8 |
+
elif precision == 'amp_bfloat16' or precision == 'amp_bf16':
|
| 9 |
+
# amp_bfloat16 is more stable than amp float16 for clip training
|
| 10 |
+
return lambda: torch.cuda.amp.autocast(dtype=torch.bfloat16)
|
| 11 |
+
else:
|
| 12 |
+
return suppress
|
a_cls/stats.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from scipy import stats
|
| 3 |
+
from sklearn import metrics
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
def d_prime(auc):
|
| 7 |
+
standard_normal = stats.norm()
|
| 8 |
+
d_prime = standard_normal.ppf(auc) * np.sqrt(2.0)
|
| 9 |
+
return d_prime
|
| 10 |
+
|
| 11 |
+
def calculate_stats(output, target):
|
| 12 |
+
"""Calculate statistics including mAP, AUC, etc.
|
| 13 |
+
|
| 14 |
+
Args:
|
| 15 |
+
output: 2d array, (samples_num, classes_num)
|
| 16 |
+
target: 2d array, (samples_num, classes_num)
|
| 17 |
+
|
| 18 |
+
Returns:
|
| 19 |
+
stats: list of statistic of each class.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
classes_num = target.shape[-1]
|
| 23 |
+
stats = []
|
| 24 |
+
|
| 25 |
+
# Accuracy, only used for single-label classification such as esc-50, not for multiple label one such as AudioSet
|
| 26 |
+
acc = metrics.accuracy_score(np.argmax(target, 1), np.argmax(output, 1))
|
| 27 |
+
|
| 28 |
+
# Class-wise statistics
|
| 29 |
+
for k in range(classes_num):
|
| 30 |
+
|
| 31 |
+
# Average precision
|
| 32 |
+
avg_precision = metrics.average_precision_score(
|
| 33 |
+
target[:, k], output[:, k], average=None)
|
| 34 |
+
|
| 35 |
+
# AUC
|
| 36 |
+
auc = metrics.roc_auc_score(target[:, k], output[:, k], average=None)
|
| 37 |
+
|
| 38 |
+
# Precisions, recalls
|
| 39 |
+
(precisions, recalls, thresholds) = metrics.precision_recall_curve(
|
| 40 |
+
target[:, k], output[:, k])
|
| 41 |
+
|
| 42 |
+
# FPR, TPR
|
| 43 |
+
(fpr, tpr, thresholds) = metrics.roc_curve(target[:, k], output[:, k])
|
| 44 |
+
|
| 45 |
+
save_every_steps = 1000 # Sample statistics to reduce size
|
| 46 |
+
dict = {'precisions': precisions[0::save_every_steps],
|
| 47 |
+
'recalls': recalls[0::save_every_steps],
|
| 48 |
+
'AP': avg_precision,
|
| 49 |
+
'fpr': fpr[0::save_every_steps],
|
| 50 |
+
'fnr': 1. - tpr[0::save_every_steps],
|
| 51 |
+
'auc': auc,
|
| 52 |
+
# note acc is not class-wise, this is just to keep consistent with other metrics
|
| 53 |
+
'acc': acc
|
| 54 |
+
}
|
| 55 |
+
stats.append(dict)
|
| 56 |
+
|
| 57 |
+
return stats
|
a_cls/util.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import pickle
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import random
|
| 7 |
+
from collections import namedtuple
|
| 8 |
+
|
| 9 |
+
def calc_recalls(S):
|
| 10 |
+
"""
|
| 11 |
+
Computes recall at 1, 5, and 10 given a similarity matrix S.
|
| 12 |
+
By convention, rows of S are assumed to correspond to images and columns are captions.
|
| 13 |
+
"""
|
| 14 |
+
assert(S.dim() == 2)
|
| 15 |
+
assert(S.size(0) == S.size(1))
|
| 16 |
+
if isinstance(S, torch.autograd.Variable):
|
| 17 |
+
S = S.data
|
| 18 |
+
n = S.size(0)
|
| 19 |
+
A2I_scores, A2I_ind = S.topk(10, 0)
|
| 20 |
+
I2A_scores, I2A_ind = S.topk(10, 1)
|
| 21 |
+
A_r1 = AverageMeter()
|
| 22 |
+
A_r5 = AverageMeter()
|
| 23 |
+
A_r10 = AverageMeter()
|
| 24 |
+
I_r1 = AverageMeter()
|
| 25 |
+
I_r5 = AverageMeter()
|
| 26 |
+
I_r10 = AverageMeter()
|
| 27 |
+
for i in range(n):
|
| 28 |
+
A_foundind = -1
|
| 29 |
+
I_foundind = -1
|
| 30 |
+
for ind in range(10):
|
| 31 |
+
if A2I_ind[ind, i] == i:
|
| 32 |
+
I_foundind = ind
|
| 33 |
+
if I2A_ind[i, ind] == i:
|
| 34 |
+
A_foundind = ind
|
| 35 |
+
# do r1s
|
| 36 |
+
if A_foundind == 0:
|
| 37 |
+
A_r1.update(1)
|
| 38 |
+
else:
|
| 39 |
+
A_r1.update(0)
|
| 40 |
+
if I_foundind == 0:
|
| 41 |
+
I_r1.update(1)
|
| 42 |
+
else:
|
| 43 |
+
I_r1.update(0)
|
| 44 |
+
# do r5s
|
| 45 |
+
if A_foundind >= 0 and A_foundind < 5:
|
| 46 |
+
A_r5.update(1)
|
| 47 |
+
else:
|
| 48 |
+
A_r5.update(0)
|
| 49 |
+
if I_foundind >= 0 and I_foundind < 5:
|
| 50 |
+
I_r5.update(1)
|
| 51 |
+
else:
|
| 52 |
+
I_r5.update(0)
|
| 53 |
+
# do r10s
|
| 54 |
+
if A_foundind >= 0 and A_foundind < 10:
|
| 55 |
+
A_r10.update(1)
|
| 56 |
+
else:
|
| 57 |
+
A_r10.update(0)
|
| 58 |
+
if I_foundind >= 0 and I_foundind < 10:
|
| 59 |
+
I_r10.update(1)
|
| 60 |
+
else:
|
| 61 |
+
I_r10.update(0)
|
| 62 |
+
|
| 63 |
+
recalls = {'A_r1':A_r1.avg, 'A_r5':A_r5.avg, 'A_r10':A_r10.avg,
|
| 64 |
+
'I_r1':I_r1.avg, 'I_r5':I_r5.avg, 'I_r10':I_r10.avg}
|
| 65 |
+
#'A_meanR':A_meanR.avg, 'I_meanR':I_meanR.avg}
|
| 66 |
+
|
| 67 |
+
return recalls
|
| 68 |
+
|
| 69 |
+
def computeMatchmap(I, A):
|
| 70 |
+
assert(I.dim() == 3)
|
| 71 |
+
assert(A.dim() == 2)
|
| 72 |
+
D = I.size(0)
|
| 73 |
+
H = I.size(1)
|
| 74 |
+
W = I.size(2)
|
| 75 |
+
T = A.size(1)
|
| 76 |
+
Ir = I.view(D, -1).t()
|
| 77 |
+
matchmap = torch.mm(Ir, A)
|
| 78 |
+
matchmap = matchmap.view(H, W, T)
|
| 79 |
+
return matchmap
|
| 80 |
+
|
| 81 |
+
def matchmapSim(M, simtype):
|
| 82 |
+
assert(M.dim() == 3)
|
| 83 |
+
if simtype == 'SISA':
|
| 84 |
+
return M.mean()
|
| 85 |
+
elif simtype == 'MISA':
|
| 86 |
+
M_maxH, _ = M.max(0)
|
| 87 |
+
M_maxHW, _ = M_maxH.max(0)
|
| 88 |
+
return M_maxHW.mean()
|
| 89 |
+
elif simtype == 'SIMA':
|
| 90 |
+
M_maxT, _ = M.max(2)
|
| 91 |
+
return M_maxT.mean()
|
| 92 |
+
else:
|
| 93 |
+
raise ValueError
|
| 94 |
+
|
| 95 |
+
def sampled_margin_rank_loss(image_outputs, audio_outputs, nframes, margin=1., simtype='MISA'):
|
| 96 |
+
"""
|
| 97 |
+
Computes the triplet margin ranking loss for each anchor image/caption pair
|
| 98 |
+
The impostor image/caption is randomly sampled from the minibatch
|
| 99 |
+
"""
|
| 100 |
+
assert(image_outputs.dim() == 4)
|
| 101 |
+
assert(audio_outputs.dim() == 3)
|
| 102 |
+
n = image_outputs.size(0)
|
| 103 |
+
loss = torch.zeros(1, device=image_outputs.device, requires_grad=True)
|
| 104 |
+
for i in range(n):
|
| 105 |
+
I_imp_ind = i
|
| 106 |
+
A_imp_ind = i
|
| 107 |
+
while I_imp_ind == i:
|
| 108 |
+
I_imp_ind = np.random.randint(0, n)
|
| 109 |
+
while A_imp_ind == i:
|
| 110 |
+
A_imp_ind = np.random.randint(0, n)
|
| 111 |
+
nF = nframes[i]
|
| 112 |
+
nFimp = nframes[A_imp_ind]
|
| 113 |
+
anchorsim = matchmapSim(computeMatchmap(image_outputs[i], audio_outputs[i][:, 0:nF]), simtype)
|
| 114 |
+
Iimpsim = matchmapSim(computeMatchmap(image_outputs[I_imp_ind], audio_outputs[i][:, 0:nF]), simtype)
|
| 115 |
+
Aimpsim = matchmapSim(computeMatchmap(image_outputs[i], audio_outputs[A_imp_ind][:, 0:nFimp]), simtype)
|
| 116 |
+
A2I_simdif = margin + Iimpsim - anchorsim
|
| 117 |
+
if (A2I_simdif.data > 0).all():
|
| 118 |
+
loss = loss + A2I_simdif
|
| 119 |
+
I2A_simdif = margin + Aimpsim - anchorsim
|
| 120 |
+
if (I2A_simdif.data > 0).all():
|
| 121 |
+
loss = loss + I2A_simdif
|
| 122 |
+
loss = loss / n
|
| 123 |
+
return loss
|
| 124 |
+
|
| 125 |
+
def compute_matchmap_similarity_matrix(image_outputs, audio_outputs, nframes, simtype='MISA'):
|
| 126 |
+
"""
|
| 127 |
+
Assumes image_outputs is a (batchsize, embedding_dim, rows, height) tensor
|
| 128 |
+
Assumes audio_outputs is a (batchsize, embedding_dim, 1, time) tensor
|
| 129 |
+
Returns similarity matrix S where images are rows and audios are along the columns
|
| 130 |
+
"""
|
| 131 |
+
assert(image_outputs.dim() == 4)
|
| 132 |
+
assert(audio_outputs.dim() == 3)
|
| 133 |
+
n = image_outputs.size(0)
|
| 134 |
+
S = torch.zeros(n, n, device=image_outputs.device)
|
| 135 |
+
for image_idx in range(n):
|
| 136 |
+
for audio_idx in range(n):
|
| 137 |
+
nF = max(1, nframes[audio_idx])
|
| 138 |
+
S[image_idx, audio_idx] = matchmapSim(computeMatchmap(image_outputs[image_idx], audio_outputs[audio_idx][:, 0:nF]), simtype)
|
| 139 |
+
return S
|
| 140 |
+
|
| 141 |
+
def compute_pooldot_similarity_matrix(image_outputs, audio_outputs, nframes):
|
| 142 |
+
"""
|
| 143 |
+
Assumes image_outputs is a (batchsize, embedding_dim, rows, height) tensor
|
| 144 |
+
Assumes audio_outputs is a (batchsize, embedding_dim, 1, time) tensor
|
| 145 |
+
Returns similarity matrix S where images are rows and audios are along the columns
|
| 146 |
+
S[i][j] is computed as the dot product between the meanpooled embeddings of
|
| 147 |
+
the ith image output and jth audio output
|
| 148 |
+
"""
|
| 149 |
+
assert(image_outputs.dim() == 4)
|
| 150 |
+
assert(audio_outputs.dim() == 4)
|
| 151 |
+
n = image_outputs.size(0)
|
| 152 |
+
imagePoolfunc = nn.AdaptiveAvgPool2d((1, 1))
|
| 153 |
+
pooled_image_outputs = imagePoolfunc(image_outputs).squeeze(3).squeeze(2)
|
| 154 |
+
audioPoolfunc = nn.AdaptiveAvgPool2d((1, 1))
|
| 155 |
+
pooled_audio_outputs_list = []
|
| 156 |
+
for idx in range(n):
|
| 157 |
+
nF = max(1, nframes[idx])
|
| 158 |
+
pooled_audio_outputs_list.append(audioPoolfunc(audio_outputs[idx][:, :, 0:nF]).unsqueeze(0))
|
| 159 |
+
pooled_audio_outputs = torch.cat(pooled_audio_outputs_list).squeeze(3).squeeze(2)
|
| 160 |
+
S = torch.mm(pooled_image_outputs, pooled_audio_outputs.t())
|
| 161 |
+
return S
|
| 162 |
+
|
| 163 |
+
def one_imposter_index(i, N):
|
| 164 |
+
imp_ind = random.randint(0, N - 2)
|
| 165 |
+
if imp_ind == i:
|
| 166 |
+
imp_ind = N - 1
|
| 167 |
+
return imp_ind
|
| 168 |
+
|
| 169 |
+
def basic_get_imposter_indices(N):
|
| 170 |
+
imposter_idc = []
|
| 171 |
+
for i in range(N):
|
| 172 |
+
# Select an imposter index for example i:
|
| 173 |
+
imp_ind = one_imposter_index(i, N)
|
| 174 |
+
imposter_idc.append(imp_ind)
|
| 175 |
+
return imposter_idc
|
| 176 |
+
|
| 177 |
+
def semihardneg_triplet_loss_from_S(S, margin):
|
| 178 |
+
"""
|
| 179 |
+
Input: Similarity matrix S as an autograd.Variable
|
| 180 |
+
Output: The one-way triplet loss from rows of S to columns of S. Impostors are taken
|
| 181 |
+
to be the most similar point to the anchor that is still less similar to the anchor
|
| 182 |
+
than the positive example.
|
| 183 |
+
You would need to run this function twice, once with S and once with S.t(),
|
| 184 |
+
in order to compute the triplet loss in both directions.
|
| 185 |
+
"""
|
| 186 |
+
assert(S.dim() == 2)
|
| 187 |
+
assert(S.size(0) == S.size(1))
|
| 188 |
+
N = S.size(0)
|
| 189 |
+
loss = torch.autograd.Variable(torch.zeros(1).type(S.data.type()), requires_grad=True)
|
| 190 |
+
# Imposter - ground truth
|
| 191 |
+
Sdiff = S - torch.diag(S).view(-1, 1)
|
| 192 |
+
eps = 1e-12
|
| 193 |
+
# All examples less similar than ground truth
|
| 194 |
+
mask = (Sdiff < -eps).type(torch.LongTensor)
|
| 195 |
+
maskf = mask.type_as(S)
|
| 196 |
+
# Mask out all examples >= gt with minimum similarity
|
| 197 |
+
Sp = maskf * Sdiff + (1 - maskf) * torch.min(Sdiff).detach()
|
| 198 |
+
# Find the index maximum similar of the remaining
|
| 199 |
+
_, idc = Sp.max(dim=1)
|
| 200 |
+
idc = idc.data.cpu()
|
| 201 |
+
# Vector mask: 1 iff there exists an example < gt
|
| 202 |
+
has_neg = (mask.sum(dim=1) > 0).data.type(torch.LongTensor)
|
| 203 |
+
# Random imposter indices
|
| 204 |
+
random_imp_ind = torch.LongTensor(basic_get_imposter_indices(N))
|
| 205 |
+
# Use hardneg if there exists an example < gt, otherwise use random imposter
|
| 206 |
+
imp_idc = has_neg * idc + (1 - has_neg) * random_imp_ind
|
| 207 |
+
# This could probably be vectorized too, but I haven't.
|
| 208 |
+
for i, imp in enumerate(imp_idc):
|
| 209 |
+
local_loss = Sdiff[i, imp] + margin
|
| 210 |
+
if (local_loss.data > 0).all():
|
| 211 |
+
loss = loss + local_loss
|
| 212 |
+
loss = loss / N
|
| 213 |
+
return loss
|
| 214 |
+
|
| 215 |
+
def sampled_triplet_loss_from_S(S, margin):
|
| 216 |
+
"""
|
| 217 |
+
Input: Similarity matrix S as an autograd.Variable
|
| 218 |
+
Output: The one-way triplet loss from rows of S to columns of S. Imposters are
|
| 219 |
+
randomly sampled from the columns of S.
|
| 220 |
+
You would need to run this function twice, once with S and once with S.t(),
|
| 221 |
+
in order to compute the triplet loss in both directions.
|
| 222 |
+
"""
|
| 223 |
+
assert(S.dim() == 2)
|
| 224 |
+
assert(S.size(0) == S.size(1))
|
| 225 |
+
N = S.size(0)
|
| 226 |
+
loss = torch.autograd.Variable(torch.zeros(1).type(S.data.type()), requires_grad=True)
|
| 227 |
+
# Imposter - ground truth
|
| 228 |
+
Sdiff = S - torch.diag(S).view(-1, 1)
|
| 229 |
+
imp_ind = torch.LongTensor(basic_get_imposter_indices(N))
|
| 230 |
+
# This could probably be vectorized too, but I haven't.
|
| 231 |
+
for i, imp in enumerate(imp_ind):
|
| 232 |
+
local_loss = Sdiff[i, imp] + margin
|
| 233 |
+
if (local_loss.data > 0).all():
|
| 234 |
+
loss = loss + local_loss
|
| 235 |
+
loss = loss / N
|
| 236 |
+
return loss
|
| 237 |
+
|
| 238 |
+
class AverageMeter(object):
|
| 239 |
+
"""Computes and stores the average and current value"""
|
| 240 |
+
def __init__(self):
|
| 241 |
+
self.reset()
|
| 242 |
+
|
| 243 |
+
def reset(self):
|
| 244 |
+
self.val = 0
|
| 245 |
+
self.avg = 0
|
| 246 |
+
self.sum = 0
|
| 247 |
+
self.count = 0
|
| 248 |
+
|
| 249 |
+
def update(self, val, n=1):
|
| 250 |
+
self.val = val
|
| 251 |
+
self.sum += val * n
|
| 252 |
+
self.count += n
|
| 253 |
+
self.avg = self.sum / self.count
|
| 254 |
+
|
| 255 |
+
def adjust_learning_rate(base_lr, lr_decay, optimizer, epoch):
|
| 256 |
+
"""Sets the learning rate to the initial LR decayed by 10 every lr_decay epochs"""
|
| 257 |
+
lr = base_lr * (0.1 ** (epoch // lr_decay))
|
| 258 |
+
print('now learning rate changed to {:f}'.format(lr))
|
| 259 |
+
for param_group in optimizer.param_groups:
|
| 260 |
+
param_group['lr'] = lr
|
| 261 |
+
|
| 262 |
+
def adjust_learning_rate2(base_lr, lr_decay, optimizer, epoch):
|
| 263 |
+
"""Sets the learning rate to the initial LR decayed by 10 every lr_decay epochs"""
|
| 264 |
+
for param_group in optimizer.param_groups:
|
| 265 |
+
cur_lr = param_group['lr']
|
| 266 |
+
print('current learing rate is {:f}'.format(lr))
|
| 267 |
+
lr = cur_lr * 0.1
|
| 268 |
+
print('now learning rate changed to {:f}'.format(lr))
|
| 269 |
+
for param_group in optimizer.param_groups:
|
| 270 |
+
param_group['lr'] = lr
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
def load_progress(prog_pkl, quiet=False):
|
| 274 |
+
"""
|
| 275 |
+
load progress pkl file
|
| 276 |
+
Args:
|
| 277 |
+
prog_pkl(str): path to progress pkl file
|
| 278 |
+
Return:
|
| 279 |
+
progress(list):
|
| 280 |
+
epoch(int):
|
| 281 |
+
global_step(int):
|
| 282 |
+
best_epoch(int):
|
| 283 |
+
best_avg_r10(float):
|
| 284 |
+
"""
|
| 285 |
+
def _print(msg):
|
| 286 |
+
if not quiet:
|
| 287 |
+
print(msg)
|
| 288 |
+
|
| 289 |
+
with open(prog_pkl, "rb") as f:
|
| 290 |
+
prog = pickle.load(f)
|
| 291 |
+
epoch, global_step, best_epoch, best_avg_r10, _ = prog[-1]
|
| 292 |
+
|
| 293 |
+
_print("\nPrevious Progress:")
|
| 294 |
+
msg = "[%5s %7s %5s %7s %6s]" % ("epoch", "step", "best_epoch", "best_avg_r10", "time")
|
| 295 |
+
_print(msg)
|
| 296 |
+
return prog, epoch, global_step, best_epoch, best_avg_r10
|
| 297 |
+
|
| 298 |
+
def count_parameters(model):
|
| 299 |
+
return sum([p.numel() for p in model.parameters() if p.requires_grad])
|
| 300 |
+
|
| 301 |
+
PrenetConfig = namedtuple(
|
| 302 |
+
'PrenetConfig', ['input_size', 'hidden_size', 'num_layers', 'dropout'])
|
| 303 |
+
|
| 304 |
+
RNNConfig = namedtuple(
|
| 305 |
+
'RNNConfig',
|
| 306 |
+
['input_size', 'hidden_size', 'num_layers', 'dropout', 'residual'])
|
a_cls/zero_shot.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import nn
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
from open_clip import get_input_dtype, get_tokenizer
|
| 11 |
+
from open_clip.factory import HF_HUB_PREFIX
|
| 12 |
+
from .precision import get_autocast
|
| 13 |
+
from .stats import calculate_stats, d_prime
|
| 14 |
+
from .zero_shot_classifier import build_zero_shot_classifier
|
| 15 |
+
from .zero_shot_metadata import CLASSNAMES, OPENAI_IMAGENET_TEMPLATES
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def accuracy(output, target, topk=(1,)):
|
| 19 |
+
pred = output.topk(max(topk), 1, True, True)[1].t()
|
| 20 |
+
correct = pred.eq(target.view(1, -1).expand_as(pred))
|
| 21 |
+
return [float(correct[:k].reshape(-1).float().sum(0, keepdim=True).cpu().numpy()) for k in topk]
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def run(model, classifier, dataloader, args):
|
| 25 |
+
autocast = get_autocast(args.precision)
|
| 26 |
+
input_dtype = get_input_dtype(args.precision)
|
| 27 |
+
|
| 28 |
+
with torch.no_grad():
|
| 29 |
+
top1, top5, n = 0., 0., 0.
|
| 30 |
+
for images, target in tqdm(dataloader, unit_scale=args.batch_size):
|
| 31 |
+
images = images.to(device=args.device, dtype=input_dtype)
|
| 32 |
+
images = images.unsqueeze(2)
|
| 33 |
+
target = target.to(args.device)
|
| 34 |
+
|
| 35 |
+
with autocast():
|
| 36 |
+
# predict
|
| 37 |
+
output = model(image=images)
|
| 38 |
+
image_features = output['image_features'] if isinstance(output, dict) else output[0]
|
| 39 |
+
logits = 100. * image_features @ classifier
|
| 40 |
+
|
| 41 |
+
# measure accuracy
|
| 42 |
+
acc1, acc5 = accuracy(logits, target, topk=(1, 5))
|
| 43 |
+
top1 += acc1
|
| 44 |
+
top5 += acc5
|
| 45 |
+
n += images.size(0)
|
| 46 |
+
|
| 47 |
+
top1 = (top1 / n)
|
| 48 |
+
top5 = (top5 / n)
|
| 49 |
+
return top1, top5
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def validate(audio_model, classifier, val_loader, args, epoch):
|
| 53 |
+
epoch = epoch - 1 ########################
|
| 54 |
+
# switch to evaluate mode
|
| 55 |
+
audio_model.eval()
|
| 56 |
+
autocast = get_autocast(args.precision)
|
| 57 |
+
input_dtype = get_input_dtype(args.precision)
|
| 58 |
+
A_predictions = []
|
| 59 |
+
A_targets = []
|
| 60 |
+
A_loss = []
|
| 61 |
+
with torch.no_grad():
|
| 62 |
+
for i, (audio_input, labels) in enumerate(tqdm(val_loader)):
|
| 63 |
+
audio_input = audio_input.to(device=args.device, dtype=input_dtype)
|
| 64 |
+
|
| 65 |
+
# compute output
|
| 66 |
+
with autocast():
|
| 67 |
+
# predict
|
| 68 |
+
output = audio_model(image=audio_input)
|
| 69 |
+
image_features = output['image_features'] if isinstance(output, dict) else output[0]
|
| 70 |
+
logits = 100. * image_features @ classifier
|
| 71 |
+
audio_output = logits
|
| 72 |
+
|
| 73 |
+
# audio_output = torch.sigmoid(audio_output)
|
| 74 |
+
predictions = audio_output.to('cpu').detach()
|
| 75 |
+
|
| 76 |
+
A_predictions.append(predictions)
|
| 77 |
+
A_targets.append(labels)
|
| 78 |
+
|
| 79 |
+
# compute the loss
|
| 80 |
+
labels = labels.to(args.device)
|
| 81 |
+
loss = nn.CrossEntropyLoss()(audio_output, torch.argmax(labels.long(), dim=1))
|
| 82 |
+
A_loss.append(loss.to('cpu').detach())
|
| 83 |
+
|
| 84 |
+
audio_output = torch.cat(A_predictions)
|
| 85 |
+
target = torch.cat(A_targets)
|
| 86 |
+
loss = np.mean(A_loss)
|
| 87 |
+
stats = calculate_stats(audio_output, target)
|
| 88 |
+
|
| 89 |
+
# save the prediction here
|
| 90 |
+
args.a_cls_output_dir = os.path.join(args.log_base_path, f'a_cls/{args.val_a_cls_data.lower()}')
|
| 91 |
+
os.makedirs(args.a_cls_output_dir, exist_ok=True)
|
| 92 |
+
if os.path.exists(args.a_cls_output_dir + '/predictions') == False:
|
| 93 |
+
os.mkdir(args.a_cls_output_dir + '/predictions')
|
| 94 |
+
np.savetxt(args.a_cls_output_dir + '/predictions/target.csv', target, delimiter=',')
|
| 95 |
+
np.savetxt(args.a_cls_output_dir + '/predictions/predictions_' + str(epoch) + '.csv', audio_output,
|
| 96 |
+
delimiter=',')
|
| 97 |
+
|
| 98 |
+
valid_loss = loss
|
| 99 |
+
main_metrics = 'mAP'
|
| 100 |
+
metrics = {}
|
| 101 |
+
|
| 102 |
+
if args.do_train:
|
| 103 |
+
# ensemble results
|
| 104 |
+
cum_stats = validate_ensemble(args, epoch)
|
| 105 |
+
cum_mAP = np.mean([stat['AP'] for stat in cum_stats])
|
| 106 |
+
cum_mAUC = np.mean([stat['auc'] for stat in cum_stats])
|
| 107 |
+
cum_acc = cum_stats[0]['acc']
|
| 108 |
+
|
| 109 |
+
mAP = np.mean([stat['AP'] for stat in stats])
|
| 110 |
+
mAUC = np.mean([stat['auc'] for stat in stats])
|
| 111 |
+
acc = stats[0]['acc']
|
| 112 |
+
|
| 113 |
+
middle_ps = [stat['precisions'][int(len(stat['precisions']) / 2)] for stat in stats]
|
| 114 |
+
middle_rs = [stat['recalls'][int(len(stat['recalls']) / 2)] for stat in stats]
|
| 115 |
+
average_precision = np.mean(middle_ps)
|
| 116 |
+
average_recall = np.mean(middle_rs)
|
| 117 |
+
|
| 118 |
+
if main_metrics == 'mAP':
|
| 119 |
+
logging.info("mAP: {:.6f}".format(mAP))
|
| 120 |
+
else:
|
| 121 |
+
logging.info("acc: {:.6f}".format(acc))
|
| 122 |
+
logging.info("AUC: {:.6f}".format(mAUC))
|
| 123 |
+
logging.info("Avg Precision: {:.6f}".format(average_precision))
|
| 124 |
+
logging.info("Avg Recall: {:.6f}".format(average_recall))
|
| 125 |
+
logging.info("d_prime: {:.6f}".format(d_prime(mAUC)))
|
| 126 |
+
logging.info("valid_loss: {:.6f}".format(valid_loss))
|
| 127 |
+
|
| 128 |
+
if args.do_train:
|
| 129 |
+
logging.info("cum_mAP: {:.6f}".format(cum_mAP))
|
| 130 |
+
logging.info("cum_mAUC: {:.6f}".format(cum_mAUC))
|
| 131 |
+
|
| 132 |
+
if main_metrics == 'mAP':
|
| 133 |
+
metrics['mAP'] = float(mAP)
|
| 134 |
+
else:
|
| 135 |
+
metrics['acc'] = float(acc)
|
| 136 |
+
|
| 137 |
+
metrics['mAUC'] = float(mAUC)
|
| 138 |
+
metrics['average_precision'] = float(average_precision)
|
| 139 |
+
metrics['average_recall'] = float(average_recall)
|
| 140 |
+
metrics['d_prime_mAUC'] = float(d_prime(mAUC))
|
| 141 |
+
metrics['valid_loss'] = float(valid_loss)
|
| 142 |
+
|
| 143 |
+
if args.do_train:
|
| 144 |
+
metrics['cum_mAP'] = float(cum_mAP)
|
| 145 |
+
metrics['cum_mAUC'] = float(cum_mAUC)
|
| 146 |
+
|
| 147 |
+
return metrics
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def validate_ensemble(args, epoch):
|
| 151 |
+
exp_dir = args.a_cls_output_dir
|
| 152 |
+
target = np.loadtxt(exp_dir + '/predictions/target.csv', delimiter=',')
|
| 153 |
+
if epoch == 0:
|
| 154 |
+
cum_predictions = np.loadtxt(exp_dir + '/predictions/predictions_0.csv', delimiter=',')
|
| 155 |
+
else:
|
| 156 |
+
cum_predictions = np.loadtxt(exp_dir + '/predictions/cum_predictions.csv', delimiter=',') * (epoch - 1)
|
| 157 |
+
predictions = np.loadtxt(exp_dir + '/predictions/predictions_' + str(epoch) + '.csv', delimiter=',')
|
| 158 |
+
cum_predictions = cum_predictions + predictions
|
| 159 |
+
# remove the prediction file to save storage space
|
| 160 |
+
os.remove(exp_dir + '/predictions/predictions_' + str(epoch - 1) + '.csv')
|
| 161 |
+
|
| 162 |
+
cum_predictions = cum_predictions / (epoch + 1)
|
| 163 |
+
np.savetxt(exp_dir + '/predictions/cum_predictions.csv', cum_predictions, delimiter=',')
|
| 164 |
+
|
| 165 |
+
stats = calculate_stats(cum_predictions, target)
|
| 166 |
+
return stats
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def zero_shot_eval(model, data, epoch, args):
|
| 177 |
+
temp_val_a_cls_data = args.val_a_cls_data
|
| 178 |
+
args.val_a_cls_data = list(data.keys())
|
| 179 |
+
assert len(args.val_a_cls_data) == 1
|
| 180 |
+
args.val_a_cls_data = args.val_a_cls_data[0]
|
| 181 |
+
|
| 182 |
+
if args.val_a_cls_data not in data:
|
| 183 |
+
return {}
|
| 184 |
+
if args.zeroshot_frequency == 0:
|
| 185 |
+
return {}
|
| 186 |
+
if (epoch % args.zeroshot_frequency) != 0 and epoch != args.epochs:
|
| 187 |
+
return {}
|
| 188 |
+
if args.distributed and not args.horovod:
|
| 189 |
+
model = model.module
|
| 190 |
+
|
| 191 |
+
logging.info(f'Starting zero-shot {args.val_a_cls_data.upper()}.')
|
| 192 |
+
|
| 193 |
+
logging.info('Building zero-shot classifier')
|
| 194 |
+
autocast = get_autocast(args.precision)
|
| 195 |
+
with autocast():
|
| 196 |
+
tokenizer = get_tokenizer(HF_HUB_PREFIX+args.model, cache_dir=args.cache_dir)
|
| 197 |
+
# tokenizer = get_tokenizer("ViT-L-14")
|
| 198 |
+
classifier = build_zero_shot_classifier(
|
| 199 |
+
model,
|
| 200 |
+
tokenizer=tokenizer,
|
| 201 |
+
classnames=CLASSNAMES[args.val_a_cls_data],
|
| 202 |
+
templates=OPENAI_IMAGENET_TEMPLATES,
|
| 203 |
+
num_classes_per_batch=10,
|
| 204 |
+
device=args.device,
|
| 205 |
+
use_tqdm=True,
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
logging.info('Using classifier')
|
| 209 |
+
results = {}
|
| 210 |
+
if args.val_a_cls_data.lower() == 'audioset':
|
| 211 |
+
if args.val_a_cls_data in data:
|
| 212 |
+
stats = validate(model, classifier, data[args.val_a_cls_data].dataloader, args, epoch)
|
| 213 |
+
results.update(stats)
|
| 214 |
+
else:
|
| 215 |
+
if args.val_a_cls_data in data:
|
| 216 |
+
top1, top5 = run(model, classifier, data[args.val_a_cls_data].dataloader, args)
|
| 217 |
+
results[f'{args.val_a_cls_data}-zeroshot-val-top1'] = top1
|
| 218 |
+
results[f'{args.val_a_cls_data}-zeroshot-val-top5'] = top5
|
| 219 |
+
|
| 220 |
+
logging.info(f'Finished zero-shot {args.val_a_cls_data.upper()}.')
|
| 221 |
+
|
| 222 |
+
args.val_a_cls_data = temp_val_a_cls_data
|
| 223 |
+
return results
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
|
a_cls/zero_shot_classifier.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from itertools import islice
|
| 3 |
+
from typing import Callable, List, Optional, Sequence, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def batched(iterable, n):
|
| 10 |
+
"""Batch data into lists of length *n*. The last batch may be shorter.
|
| 11 |
+
NOTE based on more-itertools impl, to be replaced by python 3.12 itertools.batched impl
|
| 12 |
+
"""
|
| 13 |
+
it = iter(iterable)
|
| 14 |
+
while True:
|
| 15 |
+
batch = list(islice(it, n))
|
| 16 |
+
if not batch:
|
| 17 |
+
break
|
| 18 |
+
yield batch
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def build_zero_shot_classifier(
|
| 22 |
+
model,
|
| 23 |
+
tokenizer,
|
| 24 |
+
classnames: Sequence[str],
|
| 25 |
+
templates: Sequence[Union[Callable, str]],
|
| 26 |
+
num_classes_per_batch: Optional[int] = 10,
|
| 27 |
+
device: Union[str, torch.device] = 'cpu',
|
| 28 |
+
use_tqdm: bool = False,
|
| 29 |
+
):
|
| 30 |
+
""" Build zero-shot classifier weights by iterating over class names in batches
|
| 31 |
+
Args:
|
| 32 |
+
model: CLIP model instance
|
| 33 |
+
tokenizer: CLIP tokenizer instance
|
| 34 |
+
classnames: A sequence of class (label) names
|
| 35 |
+
templates: A sequence of callables or format() friendly strings to produce templates per class name
|
| 36 |
+
num_classes_per_batch: The number of classes to batch together in each forward, all if None
|
| 37 |
+
device: Device to use.
|
| 38 |
+
use_tqdm: Enable TQDM progress bar.
|
| 39 |
+
"""
|
| 40 |
+
assert isinstance(templates, Sequence) and len(templates) > 0
|
| 41 |
+
assert isinstance(classnames, Sequence) and len(classnames) > 0
|
| 42 |
+
use_format = isinstance(templates[0], str)
|
| 43 |
+
num_templates = len(templates)
|
| 44 |
+
num_classes = len(classnames)
|
| 45 |
+
if use_tqdm:
|
| 46 |
+
import tqdm
|
| 47 |
+
num_iter = 1 if num_classes_per_batch is None else ((num_classes - 1) // num_classes_per_batch + 1)
|
| 48 |
+
iter_wrap = partial(tqdm.tqdm, total=num_iter, unit_scale=num_classes_per_batch)
|
| 49 |
+
else:
|
| 50 |
+
iter_wrap = iter
|
| 51 |
+
|
| 52 |
+
def _process_batch(batch_classnames):
|
| 53 |
+
num_batch_classes = len(batch_classnames)
|
| 54 |
+
texts = [template.format(c) if use_format else template(c) for c in batch_classnames for template in templates]
|
| 55 |
+
input_ids, attention_mask = tokenizer(texts)
|
| 56 |
+
input_ids, attention_mask = input_ids.to(device), attention_mask.to(device)
|
| 57 |
+
class_embeddings = F.normalize(model.encode_text(input_ids, attention_mask), dim=-1)
|
| 58 |
+
class_embeddings = class_embeddings.reshape(num_batch_classes, num_templates, -1).mean(dim=1)
|
| 59 |
+
class_embeddings = class_embeddings / class_embeddings.norm(dim=1, keepdim=True)
|
| 60 |
+
class_embeddings = class_embeddings.T
|
| 61 |
+
return class_embeddings
|
| 62 |
+
|
| 63 |
+
with torch.no_grad():
|
| 64 |
+
if num_classes_per_batch:
|
| 65 |
+
batched_embeds = [_process_batch(batch) for batch in iter_wrap(batched(classnames, num_classes_per_batch))]
|
| 66 |
+
zeroshot_weights = torch.cat(batched_embeds, dim=1)
|
| 67 |
+
else:
|
| 68 |
+
zeroshot_weights = _process_batch(classnames)
|
| 69 |
+
return zeroshot_weights
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def build_zero_shot_classifier_legacy(
|
| 73 |
+
model,
|
| 74 |
+
tokenizer,
|
| 75 |
+
classnames: Sequence[str],
|
| 76 |
+
templates: Sequence[Union[Callable, str]],
|
| 77 |
+
device: Union[str, torch.device] = 'cpu',
|
| 78 |
+
use_tqdm: bool = False,
|
| 79 |
+
):
|
| 80 |
+
""" Build zero-shot classifier weights by iterating over class names 1 by 1
|
| 81 |
+
Args:
|
| 82 |
+
model: CLIP model instance
|
| 83 |
+
tokenizer: CLIP tokenizer instance
|
| 84 |
+
classnames: A sequence of class (label) names
|
| 85 |
+
templates: A sequence of callables or format() friendly strings to produce templates per class name
|
| 86 |
+
device: Device to use.
|
| 87 |
+
use_tqdm: Enable TQDM progress bar.
|
| 88 |
+
"""
|
| 89 |
+
assert isinstance(templates, Sequence) and len(templates) > 0
|
| 90 |
+
assert isinstance(classnames, Sequence) and len(classnames) > 0
|
| 91 |
+
if use_tqdm:
|
| 92 |
+
import tqdm
|
| 93 |
+
iter_wrap = tqdm.tqdm
|
| 94 |
+
else:
|
| 95 |
+
iter_wrap = iter
|
| 96 |
+
|
| 97 |
+
use_format = isinstance(templates[0], str)
|
| 98 |
+
|
| 99 |
+
with torch.no_grad():
|
| 100 |
+
zeroshot_weights = []
|
| 101 |
+
for classname in iter_wrap(classnames):
|
| 102 |
+
texts = [template.format(classname) if use_format else template(classname) for template in templates]
|
| 103 |
+
texts = tokenizer(texts).to(device) # tokenize
|
| 104 |
+
class_embeddings = model.encode_text(texts)
|
| 105 |
+
class_embedding = F.normalize(class_embeddings, dim=-1).mean(dim=0)
|
| 106 |
+
class_embedding /= class_embedding.norm()
|
| 107 |
+
zeroshot_weights.append(class_embedding)
|
| 108 |
+
zeroshot_weights = torch.stack(zeroshot_weights, dim=1).to(device)
|
| 109 |
+
|
| 110 |
+
return zeroshot_weights
|
| 111 |
+
|
a_cls/zero_shot_metadata.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
|
| 5 |
+
# OPENAI_IMAGENET_TEMPLATES = (
|
| 6 |
+
# lambda c: f'This is a sound of {c}.',
|
| 7 |
+
# )
|
| 8 |
+
OPENAI_IMAGENET_TEMPLATES = (
|
| 9 |
+
lambda c: f'a bad sound of a {c}.',
|
| 10 |
+
lambda c: f'a sound of many {c}.',
|
| 11 |
+
lambda c: f'a sculpture of a {c}.',
|
| 12 |
+
lambda c: f'a sound of the hard to see {c}.',
|
| 13 |
+
lambda c: f'a low resolution sound of the {c}.',
|
| 14 |
+
lambda c: f'a rendering of a {c}.',
|
| 15 |
+
lambda c: f'graffiti of a {c}.',
|
| 16 |
+
lambda c: f'a bad sound of the {c}.',
|
| 17 |
+
lambda c: f'a cropped sound of the {c}.',
|
| 18 |
+
lambda c: f'a tattoo of a {c}.',
|
| 19 |
+
lambda c: f'the embroidered {c}.',
|
| 20 |
+
lambda c: f'a sound of a hard to see {c}.',
|
| 21 |
+
lambda c: f'a bright sound of a {c}.',
|
| 22 |
+
lambda c: f'a sound of a clean {c}.',
|
| 23 |
+
lambda c: f'a sound of a dirty {c}.',
|
| 24 |
+
lambda c: f'a dark sound of the {c}.',
|
| 25 |
+
lambda c: f'a drawing of a {c}.',
|
| 26 |
+
lambda c: f'a sound of my {c}.',
|
| 27 |
+
lambda c: f'the plastic {c}.',
|
| 28 |
+
lambda c: f'a sound of the cool {c}.',
|
| 29 |
+
lambda c: f'a close-up sound of a {c}.',
|
| 30 |
+
lambda c: f'a black and white sound of the {c}.',
|
| 31 |
+
lambda c: f'a painting of the {c}.',
|
| 32 |
+
lambda c: f'a painting of a {c}.',
|
| 33 |
+
lambda c: f'a pixelated sound of the {c}.',
|
| 34 |
+
lambda c: f'a sculpture of the {c}.',
|
| 35 |
+
lambda c: f'a bright sound of the {c}.',
|
| 36 |
+
lambda c: f'a cropped sound of a {c}.',
|
| 37 |
+
lambda c: f'a plastic {c}.',
|
| 38 |
+
lambda c: f'a sound of the dirty {c}.',
|
| 39 |
+
lambda c: f'a jpeg corrupted sound of a {c}.',
|
| 40 |
+
lambda c: f'a blurry sound of the {c}.',
|
| 41 |
+
lambda c: f'a sound of the {c}.',
|
| 42 |
+
lambda c: f'a good sound of the {c}.',
|
| 43 |
+
lambda c: f'a rendering of the {c}.',
|
| 44 |
+
lambda c: f'a {c} in a video game.',
|
| 45 |
+
lambda c: f'a sound of one {c}.',
|
| 46 |
+
lambda c: f'a doodle of a {c}.',
|
| 47 |
+
lambda c: f'a close-up sound of the {c}.',
|
| 48 |
+
lambda c: f'a sound of a {c}.',
|
| 49 |
+
lambda c: f'the origami {c}.',
|
| 50 |
+
lambda c: f'the {c} in a video game.',
|
| 51 |
+
lambda c: f'a sketch of a {c}.',
|
| 52 |
+
lambda c: f'a doodle of the {c}.',
|
| 53 |
+
lambda c: f'a origami {c}.',
|
| 54 |
+
lambda c: f'a low resolution sound of a {c}.',
|
| 55 |
+
lambda c: f'the toy {c}.',
|
| 56 |
+
lambda c: f'a rendition of the {c}.',
|
| 57 |
+
lambda c: f'a sound of the clean {c}.',
|
| 58 |
+
lambda c: f'a sound of a large {c}.',
|
| 59 |
+
lambda c: f'a rendition of a {c}.',
|
| 60 |
+
lambda c: f'a sound of a nice {c}.',
|
| 61 |
+
lambda c: f'a sound of a weird {c}.',
|
| 62 |
+
lambda c: f'a blurry sound of a {c}.',
|
| 63 |
+
lambda c: f'a cartoon {c}.',
|
| 64 |
+
lambda c: f'art of a {c}.',
|
| 65 |
+
lambda c: f'a sketch of the {c}.',
|
| 66 |
+
lambda c: f'a embroidered {c}.',
|
| 67 |
+
lambda c: f'a pixelated sound of a {c}.',
|
| 68 |
+
lambda c: f'itap of the {c}.',
|
| 69 |
+
lambda c: f'a jpeg corrupted sound of the {c}.',
|
| 70 |
+
lambda c: f'a good sound of a {c}.',
|
| 71 |
+
lambda c: f'a plushie {c}.',
|
| 72 |
+
lambda c: f'a sound of the nice {c}.',
|
| 73 |
+
lambda c: f'a sound of the small {c}.',
|
| 74 |
+
lambda c: f'a sound of the weird {c}.',
|
| 75 |
+
lambda c: f'the cartoon {c}.',
|
| 76 |
+
lambda c: f'art of the {c}.',
|
| 77 |
+
lambda c: f'a drawing of the {c}.',
|
| 78 |
+
lambda c: f'a sound of the large {c}.',
|
| 79 |
+
lambda c: f'a black and white sound of a {c}.',
|
| 80 |
+
lambda c: f'the plushie {c}.',
|
| 81 |
+
lambda c: f'a dark sound of a {c}.',
|
| 82 |
+
lambda c: f'itap of a {c}.',
|
| 83 |
+
lambda c: f'graffiti of the {c}.',
|
| 84 |
+
lambda c: f'a toy {c}.',
|
| 85 |
+
lambda c: f'itap of my {c}.',
|
| 86 |
+
lambda c: f'a sound of a cool {c}.',
|
| 87 |
+
lambda c: f'a sound of a small {c}.',
|
| 88 |
+
lambda c: f'a tattoo of the {c}.',
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
# a much smaller subset of above prompts
|
| 92 |
+
# from https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb
|
| 93 |
+
SIMPLE_IMAGENET_TEMPLATES = (
|
| 94 |
+
lambda c: f'itap of a {c}.',
|
| 95 |
+
lambda c: f'a bad sound of the {c}.',
|
| 96 |
+
lambda c: f'a origami {c}.',
|
| 97 |
+
lambda c: f'a sound of the large {c}.',
|
| 98 |
+
lambda c: f'a {c} in a video game.',
|
| 99 |
+
lambda c: f'art of the {c}.',
|
| 100 |
+
lambda c: f'a sound of the small {c}.',
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
PATH = os.path.join(os.path.dirname(os.path.abspath(__file__)), "class_labels_indices.csv")
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
CLASSNAMES = {
|
| 108 |
+
'Audioset': tuple(pd.read_csv(PATH).values[:, 2]),
|
| 109 |
+
'ESC50': (
|
| 110 |
+
'airplane', 'breathing', 'brushing teeth', 'can opening', 'car horn', 'cat', 'chainsaw', 'chirping birds',
|
| 111 |
+
'church bells', 'clapping', 'clock alarm', 'clock tick', 'coughing', 'cow', 'crackling fire', 'crickets',
|
| 112 |
+
'crow', 'crying baby', 'dog', 'door wood creaks', 'door wood knock', 'drinking sipping', 'engine', 'fireworks',
|
| 113 |
+
'footsteps', 'frog', 'glass breaking', 'hand saw', 'helicopter', 'hen', 'insects', 'keyboard typing',
|
| 114 |
+
'laughing', 'mouse click', 'pig', 'pouring water', 'rain', 'rooster', 'sea waves', 'sheep', 'siren',
|
| 115 |
+
'sneezing', 'snoring', 'thunderstorm', 'toilet flush', 'train', 'vacuum cleaner', 'washing machine',
|
| 116 |
+
'water drops', 'wind'
|
| 117 |
+
),
|
| 118 |
+
'VGGSound': (
|
| 119 |
+
'air conditioning noise', 'air horn', 'airplane', 'airplane flyby', 'alarm clock ringing',
|
| 120 |
+
'alligators, crocodiles hissing', 'ambulance siren', 'arc welding', 'baby babbling', 'baby crying',
|
| 121 |
+
'baby laughter', 'baltimore oriole calling', 'barn swallow calling', 'basketball bounce',
|
| 122 |
+
'bathroom ventilation fan running', 'beat boxing', 'bee, wasp, etc. buzzing', 'bird chirping, tweeting',
|
| 123 |
+
'bird squawking', 'bird wings flapping', 'black capped chickadee calling', 'blowtorch igniting',
|
| 124 |
+
'bouncing on trampoline', 'bowling impact', 'bull bellowing', 'canary calling', 'cap gun shooting',
|
| 125 |
+
'car engine idling', 'car engine knocking', 'car engine starting', 'car passing by', 'cat caterwauling',
|
| 126 |
+
'cat growling', 'cat hissing', 'cat meowing', 'cat purring', 'cattle mooing', 'cattle, bovinae cowbell',
|
| 127 |
+
'cell phone buzzing', 'chainsawing trees', 'cheetah chirrup', 'chicken clucking', 'chicken crowing',
|
| 128 |
+
'child singing', 'child speech, kid speaking', 'children shouting', 'chimpanzee pant-hooting',
|
| 129 |
+
'chinchilla barking', 'chipmunk chirping', 'chopping food', 'chopping wood', 'church bell ringing',
|
| 130 |
+
'civil defense siren', 'cow lowing', 'coyote howling', 'cricket chirping', 'crow cawing', 'cuckoo bird calling',
|
| 131 |
+
'cupboard opening or closing', 'cutting hair with electric trimmers', 'dinosaurs bellowing', 'disc scratching',
|
| 132 |
+
'dog barking', 'dog baying', 'dog bow-wow', 'dog growling', 'dog howling', 'dog whimpering',
|
| 133 |
+
'donkey, ass braying', 'door slamming', 'driving buses', 'driving motorcycle', 'driving snowmobile',
|
| 134 |
+
'duck quacking', 'eagle screaming', 'eating with cutlery', 'electric grinder grinding',
|
| 135 |
+
'electric shaver, electric razor shaving', 'elephant trumpeting', 'eletric blender running', 'elk bugling',
|
| 136 |
+
'engine accelerating, revving, vroom', 'female singing', 'female speech, woman speaking', 'ferret dooking',
|
| 137 |
+
'fire crackling', 'fire truck siren', 'fireworks banging', 'firing cannon', 'firing muskets',
|
| 138 |
+
'fly, housefly buzzing', 'foghorn', 'footsteps on snow', 'forging swords', 'fox barking', 'francolin calling',
|
| 139 |
+
'frog croaking', 'gibbon howling', 'goat bleating', 'golf driving', 'goose honking', 'hail',
|
| 140 |
+
'hair dryer drying', 'hammering nails', 'heart sounds, heartbeat', 'hedge trimmer running', 'helicopter',
|
| 141 |
+
'horse clip-clop', 'horse neighing', 'ice cracking', 'ice cream truck, ice cream van', 'lathe spinning',
|
| 142 |
+
'lawn mowing', 'lighting firecrackers', 'lions growling', 'lions roaring', 'lip smacking',
|
| 143 |
+
'machine gun shooting', 'magpie calling', 'male singing', 'male speech, man speaking', 'metronome',
|
| 144 |
+
'missile launch', 'mosquito buzzing', 'motorboat, speedboat acceleration', 'mouse clicking', 'mouse pattering',
|
| 145 |
+
'mouse squeaking', 'mynah bird singing', 'ocean burbling', 'opening or closing car doors',
|
| 146 |
+
'opening or closing car electric windows', 'opening or closing drawers', 'orchestra', 'otter growling',
|
| 147 |
+
'owl hooting', 'parrot talking', 'penguins braying', 'people babbling', 'people battle cry',
|
| 148 |
+
'people belly laughing', 'people booing', 'people burping', 'people cheering', 'people clapping',
|
| 149 |
+
'people coughing', 'people crowd', 'people eating', 'people eating apple', 'people eating crisps',
|
| 150 |
+
'people eating noodle', 'people farting', 'people finger snapping', 'people gargling', 'people giggling',
|
| 151 |
+
'people hiccup', 'people humming', 'people marching', 'people nose blowing', 'people running',
|
| 152 |
+
'people screaming', 'people shuffling', 'people slapping', 'people slurping', 'people sneezing',
|
| 153 |
+
'people sniggering', 'people sobbing', 'people whispering', 'people whistling', 'pheasant crowing',
|
| 154 |
+
'pig oinking', 'pigeon, dove cooing', 'planing timber', 'plastic bottle crushing', 'playing accordion',
|
| 155 |
+
'playing acoustic guitar', 'playing badminton', 'playing bagpipes', 'playing banjo', 'playing bass drum',
|
| 156 |
+
'playing bass guitar', 'playing bassoon', 'playing bongo', 'playing bugle', 'playing castanets',
|
| 157 |
+
'playing cello', 'playing clarinet', 'playing congas', 'playing cornet', 'playing cymbal', 'playing darts',
|
| 158 |
+
'playing didgeridoo', 'playing djembe', 'playing double bass', 'playing drum kit', 'playing electric guitar',
|
| 159 |
+
'playing electronic organ', 'playing erhu', 'playing flute', 'playing french horn', 'playing glockenspiel',
|
| 160 |
+
'playing gong', 'playing guiro', 'playing hammond organ', 'playing harmonica', 'playing harp',
|
| 161 |
+
'playing harpsichord', 'playing hockey', 'playing lacrosse', 'playing mandolin', 'playing marimba, xylophone',
|
| 162 |
+
'playing oboe', 'playing piano', 'playing saxophone', 'playing shofar', 'playing sitar', 'playing snare drum',
|
| 163 |
+
'playing squash', 'playing steel guitar, slide guitar', 'playing steelpan', 'playing synthesizer',
|
| 164 |
+
'playing tabla', 'playing table tennis', 'playing tambourine', 'playing tennis', 'playing theremin',
|
| 165 |
+
'playing timbales', 'playing timpani', 'playing trombone', 'playing trumpet', 'playing tuning fork',
|
| 166 |
+
'playing tympani', 'playing ukulele', 'playing vibraphone', 'playing violin, fiddle', 'playing volleyball',
|
| 167 |
+
'playing washboard', 'playing zither', 'police car (siren)', 'police radio chatter', 'popping popcorn',
|
| 168 |
+
'printer printing', 'pumping water', 'race car, auto racing', 'railroad car, train wagon', 'raining', 'rapping',
|
| 169 |
+
'reversing beeps', 'ripping paper', 'roller coaster running', 'rope skipping', 'rowboat, canoe, kayak rowing',
|
| 170 |
+
'running electric fan', 'sailing', 'scuba diving', 'sea lion barking', 'sea waves', 'sharpen knife',
|
| 171 |
+
'sheep bleating', 'shot football', 'singing bowl', 'singing choir', 'skateboarding', 'skidding', 'skiing',
|
| 172 |
+
'sliding door', 'sloshing water', 'slot machine', 'smoke detector beeping', 'snake hissing', 'snake rattling',
|
| 173 |
+
'splashing water', 'spraying water', 'squishing water', 'stream burbling', 'strike lighter', 'striking bowling',
|
| 174 |
+
'striking pool', 'subway, metro, underground', 'swimming', 'tap dancing', 'tapping guitar',
|
| 175 |
+
'telephone bell ringing', 'thunder', 'toilet flushing', 'tornado roaring', 'tractor digging', 'train horning',
|
| 176 |
+
'train wheels squealing', 'train whistling', 'turkey gobbling', 'typing on computer keyboard',
|
| 177 |
+
'typing on typewriter', 'underwater bubbling', 'using sewing machines', 'vacuum cleaner cleaning floors',
|
| 178 |
+
'vehicle horn, car horn, honking', 'volcano explosion', 'warbler chirping', 'waterfall burbling',
|
| 179 |
+
'whale calling', 'wind chime', 'wind noise', 'wind rustling leaves', 'wood thrush calling',
|
| 180 |
+
'woodpecker pecking tree', 'writing on blackboard with chalk', 'yodelling', 'zebra braying'
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
}
|
a_cls/zeroshot_cls.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
from training.distributed import is_master
|
| 6 |
+
from .zero_shot import zero_shot_eval
|
| 7 |
+
|
| 8 |
+
try:
|
| 9 |
+
import wandb
|
| 10 |
+
except ImportError:
|
| 11 |
+
wandb = None
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def evaluate_a_cls(model, data, epoch, args, tb_writer=None):
|
| 16 |
+
metrics = {}
|
| 17 |
+
if not is_master(args):
|
| 18 |
+
return metrics
|
| 19 |
+
model.eval()
|
| 20 |
+
|
| 21 |
+
zero_shot_metrics = zero_shot_eval(model, data, epoch, args)
|
| 22 |
+
metrics.update(zero_shot_metrics)
|
| 23 |
+
|
| 24 |
+
if not metrics:
|
| 25 |
+
return metrics
|
| 26 |
+
|
| 27 |
+
logging.info(
|
| 28 |
+
f"Eval Epoch: {epoch} "
|
| 29 |
+
+ "\t".join([f"{k}: {round(v, 4):.4f}" for k, v in metrics.items()])
|
| 30 |
+
)
|
| 31 |
+
if args.save_logs:
|
| 32 |
+
for name, val in metrics.items():
|
| 33 |
+
if tb_writer is not None:
|
| 34 |
+
tb_writer.add_scalar(f"val/a_cls/{args.val_a_cls_data[0].lower()}/{name}", val, epoch)
|
| 35 |
+
args.a_cls_output_dir = os.path.join(args.log_base_path, f'a_cls/{args.val_a_cls_data[0].lower()}')
|
| 36 |
+
os.makedirs(args.a_cls_output_dir, exist_ok=True)
|
| 37 |
+
with open(os.path.join(args.a_cls_output_dir, "results.jsonl"), "a+") as f:
|
| 38 |
+
f.write(json.dumps(metrics))
|
| 39 |
+
f.write("\n")
|
| 40 |
+
|
| 41 |
+
if args.wandb:
|
| 42 |
+
assert wandb is not None, 'Please install wandb.'
|
| 43 |
+
for name, val in metrics.items():
|
| 44 |
+
wandb.log({f"val/{name}": val, 'epoch': epoch})
|
| 45 |
+
|
| 46 |
+
return metrics
|
app.py
ADDED
|
@@ -0,0 +1,327 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
|
| 8 |
+
from data.process_image import load_and_transform_image, get_image_transform
|
| 9 |
+
from main import SET_GLOBAL_VALUE
|
| 10 |
+
from model.build_model import create_vat_model
|
| 11 |
+
from data.process_audio import load_and_transform_audio, get_audio_transform
|
| 12 |
+
from data.process_video import load_and_transform_video, get_video_transform
|
| 13 |
+
from data.process_depth import load_and_transform_depth, get_depth_transform
|
| 14 |
+
from data.process_thermal import load_and_transform_thermal, get_thermal_transform
|
| 15 |
+
from data.process_text import load_and_transform_text
|
| 16 |
+
from open_clip import get_tokenizer
|
| 17 |
+
from open_clip.factory import HF_HUB_PREFIX
|
| 18 |
+
|
| 19 |
+
os.system("wget https://huggingface.co/lb203/LanguageBind/resolve/main/vl.pt")
|
| 20 |
+
os.system("wget https://huggingface.co/lb203/LanguageBind/resolve/main/al.pt")
|
| 21 |
+
os.system("wget https://huggingface.co/lb203/LanguageBind/resolve/main/il.pt")
|
| 22 |
+
os.system("wget https://huggingface.co/lb203/LanguageBind/resolve/main/dl.pt")
|
| 23 |
+
os.system("wget https://huggingface.co/lb203/LanguageBind/resolve/main/tl.pt")
|
| 24 |
+
|
| 25 |
+
class LanguageBind(nn.Module):
|
| 26 |
+
def __init__(self, args):
|
| 27 |
+
super(LanguageBind, self).__init__()
|
| 28 |
+
temp_clip_type = args.clip_type
|
| 29 |
+
self.modality_encoder = {}
|
| 30 |
+
self.modality_proj = {}
|
| 31 |
+
self.modality_scale = {}
|
| 32 |
+
for c in temp_clip_type:
|
| 33 |
+
args.clip_type = c
|
| 34 |
+
if c == 'il':
|
| 35 |
+
args.convert_to_lora = False
|
| 36 |
+
model = create_vat_model(args)
|
| 37 |
+
args.convert_to_lora = True
|
| 38 |
+
elif c == 'vl':
|
| 39 |
+
args.lora_r = 64
|
| 40 |
+
args.add_time_attn = True
|
| 41 |
+
model = create_vat_model(args)
|
| 42 |
+
args.add_time_attn = False
|
| 43 |
+
args.lora_r = 2
|
| 44 |
+
elif c == 'al':
|
| 45 |
+
args.lora_r = 8
|
| 46 |
+
model = create_vat_model(args)
|
| 47 |
+
args.lora_r = 2
|
| 48 |
+
else:
|
| 49 |
+
model = create_vat_model(args)
|
| 50 |
+
state_dict = torch.load(f'model_zoo/{c}.pt', map_location='cpu')
|
| 51 |
+
if state_dict.get('state_dict', None) is not None:
|
| 52 |
+
state_dict = state_dict['state_dict']
|
| 53 |
+
if next(iter(state_dict.items()))[0].startswith('module'):
|
| 54 |
+
state_dict = {k[7:]: v for k, v in state_dict.items()}
|
| 55 |
+
msg = model.load_state_dict(state_dict, strict=False)
|
| 56 |
+
print(f'load {c}, {msg}')
|
| 57 |
+
if c == 'vl':
|
| 58 |
+
self.modality_encoder['video'] = model.vision_model
|
| 59 |
+
self.modality_proj['video'] = model.visual_projection
|
| 60 |
+
self.modality_scale['video'] = model.logit_scale
|
| 61 |
+
elif c == 'al':
|
| 62 |
+
self.modality_encoder['audio'] = model.vision_model
|
| 63 |
+
self.modality_proj['audio'] = model.visual_projection
|
| 64 |
+
self.modality_scale['audio'] = model.logit_scale
|
| 65 |
+
elif c == 'dl':
|
| 66 |
+
self.modality_encoder['depth'] = model.vision_model
|
| 67 |
+
self.modality_proj['depth'] = model.visual_projection
|
| 68 |
+
self.modality_scale['depth'] = model.logit_scale
|
| 69 |
+
elif c == 'tl':
|
| 70 |
+
self.modality_encoder['thermal'] = model.vision_model
|
| 71 |
+
self.modality_proj['thermal'] = model.visual_projection
|
| 72 |
+
self.modality_scale['thermal'] = model.logit_scale
|
| 73 |
+
elif c == 'il':
|
| 74 |
+
self.modality_encoder['image'] = model.vision_model
|
| 75 |
+
self.modality_proj['image'] = model.visual_projection
|
| 76 |
+
self.modality_scale['image'] = model.logit_scale
|
| 77 |
+
else:
|
| 78 |
+
raise NameError(f'No clip_type of {c}')
|
| 79 |
+
self.modality_encoder['language'] = model.text_model
|
| 80 |
+
self.modality_proj['language'] = model.text_projection
|
| 81 |
+
|
| 82 |
+
self.modality_encoder = nn.ModuleDict(self.modality_encoder)
|
| 83 |
+
self.modality_proj = nn.ModuleDict(self.modality_proj)
|
| 84 |
+
|
| 85 |
+
def forward(self, inputs):
|
| 86 |
+
outputs = {}
|
| 87 |
+
for key, value in inputs.items():
|
| 88 |
+
value = self.modality_encoder[key](**value)[1]
|
| 89 |
+
value = self.modality_proj[key](value)
|
| 90 |
+
value = value / value.norm(p=2, dim=-1, keepdim=True)
|
| 91 |
+
# if key != 'language':
|
| 92 |
+
# value = value * self.modality_scale[key].exp()
|
| 93 |
+
outputs[key] = value
|
| 94 |
+
return outputs
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
MODEL_DICT = {"ViT-L-14": "laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K",
|
| 100 |
+
"ViT-H-14": "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"}
|
| 101 |
+
CHECKPOINT_DICT = {"ViT-L-14": "models--laion--CLIP-ViT-L-14-DataComp.XL-s13B-b90K/snapshots/84c9828e63dc9a9351d1fe637c346d4c1c4db341/pytorch_model.bin",
|
| 102 |
+
"ViT-H-14": "models--laion--CLIP-ViT-H-14-laion2B-s32B-b79K/snapshots/94a64189c3535c1cb44acfcccd7b0908c1c8eb23/pytorch_model.bin"}
|
| 103 |
+
parser = argparse.ArgumentParser()
|
| 104 |
+
args = parser.parse_args()
|
| 105 |
+
args.pretrained = False
|
| 106 |
+
args.model = MODEL_DICT["ViT-L-14"]
|
| 107 |
+
args.cache_dir = 'D:/Omni-modal-valdt-audio'
|
| 108 |
+
args.video_decode_backend = 'decord'
|
| 109 |
+
# args.device = 'cpu'
|
| 110 |
+
args.device = 'cuda:0'
|
| 111 |
+
device = torch.device(args.device)
|
| 112 |
+
args.precision = None
|
| 113 |
+
args.init_temp = 0
|
| 114 |
+
args.force_patch_dropout = 0.0
|
| 115 |
+
args.add_time_attn = False
|
| 116 |
+
args.convert_to_lora = True
|
| 117 |
+
args.lora_r = 2
|
| 118 |
+
args.lora_alpha = 16
|
| 119 |
+
args.lora_dropout = 0.0 # 0.1?
|
| 120 |
+
args.num_frames = 8
|
| 121 |
+
args.clip_type = 'vl'
|
| 122 |
+
args.num_mel_bins = 1008
|
| 123 |
+
args.target_length = 112
|
| 124 |
+
args.audio_sample_rate = 16000
|
| 125 |
+
args.audio_mean = 4.5689974
|
| 126 |
+
args.audio_std = -4.2677393
|
| 127 |
+
args.max_depth = 10
|
| 128 |
+
args.image_size = 224
|
| 129 |
+
args.rank = 0
|
| 130 |
+
SET_GLOBAL_VALUE('PATCH_DROPOUT', args.force_patch_dropout)
|
| 131 |
+
SET_GLOBAL_VALUE('NUM_FRAMES', args.num_frames)
|
| 132 |
+
args.clip_type = ['il', 'vl', 'al', 'dl', 'tl']
|
| 133 |
+
model = LanguageBind(args).to(device)
|
| 134 |
+
model.eval()
|
| 135 |
+
|
| 136 |
+
modality_transform = {
|
| 137 |
+
'language': get_tokenizer(HF_HUB_PREFIX + args.model, cache_dir=args.cache_dir),
|
| 138 |
+
'video': get_video_transform(args),
|
| 139 |
+
'audio': get_audio_transform(args),
|
| 140 |
+
'depth': get_depth_transform(args),
|
| 141 |
+
'thermal': get_thermal_transform(args),
|
| 142 |
+
'image': get_image_transform(args),
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def stack_dict(x, device):
|
| 147 |
+
out_dict = {}
|
| 148 |
+
keys = list(x[0].keys())
|
| 149 |
+
for key in keys:
|
| 150 |
+
out_dict[key] = torch.stack([i[key] for i in x]).to(device)
|
| 151 |
+
return out_dict
|
| 152 |
+
|
| 153 |
+
def image_to_language(image, language):
|
| 154 |
+
inputs = {}
|
| 155 |
+
inputs['image'] = stack_dict([load_and_transform_image(image, modality_transform['image'])], device)
|
| 156 |
+
inputs['language'] = stack_dict([load_and_transform_text(language, modality_transform['language'])], device)
|
| 157 |
+
with torch.no_grad():
|
| 158 |
+
embeddings = model(inputs)
|
| 159 |
+
return (embeddings['image'] @ embeddings['language'].T).item()
|
| 160 |
+
|
| 161 |
+
def video_to_language(video, language):
|
| 162 |
+
inputs = {}
|
| 163 |
+
inputs['video'] = stack_dict([load_and_transform_video(video, modality_transform['video'])], device)
|
| 164 |
+
inputs['language'] = stack_dict([load_and_transform_text(language, modality_transform['language'])], device)
|
| 165 |
+
with torch.no_grad():
|
| 166 |
+
embeddings = model(inputs)
|
| 167 |
+
return (embeddings['video'] @ embeddings['language'].T).item()
|
| 168 |
+
|
| 169 |
+
def audio_to_language(audio, language):
|
| 170 |
+
inputs = {}
|
| 171 |
+
inputs['audio'] = stack_dict([load_and_transform_audio(audio, modality_transform['audio'])], device)
|
| 172 |
+
inputs['language'] = stack_dict([load_and_transform_text(language, modality_transform['language'])], device)
|
| 173 |
+
with torch.no_grad():
|
| 174 |
+
embeddings = model(inputs)
|
| 175 |
+
return (embeddings['audio'] @ embeddings['language'].T).item()
|
| 176 |
+
|
| 177 |
+
def depth_to_language(depth, language):
|
| 178 |
+
inputs = {}
|
| 179 |
+
inputs['depth'] = stack_dict([load_and_transform_depth(depth, modality_transform['depth'])], device)
|
| 180 |
+
inputs['language'] = stack_dict([load_and_transform_text(language, modality_transform['language'])], device)
|
| 181 |
+
with torch.no_grad():
|
| 182 |
+
embeddings = model(inputs)
|
| 183 |
+
return (embeddings['depth'] @ embeddings['language'].T).item()
|
| 184 |
+
|
| 185 |
+
def thermal_to_language(thermal, language):
|
| 186 |
+
inputs = {}
|
| 187 |
+
inputs['thermal'] = stack_dict([load_and_transform_thermal(thermal, modality_transform['thermal'])], device)
|
| 188 |
+
inputs['language'] = stack_dict([load_and_transform_text(language, modality_transform['language'])], device)
|
| 189 |
+
with torch.no_grad():
|
| 190 |
+
embeddings = model(inputs)
|
| 191 |
+
return (embeddings['thermal'] @ embeddings['language'].T).item()
|
| 192 |
+
|
| 193 |
+
code_highlight_css = (
|
| 194 |
+
"""
|
| 195 |
+
#chatbot .hll { background-color: #ffffcc }
|
| 196 |
+
#chatbot .c { color: #408080; font-style: italic }
|
| 197 |
+
#chatbot .err { border: 1px solid #FF0000 }
|
| 198 |
+
#chatbot .k { color: #008000; font-weight: bold }
|
| 199 |
+
#chatbot .o { color: #666666 }
|
| 200 |
+
#chatbot .ch { color: #408080; font-style: italic }
|
| 201 |
+
#chatbot .cm { color: #408080; font-style: italic }
|
| 202 |
+
#chatbot .cp { color: #BC7A00 }
|
| 203 |
+
#chatbot .cpf { color: #408080; font-style: italic }
|
| 204 |
+
#chatbot .c1 { color: #408080; font-style: italic }
|
| 205 |
+
#chatbot .cs { color: #408080; font-style: italic }
|
| 206 |
+
#chatbot .gd { color: #A00000 }
|
| 207 |
+
#chatbot .ge { font-style: italic }
|
| 208 |
+
#chatbot .gr { color: #FF0000 }
|
| 209 |
+
#chatbot .gh { color: #000080; font-weight: bold }
|
| 210 |
+
#chatbot .gi { color: #00A000 }
|
| 211 |
+
#chatbot .go { color: #888888 }
|
| 212 |
+
#chatbot .gp { color: #000080; font-weight: bold }
|
| 213 |
+
#chatbot .gs { font-weight: bold }
|
| 214 |
+
#chatbot .gu { color: #800080; font-weight: bold }
|
| 215 |
+
#chatbot .gt { color: #0044DD }
|
| 216 |
+
#chatbot .kc { color: #008000; font-weight: bold }
|
| 217 |
+
#chatbot .kd { color: #008000; font-weight: bold }
|
| 218 |
+
#chatbot .kn { color: #008000; font-weight: bold }
|
| 219 |
+
#chatbot .kp { color: #008000 }
|
| 220 |
+
#chatbot .kr { color: #008000; font-weight: bold }
|
| 221 |
+
#chatbot .kt { color: #B00040 }
|
| 222 |
+
#chatbot .m { color: #666666 }
|
| 223 |
+
#chatbot .s { color: #BA2121 }
|
| 224 |
+
#chatbot .na { color: #7D9029 }
|
| 225 |
+
#chatbot .nb { color: #008000 }
|
| 226 |
+
#chatbot .nc { color: #0000FF; font-weight: bold }
|
| 227 |
+
#chatbot .no { color: #880000 }
|
| 228 |
+
#chatbot .nd { color: #AA22FF }
|
| 229 |
+
#chatbot .ni { color: #999999; font-weight: bold }
|
| 230 |
+
#chatbot .ne { color: #D2413A; font-weight: bold }
|
| 231 |
+
#chatbot .nf { color: #0000FF }
|
| 232 |
+
#chatbot .nl { color: #A0A000 }
|
| 233 |
+
#chatbot .nn { color: #0000FF; font-weight: bold }
|
| 234 |
+
#chatbot .nt { color: #008000; font-weight: bold }
|
| 235 |
+
#chatbot .nv { color: #19177C }
|
| 236 |
+
#chatbot .ow { color: #AA22FF; font-weight: bold }
|
| 237 |
+
#chatbot .w { color: #bbbbbb }
|
| 238 |
+
#chatbot .mb { color: #666666 }
|
| 239 |
+
#chatbot .mf { color: #666666 }
|
| 240 |
+
#chatbot .mh { color: #666666 }
|
| 241 |
+
#chatbot .mi { color: #666666 }
|
| 242 |
+
#chatbot .mo { color: #666666 }
|
| 243 |
+
#chatbot .sa { color: #BA2121 }
|
| 244 |
+
#chatbot .sb { color: #BA2121 }
|
| 245 |
+
#chatbot .sc { color: #BA2121 }
|
| 246 |
+
#chatbot .dl { color: #BA2121 }
|
| 247 |
+
#chatbot .sd { color: #BA2121; font-style: italic }
|
| 248 |
+
#chatbot .s2 { color: #BA2121 }
|
| 249 |
+
#chatbot .se { color: #BB6622; font-weight: bold }
|
| 250 |
+
#chatbot .sh { color: #BA2121 }
|
| 251 |
+
#chatbot .si { color: #BB6688; font-weight: bold }
|
| 252 |
+
#chatbot .sx { color: #008000 }
|
| 253 |
+
#chatbot .sr { color: #BB6688 }
|
| 254 |
+
#chatbot .s1 { color: #BA2121 }
|
| 255 |
+
#chatbot .ss { color: #19177C }
|
| 256 |
+
#chatbot .bp { color: #008000 }
|
| 257 |
+
#chatbot .fm { color: #0000FF }
|
| 258 |
+
#chatbot .vc { color: #19177C }
|
| 259 |
+
#chatbot .vg { color: #19177C }
|
| 260 |
+
#chatbot .vi { color: #19177C }
|
| 261 |
+
#chatbot .vm { color: #19177C }
|
| 262 |
+
#chatbot .il { color: #666666 }
|
| 263 |
+
""")
|
| 264 |
+
#.highlight { background: #f8f8f8; }
|
| 265 |
+
|
| 266 |
+
title_markdown = ("""
|
| 267 |
+
<h1 align="center"><a href="https://github.com/PKU-YuanGroup/LanguageBind"><img src="https://z1.ax1x.com/2023/10/04/pPOBSL6.png", alt="LanguageBind🚀" border="0" style="margin: 0 auto; height: 200px;" /></a> </h1>
|
| 268 |
+
|
| 269 |
+
<h2 align="center"> LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment </h2>
|
| 270 |
+
|
| 271 |
+
<h5 align="center"> If you like our project, please give us a star ✨ on Github for latest update. </h2>
|
| 272 |
+
|
| 273 |
+
<div align="center">
|
| 274 |
+
<div style="display:flex; gap: 0.25rem;" align="center">
|
| 275 |
+
<a href='https://github.com/PKU-YuanGroup/LanguageBind'><img src='https://img.shields.io/badge/Github-Code-blue'></a>
|
| 276 |
+
<a href="https://arxiv.org/pdf/2310.01852.pdf"><img src="https://img.shields.io/badge/Arxiv-2310.01852-red"></a>
|
| 277 |
+
<a href='https://github.com/PKU-YuanGroup/LanguageBind/stargazers'><img src='https://img.shields.io/github/stars/PKU-YuanGroup/LanguageBind.svg?style=social'></a>
|
| 278 |
+
</div>
|
| 279 |
+
</div>
|
| 280 |
+
""")
|
| 281 |
+
css = code_highlight_css + """
|
| 282 |
+
pre {
|
| 283 |
+
white-space: pre-wrap; /* Since CSS 2.1 */
|
| 284 |
+
white-space: -moz-pre-wrap; /* Mozilla, since 1999 */
|
| 285 |
+
white-space: -pre-wrap; /* Opera 4-6 */
|
| 286 |
+
white-space: -o-pre-wrap; /* Opera 7 */
|
| 287 |
+
word-wrap: break-word; /* Internet Explorer 5.5+ */
|
| 288 |
+
}
|
| 289 |
+
"""
|
| 290 |
+
|
| 291 |
+
with gr.Blocks(title="LanguageBind🚀", css=css) as demo:
|
| 292 |
+
gr.Markdown(title_markdown)
|
| 293 |
+
with gr.Row():
|
| 294 |
+
with gr.Column():
|
| 295 |
+
image = gr.Image(type="filepath", height=224, width=224, label='Image Input')
|
| 296 |
+
language_i = gr.Textbox(lines=2, label='Text Input')
|
| 297 |
+
out_i = gr.Textbox(label='Similarity of Image to Text')
|
| 298 |
+
b_i = gr.Button("Calculate similarity of Image to Text")
|
| 299 |
+
with gr.Column():
|
| 300 |
+
video = gr.Video(type="filepath", height=224, width=224, label='Video Input')
|
| 301 |
+
language_v = gr.Textbox(lines=2, label='Text Input')
|
| 302 |
+
out_v = gr.Textbox(label='Similarity of Video to Text')
|
| 303 |
+
b_v = gr.Button("Calculate similarity of Video to Text")
|
| 304 |
+
with gr.Column():
|
| 305 |
+
audio = gr.Audio(type="filepath", label='Audio Input')
|
| 306 |
+
language_a = gr.Textbox(lines=2, label='Text Input')
|
| 307 |
+
out_a = gr.Textbox(label='Similarity of Audio to Text')
|
| 308 |
+
b_a = gr.Button("Calculate similarity of Audio to Text")
|
| 309 |
+
with gr.Row():
|
| 310 |
+
with gr.Column():
|
| 311 |
+
depth = gr.Image(type="filepath", height=224, width=224, label='Depth Input, Need a .png file, 16 bit, with values ranging from 0-10000 (representing 0-10 metres, but 1000 times)')
|
| 312 |
+
language_d = gr.Textbox(lines=2, label='Text Input')
|
| 313 |
+
out_d = gr.Textbox(label='Similarity of Depth to Text')
|
| 314 |
+
b_d = gr.Button("Calculate similarity of Depth to Text")
|
| 315 |
+
with gr.Column():
|
| 316 |
+
thermal = gr.Image(type="filepath", height=224, width=224, label='Thermal Input')
|
| 317 |
+
language_t = gr.Textbox(lines=2, label='Text Input')
|
| 318 |
+
out_t = gr.Textbox(label='Similarity of Thermal to Text')
|
| 319 |
+
b_t = gr.Button("Calculate similarity of Thermal to Text")
|
| 320 |
+
|
| 321 |
+
b_i.click(image_to_language, inputs=[image, language_i], outputs=out_i)
|
| 322 |
+
b_a.click(audio_to_language, inputs=[audio, language_a], outputs=out_a)
|
| 323 |
+
b_v.click(video_to_language, inputs=[video, language_v], outputs=out_v)
|
| 324 |
+
b_d.click(depth_to_language, inputs=[depth, language_d], outputs=out_d)
|
| 325 |
+
b_t.click(thermal_to_language, inputs=[thermal, language_t], outputs=out_t)
|
| 326 |
+
|
| 327 |
+
demo.launch()
|
assets/languagebind.jpg
ADDED
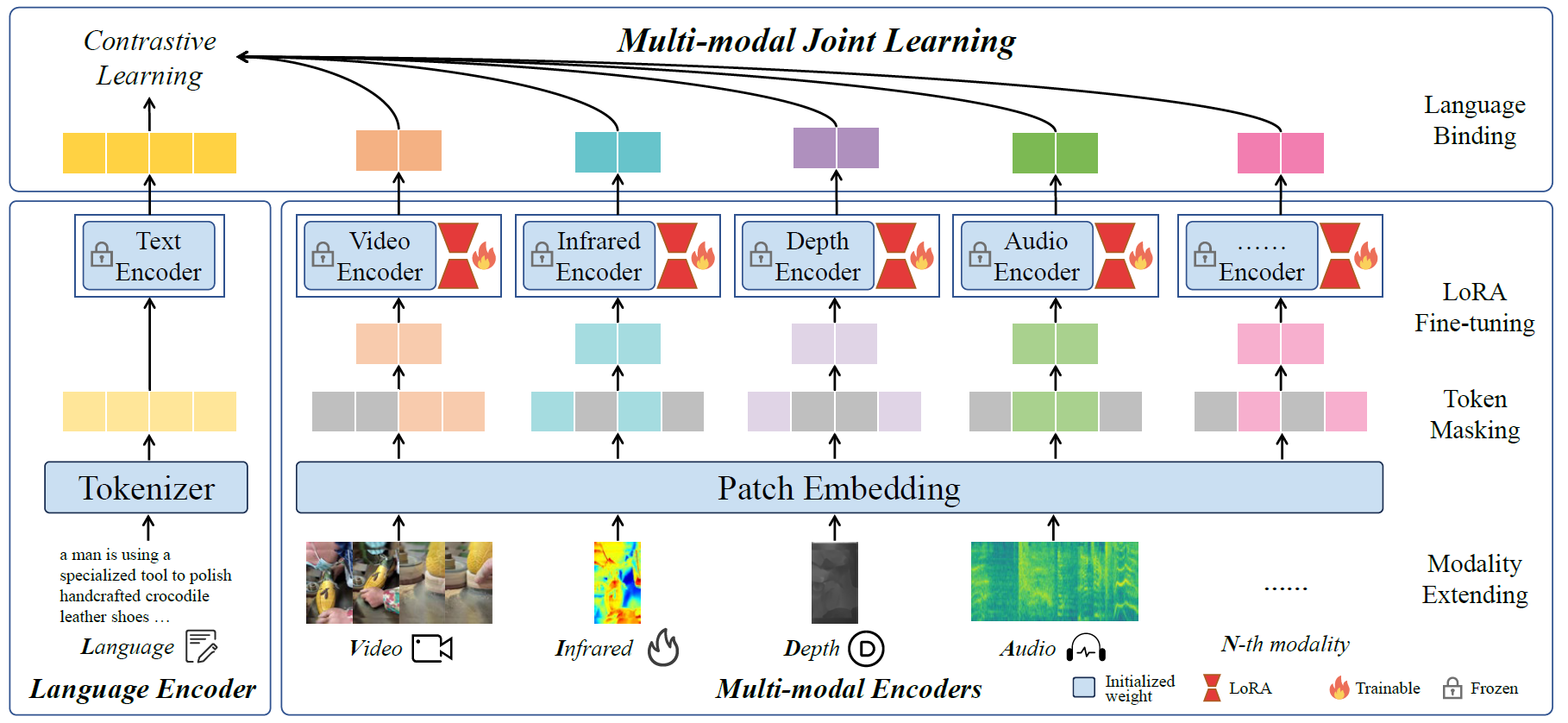
|
assets/logo.png
ADDED
|
|
assets/res1.jpg
ADDED

|
assets/res2.jpg
ADDED
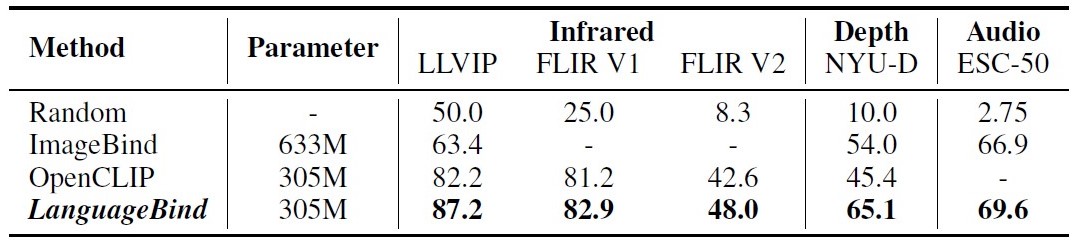
|
d_cls/__pycache__/precision.cpython-38.pyc
ADDED
|
Binary file (582 Bytes). View file
|
|
|
d_cls/__pycache__/zero_shot.cpython-38.pyc
ADDED
|
Binary file (2.81 kB). View file
|
|
|
d_cls/__pycache__/zero_shot_classifier.cpython-38.pyc
ADDED
|
Binary file (4.25 kB). View file
|
|
|
d_cls/__pycache__/zero_shot_metadata.cpython-38.pyc
ADDED
|
Binary file (10.9 kB). View file
|
|
|
d_cls/__pycache__/zeroshot_cls.cpython-38.pyc
ADDED
|
Binary file (1.44 kB). View file
|
|
|
d_cls/cp_zero_shot_metadata.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
|
| 5 |
+
OPENAI_IMAGENET_TEMPLATES = (
|
| 6 |
+
lambda c: f'a bad photo of a {c}.',
|
| 7 |
+
lambda c: f'a photo of many {c}.',
|
| 8 |
+
lambda c: f'a sculpture of a {c}.',
|
| 9 |
+
lambda c: f'a photo of the hard to see {c}.',
|
| 10 |
+
lambda c: f'a low resolution photo of the {c}.',
|
| 11 |
+
lambda c: f'a rendering of a {c}.',
|
| 12 |
+
lambda c: f'graffiti of a {c}.',
|
| 13 |
+
lambda c: f'a bad photo of the {c}.',
|
| 14 |
+
lambda c: f'a cropped photo of the {c}.',
|
| 15 |
+
lambda c: f'a tattoo of a {c}.',
|
| 16 |
+
lambda c: f'the embroidered {c}.',
|
| 17 |
+
lambda c: f'a photo of a hard to see {c}.',
|
| 18 |
+
lambda c: f'a bright photo of a {c}.',
|
| 19 |
+
lambda c: f'a photo of a clean {c}.',
|
| 20 |
+
lambda c: f'a photo of a dirty {c}.',
|
| 21 |
+
lambda c: f'a dark photo of the {c}.',
|
| 22 |
+
lambda c: f'a drawing of a {c}.',
|
| 23 |
+
lambda c: f'a photo of my {c}.',
|
| 24 |
+
lambda c: f'the plastic {c}.',
|
| 25 |
+
lambda c: f'a photo of the cool {c}.',
|
| 26 |
+
lambda c: f'a close-up photo of a {c}.',
|
| 27 |
+
lambda c: f'a black and white photo of the {c}.',
|
| 28 |
+
lambda c: f'a painting of the {c}.',
|
| 29 |
+
lambda c: f'a painting of a {c}.',
|
| 30 |
+
lambda c: f'a pixelated photo of the {c}.',
|
| 31 |
+
lambda c: f'a sculpture of the {c}.',
|
| 32 |
+
lambda c: f'a bright photo of the {c}.',
|
| 33 |
+
lambda c: f'a cropped photo of a {c}.',
|
| 34 |
+
lambda c: f'a plastic {c}.',
|
| 35 |
+
lambda c: f'a photo of the dirty {c}.',
|
| 36 |
+
lambda c: f'a jpeg corrupted photo of a {c}.',
|
| 37 |
+
lambda c: f'a blurry photo of the {c}.',
|
| 38 |
+
lambda c: f'a photo of the {c}.',
|
| 39 |
+
lambda c: f'a good photo of the {c}.',
|
| 40 |
+
lambda c: f'a rendering of the {c}.',
|
| 41 |
+
lambda c: f'a {c} in a video game.',
|
| 42 |
+
lambda c: f'a photo of one {c}.',
|
| 43 |
+
lambda c: f'a doodle of a {c}.',
|
| 44 |
+
lambda c: f'a close-up photo of the {c}.',
|
| 45 |
+
lambda c: f'a photo of a {c}.',
|
| 46 |
+
lambda c: f'the origami {c}.',
|
| 47 |
+
lambda c: f'the {c} in a video game.',
|
| 48 |
+
lambda c: f'a sketch of a {c}.',
|
| 49 |
+
lambda c: f'a doodle of the {c}.',
|
| 50 |
+
lambda c: f'a origami {c}.',
|
| 51 |
+
lambda c: f'a low resolution photo of a {c}.',
|
| 52 |
+
lambda c: f'the toy {c}.',
|
| 53 |
+
lambda c: f'a rendition of the {c}.',
|
| 54 |
+
lambda c: f'a photo of the clean {c}.',
|
| 55 |
+
lambda c: f'a photo of a large {c}.',
|
| 56 |
+
lambda c: f'a rendition of a {c}.',
|
| 57 |
+
lambda c: f'a photo of a nice {c}.',
|
| 58 |
+
lambda c: f'a photo of a weird {c}.',
|
| 59 |
+
lambda c: f'a blurry photo of a {c}.',
|
| 60 |
+
lambda c: f'a cartoon {c}.',
|
| 61 |
+
lambda c: f'art of a {c}.',
|
| 62 |
+
lambda c: f'a sketch of the {c}.',
|
| 63 |
+
lambda c: f'a embroidered {c}.',
|
| 64 |
+
lambda c: f'a pixelated photo of a {c}.',
|
| 65 |
+
lambda c: f'itap of the {c}.',
|
| 66 |
+
lambda c: f'a jpeg corrupted photo of the {c}.',
|
| 67 |
+
lambda c: f'a good photo of a {c}.',
|
| 68 |
+
lambda c: f'a plushie {c}.',
|
| 69 |
+
lambda c: f'a photo of the nice {c}.',
|
| 70 |
+
lambda c: f'a photo of the small {c}.',
|
| 71 |
+
lambda c: f'a photo of the weird {c}.',
|
| 72 |
+
lambda c: f'the cartoon {c}.',
|
| 73 |
+
lambda c: f'art of the {c}.',
|
| 74 |
+
lambda c: f'a drawing of the {c}.',
|
| 75 |
+
lambda c: f'a photo of the large {c}.',
|
| 76 |
+
lambda c: f'a black and white photo of a {c}.',
|
| 77 |
+
lambda c: f'the plushie {c}.',
|
| 78 |
+
lambda c: f'a dark photo of a {c}.',
|
| 79 |
+
lambda c: f'itap of a {c}.',
|
| 80 |
+
lambda c: f'graffiti of the {c}.',
|
| 81 |
+
lambda c: f'a toy {c}.',
|
| 82 |
+
lambda c: f'itap of my {c}.',
|
| 83 |
+
lambda c: f'a photo of a cool {c}.',
|
| 84 |
+
lambda c: f'a photo of a small {c}.',
|
| 85 |
+
lambda c: f'a tattoo of the {c}.',
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# a much smaller subset of above prompts
|
| 90 |
+
# from https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb
|
| 91 |
+
SIMPLE_IMAGENET_TEMPLATES = (
|
| 92 |
+
lambda c: f'itap of a {c}.',
|
| 93 |
+
lambda c: f'a bad photo of the {c}.',
|
| 94 |
+
lambda c: f'a origami {c}.',
|
| 95 |
+
lambda c: f'a photo of the large {c}.',
|
| 96 |
+
lambda c: f'a {c} in a video game.',
|
| 97 |
+
lambda c: f'art of the {c}.',
|
| 98 |
+
lambda c: f'a photo of the small {c}.',
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
IMAGENET_CLASSNAMES = (
|
| 103 |
+
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
CLASSNAMES = {
|
| 108 |
+
'NYUV2': (
|
| 109 |
+
"bathroom", "bedroom", "bookstore", "classroom", "dining room",
|
| 110 |
+
"home office", "kitchen", "living room", "office", "others"
|
| 111 |
+
),
|
| 112 |
+
'SUNRGBD': (
|
| 113 |
+
"bathroom", "bedroom", "classroom", "computer room", "conference room", "corridor", "dining area",
|
| 114 |
+
"dining room", "discussion area", "furniture store", "home office", "kitchen", "lab", "lecture theatre",
|
| 115 |
+
"library", "living room", "office", "rest space", "study space"
|
| 116 |
+
),
|
| 117 |
+
}
|
d_cls/datasets.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from data.build_datasets import DataInfo
|
| 5 |
+
from data.process_depth import get_depth_transform, opencv_loader
|
| 6 |
+
from torchvision import datasets
|
| 7 |
+
|
| 8 |
+
def get_depth_dataset(args):
|
| 9 |
+
data_path = args.depth_data_path
|
| 10 |
+
transform = get_depth_transform(args)
|
| 11 |
+
dataset = datasets.ImageFolder(data_path, transform=transform, loader=opencv_loader)
|
| 12 |
+
|
| 13 |
+
dataloader = torch.utils.data.DataLoader(
|
| 14 |
+
dataset,
|
| 15 |
+
batch_size=args.batch_size,
|
| 16 |
+
num_workers=args.workers,
|
| 17 |
+
sampler=None,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
return DataInfo(dataloader=dataloader, sampler=None)
|
d_cls/precision.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from contextlib import suppress
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def get_autocast(precision):
|
| 6 |
+
if precision == 'amp':
|
| 7 |
+
return torch.cuda.amp.autocast
|
| 8 |
+
elif precision == 'amp_bfloat16' or precision == 'amp_bf16':
|
| 9 |
+
# amp_bfloat16 is more stable than amp float16 for clip training
|
| 10 |
+
return lambda: torch.cuda.amp.autocast(dtype=torch.bfloat16)
|
| 11 |
+
else:
|
| 12 |
+
return suppress
|
d_cls/zero_shot.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
from open_clip import get_input_dtype, get_tokenizer
|
| 8 |
+
from open_clip.factory import HF_HUB_PREFIX
|
| 9 |
+
from .precision import get_autocast
|
| 10 |
+
from .zero_shot_classifier import build_zero_shot_classifier
|
| 11 |
+
from .zero_shot_metadata import CLASSNAMES, OPENAI_IMAGENET_TEMPLATES
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def accuracy(output, target, topk=(1,)):
|
| 15 |
+
pred = output.topk(max(topk), 1, True, True)[1].t()
|
| 16 |
+
correct = pred.eq(target.view(1, -1).expand_as(pred))
|
| 17 |
+
return [float(correct[:k].reshape(-1).float().sum(0, keepdim=True).cpu().numpy()) for k in topk]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def run(model, classifier, dataloader, args):
|
| 21 |
+
autocast = get_autocast(args.precision)
|
| 22 |
+
input_dtype = get_input_dtype(args.precision)
|
| 23 |
+
|
| 24 |
+
with torch.no_grad():
|
| 25 |
+
top1, top5, n = 0., 0., 0.
|
| 26 |
+
for images, target in tqdm(dataloader, unit_scale=args.batch_size):
|
| 27 |
+
images = images.to(device=args.device, dtype=input_dtype)
|
| 28 |
+
images = images.unsqueeze(2)
|
| 29 |
+
target = target.to(args.device)
|
| 30 |
+
|
| 31 |
+
with autocast():
|
| 32 |
+
# predict
|
| 33 |
+
output = model(image=images)
|
| 34 |
+
image_features = output['image_features'] if isinstance(output, dict) else output[0]
|
| 35 |
+
logits = 100. * image_features @ classifier
|
| 36 |
+
|
| 37 |
+
# measure accuracy
|
| 38 |
+
acc1, acc5 = accuracy(logits, target, topk=(1, 5))
|
| 39 |
+
top1 += acc1
|
| 40 |
+
top5 += acc5
|
| 41 |
+
n += images.size(0)
|
| 42 |
+
|
| 43 |
+
top1 = (top1 / n)
|
| 44 |
+
top5 = (top5 / n)
|
| 45 |
+
return top1, top5
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def zero_shot_eval(model, data, epoch, args):
|
| 49 |
+
temp_val_d_cls_data = args.val_d_cls_data
|
| 50 |
+
args.val_d_cls_data = list(data.keys())
|
| 51 |
+
assert len(args.val_d_cls_data) == 1
|
| 52 |
+
args.val_d_cls_data = args.val_d_cls_data[0]
|
| 53 |
+
|
| 54 |
+
if args.val_d_cls_data not in data:
|
| 55 |
+
return {}
|
| 56 |
+
if args.zeroshot_frequency == 0:
|
| 57 |
+
return {}
|
| 58 |
+
if (epoch % args.zeroshot_frequency) != 0 and epoch != args.epochs:
|
| 59 |
+
return {}
|
| 60 |
+
if args.distributed and not args.horovod:
|
| 61 |
+
model = model.module
|
| 62 |
+
|
| 63 |
+
logging.info(f'Starting zero-shot {args.val_d_cls_data.upper()}.')
|
| 64 |
+
|
| 65 |
+
logging.info('Building zero-shot classifier')
|
| 66 |
+
autocast = get_autocast(args.precision)
|
| 67 |
+
with autocast():
|
| 68 |
+
tokenizer = get_tokenizer(HF_HUB_PREFIX+args.model, cache_dir=args.cache_dir)
|
| 69 |
+
# tokenizer = get_tokenizer("ViT-L-14")
|
| 70 |
+
classifier = build_zero_shot_classifier(
|
| 71 |
+
model,
|
| 72 |
+
tokenizer=tokenizer,
|
| 73 |
+
classnames=CLASSNAMES[args.val_d_cls_data],
|
| 74 |
+
templates=OPENAI_IMAGENET_TEMPLATES,
|
| 75 |
+
num_classes_per_batch=10,
|
| 76 |
+
device=args.device,
|
| 77 |
+
use_tqdm=True,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
logging.info('Using classifier')
|
| 81 |
+
results = {}
|
| 82 |
+
if args.val_d_cls_data in data:
|
| 83 |
+
top1, top5 = run(model, classifier, data[args.val_d_cls_data].dataloader, args)
|
| 84 |
+
results[f'{args.val_d_cls_data}-zeroshot-val-top1'] = top1
|
| 85 |
+
results[f'{args.val_d_cls_data}-zeroshot-val-top5'] = top5
|
| 86 |
+
|
| 87 |
+
logging.info(f'Finished zero-shot {args.val_d_cls_data.upper()}.')
|
| 88 |
+
|
| 89 |
+
args.val_d_cls_data = temp_val_d_cls_data
|
| 90 |
+
return results
|
d_cls/zero_shot_classifier.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from itertools import islice
|
| 3 |
+
from typing import Callable, List, Optional, Sequence, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def batched(iterable, n):
|
| 10 |
+
"""Batch data into lists of length *n*. The last batch may be shorter.
|
| 11 |
+
NOTE based on more-itertools impl, to be replaced by python 3.12 itertools.batched impl
|
| 12 |
+
"""
|
| 13 |
+
it = iter(iterable)
|
| 14 |
+
while True:
|
| 15 |
+
batch = list(islice(it, n))
|
| 16 |
+
if not batch:
|
| 17 |
+
break
|
| 18 |
+
yield batch
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def build_zero_shot_classifier(
|
| 22 |
+
model,
|
| 23 |
+
tokenizer,
|
| 24 |
+
classnames: Sequence[str],
|
| 25 |
+
templates: Sequence[Union[Callable, str]],
|
| 26 |
+
num_classes_per_batch: Optional[int] = 10,
|
| 27 |
+
device: Union[str, torch.device] = 'cpu',
|
| 28 |
+
use_tqdm: bool = False,
|
| 29 |
+
):
|
| 30 |
+
""" Build zero-shot classifier weights by iterating over class names in batches
|
| 31 |
+
Args:
|
| 32 |
+
model: CLIP model instance
|
| 33 |
+
tokenizer: CLIP tokenizer instance
|
| 34 |
+
classnames: A sequence of class (label) names
|
| 35 |
+
templates: A sequence of callables or format() friendly strings to produce templates per class name
|
| 36 |
+
num_classes_per_batch: The number of classes to batch together in each forward, all if None
|
| 37 |
+
device: Device to use.
|
| 38 |
+
use_tqdm: Enable TQDM progress bar.
|
| 39 |
+
"""
|
| 40 |
+
assert isinstance(templates, Sequence) and len(templates) > 0
|
| 41 |
+
assert isinstance(classnames, Sequence) and len(classnames) > 0
|
| 42 |
+
use_format = isinstance(templates[0], str)
|
| 43 |
+
num_templates = len(templates)
|
| 44 |
+
num_classes = len(classnames)
|
| 45 |
+
if use_tqdm:
|
| 46 |
+
import tqdm
|
| 47 |
+
num_iter = 1 if num_classes_per_batch is None else ((num_classes - 1) // num_classes_per_batch + 1)
|
| 48 |
+
iter_wrap = partial(tqdm.tqdm, total=num_iter, unit_scale=num_classes_per_batch)
|
| 49 |
+
else:
|
| 50 |
+
iter_wrap = iter
|
| 51 |
+
|
| 52 |
+
def _process_batch(batch_classnames):
|
| 53 |
+
num_batch_classes = len(batch_classnames)
|
| 54 |
+
texts = [template.format(c) if use_format else template(c) for c in batch_classnames for template in templates]
|
| 55 |
+
input_ids, attention_mask = tokenizer(texts)
|
| 56 |
+
input_ids, attention_mask = input_ids.to(device), attention_mask.to(device)
|
| 57 |
+
class_embeddings = F.normalize(model.encode_text(input_ids, attention_mask), dim=-1)
|
| 58 |
+
class_embeddings = class_embeddings.reshape(num_batch_classes, num_templates, -1).mean(dim=1)
|
| 59 |
+
class_embeddings = class_embeddings / class_embeddings.norm(dim=1, keepdim=True)
|
| 60 |
+
class_embeddings = class_embeddings.T
|
| 61 |
+
return class_embeddings
|
| 62 |
+
|
| 63 |
+
with torch.no_grad():
|
| 64 |
+
if num_classes_per_batch:
|
| 65 |
+
batched_embeds = [_process_batch(batch) for batch in iter_wrap(batched(classnames, num_classes_per_batch))]
|
| 66 |
+
zeroshot_weights = torch.cat(batched_embeds, dim=1)
|
| 67 |
+
else:
|
| 68 |
+
zeroshot_weights = _process_batch(classnames)
|
| 69 |
+
return zeroshot_weights
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def build_zero_shot_classifier_legacy(
|
| 73 |
+
model,
|
| 74 |
+
tokenizer,
|
| 75 |
+
classnames: Sequence[str],
|
| 76 |
+
templates: Sequence[Union[Callable, str]],
|
| 77 |
+
device: Union[str, torch.device] = 'cpu',
|
| 78 |
+
use_tqdm: bool = False,
|
| 79 |
+
):
|
| 80 |
+
""" Build zero-shot classifier weights by iterating over class names 1 by 1
|
| 81 |
+
Args:
|
| 82 |
+
model: CLIP model instance
|
| 83 |
+
tokenizer: CLIP tokenizer instance
|
| 84 |
+
classnames: A sequence of class (label) names
|
| 85 |
+
templates: A sequence of callables or format() friendly strings to produce templates per class name
|
| 86 |
+
device: Device to use.
|
| 87 |
+
use_tqdm: Enable TQDM progress bar.
|
| 88 |
+
"""
|
| 89 |
+
assert isinstance(templates, Sequence) and len(templates) > 0
|
| 90 |
+
assert isinstance(classnames, Sequence) and len(classnames) > 0
|
| 91 |
+
if use_tqdm:
|
| 92 |
+
import tqdm
|
| 93 |
+
iter_wrap = tqdm.tqdm
|
| 94 |
+
else:
|
| 95 |
+
iter_wrap = iter
|
| 96 |
+
|
| 97 |
+
use_format = isinstance(templates[0], str)
|
| 98 |
+
|
| 99 |
+
with torch.no_grad():
|
| 100 |
+
zeroshot_weights = []
|
| 101 |
+
for classname in iter_wrap(classnames):
|
| 102 |
+
texts = [template.format(classname) if use_format else template(classname) for template in templates]
|
| 103 |
+
texts = tokenizer(texts).to(device) # tokenize
|
| 104 |
+
class_embeddings = model.encode_text(texts)
|
| 105 |
+
class_embedding = F.normalize(class_embeddings, dim=-1).mean(dim=0)
|
| 106 |
+
class_embedding /= class_embedding.norm()
|
| 107 |
+
zeroshot_weights.append(class_embedding)
|
| 108 |
+
zeroshot_weights = torch.stack(zeroshot_weights, dim=1).to(device)
|
| 109 |
+
|
| 110 |
+
return zeroshot_weights
|
| 111 |
+
|
d_cls/zero_shot_metadata.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
|
| 5 |
+
OPENAI_IMAGENET_TEMPLATES = (
|
| 6 |
+
lambda c: f'a bad depth photo of a {c}.',
|
| 7 |
+
lambda c: f'a depth photo of many {c}.',
|
| 8 |
+
lambda c: f'a sculpture of a {c}.',
|
| 9 |
+
lambda c: f'a depth photo of the hard to see {c}.',
|
| 10 |
+
lambda c: f'a low resolution depth photo of the {c}.',
|
| 11 |
+
lambda c: f'a rendering of a {c}.',
|
| 12 |
+
lambda c: f'graffiti of a {c}.',
|
| 13 |
+
lambda c: f'a bad depth photo of the {c}.',
|
| 14 |
+
lambda c: f'a cropped depth photo of the {c}.',
|
| 15 |
+
lambda c: f'a tattoo of a {c}.',
|
| 16 |
+
lambda c: f'the embroidered {c}.',
|
| 17 |
+
lambda c: f'a depth photo of a hard to see {c}.',
|
| 18 |
+
lambda c: f'a bright depth photo of a {c}.',
|
| 19 |
+
lambda c: f'a depth photo of a clean {c}.',
|
| 20 |
+
lambda c: f'a depth photo of a dirty {c}.',
|
| 21 |
+
lambda c: f'a dark depth photo of the {c}.',
|
| 22 |
+
lambda c: f'a drawing of a {c}.',
|
| 23 |
+
lambda c: f'a depth photo of my {c}.',
|
| 24 |
+
lambda c: f'the plastic {c}.',
|
| 25 |
+
lambda c: f'a depth photo of the cool {c}.',
|
| 26 |
+
lambda c: f'a close-up depth photo of a {c}.',
|
| 27 |
+
lambda c: f'a black and white depth photo of the {c}.',
|
| 28 |
+
lambda c: f'a painting of the {c}.',
|
| 29 |
+
lambda c: f'a painting of a {c}.',
|
| 30 |
+
lambda c: f'a pixelated depth photo of the {c}.',
|
| 31 |
+
lambda c: f'a sculpture of the {c}.',
|
| 32 |
+
lambda c: f'a bright depth photo of the {c}.',
|
| 33 |
+
lambda c: f'a cropped depth photo of a {c}.',
|
| 34 |
+
lambda c: f'a plastic {c}.',
|
| 35 |
+
lambda c: f'a depth photo of the dirty {c}.',
|
| 36 |
+
lambda c: f'a jpeg corrupted depth photo of a {c}.',
|
| 37 |
+
lambda c: f'a blurry depth photo of the {c}.',
|
| 38 |
+
lambda c: f'a depth photo of the {c}.',
|
| 39 |
+
lambda c: f'a good depth photo of the {c}.',
|
| 40 |
+
lambda c: f'a rendering of the {c}.',
|
| 41 |
+
lambda c: f'a {c} in a video game.',
|
| 42 |
+
lambda c: f'a depth photo of one {c}.',
|
| 43 |
+
lambda c: f'a doodle of a {c}.',
|
| 44 |
+
lambda c: f'a close-up depth photo of the {c}.',
|
| 45 |
+
lambda c: f'a depth photo of a {c}.',
|
| 46 |
+
lambda c: f'the origami {c}.',
|
| 47 |
+
lambda c: f'the {c} in a video game.',
|
| 48 |
+
lambda c: f'a sketch of a {c}.',
|
| 49 |
+
lambda c: f'a doodle of the {c}.',
|
| 50 |
+
lambda c: f'a origami {c}.',
|
| 51 |
+
lambda c: f'a low resolution depth photo of a {c}.',
|
| 52 |
+
lambda c: f'the toy {c}.',
|
| 53 |
+
lambda c: f'a rendition of the {c}.',
|
| 54 |
+
lambda c: f'a depth photo of the clean {c}.',
|
| 55 |
+
lambda c: f'a depth photo of a large {c}.',
|
| 56 |
+
lambda c: f'a rendition of a {c}.',
|
| 57 |
+
lambda c: f'a depth photo of a nice {c}.',
|
| 58 |
+
lambda c: f'a depth photo of a weird {c}.',
|
| 59 |
+
lambda c: f'a blurry depth photo of a {c}.',
|
| 60 |
+
lambda c: f'a cartoon {c}.',
|
| 61 |
+
lambda c: f'art of a {c}.',
|
| 62 |
+
lambda c: f'a sketch of the {c}.',
|
| 63 |
+
lambda c: f'a embroidered {c}.',
|
| 64 |
+
lambda c: f'a pixelated depth photo of a {c}.',
|
| 65 |
+
lambda c: f'itap of the {c}.',
|
| 66 |
+
lambda c: f'a jpeg corrupted depth photo of the {c}.',
|
| 67 |
+
lambda c: f'a good depth photo of a {c}.',
|
| 68 |
+
lambda c: f'a plushie {c}.',
|
| 69 |
+
lambda c: f'a depth photo of the nice {c}.',
|
| 70 |
+
lambda c: f'a depth photo of the small {c}.',
|
| 71 |
+
lambda c: f'a depth photo of the weird {c}.',
|
| 72 |
+
lambda c: f'the cartoon {c}.',
|
| 73 |
+
lambda c: f'art of the {c}.',
|
| 74 |
+
lambda c: f'a drawing of the {c}.',
|
| 75 |
+
lambda c: f'a depth photo of the large {c}.',
|
| 76 |
+
lambda c: f'a black and white depth photo of a {c}.',
|
| 77 |
+
lambda c: f'the plushie {c}.',
|
| 78 |
+
lambda c: f'a dark depth photo of a {c}.',
|
| 79 |
+
lambda c: f'itap of a {c}.',
|
| 80 |
+
lambda c: f'graffiti of the {c}.',
|
| 81 |
+
lambda c: f'a toy {c}.',
|
| 82 |
+
lambda c: f'itap of my {c}.',
|
| 83 |
+
lambda c: f'a depth photo of a cool {c}.',
|
| 84 |
+
lambda c: f'a depth photo of a small {c}.',
|
| 85 |
+
lambda c: f'a tattoo of the {c}.',
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# a much smaller subset of above prompts
|
| 90 |
+
# from https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb
|
| 91 |
+
SIMPLE_IMAGENET_TEMPLATES = (
|
| 92 |
+
lambda c: f'itap of a {c}.',
|
| 93 |
+
lambda c: f'a bad depth photo of the {c}.',
|
| 94 |
+
lambda c: f'a origami {c}.',
|
| 95 |
+
lambda c: f'a depth photo of the large {c}.',
|
| 96 |
+
lambda c: f'a {c} in a video game.',
|
| 97 |
+
lambda c: f'art of the {c}.',
|
| 98 |
+
lambda c: f'a depth photo of the small {c}.',
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
IMAGENET_CLASSNAMES = (
|
| 103 |
+
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
CLASSNAMES = {
|
| 108 |
+
'NYUV2': (
|
| 109 |
+
"bathroom", "bedroom", "bookstore", "classroom", "dining room",
|
| 110 |
+
"home office", "kitchen", "living room", "office", "others"
|
| 111 |
+
),
|
| 112 |
+
'SUNRGBD': (
|
| 113 |
+
"bathroom", "bedroom", "classroom", "computer room", "conference room", "corridor", "dining area",
|
| 114 |
+
"dining room", "discussion area", "furniture store", "home office", "kitchen", "lab", "lecture theatre",
|
| 115 |
+
"library", "living room", "office", "rest space", "study space"
|
| 116 |
+
),
|
| 117 |
+
}
|
d_cls/zeroshot_cls.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
from training.distributed import is_master
|
| 6 |
+
from .zero_shot import zero_shot_eval
|
| 7 |
+
|
| 8 |
+
try:
|
| 9 |
+
import wandb
|
| 10 |
+
except ImportError:
|
| 11 |
+
wandb = None
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def evaluate_d_cls(model, data, epoch, args, tb_writer=None):
|
| 16 |
+
metrics = {}
|
| 17 |
+
if not is_master(args):
|
| 18 |
+
return metrics
|
| 19 |
+
model.eval()
|
| 20 |
+
|
| 21 |
+
zero_shot_metrics = zero_shot_eval(model, data, epoch, args)
|
| 22 |
+
metrics.update(zero_shot_metrics)
|
| 23 |
+
|
| 24 |
+
if not metrics:
|
| 25 |
+
return metrics
|
| 26 |
+
|
| 27 |
+
logging.info(
|
| 28 |
+
f"Eval Epoch: {epoch} "
|
| 29 |
+
+ "\t".join([f"{k}: {round(v, 4):.4f}" for k, v in metrics.items()])
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
if args.save_logs:
|
| 33 |
+
for name, val in metrics.items():
|
| 34 |
+
if tb_writer is not None:
|
| 35 |
+
tb_writer.add_scalar(f"val/d_cls/{args.val_d_cls_data[0].lower()}/{name}", val, epoch)
|
| 36 |
+
args.d_cls_output_dir = os.path.join(args.log_base_path, f'd_cls/{args.val_d_cls_data[0].lower()}')
|
| 37 |
+
os.makedirs(args.d_cls_output_dir, exist_ok=True)
|
| 38 |
+
with open(os.path.join(args.d_cls_output_dir, "results.jsonl"), "a+") as f:
|
| 39 |
+
f.write(json.dumps(metrics))
|
| 40 |
+
f.write("\n")
|
| 41 |
+
|
| 42 |
+
if args.wandb:
|
| 43 |
+
assert wandb is not None, 'Please install wandb.'
|
| 44 |
+
for name, val in metrics.items():
|
| 45 |
+
wandb.log({f"val/{name}": val, 'epoch': epoch})
|
| 46 |
+
|
| 47 |
+
return metrics
|
data/__pycache__/base_datasets.cpython-38.pyc
ADDED
|
Binary file (5.5 kB). View file
|
|
|
data/__pycache__/build_datasets.cpython-38.pyc
ADDED
|
Binary file (5.33 kB). View file
|
|
|
data/__pycache__/new_loadvat.cpython-38.pyc
ADDED
|
Binary file (13.7 kB). View file
|
|
|
data/__pycache__/process_audio.cpython-38.pyc
ADDED
|
Binary file (3.7 kB). View file
|
|
|
data/__pycache__/process_depth.cpython-38.pyc
ADDED
|
Binary file (1.89 kB). View file
|
|
|
data/__pycache__/process_image.cpython-38.pyc
ADDED
|
Binary file (813 Bytes). View file
|
|
|
data/__pycache__/process_text.cpython-38.pyc
ADDED
|
Binary file (7.77 kB). View file
|
|
|
data/__pycache__/process_thermal.cpython-38.pyc
ADDED
|
Binary file (914 Bytes). View file
|
|
|
data/__pycache__/process_video.cpython-38.pyc
ADDED
|
Binary file (4.2 kB). View file
|
|
|
data/base_datasets.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import contextlib
|
| 2 |
+
import io
|
| 3 |
+
import json
|
| 4 |
+
import logging
|
| 5 |
+
import os.path
|
| 6 |
+
import random
|
| 7 |
+
import re
|
| 8 |
+
import time
|
| 9 |
+
|
| 10 |
+
import pandas as pd
|
| 11 |
+
|
| 12 |
+
from open_clip import get_tokenizer
|
| 13 |
+
from open_clip.factory import HF_HUB_PREFIX
|
| 14 |
+
from .process_video import load_and_transform_video, get_video_transform
|
| 15 |
+
from .process_audio import load_and_transform_audio, get_audio_transform
|
| 16 |
+
from .process_text import load_and_transform_text
|
| 17 |
+
from .process_depth import load_and_transform_depth, get_depth_transform
|
| 18 |
+
from .process_thermal import load_and_transform_thermal, get_thermal_transform
|
| 19 |
+
|
| 20 |
+
import argparse
|
| 21 |
+
from os.path import join as opj
|
| 22 |
+
from torch.utils.data import Dataset, DataLoader
|
| 23 |
+
from tqdm import tqdm
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class VAT_dataset(Dataset):
|
| 29 |
+
def __init__(self, args):
|
| 30 |
+
super().__init__()
|
| 31 |
+
self.video_decode_backend = args.video_decode_backend
|
| 32 |
+
self.num_frames = args.num_frames
|
| 33 |
+
self.text_type = args.text_type
|
| 34 |
+
self.chatgpt = self.text_type == 'polish_mplug'
|
| 35 |
+
self.title = self.text_type == 'raw'
|
| 36 |
+
self.data_root = '/apdcephfs_cq3/share_1311970/A_Youtube'
|
| 37 |
+
with open(args.train_data, 'r') as f:
|
| 38 |
+
self.id2title_folder_caps = json.load(f)
|
| 39 |
+
self.ids = list(self.id2title_folder_caps.keys())[:args.train_num_samples]
|
| 40 |
+
|
| 41 |
+
self.clip_type = args.clip_type
|
| 42 |
+
|
| 43 |
+
self.num_mel_bins = args.num_mel_bins
|
| 44 |
+
self.target_length = args.target_length
|
| 45 |
+
self.audio_sample_rate = args.audio_sample_rate
|
| 46 |
+
self.audio_mean = args.audio_mean
|
| 47 |
+
self.audio_std = args.audio_std
|
| 48 |
+
|
| 49 |
+
# self.audio_error_file = open('./audio_error_id.txt', 'w')
|
| 50 |
+
|
| 51 |
+
self.tokenizer = get_tokenizer(HF_HUB_PREFIX + args.model, cache_dir=args.cache_dir)
|
| 52 |
+
self.video_transform = get_video_transform(args)
|
| 53 |
+
self.audio_transform = get_audio_transform(args)
|
| 54 |
+
self.depth_transform = get_depth_transform(args)
|
| 55 |
+
self.thermal_transform = get_thermal_transform(args)
|
| 56 |
+
|
| 57 |
+
def __len__(self):
|
| 58 |
+
return len(self.ids)
|
| 59 |
+
# return self.id2title_folder_caps.shape[0]
|
| 60 |
+
|
| 61 |
+
def __getitem__(self, idx):
|
| 62 |
+
id = self.ids[idx]
|
| 63 |
+
folder = self.id2title_folder_caps[id]['folder']
|
| 64 |
+
try:
|
| 65 |
+
text_output = self.get_text(id)
|
| 66 |
+
input_ids, attention_mask = text_output['input_ids'], text_output['attention_mask']
|
| 67 |
+
if self.clip_type == 'vl':
|
| 68 |
+
matched_modality = self.get_video(id, folder)
|
| 69 |
+
elif self.clip_type == 'al':
|
| 70 |
+
matched_modality = self.get_audio(id, folder)
|
| 71 |
+
elif self.clip_type == 'dl':
|
| 72 |
+
matched_modality = self.get_depth(id, folder)
|
| 73 |
+
elif self.clip_type == 'tl':
|
| 74 |
+
matched_modality = self.get_thermal(id, folder)
|
| 75 |
+
return matched_modality['pixel_values'], input_ids, attention_mask
|
| 76 |
+
except Exception as error_msg:
|
| 77 |
+
logging.info(f"Failed at {id} with \"{error_msg}\"")
|
| 78 |
+
return self.__getitem__(random.randint(0, self.__len__()-1))
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def get_video(self, id, folder):
|
| 82 |
+
video_path = opj(self.data_root, folder, f'{id}.mp4')
|
| 83 |
+
video = load_and_transform_video(video_path, self.video_transform,
|
| 84 |
+
video_decode_backend=self.video_decode_backend, num_frames=self.num_frames)
|
| 85 |
+
return video
|
| 86 |
+
|
| 87 |
+
def get_audio(self, id, folder):
|
| 88 |
+
'''
|
| 89 |
+
audio_path = opj(self.data_root, folder, f'{id}.mp3')
|
| 90 |
+
if os.path.exists(audio_path):
|
| 91 |
+
pass
|
| 92 |
+
else:
|
| 93 |
+
audio_path = audio_path[:-4] + '.m4a'
|
| 94 |
+
if os.path.exists(audio_path):
|
| 95 |
+
pass
|
| 96 |
+
else:
|
| 97 |
+
audio_path = audio_path[:-4] + '.wav'
|
| 98 |
+
if not os.path.exists(audio_path):
|
| 99 |
+
# self.audio_error_file.write(audio_path[:-4] + '\n')
|
| 100 |
+
raise FileNotFoundError(f'Not found audio file at \'{audio_path[:-4]}\' with .mp3 .m4a .wav')
|
| 101 |
+
# AudioSegment.from_file(audio_path).export(audio_path[:-4] + '.mp3', format='mp3')
|
| 102 |
+
# audio_path = opj(self.data_root, folder, f'{id}.mp3')
|
| 103 |
+
audio = load_and_transform_audio(audio_path, self.audio_transform)
|
| 104 |
+
'''
|
| 105 |
+
|
| 106 |
+
audio_path = opj(self.data_root, folder+'_ffmpeg_mp3', f'{id}.mp3')
|
| 107 |
+
audio = load_and_transform_audio(audio_path, self.audio_transform)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
return audio
|
| 111 |
+
|
| 112 |
+
def get_text(self, id):
|
| 113 |
+
text = self.id2title_folder_caps[id][self.text_type]
|
| 114 |
+
text_output = load_and_transform_text(text, self.tokenizer, title=self.title)
|
| 115 |
+
return text_output
|
| 116 |
+
|
| 117 |
+
def get_depth(self, id, folder):
|
| 118 |
+
depth_folder = opj(self.data_root, folder, f'{id}_depth_f8glpn_folder')
|
| 119 |
+
# random_id = random.randint(0, 7)
|
| 120 |
+
random_id = 3
|
| 121 |
+
depth_path = os.path.join(depth_folder, f'{random_id}.png')
|
| 122 |
+
depth = load_and_transform_depth(depth_path, self.depth_transform)
|
| 123 |
+
return depth
|
| 124 |
+
|
| 125 |
+
def get_thermal(self, id, folder):
|
| 126 |
+
thermal_folder = opj(self.data_root, folder, f'{id}_thermal_f8_folder')
|
| 127 |
+
# random_id = random.randint(0, 7)
|
| 128 |
+
random_id = 3
|
| 129 |
+
thermal_path = os.path.join(thermal_folder, f'{random_id}.jpg')
|
| 130 |
+
thermal = load_and_transform_thermal(thermal_path, self.thermal_transform)
|
| 131 |
+
return thermal
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
if __name__ == '__main__':
|
| 138 |
+
parser = argparse.ArgumentParser('Pre-training', add_help=False)
|
| 139 |
+
parser.add_argument('--num_frames', default=8, type=float, help='')
|
| 140 |
+
parser.add_argument('--workers', default=10, type=int, help='')
|
| 141 |
+
args = parser.parse_args()
|
| 142 |
+
|
| 143 |
+
args.cache_dir = 'D:\Omni-modal-hf'
|
| 144 |
+
args.num_frames = 8
|
| 145 |
+
args.clip_type = 'vl'
|
| 146 |
+
args.num_mel_bins = 128
|
| 147 |
+
args.target_length = 1024
|
| 148 |
+
args.audio_sample_rate = 16000
|
| 149 |
+
args.audio_mean = 1
|
| 150 |
+
args.audio_std = 1
|
| 151 |
+
args.rank = 0
|
| 152 |
+
args.batch_size = 16
|
| 153 |
+
|
| 154 |
+
train_dataset = VAT_dataset(args)
|
| 155 |
+
load = DataLoader(train_dataset, batch_size=args.batch_size, num_workers=args.workers)
|
| 156 |
+
|
| 157 |
+
for samples in tqdm((load)):
|
| 158 |
+
matched_modality, input_ids, attention_mask = samples
|
| 159 |
+
# print(video.shape, text.shape)
|
data/bpe_simple_vocab_16e6.txt.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:924691ac288e54409236115652ad4aa250f48203de50a9e4722a6ecd48d6804a
|
| 3 |
+
size 1356917
|
data/build_datasets.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
from dataclasses import dataclass
|
| 4 |
+
from multiprocessing import Value
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch.utils.data import DataLoader
|
| 8 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 9 |
+
|
| 10 |
+
from data.base_datasets import VAT_dataset
|
| 11 |
+
from data.new_loadvat import get_wds_dataset
|
| 12 |
+
from open_clip import get_tokenizer
|
| 13 |
+
from open_clip.factory import HF_HUB_PREFIX
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class SharedEpoch:
|
| 17 |
+
def __init__(self, epoch: int = 0):
|
| 18 |
+
self.shared_epoch = Value('i', epoch)
|
| 19 |
+
|
| 20 |
+
def set_value(self, epoch):
|
| 21 |
+
self.shared_epoch.value = epoch
|
| 22 |
+
|
| 23 |
+
def get_value(self):
|
| 24 |
+
return self.shared_epoch.value
|
| 25 |
+
|
| 26 |
+
@dataclass
|
| 27 |
+
class DataInfo:
|
| 28 |
+
dataloader: DataLoader
|
| 29 |
+
sampler: DistributedSampler = None
|
| 30 |
+
shared_epoch: SharedEpoch = None
|
| 31 |
+
|
| 32 |
+
def set_epoch(self, epoch):
|
| 33 |
+
if self.shared_epoch is not None:
|
| 34 |
+
self.shared_epoch.set_value(epoch)
|
| 35 |
+
if self.sampler is not None and isinstance(self.sampler, DistributedSampler):
|
| 36 |
+
self.sampler.set_epoch(epoch)
|
| 37 |
+
|
| 38 |
+
def get_VAT_dataset(args):
|
| 39 |
+
dataset = VAT_dataset(args)
|
| 40 |
+
num_samples = len(dataset)
|
| 41 |
+
sampler = DistributedSampler(dataset) if args.distributed else None
|
| 42 |
+
shuffle = sampler is None
|
| 43 |
+
|
| 44 |
+
dataloader = DataLoader(
|
| 45 |
+
dataset,
|
| 46 |
+
batch_size=args.batch_size,
|
| 47 |
+
# prefetch_factor=2,
|
| 48 |
+
# persistent_workers=True,
|
| 49 |
+
shuffle=shuffle,
|
| 50 |
+
num_workers=args.workers,
|
| 51 |
+
pin_memory=True,
|
| 52 |
+
sampler=sampler,
|
| 53 |
+
drop_last=True,
|
| 54 |
+
)
|
| 55 |
+
dataloader.num_samples = num_samples
|
| 56 |
+
dataloader.num_batches = len(dataloader)
|
| 57 |
+
|
| 58 |
+
return DataInfo(dataloader, sampler)
|
| 59 |
+
|
| 60 |
+
def get_data(args, epoch=0):
|
| 61 |
+
data = {}
|
| 62 |
+
|
| 63 |
+
if args.do_train:
|
| 64 |
+
if args.train_data.endswith(".json"):
|
| 65 |
+
data[f"{args.clip_type}_pt"] = get_VAT_dataset(args)
|
| 66 |
+
elif args.train_data.endswith(".tar"):
|
| 67 |
+
data[f"{args.clip_type}_pt"] = get_wds_dataset(args, is_train=True, epoch=epoch)
|
| 68 |
+
else:
|
| 69 |
+
raise NameError
|
| 70 |
+
|
| 71 |
+
if args.do_eval:
|
| 72 |
+
temp_batch_size = args.batch_size
|
| 73 |
+
args.batch_size = 8 if args.val_vl_ret_data else 16
|
| 74 |
+
data_root = "/apdcephfs_cq3/share_1311970/downstream_datasets/VideoTextRetrieval/vtRetdata"
|
| 75 |
+
if args.val_vl_ret_data:
|
| 76 |
+
data["vl_ret"] = []
|
| 77 |
+
for val_vl_ret_data in args.val_vl_ret_data:
|
| 78 |
+
if val_vl_ret_data == "msrvtt":
|
| 79 |
+
args.train_csv = os.path.join(f'{data_root}/MSRVTT/MSRVTT_train.9k.csv')
|
| 80 |
+
args.val_csv = os.path.join(f'{data_root}/MSRVTT/MSRVTT_JSFUSION_test.csv')
|
| 81 |
+
args.data_path = os.path.join(f'{data_root}/MSRVTT/MSRVTT_data.json')
|
| 82 |
+
args.features_path = os.path.join(f'{data_root}/MSRVTT/MSRVTT_Videos')
|
| 83 |
+
elif val_vl_ret_data == "msvd":
|
| 84 |
+
args.data_path = os.path.join(f'{data_root}/MSVD')
|
| 85 |
+
args.features_path = os.path.join(f'{data_root}/MSVD/MSVD_Videos')
|
| 86 |
+
elif val_vl_ret_data == "activity":
|
| 87 |
+
args.data_path = os.path.join(f'{data_root}/ActivityNet')
|
| 88 |
+
args.features_path = os.path.join(f'{data_root}/ActivityNet/Videos/Activity_Videos')
|
| 89 |
+
elif val_vl_ret_data == "didemo":
|
| 90 |
+
args.data_path = os.path.join(f'{data_root}/Didemo')
|
| 91 |
+
args.features_path = os.path.join(f'{data_root}/Didemo/videos')
|
| 92 |
+
else:
|
| 93 |
+
raise NameError
|
| 94 |
+
|
| 95 |
+
args.batch_size_val = args.batch_size if args.batch_size_val == 0 else args.batch_size_val
|
| 96 |
+
args.max_frames = args.num_frames
|
| 97 |
+
args.num_thread_reader = args.workers
|
| 98 |
+
args.slice_framepos = 2 # "0: cut from head frames; 1: cut from tail frames; 2: extract frames uniformly."
|
| 99 |
+
|
| 100 |
+
from vl_ret.data_dataloaders import DATALOADER_DICT
|
| 101 |
+
|
| 102 |
+
tokenizer = get_tokenizer(HF_HUB_PREFIX + args.model, cache_dir=args.cache_dir)
|
| 103 |
+
test_dataloader, test_length = None, 0
|
| 104 |
+
if DATALOADER_DICT[val_vl_ret_data]["test"] is not None:
|
| 105 |
+
test_dataloader, test_length = DATALOADER_DICT[val_vl_ret_data]["test"](args, tokenizer)
|
| 106 |
+
|
| 107 |
+
if DATALOADER_DICT[val_vl_ret_data]["val"] is not None:
|
| 108 |
+
val_dataloader, val_length = DATALOADER_DICT[val_vl_ret_data]["val"](args, tokenizer, subset="val")
|
| 109 |
+
else:
|
| 110 |
+
val_dataloader, val_length = test_dataloader, test_length
|
| 111 |
+
## report validation results if the ["test"] is None
|
| 112 |
+
if test_dataloader is None:
|
| 113 |
+
test_dataloader, test_length = val_dataloader, val_length
|
| 114 |
+
|
| 115 |
+
data["vl_ret"].append({val_vl_ret_data: test_dataloader})
|
| 116 |
+
|
| 117 |
+
if args.val_v_cls_data:
|
| 118 |
+
from v_cls import get_video_cls_dataloader
|
| 119 |
+
args.data_set = args.val_v_cls_data
|
| 120 |
+
args.num_workers = args.workers
|
| 121 |
+
args.num_sample = 1 # no repeat
|
| 122 |
+
data["v_cls"] = get_video_cls_dataloader(args)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
if args.val_a_cls_data:
|
| 126 |
+
data["a_cls"] = []
|
| 127 |
+
data_root = "/apdcephfs_cq3/share_1311970/downstream_datasets/Audio"
|
| 128 |
+
temp_val_a_cls_data = args.val_a_cls_data
|
| 129 |
+
for val_a_cls_data in temp_val_a_cls_data:
|
| 130 |
+
from a_cls.datasets import get_audio_dataset
|
| 131 |
+
args.val_a_cls_data = val_a_cls_data
|
| 132 |
+
args.audio_data_path = os.path.join(data_root, f'{val_a_cls_data.lower()}/test')
|
| 133 |
+
data['a_cls'].append({val_a_cls_data: get_audio_dataset(args)})
|
| 134 |
+
args.val_a_cls_data = temp_val_a_cls_data
|
| 135 |
+
|
| 136 |
+
if args.imagenet_val is not None:
|
| 137 |
+
from i_cls.datasets import get_imagenet
|
| 138 |
+
data['i_cls'] = {}
|
| 139 |
+
data['i_cls']["imagenet-val"] = get_imagenet(args, "val")
|
| 140 |
+
if args.imagenet_v2 is not None:
|
| 141 |
+
from i_cls.datasets import get_imagenet
|
| 142 |
+
if data.get('i_cls', None) is None:
|
| 143 |
+
data['i_cls'] = {}
|
| 144 |
+
data['i_cls']["imagenet-v2"] = get_imagenet(args, "v2")
|
| 145 |
+
|
| 146 |
+
if args.val_d_cls_data:
|
| 147 |
+
data["d_cls"] = []
|
| 148 |
+
data_root = "/apdcephfs_cq3/share_1311970/downstream_datasets/Depth"
|
| 149 |
+
temp_val_d_cls_data = args.val_d_cls_data
|
| 150 |
+
for val_d_cls_data in temp_val_d_cls_data:
|
| 151 |
+
from d_cls.datasets import get_depth_dataset
|
| 152 |
+
args.val_d_cls_data = val_d_cls_data
|
| 153 |
+
args.depth_data_path = os.path.join(data_root, f'{val_d_cls_data.lower()}/data/val')
|
| 154 |
+
data['d_cls'].append({val_d_cls_data: get_depth_dataset(args)})
|
| 155 |
+
args.val_d_cls_data = temp_val_d_cls_data
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
if args.val_t_cls_data:
|
| 159 |
+
data["t_cls"] = []
|
| 160 |
+
data_root = "/apdcephfs_cq3/share_1311970/downstream_datasets/Thermal"
|
| 161 |
+
temp_val_t_cls_data = args.val_t_cls_data
|
| 162 |
+
for val_t_cls_data in temp_val_t_cls_data:
|
| 163 |
+
from t_cls.datasets import get_thermal_dataset
|
| 164 |
+
args.val_t_cls_data = val_t_cls_data
|
| 165 |
+
args.thermal_data_path = os.path.join(data_root, f'{val_t_cls_data.lower()}/val')
|
| 166 |
+
data['t_cls'].append({val_t_cls_data: get_thermal_dataset(args)})
|
| 167 |
+
args.val_t_cls_data = temp_val_t_cls_data
|
| 168 |
+
|
| 169 |
+
args.batch_size = temp_batch_size
|
| 170 |
+
|
| 171 |
+
return data
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
|
data/new_loadvat.py
ADDED
|
@@ -0,0 +1,498 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ast
|
| 2 |
+
import io
|
| 3 |
+
import json
|
| 4 |
+
import logging
|
| 5 |
+
import math
|
| 6 |
+
import os
|
| 7 |
+
import random
|
| 8 |
+
import sys
|
| 9 |
+
import braceexpand
|
| 10 |
+
from dataclasses import dataclass
|
| 11 |
+
from multiprocessing import Value
|
| 12 |
+
|
| 13 |
+
import numpy.lib.format
|
| 14 |
+
import numpy as np
|
| 15 |
+
import pandas as pd
|
| 16 |
+
import torch
|
| 17 |
+
import torchvision.datasets as datasets
|
| 18 |
+
import webdataset as wds
|
| 19 |
+
from PIL import Image
|
| 20 |
+
from torch.utils.data import Dataset, DataLoader, SubsetRandomSampler, IterableDataset, get_worker_info
|
| 21 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 22 |
+
from torchvision.transforms import ToTensor
|
| 23 |
+
from tqdm import tqdm
|
| 24 |
+
from webdataset.filters import _shuffle
|
| 25 |
+
from webdataset.tariterators import base_plus_ext, url_opener, tar_file_expander, valid_sample
|
| 26 |
+
|
| 27 |
+
from open_clip import get_tokenizer
|
| 28 |
+
from open_clip.factory import HF_HUB_PREFIX
|
| 29 |
+
from training.params import parse_args
|
| 30 |
+
from data.process_text import load_and_transform_text
|
| 31 |
+
from data.process_video import get_video_transform
|
| 32 |
+
from data.process_audio import get_audio_transform
|
| 33 |
+
from data.process_depth import get_depth_transform
|
| 34 |
+
from data.process_thermal import get_thermal_transform
|
| 35 |
+
import pdb
|
| 36 |
+
try:
|
| 37 |
+
import horovod.torch as hvd
|
| 38 |
+
except ImportError:
|
| 39 |
+
hvd = None
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class SharedEpoch:
|
| 44 |
+
def __init__(self, epoch: int = 0):
|
| 45 |
+
self.shared_epoch = Value('i', epoch)
|
| 46 |
+
|
| 47 |
+
def set_value(self, epoch):
|
| 48 |
+
self.shared_epoch.value = epoch
|
| 49 |
+
|
| 50 |
+
def get_value(self):
|
| 51 |
+
return self.shared_epoch.value
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@dataclass
|
| 55 |
+
class DataInfo:
|
| 56 |
+
dataloader: DataLoader
|
| 57 |
+
sampler: DistributedSampler = None
|
| 58 |
+
shared_epoch: SharedEpoch = None
|
| 59 |
+
|
| 60 |
+
def set_epoch(self, epoch):
|
| 61 |
+
if self.shared_epoch is not None:
|
| 62 |
+
self.shared_epoch.set_value(epoch)
|
| 63 |
+
if self.sampler is not None and isinstance(self.sampler, DistributedSampler):
|
| 64 |
+
self.sampler.set_epoch(epoch)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def expand_urls(urls, weights=None):
|
| 68 |
+
if weights is None:
|
| 69 |
+
expanded_urls = wds.shardlists.expand_urls(urls)
|
| 70 |
+
return expanded_urls, None
|
| 71 |
+
if isinstance(urls, str):
|
| 72 |
+
urllist = urls.split("::")
|
| 73 |
+
weights = weights.split('::')
|
| 74 |
+
assert len(weights) == len(urllist), \
|
| 75 |
+
f"Expected the number of data components ({len(urllist)}) and weights({len(weights)}) to match."
|
| 76 |
+
weights = [float(weight) for weight in weights]
|
| 77 |
+
all_urls, all_weights = [], []
|
| 78 |
+
for url, weight in zip(urllist, weights):
|
| 79 |
+
expanded_url = list(braceexpand.braceexpand(url))
|
| 80 |
+
expanded_weights = [weight for _ in expanded_url]
|
| 81 |
+
all_urls.extend(expanded_url)
|
| 82 |
+
all_weights.extend(expanded_weights)
|
| 83 |
+
return all_urls, all_weights
|
| 84 |
+
else:
|
| 85 |
+
all_urls = list(urls)
|
| 86 |
+
return all_urls, weights
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def get_dataset_size(shards):
|
| 90 |
+
shards_list, _ = expand_urls(shards)
|
| 91 |
+
dir_path = os.path.dirname(shards_list[0])
|
| 92 |
+
sizes_filename = os.path.join(dir_path, 'sizes.json')
|
| 93 |
+
len_filename = os.path.join(dir_path, '__len__')
|
| 94 |
+
if os.path.exists(sizes_filename):
|
| 95 |
+
sizes = json.load(open(sizes_filename, 'r'))
|
| 96 |
+
total_size = sum([int(sizes[os.path.basename(shard)]) for shard in shards_list])
|
| 97 |
+
elif os.path.exists(len_filename):
|
| 98 |
+
# FIXME this used to be eval(open(...)) but that seemed rather unsafe
|
| 99 |
+
total_size = ast.literal_eval(open(len_filename, 'r').read())
|
| 100 |
+
else:
|
| 101 |
+
total_size = None # num samples undefined
|
| 102 |
+
# some common dataset sizes (at time of authors last download)
|
| 103 |
+
# CC3M (train): 2905954
|
| 104 |
+
# CC12M: 10968539
|
| 105 |
+
# LAION-400M: 407332084
|
| 106 |
+
# LAION-2B (english): 2170337258
|
| 107 |
+
num_shards = len(shards_list)
|
| 108 |
+
return total_size, num_shards
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def count_samples(dataloader):
|
| 113 |
+
os.environ["WDS_EPOCH"] = "0"
|
| 114 |
+
n_elements, n_batches = 0, 0
|
| 115 |
+
for images, texts in dataloader:
|
| 116 |
+
n_batches += 1
|
| 117 |
+
n_elements += len(images)
|
| 118 |
+
assert len(images) == len(texts)
|
| 119 |
+
return n_elements, n_batches
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def filter_no_caption_or_no_image(sample):
|
| 123 |
+
has_caption = ('raw.txt' in sample and 'mplug.txt' in sample and 'polish_mplug.txt' in sample and 'ofa3.txt' in sample)
|
| 124 |
+
has_image = ('frm7.jpg' in sample and 'tml0.jpg' in sample and 'dep0.npy' in sample)
|
| 125 |
+
return has_caption and has_image
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def log_and_continue(exn):
|
| 129 |
+
"""Call in an exception handler to ignore any exception, issue a warning, and continue."""
|
| 130 |
+
logging.warning(f'Handling webdataset error ({repr(exn)}). Ignoring.')
|
| 131 |
+
return True
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def group_by_keys_nothrow(data, keys=base_plus_ext, lcase=True, suffixes=None, handler=None):
|
| 135 |
+
"""Return function over iterator that groups key, value pairs into samples.
|
| 136 |
+
|
| 137 |
+
:param keys: function that splits the key into key and extension (base_plus_ext)
|
| 138 |
+
:param lcase: convert suffixes to lower case (Default value = True)
|
| 139 |
+
"""
|
| 140 |
+
current_sample = None
|
| 141 |
+
for filesample in data:
|
| 142 |
+
assert isinstance(filesample, dict)
|
| 143 |
+
fname, value = filesample["fname"], filesample["data"]
|
| 144 |
+
prefix, suffix = keys(fname)
|
| 145 |
+
if prefix is None:
|
| 146 |
+
continue
|
| 147 |
+
if lcase:
|
| 148 |
+
suffix = suffix.lower()
|
| 149 |
+
# FIXME webdataset version throws if suffix in current_sample, but we have a potential for
|
| 150 |
+
# this happening in the current LAION400m dataset if a tar ends with same prefix as the next
|
| 151 |
+
# begins, rare, but can happen since prefix aren't unique across tar files in that dataset
|
| 152 |
+
if current_sample is None or prefix != current_sample["__key__"] or suffix in current_sample:
|
| 153 |
+
if valid_sample(current_sample):
|
| 154 |
+
yield current_sample
|
| 155 |
+
current_sample = dict(__key__=prefix, __url__=filesample["__url__"])
|
| 156 |
+
if suffixes is None or suffix in suffixes:
|
| 157 |
+
current_sample[suffix] = value
|
| 158 |
+
if valid_sample(current_sample):
|
| 159 |
+
yield current_sample
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def tarfile_to_samples_nothrow(src, handler=log_and_continue):
|
| 163 |
+
# NOTE this is a re-impl of the webdataset impl with group_by_keys that doesn't throw
|
| 164 |
+
streams = url_opener(src, handler=handler)
|
| 165 |
+
files = tar_file_expander(streams, handler=handler)
|
| 166 |
+
samples = group_by_keys_nothrow(files, handler=handler)
|
| 167 |
+
return samples
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def pytorch_worker_seed(increment=0):
|
| 171 |
+
"""get dataloader worker seed from pytorch"""
|
| 172 |
+
worker_info = get_worker_info()
|
| 173 |
+
if worker_info is not None:
|
| 174 |
+
# favour using the seed already created for pytorch dataloader workers if it exists
|
| 175 |
+
seed = worker_info.seed
|
| 176 |
+
if increment:
|
| 177 |
+
# space out seed increments so they can't overlap across workers in different iterations
|
| 178 |
+
seed += increment * max(1, worker_info.num_workers)
|
| 179 |
+
return seed
|
| 180 |
+
# fallback to wds rank based seed
|
| 181 |
+
return wds.utils.pytorch_worker_seed()
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
_SHARD_SHUFFLE_SIZE = 200
|
| 185 |
+
_SHARD_SHUFFLE_INITIAL = 50
|
| 186 |
+
_SAMPLE_SHUFFLE_SIZE = 500
|
| 187 |
+
_SAMPLE_SHUFFLE_INITIAL = 100
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
class detshuffle2(wds.PipelineStage):
|
| 191 |
+
def __init__(
|
| 192 |
+
self,
|
| 193 |
+
bufsize=1000,
|
| 194 |
+
initial=100,
|
| 195 |
+
seed=0,
|
| 196 |
+
epoch=-1,
|
| 197 |
+
):
|
| 198 |
+
self.bufsize = bufsize
|
| 199 |
+
self.initial = initial
|
| 200 |
+
self.seed = seed
|
| 201 |
+
self.epoch = epoch
|
| 202 |
+
|
| 203 |
+
def run(self, src):
|
| 204 |
+
if isinstance(self.epoch, SharedEpoch):
|
| 205 |
+
epoch = self.epoch.get_value()
|
| 206 |
+
else:
|
| 207 |
+
# NOTE: this is epoch tracking is problematic in a multiprocess (dataloader workers or train)
|
| 208 |
+
# situation as different workers may wrap at different times (or not at all).
|
| 209 |
+
self.epoch += 1
|
| 210 |
+
epoch = self.epoch
|
| 211 |
+
rng = random.Random()
|
| 212 |
+
if self.seed < 0:
|
| 213 |
+
# If seed is negative, we use the worker's seed, this will be different across all nodes/workers
|
| 214 |
+
seed = pytorch_worker_seed(epoch)
|
| 215 |
+
else:
|
| 216 |
+
# This seed to be deterministic AND the same across all nodes/workers in each epoch
|
| 217 |
+
seed = self.seed + epoch
|
| 218 |
+
rng.seed(seed)
|
| 219 |
+
return _shuffle(src, self.bufsize, self.initial, rng)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
class ResampledShards2(IterableDataset):
|
| 223 |
+
"""An iterable dataset yielding a list of urls."""
|
| 224 |
+
|
| 225 |
+
def __init__(
|
| 226 |
+
self,
|
| 227 |
+
urls,
|
| 228 |
+
weights=None,
|
| 229 |
+
nshards=sys.maxsize,
|
| 230 |
+
worker_seed=None,
|
| 231 |
+
deterministic=False,
|
| 232 |
+
epoch=-1,
|
| 233 |
+
):
|
| 234 |
+
"""Sample shards from the shard list with replacement.
|
| 235 |
+
|
| 236 |
+
:param urls: a list of URLs as a Python list or brace notation string
|
| 237 |
+
"""
|
| 238 |
+
super().__init__()
|
| 239 |
+
urls, weights = expand_urls(urls, weights)
|
| 240 |
+
self.urls = urls
|
| 241 |
+
self.weights = weights
|
| 242 |
+
if self.weights is not None:
|
| 243 |
+
assert len(self.urls) == len(self.weights), \
|
| 244 |
+
f"Number of urls {len(self.urls)} and weights {len(self.weights)} should match."
|
| 245 |
+
assert isinstance(self.urls[0], str)
|
| 246 |
+
self.nshards = nshards
|
| 247 |
+
self.rng = random.Random()
|
| 248 |
+
self.worker_seed = worker_seed
|
| 249 |
+
self.deterministic = deterministic
|
| 250 |
+
self.epoch = epoch
|
| 251 |
+
|
| 252 |
+
def __iter__(self):
|
| 253 |
+
"""Return an iterator over the shards."""
|
| 254 |
+
if isinstance(self.epoch, SharedEpoch):
|
| 255 |
+
epoch = self.epoch.get_value()
|
| 256 |
+
else:
|
| 257 |
+
# NOTE: this is epoch tracking is problematic in a multiprocess (dataloader workers or train)
|
| 258 |
+
# situation as different workers may wrap at different times (or not at all).
|
| 259 |
+
self.epoch += 1
|
| 260 |
+
epoch = self.epoch
|
| 261 |
+
if self.deterministic:
|
| 262 |
+
# reset seed w/ epoch if deterministic
|
| 263 |
+
if self.worker_seed is None:
|
| 264 |
+
# pytorch worker seed should be deterministic due to being init by arg.seed + rank + worker id
|
| 265 |
+
seed = pytorch_worker_seed(epoch)
|
| 266 |
+
else:
|
| 267 |
+
seed = self.worker_seed() + epoch
|
| 268 |
+
self.rng.seed(seed)
|
| 269 |
+
for _ in range(self.nshards):
|
| 270 |
+
if self.weights is None:
|
| 271 |
+
yield dict(url=self.rng.choice(self.urls))
|
| 272 |
+
else:
|
| 273 |
+
yield dict(url=self.rng.choices(self.urls, weights=self.weights, k=1)[0])
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
class Decode:
|
| 277 |
+
def __init__(self, args=None):
|
| 278 |
+
self.num_frames = args.num_frames
|
| 279 |
+
self.text_type = args.text_type
|
| 280 |
+
self.chatgpt = self.text_type == 'polish_mplug'
|
| 281 |
+
self.title = self.text_type == 'raw'
|
| 282 |
+
self.clip_type = args.clip_type
|
| 283 |
+
self.tokenizer = get_tokenizer(HF_HUB_PREFIX + args.model, cache_dir=args.cache_dir)
|
| 284 |
+
self.video_transform = get_video_transform(args)
|
| 285 |
+
self.audio_transform = get_audio_transform(args)
|
| 286 |
+
self.depth_transform = get_depth_transform(args)
|
| 287 |
+
self.thermal_transform = get_thermal_transform(args)
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
def __call__(self, sample):
|
| 291 |
+
input_ids, attention_mask = self.get_text(sample[f"{self.text_type}.txt"], chatgpt=self.chatgpt, title=self.title)
|
| 292 |
+
if self.clip_type == 'vl':
|
| 293 |
+
matched_modality = self.get_video([sample[f"frm{i}.jpg"] for i in range(self.num_frames)])
|
| 294 |
+
elif self.clip_type == 'al':
|
| 295 |
+
matched_modality = self.get_audio()
|
| 296 |
+
elif self.clip_type == 'dl':
|
| 297 |
+
matched_modality = self.get_depth(sample[f"dep0.npy"])
|
| 298 |
+
elif self.clip_type == 'tl':
|
| 299 |
+
matched_modality = self.get_thermal(sample[f"tml0.jpg"])
|
| 300 |
+
# matched_modality = self.get_thermal(sample[f"tml{random.randint(0, 7)}.jpg"])
|
| 301 |
+
else:
|
| 302 |
+
raise ValueError
|
| 303 |
+
return matched_modality, input_ids, attention_mask
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
def get_video(self, frames):
|
| 307 |
+
video_data = []
|
| 308 |
+
for frame in frames:
|
| 309 |
+
with io.BytesIO(frame) as stream:
|
| 310 |
+
img = Image.open(stream)
|
| 311 |
+
img.load()
|
| 312 |
+
assert min(img.size) == 256
|
| 313 |
+
result = ToTensor()(img)
|
| 314 |
+
video_data.append(result)
|
| 315 |
+
video_data = torch.stack(video_data, dim=1)
|
| 316 |
+
# video_data torch.Size([3, 8, 455, 256])
|
| 317 |
+
# video_outputs torch.Size([3, 8, 224, 224])
|
| 318 |
+
video_outputs = self.video_transform(video_data)
|
| 319 |
+
return video_outputs
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
def get_text(self, text, chatgpt=True, title=False):
|
| 323 |
+
text = text.decode("utf-8")
|
| 324 |
+
if chatgpt:
|
| 325 |
+
assert text.startswith('In the video, ')
|
| 326 |
+
text = text[14:]
|
| 327 |
+
tokens = load_and_transform_text(text, self.tokenizer, title=title)
|
| 328 |
+
return tokens['input_ids'], tokens['attention_mask']
|
| 329 |
+
|
| 330 |
+
def get_audio(self):
|
| 331 |
+
raise NotImplementedError
|
| 332 |
+
|
| 333 |
+
def get_depth(self, depth):
|
| 334 |
+
stream = io.BytesIO(depth)
|
| 335 |
+
img = numpy.lib.format.read_array(stream)
|
| 336 |
+
depth = self.depth_transform(img)
|
| 337 |
+
return depth
|
| 338 |
+
|
| 339 |
+
def get_thermal(self, thermal):
|
| 340 |
+
with io.BytesIO(thermal) as stream:
|
| 341 |
+
img = Image.open(stream)
|
| 342 |
+
img.load()
|
| 343 |
+
thermal = self.thermal_transform(img)
|
| 344 |
+
return thermal
|
| 345 |
+
|
| 346 |
+
def get_wds_dataset(args, is_train, epoch=0, floor=False):
|
| 347 |
+
input_shards = args.train_data if is_train else args.val_data
|
| 348 |
+
assert input_shards is not None
|
| 349 |
+
resampled = getattr(args, 'dataset_resampled', False) and is_train
|
| 350 |
+
|
| 351 |
+
num_shards = None
|
| 352 |
+
if is_train:
|
| 353 |
+
if args.train_num_samples is not None:
|
| 354 |
+
num_samples = args.train_num_samples
|
| 355 |
+
else:
|
| 356 |
+
num_samples, num_shards = get_dataset_size(input_shards)
|
| 357 |
+
if not num_samples:
|
| 358 |
+
raise RuntimeError(
|
| 359 |
+
'Currently, the number of dataset samples must be specified for the training dataset. '
|
| 360 |
+
'Please specify it via `--train-num-samples` if no dataset length info is present.')
|
| 361 |
+
else:
|
| 362 |
+
# Eval will just exhaust the iterator if the size is not specified.
|
| 363 |
+
num_samples = args.val_num_samples or 0
|
| 364 |
+
|
| 365 |
+
shared_epoch = SharedEpoch(epoch=epoch) # create a shared epoch store to sync epoch to dataloader worker proc
|
| 366 |
+
|
| 367 |
+
if resampled:
|
| 368 |
+
pipeline = [ResampledShards2(
|
| 369 |
+
input_shards,
|
| 370 |
+
weights=args.train_data_upsampling_factors,
|
| 371 |
+
deterministic=True,
|
| 372 |
+
epoch=shared_epoch,
|
| 373 |
+
)]
|
| 374 |
+
else:
|
| 375 |
+
assert args.train_data_upsampling_factors is None, \
|
| 376 |
+
"--train_data_upsampling_factors is only supported when sampling with replacement (with --dataset-resampled)."
|
| 377 |
+
pipeline = [wds.SimpleShardList(input_shards)]
|
| 378 |
+
|
| 379 |
+
# at this point we have an iterator over all the shards
|
| 380 |
+
if is_train:
|
| 381 |
+
if not resampled:
|
| 382 |
+
pipeline.extend([
|
| 383 |
+
detshuffle2(
|
| 384 |
+
bufsize=_SHARD_SHUFFLE_SIZE,
|
| 385 |
+
initial=_SHARD_SHUFFLE_INITIAL,
|
| 386 |
+
seed=args.seed,
|
| 387 |
+
epoch=shared_epoch,
|
| 388 |
+
),
|
| 389 |
+
wds.split_by_node,
|
| 390 |
+
wds.split_by_worker,
|
| 391 |
+
])
|
| 392 |
+
pipeline.extend([
|
| 393 |
+
# at this point, we have an iterator over the shards assigned to each worker at each node
|
| 394 |
+
tarfile_to_samples_nothrow, # wds.tarfile_to_samples(handler=log_and_continue),
|
| 395 |
+
wds.shuffle(
|
| 396 |
+
bufsize=_SAMPLE_SHUFFLE_SIZE,
|
| 397 |
+
initial=_SAMPLE_SHUFFLE_INITIAL,
|
| 398 |
+
),
|
| 399 |
+
])
|
| 400 |
+
else:
|
| 401 |
+
pipeline.extend([
|
| 402 |
+
wds.split_by_worker,
|
| 403 |
+
# at this point, we have an iterator over the shards assigned to each worker
|
| 404 |
+
wds.tarfile_to_samples(handler=log_and_continue),
|
| 405 |
+
])
|
| 406 |
+
pipeline.extend([
|
| 407 |
+
wds.select(filter_no_caption_or_no_image),
|
| 408 |
+
# wds.decode("pilrgb", handler=log_and_continue),
|
| 409 |
+
# wds.rename(image="jpg;png;jpeg;webp", text="txt"),
|
| 410 |
+
# wds.map_dict(image=preprocess_img, text=lambda text: tokenizer(text)[0]),
|
| 411 |
+
# wds.to_tuple("image", "text"),
|
| 412 |
+
wds.map(Decode(args), handler=log_and_continue),
|
| 413 |
+
wds.batched(args.batch_size, partial=not is_train)
|
| 414 |
+
])
|
| 415 |
+
|
| 416 |
+
dataset = wds.DataPipeline(*pipeline)
|
| 417 |
+
|
| 418 |
+
if is_train:
|
| 419 |
+
if not resampled:
|
| 420 |
+
num_shards = num_shards or len(expand_urls(input_shards)[0])
|
| 421 |
+
assert num_shards >= args.workers * args.world_size, 'number of shards must be >= total workers'
|
| 422 |
+
# roll over and repeat a few samples to get same number of full batches on each node
|
| 423 |
+
round_fn = math.floor if floor else math.ceil
|
| 424 |
+
global_batch_size = args.batch_size * args.world_size
|
| 425 |
+
num_batches = round_fn(num_samples / global_batch_size)
|
| 426 |
+
num_workers = max(1, args.workers)
|
| 427 |
+
num_worker_batches = round_fn(num_batches / num_workers) # per dataloader worker
|
| 428 |
+
num_batches = num_worker_batches * num_workers
|
| 429 |
+
num_samples = num_batches * global_batch_size
|
| 430 |
+
dataset = dataset.with_epoch(num_worker_batches) # each worker is iterating over this
|
| 431 |
+
else:
|
| 432 |
+
# last batches are partial, eval is done on single (master) node
|
| 433 |
+
num_batches = math.ceil(num_samples / args.batch_size)
|
| 434 |
+
|
| 435 |
+
dataloader = wds.WebLoader(
|
| 436 |
+
dataset,
|
| 437 |
+
batch_size=None,
|
| 438 |
+
shuffle=False,
|
| 439 |
+
num_workers=args.workers,
|
| 440 |
+
persistent_workers=args.workers > 0,
|
| 441 |
+
)
|
| 442 |
+
|
| 443 |
+
# FIXME not clear which approach is better, with_epoch before vs after dataloader?
|
| 444 |
+
# hoping to resolve via https://github.com/webdataset/webdataset/issues/169
|
| 445 |
+
# if is_train:
|
| 446 |
+
# # roll over and repeat a few samples to get same number of full batches on each node
|
| 447 |
+
# global_batch_size = args.batch_size * args.world_size
|
| 448 |
+
# num_batches = math.ceil(num_samples / global_batch_size)
|
| 449 |
+
# num_workers = max(1, args.workers)
|
| 450 |
+
# num_batches = math.ceil(num_batches / num_workers) * num_workers
|
| 451 |
+
# num_samples = num_batches * global_batch_size
|
| 452 |
+
# dataloader = dataloader.with_epoch(num_batches)
|
| 453 |
+
# else:
|
| 454 |
+
# # last batches are partial, eval is done on single (master) node
|
| 455 |
+
# num_batches = math.ceil(num_samples / args.batch_size)
|
| 456 |
+
|
| 457 |
+
# add meta-data to dataloader instance for convenience
|
| 458 |
+
dataloader.num_batches = num_batches
|
| 459 |
+
dataloader.num_samples = num_samples
|
| 460 |
+
|
| 461 |
+
return DataInfo(dataloader=dataloader, shared_epoch=shared_epoch)
|
| 462 |
+
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
def get_data(args, epoch=0):
|
| 466 |
+
data = {}
|
| 467 |
+
|
| 468 |
+
data["train"] = get_wds_dataset(args, is_train=True, epoch=epoch)
|
| 469 |
+
|
| 470 |
+
return data
|
| 471 |
+
|
| 472 |
+
|
| 473 |
+
if __name__ == '__main__':
|
| 474 |
+
args = parse_args(sys.argv[1:])
|
| 475 |
+
args.workers = 10
|
| 476 |
+
args.batch_size = 16
|
| 477 |
+
args.world_size = 1
|
| 478 |
+
args.num_frames = 8
|
| 479 |
+
args.clip_type = 'vl'
|
| 480 |
+
args.model = "laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K"
|
| 481 |
+
args.train_data = '/apdcephfs_cq3/share_1311970/lb/vat2webdata/check_8frm_title_ofa_polishmplug_1tml_1dep/{00000..03020}.tar'
|
| 482 |
+
args.train_num_samples = 10_000
|
| 483 |
+
args.dataset_type = 'webdataset'
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
data = get_data(args, epoch=0)
|
| 488 |
+
|
| 489 |
+
data['train'].set_epoch(0) # set epoch in process safe manner via sampler or shared_epoch
|
| 490 |
+
dataloader = data['train'].dataloader
|
| 491 |
+
num_batches_per_epoch = dataloader.num_batches // args.accum_freq
|
| 492 |
+
print(num_batches_per_epoch)
|
| 493 |
+
|
| 494 |
+
|
| 495 |
+
for i, batch in enumerate(tqdm(dataloader)):
|
| 496 |
+
images, input_ids, attention_mask = batch
|
| 497 |
+
# print(images.shape, input_ids.shape, attention_mask.shape)
|
| 498 |
+
# break
|
data/process_audio.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import torchaudio
|
| 6 |
+
from torchvision.transforms import transforms
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
|
| 9 |
+
torchaudio.set_audio_backend("soundfile")
|
| 10 |
+
|
| 11 |
+
def torchaudio_loader(path):
|
| 12 |
+
return torchaudio.load(path)
|
| 13 |
+
|
| 14 |
+
def int16_to_float32_torch(x):
|
| 15 |
+
return (x / 32767.0).type(torch.float32)
|
| 16 |
+
|
| 17 |
+
def float32_to_int16_torch(x):
|
| 18 |
+
x = torch.clamp(x, min=-1., max=1.)
|
| 19 |
+
return (x * 32767.).type(torch.int16)
|
| 20 |
+
|
| 21 |
+
DEFAULT_AUDIO_FRAME_SHIFT_MS = 10
|
| 22 |
+
|
| 23 |
+
class AudioTransform:
|
| 24 |
+
def __init__(self, args):
|
| 25 |
+
self.sample_rate = args.audio_sample_rate
|
| 26 |
+
self.num_mel_bins = args.num_mel_bins
|
| 27 |
+
self.target_length = args.target_length
|
| 28 |
+
self.audio_mean = args.audio_mean
|
| 29 |
+
self.audio_std = args.audio_std
|
| 30 |
+
# mean=-4.2677393
|
| 31 |
+
# std=4.5689974
|
| 32 |
+
self.norm = transforms.Normalize(mean=self.audio_mean, std=self.audio_std)
|
| 33 |
+
|
| 34 |
+
def __call__(self, audio_data_and_origin_sr):
|
| 35 |
+
audio_data, origin_sr = audio_data_and_origin_sr
|
| 36 |
+
if self.sample_rate != origin_sr:
|
| 37 |
+
# print(audio_data.shape, origin_sr)
|
| 38 |
+
audio_data = torchaudio.functional.resample(audio_data, orig_freq=origin_sr, new_freq=self.sample_rate)
|
| 39 |
+
waveform_melspec = self.waveform2melspec(audio_data[0])
|
| 40 |
+
return self.norm(waveform_melspec)
|
| 41 |
+
|
| 42 |
+
def waveform2melspec(self, audio_data):
|
| 43 |
+
max_len = self.target_length * self.sample_rate // 100
|
| 44 |
+
if audio_data.shape[-1] > max_len:
|
| 45 |
+
mel = self.get_mel(audio_data)
|
| 46 |
+
# split to three parts
|
| 47 |
+
chunk_frames = self.target_length
|
| 48 |
+
total_frames = mel.shape[0]
|
| 49 |
+
ranges = np.array_split(list(range(0, total_frames - chunk_frames + 1)), 3)
|
| 50 |
+
# print('total_frames-chunk_frames:', total_frames-chunk_frames,
|
| 51 |
+
# 'len(audio_data):', len(audio_data),
|
| 52 |
+
# 'chunk_frames:', chunk_frames,
|
| 53 |
+
# 'total_frames:', total_frames)
|
| 54 |
+
if len(ranges[1]) == 0: # if the audio is too short, we just use the first chunk
|
| 55 |
+
ranges[1] = [0]
|
| 56 |
+
if len(ranges[2]) == 0: # if the audio is too short, we just use the first chunk
|
| 57 |
+
ranges[2] = [0]
|
| 58 |
+
# randomly choose index for each part
|
| 59 |
+
idx_front = np.random.choice(ranges[0])
|
| 60 |
+
idx_middle = np.random.choice(ranges[1])
|
| 61 |
+
idx_back = np.random.choice(ranges[2])
|
| 62 |
+
# select mel
|
| 63 |
+
mel_chunk_front = mel[idx_front:idx_front + chunk_frames, :]
|
| 64 |
+
mel_chunk_middle = mel[idx_middle:idx_middle + chunk_frames, :]
|
| 65 |
+
mel_chunk_back = mel[idx_back:idx_back + chunk_frames, :]
|
| 66 |
+
# stack
|
| 67 |
+
mel_fusion = torch.stack([mel_chunk_front, mel_chunk_middle, mel_chunk_back], dim=0)
|
| 68 |
+
elif audio_data.shape[-1] < max_len: # padding if too short
|
| 69 |
+
n_repeat = int(max_len / len(audio_data))
|
| 70 |
+
audio_data = audio_data.repeat(n_repeat)
|
| 71 |
+
audio_data = F.pad(
|
| 72 |
+
audio_data,
|
| 73 |
+
(0, max_len - len(audio_data)),
|
| 74 |
+
mode="constant",
|
| 75 |
+
value=0,
|
| 76 |
+
)
|
| 77 |
+
mel = self.get_mel(audio_data)
|
| 78 |
+
mel_fusion = torch.stack([mel, mel, mel], dim=0)
|
| 79 |
+
else: # if equal
|
| 80 |
+
mel = self.get_mel(audio_data)
|
| 81 |
+
mel_fusion = torch.stack([mel, mel, mel], dim=0)
|
| 82 |
+
|
| 83 |
+
# twice check
|
| 84 |
+
p = self.target_length - mel_fusion.shape[1]
|
| 85 |
+
|
| 86 |
+
if abs(p) / self.target_length > 0.2:
|
| 87 |
+
logging.warning(
|
| 88 |
+
"Large gap between audio n_frames(%d) and "
|
| 89 |
+
"target_length (%d). Is the audio_target_length "
|
| 90 |
+
"setting correct?",
|
| 91 |
+
mel_fusion.shape[1],
|
| 92 |
+
self.target_length,
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
# cut and pad
|
| 96 |
+
if p > 0:
|
| 97 |
+
m = torch.nn.ZeroPad2d((0, 0, 0, p))
|
| 98 |
+
mel_fusion = m(mel_fusion)
|
| 99 |
+
elif p < 0:
|
| 100 |
+
mel_fusion = mel_fusion[:, 0: self.target_length, :]
|
| 101 |
+
|
| 102 |
+
mel_fusion = mel_fusion.transpose(1, 2) # [3, target_length, mel_bins] -> [3, mel_bins, target_length]
|
| 103 |
+
return mel_fusion
|
| 104 |
+
|
| 105 |
+
def get_mel(self, audio_data):
|
| 106 |
+
# mel shape: (n_mels, T)
|
| 107 |
+
audio_data -= audio_data.mean()
|
| 108 |
+
mel = torchaudio.compliance.kaldi.fbank(
|
| 109 |
+
audio_data.unsqueeze(0),
|
| 110 |
+
htk_compat=True,
|
| 111 |
+
sample_frequency=self.sample_rate,
|
| 112 |
+
use_energy=False,
|
| 113 |
+
window_type="hanning",
|
| 114 |
+
num_mel_bins=self.num_mel_bins,
|
| 115 |
+
dither=0.0,
|
| 116 |
+
frame_length=25,
|
| 117 |
+
frame_shift=DEFAULT_AUDIO_FRAME_SHIFT_MS,
|
| 118 |
+
)
|
| 119 |
+
return mel # (T, n_mels)
|
| 120 |
+
|
| 121 |
+
def get_audio_transform(args):
|
| 122 |
+
return AudioTransform(args)
|
| 123 |
+
|
| 124 |
+
def load_and_transform_audio(
|
| 125 |
+
audio_path,
|
| 126 |
+
transform,
|
| 127 |
+
):
|
| 128 |
+
waveform_and_sr = torchaudio_loader(audio_path)
|
| 129 |
+
audio_outputs = transform(waveform_and_sr)
|
| 130 |
+
|
| 131 |
+
return {'pixel_values': audio_outputs}
|
data/process_depth.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import PIL
|
| 2 |
+
import cv2
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torchvision import transforms
|
| 8 |
+
from open_clip.constants import OPENAI_DATASET_MEAN, OPENAI_DATASET_STD
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def opencv_loader(path):
|
| 12 |
+
return cv2.imread(path, cv2.IMREAD_UNCHANGED).astype('float32')
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class DepthNorm(nn.Module):
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
max_depth=0,
|
| 19 |
+
min_depth=0.01,
|
| 20 |
+
):
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.max_depth = max_depth
|
| 23 |
+
self.min_depth = min_depth
|
| 24 |
+
self.scale = 1000.0 # nyuv2 abs.depth
|
| 25 |
+
|
| 26 |
+
def forward(self, image):
|
| 27 |
+
# image = np.array(image)
|
| 28 |
+
depth_img = image / self.scale # (H, W) in meters
|
| 29 |
+
depth_img = depth_img.clip(min=self.min_depth)
|
| 30 |
+
if self.max_depth != 0:
|
| 31 |
+
depth_img = depth_img.clip(max=self.max_depth)
|
| 32 |
+
depth_img /= self.max_depth # 0-1
|
| 33 |
+
else:
|
| 34 |
+
depth_img /= depth_img.max()
|
| 35 |
+
depth_img = torch.from_numpy(depth_img).unsqueeze(0).repeat(3, 1, 1) # assume image
|
| 36 |
+
return depth_img.to(torch.get_default_dtype())
|
| 37 |
+
|
| 38 |
+
def get_depth_transform(args):
|
| 39 |
+
transform = transforms.Compose(
|
| 40 |
+
[
|
| 41 |
+
DepthNorm(max_depth=args.max_depth),
|
| 42 |
+
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
|
| 43 |
+
transforms.CenterCrop(224),
|
| 44 |
+
transforms.Normalize(OPENAI_DATASET_MEAN, OPENAI_DATASET_STD), # assume image
|
| 45 |
+
# transforms.Normalize((0.5, ), (0.5, )) # 0-1 to norm distribution
|
| 46 |
+
# transforms.Normalize((0.0418, ), (0.0295, )) # sun rgb-d imagebind
|
| 47 |
+
# transforms.Normalize((0.02, ), (0.00295, )) # nyuv2
|
| 48 |
+
]
|
| 49 |
+
)
|
| 50 |
+
return transform
|
| 51 |
+
|
| 52 |
+
def load_and_transform_depth(depth_path, transform):
|
| 53 |
+
depth = opencv_loader(depth_path)
|
| 54 |
+
depth_outputs = transform(depth)
|
| 55 |
+
return {'pixel_values': depth_outputs}
|