

Upload folder using huggingface_hub
Browse files- README.md +30 -0
- all_results.json +8 -0
- config.json +26 -0
- generation_config.json +6 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +334 -0
- special_tokens_map.json +30 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +45 -0
- train_results.json +8 -0
- trainer_log.jsonl +8 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
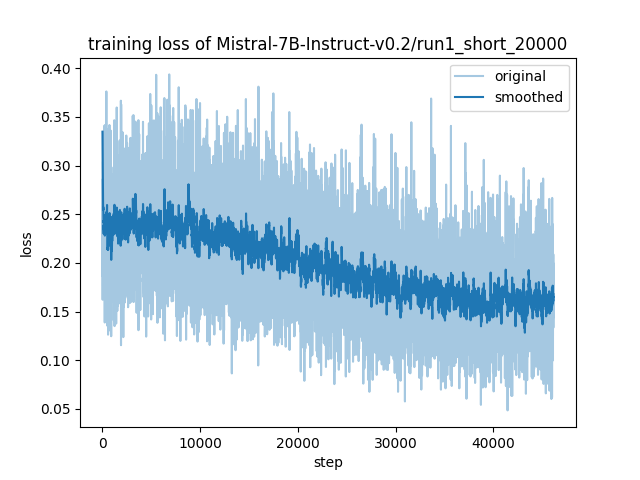
- training_loss.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
---
|
| 3 |
+
|
| 4 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 5 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 6 |
+
|
| 7 |
+
# run1_short_20000
|
| 8 |
+
|
| 9 |
+
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the rubra_train_v1_mistral_short dataset.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
### Training hyperparameters
|
| 13 |
+
|
| 14 |
+
The following hyperparameters were used during training:
|
| 15 |
+
- learning_rate: 2e-05
|
| 16 |
+
- train_batch_size: 2
|
| 17 |
+
- eval_batch_size: 8
|
| 18 |
+
- seed: 42
|
| 19 |
+
- gradient_accumulation_steps: 12
|
| 20 |
+
- total_train_batch_size: 24
|
| 21 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 22 |
+
- lr_scheduler_type: cosine
|
| 23 |
+
- num_epochs: 1.0
|
| 24 |
+
|
| 25 |
+
### Framework versions
|
| 26 |
+
|
| 27 |
+
- Transformers 4.41.2
|
| 28 |
+
- Pytorch 2.3.1+cu121
|
| 29 |
+
- Datasets 2.19.2
|
| 30 |
+
- Tokenizers 0.19.1
|
all_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"total_flos": 1.1002273748480242e+20,
|
| 4 |
+
"train_loss": 0.1970659160609881,
|
| 5 |
+
"train_runtime": 294776.7627,
|
| 6 |
+
"train_samples_per_second": 3.758,
|
| 7 |
+
"train_steps_per_second": 0.157
|
| 8 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "sanjay920/Mistral-7B-Instruct-v0.2-fc-json_v1-v6",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MistralForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 1,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 4096,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 14336,
|
| 13 |
+
"max_position_embeddings": 32768,
|
| 14 |
+
"model_type": "mistral",
|
| 15 |
+
"num_attention_heads": 32,
|
| 16 |
+
"num_hidden_layers": 36,
|
| 17 |
+
"num_key_value_heads": 8,
|
| 18 |
+
"rms_norm_eps": 1e-05,
|
| 19 |
+
"rope_theta": 1000000.0,
|
| 20 |
+
"sliding_window": null,
|
| 21 |
+
"tie_word_embeddings": false,
|
| 22 |
+
"torch_dtype": "bfloat16",
|
| 23 |
+
"transformers_version": "4.41.2",
|
| 24 |
+
"use_cache": false,
|
| 25 |
+
"vocab_size": 32000
|
| 26 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.41.2"
|
| 6 |
+
}
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d477a996919ccebe979b14435c0c94b9261effc24dbb0f51da5e075824b9ea0
|
| 3 |
+
size 4943161280
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b4ebd44d5898bc8e88bacf819980fd750aab172ae183881f33f1e6abd48fe9a2
|
| 3 |
+
size 4999818296
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f85cdc82e62e4430258291977498ebdaa2fd3600fe989f3e573ba3d02a7b66ad
|
| 3 |
+
size 4915915136
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9eb90c793d32d1a6241643a61ecf480cb809b4cd698659e01d1afaa9a377a995
|
| 3 |
+
size 3114399504
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,334 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 17973256192
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 242 |
+
"model.layers.32.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 243 |
+
"model.layers.32.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 244 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 245 |
+
"model.layers.32.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 246 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 247 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 248 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 249 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 250 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 251 |
+
"model.layers.33.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 252 |
+
"model.layers.33.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 253 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 254 |
+
"model.layers.33.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 255 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 256 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 257 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 258 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 259 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 260 |
+
"model.layers.34.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 261 |
+
"model.layers.34.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 262 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 263 |
+
"model.layers.34.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 264 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 265 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 266 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 267 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 268 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 269 |
+
"model.layers.35.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 270 |
+
"model.layers.35.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 271 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 272 |
+
"model.layers.35.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 273 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 274 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 275 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 276 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 277 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 278 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 279 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 280 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 281 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 282 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 283 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 284 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 285 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 286 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 287 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 288 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 289 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 290 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 291 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 292 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 293 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 294 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 295 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 296 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 297 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 298 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 299 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 300 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 301 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 302 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 303 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 304 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 305 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 306 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 307 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 308 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 309 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 310 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 311 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 312 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 313 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 314 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 315 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 316 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 317 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 318 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 319 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 320 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 321 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 322 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 323 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 324 |
+
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 325 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 326 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 327 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 328 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 329 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 330 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 331 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 332 |
+
"model.norm.weight": "model-00004-of-00004.safetensors"
|
| 333 |
+
}
|
| 334 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "</s>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"additional_special_tokens": [],
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{{ '<s>' + system_message }}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '[INST] ' + content + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ content + '</s>' }}{% endif %}{% endfor %}",
|
| 33 |
+
"clean_up_tokenization_spaces": false,
|
| 34 |
+
"eos_token": "</s>",
|
| 35 |
+
"legacy": true,
|
| 36 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 37 |
+
"pad_token": "</s>",
|
| 38 |
+
"padding_side": "right",
|
| 39 |
+
"sp_model_kwargs": {},
|
| 40 |
+
"spaces_between_special_tokens": false,
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 43 |
+
"unk_token": "<unk>",
|
| 44 |
+
"use_default_system_prompt": false
|
| 45 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"total_flos": 1.1002273748480242e+20,
|
| 4 |
+
"train_loss": 0.1970659160609881,
|
| 5 |
+
"train_runtime": 294776.7627,
|
| 6 |
+
"train_samples_per_second": 3.758,
|
| 7 |
+
"train_steps_per_second": 0.157
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 5, "total_steps": 46153, "loss": 0.3349, "learning_rate": 1.9999999420824903e-05, "epoch": 0.00010833531948085715, "percentage": 0.01, "elapsed_time": "0:00:33", "remaining_time": "3 days, 13:28:40"}
|
| 2 |
+
{"current_steps": 10, "total_steps": 46153, "loss": 0.3097, "learning_rate": 1.999999768329967e-05, "epoch": 0.0002166706389617143, "percentage": 0.02, "elapsed_time": "0:01:03", "remaining_time": "3 days, 9:29:33"}
|
| 3 |
+
{"current_steps": 15, "total_steps": 46153, "loss": 0.1621, "learning_rate": 1.9999994787424503e-05, "epoch": 0.00032500595844257147, "percentage": 0.03, "elapsed_time": "0:01:28", "remaining_time": "3 days, 3:43:11"}
|
| 4 |
+
{"current_steps": 20, "total_steps": 46153, "loss": 0.2691, "learning_rate": 1.9999990733199743e-05, "epoch": 0.0004333412779234286, "percentage": 0.04, "elapsed_time": "0:01:58", "remaining_time": "3 days, 3:39:21"}
|
| 5 |
+
{"current_steps": 25, "total_steps": 46153, "loss": 0.2862, "learning_rate": 1.9999985520625857e-05, "epoch": 0.0005416765974042857, "percentage": 0.05, "elapsed_time": "0:02:38", "remaining_time": "3 days, 9:04:12"}
|
| 6 |
+
{"current_steps": 30, "total_steps": 46153, "loss": 0.209, "learning_rate": 1.9999979149703445e-05, "epoch": 0.0006500119168851429, "percentage": 0.07, "elapsed_time": "0:03:02", "remaining_time": "3 days, 5:50:50"}
|
| 7 |
+
{"current_steps": 35, "total_steps": 46153, "loss": 0.2322, "learning_rate": 1.9999971620433252e-05, "epoch": 0.000758347236366, "percentage": 0.08, "elapsed_time": "0:03:36", "remaining_time": "3 days, 7:04:51"}
|
| 8 |
+
{"current_steps": 40, "total_steps": 46153, "loss": 0.2176, "learning_rate": 1.9999962932816142e-05, "epoch": 0.0008666825558468572, "percentage": 0.09, "elapsed_time": "0:04:05", "remaining_time": "3 days, 6:40:51"}
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:35abe0eecf3df3a97627ec435eaa9458a1db575b6ec4e195c55d5a835939088a
|
| 3 |
+
size 5368
|
training_loss.png
ADDED
|