
license: apache-2.0
metrics:
- f1
- recall
model-index:
- name: pretrained_model
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: F1
type: f1
value: 0.9346
- name: Recall
type: recall
value: 0.9345
pipeline_tag: image-classification
tags:
- medical
Multiple Sclerosis Prediction from MRI Scans
Project Overview
This repository contains the implementation of a Vision Transformer (ViT) model finetuned and designed to predict Multiple Sclerosis (MS) from Magnetic Resonance Imaging (MRI) scans.
What helps the model distinguish between an MRI scan of an MS patient and a healthy subject are clear lesions in different areas of the brain that can be distinguished in the MRI scans. By implementing the Vision Transformer (ViT) model for MRI scans and Multiple Sclerosis detection, we showcase the model's effectiveness in medical imaging applications.
What is Multiple Sclerosis?
Multiple Sclerosis (MS) is a chronic demyelinating disease characterized by the presence of plaques in the white matter of the central nervous system. These plaques can disrupt the flow of information within the brain, and between the brain and the rest of the body. MS can be diagnosed using MRI, which helps identify the characteristic lesions associated with the disease. Usual onset is around age 20–50.
It can cause a wide range of symptoms including fatigue, vision problems, mobility issues, cognitive changes, numbness, pain, speech difficulties, mood changes, heat sensitivity, and muscle spasticity, which vary in severity and occurrence among individuals.

Dataset
The dataset and initial modeling attempts are derived from the work by Macin et al. (2022). They proposed a computationally efficient model using Exemplar Multiple Parameters Local Phase Quantization (ExMPLPQ) combined with a k-nearest neighbor (kNN) classifier. Their model achieved high accuracy in detecting MS from MRI images.
Original Article: An Accurate Multiple Sclerosis Detection Model Based on Exemplar Multiple Parameters Local Phase Quantization: ExMPLPQ
The dataset consists of axial and sagittal MRI images divided into four classes:
- Control-Axial: Axial MRI images from healthy individuals.
- Control-Sagittal: Sagittal MRI images from healthy individuals.
- MS-Axial: Axial MRI images from individuals diagnosed with MS.
- MS-Sagittal: Sagittal MRI images from individuals diagnosed with MS.
Criterions for diagnostic labeling of MS:
Interpretation of MRI images requires experts to manually scrutinize multiple contiguous image sections for the presence of white matter lesions, with care being taken to distinguish MS plaques from lesions associated with diseases that present with similar symptoms, e.g., ischemic gliosis and central nervous system vasculitis. MS plaques are hyperintense in T2 sequence, oval-round shaped, at least 3mm in size, with asymmetric distribution. The typical location of MS plaques is as follows: periventricular: adjacent to the lateral ventricles; juxtracortical and cortical: localized to U fibers; infratentorial: located unilaterally or bilaterally paramedian adjacent to the brain stem, cerebellum, and 4th ventricle; spinal cord: cervical and thoracic localized, shorter than two vertebral segments, axially wedge-shaped, sagittal cigarette shaped, localized in peripherally located posterior and lateral columns.
Sample Distribution
We have to classes, MS or Non-MS. After we balanced the classes using downsampling, each class contains 1293 samples (MRI images), ensuring a balanced dataset for training and evaluation.
Model Architecture
We utilized and finetuned the Vision Transformer (ViT) model, specifically google/vit-base-patch16-384 on our MRI dataset images.
Vision Transformer (ViT)
- Patch Embeddings: The input image is divided into fixed-size patches (e.g., 16x16), each of which is flattened and embedded into a vector.
- Positional Encoding: Added to the patch embeddings to maintain spatial information.
- Transformer Encoder: Processes the encoded patches through multi-head self-attention layers and feed-forward neural networks.
- Classification Head: The output is pooled and passed through a fully connected layer to generate final class probabilities.
Detailed Architecture
- Base Vision Transformer:
- Pre-trained on ImageNet-21k.
- Added Adaptive Average Pooling to minimize overfitting.
- Fully Connected Layers:
- Connected Layer: 128 neurons, ReLU activation.
- Linear layer with single output (1 or 0) for binary classification.
The following table lists the hyperparameters used in our model:
| Hyperparameter | Value |
|---|---|
| Input Size | 384x384 |
| Dropout Rate | 0.5 |
| Weight Decay | 0.01 |
| Learning Rate | 1e-5 |
| Optimizer | AdamW |
| Batch Size | 8 |
Cross-validation
To ensure robust evaluation and to prevent overfitting, we employed 6 fold cross-validation. This approach divides the dataset into six subsets, training the model on five subsets while using the sixth for validation (around 431 samples per fold-validation set).
Results
Below are the results for the last epochs of each fold:
Fold-wise Results
| Fold | Epochs | Train Loss | Val Loss | F1 | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|---|
| 1 | 3 | 0.5596 | 0.2153 | 0.92 | 0.92 | 0.92 | 0.92 |
| 2 | 6 | 0.5402 | 0.1795 | 0.94 | 0.94 | 0.94 | 0.94 |
| 3 | 4 | 0.5443 | 0.2065 | 0.92 | 0.92 | 0.93 | 0.92 |
| 4 | 4 | 0.5150 | 0.2093 | 0.94 | 0.94 | 0.94 | 0.94 |
| 5 | 5 | 0.5281 | 0.1826 | 0.95 | 0.95 | 0.95 | 0.95 |
| 6 | 5 | 0.5337 | 0.2232 | 0.94 | 0.94 | 0.95 | 0.94 |
Average Metrics across all Folds
| Metric | Value |
|---|---|
| Accuracy | 0.9346 |
| Precision | 0.9378 |
| Recall | 0.9346 |
| F1 Score | 0.9345 |
Class-wise Average Metrics
| Class | Precision | Recall | F1-Score |
|---|---|---|---|
| NON-MS | 0.9229 | 0.9513 | 0.9356 |
| MS | 0.9527 | 0.9180 | 0.9335 |
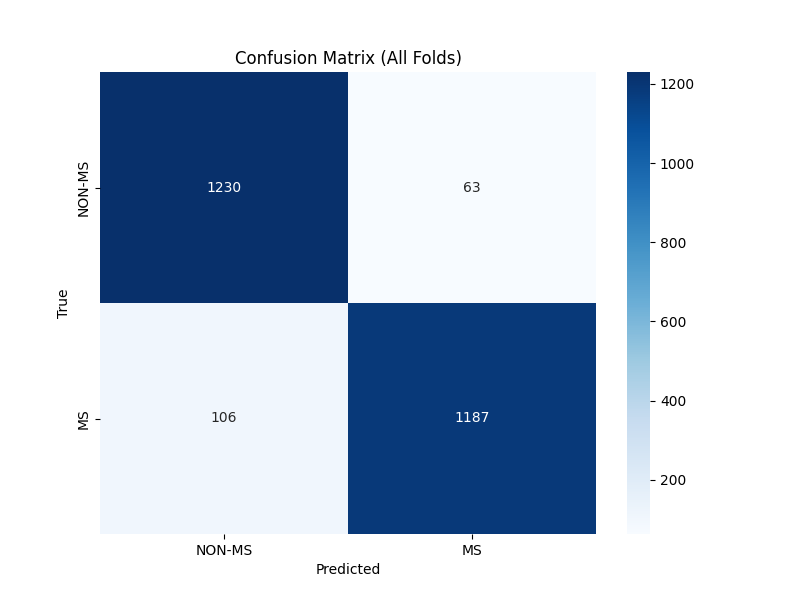
Conclusion
In conclusion, our project aimed to build upon the existing research by applying modern computer vision techniques, primarily the Vision Transformer model, to classify MS from MRI images. Through cross-validation and fine-tuning, we achieved robust performance metrics, demonstrating the efficacy of ViT models in medical image classification tasks, with an average prediction Recall of 93%.
Potential Problems and Future Directions
Small Dataset
- The current dataset, while balanced and sufficient for initial trials, is relatively small. Small datasets may not capture the full variability required for robust model training and generalization.
Higher Resolution Images
- Higher resolution images could provide more detailed information, potentially improving the model's ability to detect subtle features associated with MS.
Model Complexity and Interpretability
- Vision Transformers are complex models, which makes interpreting the learned features challenging. Understanding why the model makes specific predictions is crucial in medical applications.
Acknowledgments
This project was made possible by the pioneering efforts of Macin et al., 2022, whose data and initial study laid the groundwork for our research.
References: Macin, G., Tasci, B., Tasci, I., Faust, O., Barua, P.D., Dogan, S., Tuncer, T., Tan, R.-S., Acharya, U.R. An Accurate Multiple Sclerosis Detection Model Based on Exemplar Multiple Parameters Local Phase Quantization: ExMPLPQ. Appl. Sci. 2022, 12, 4920.
Disclaimer: This project is intended for research and educational purposes only and should not be used as a diagnostic tool without formal clinical validation.