
language:
- en
license: llama2
library_name: transformers
datasets:
- pankajmathur/orca_mini_v1_dataset
- pankajmathur/dolly-v2_orca
- pankajmathur/WizardLM_Orca
- pankajmathur/alpaca_orca
- ehartford/dolphin
model-index:
- name: model_009
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 71.59
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=psmathur/model_009
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 87.7
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=psmathur/model_009
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 69.43
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=psmathur/model_009
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 60.72
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=psmathur/model_009
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 82.32
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=psmathur/model_009
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 39.42
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=psmathur/model_009
name: Open LLM Leaderboard
model_009
A Llama2-70b model trained on Orca Style datasets.
Passionate about Generative AI? I help companies to privately train and deploy custom LLM/MLLM affordably. For startups, I can even assist with securing GPU grants to get you started. Let's chat!https://www.linkedin.com/in/pankajam Looking forward to connecting!
Evaluation
We evaluated model_009 on a wide range of tasks using Language Model Evaluation Harness from EleutherAI.
Here are the results on metrics used by HuggingFaceH4 Open LLM Leaderboard
| Task | Value |
| ARC | 0.7159 |
| HellaSwag | 0.8771 |
| MMLU | 0.6943 |
| TruthfulQA | 0.6072 |
| Winogrande | 0.8232 |
| GSM8k | 0.3942 |
| DROP | 0.4401 |
| Total Average | 0.6503 |
Prompt Format
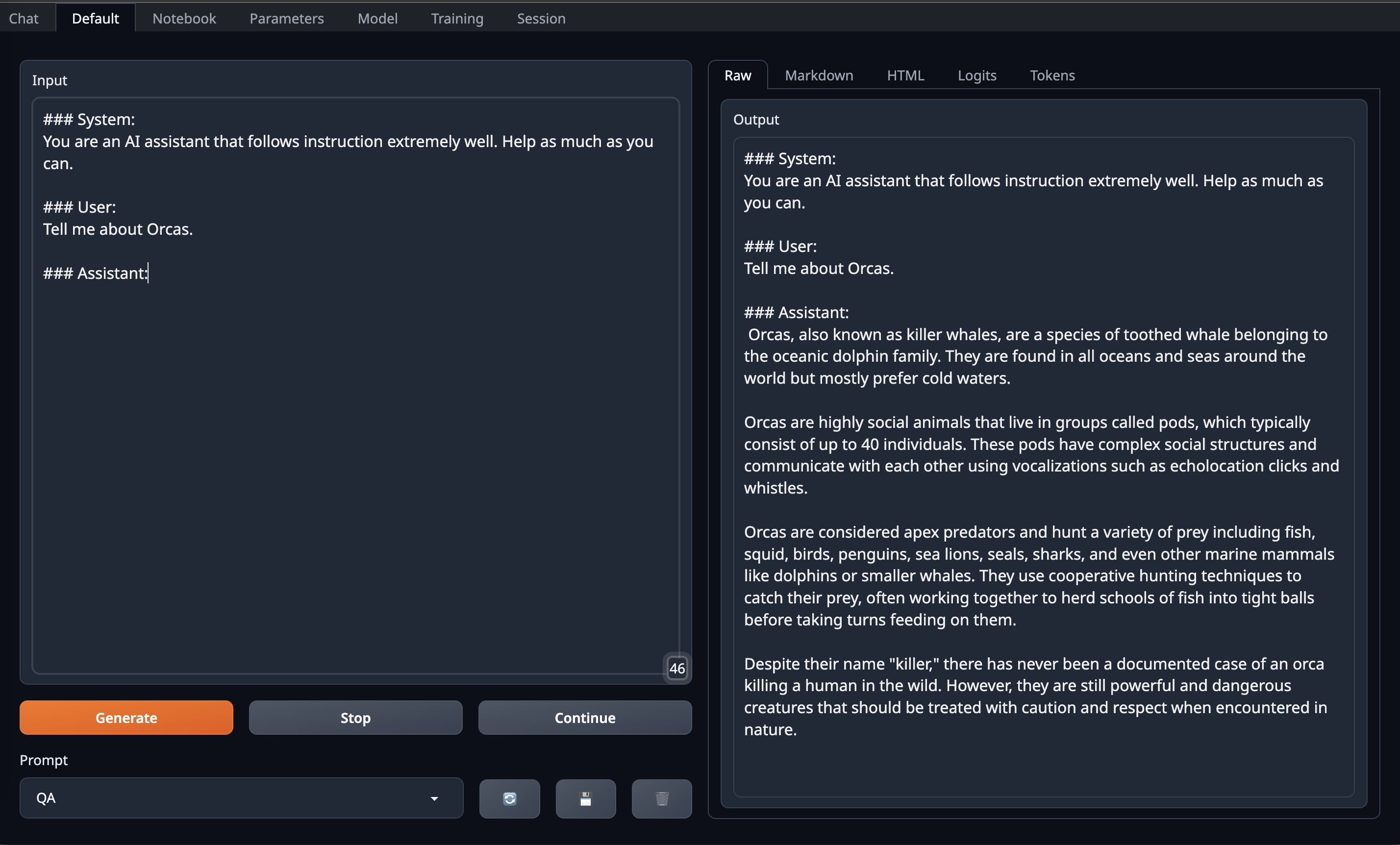
### System:
You are an AI assistant that follows instruction extremely well. Help as much as you can.
### User:
Tell me about Orcas.
### Assistant:
OobaBooga Instructions:
This model required upto 45GB GPU VRAM in 4bit so it can be loaded directly on Single RTX 6000/L40/A40/A100/H100 GPU or Double RTX 4090/L4/A10/RTX 3090/RTX A5000 So, if you have access to Machine with 45GB GPU VRAM and have installed OobaBooga Web UI on it. You can just download this model by using HF repo link directly on OobaBooga Web UI "Model" Tab/Page & Just use load-in-4bit option in it.
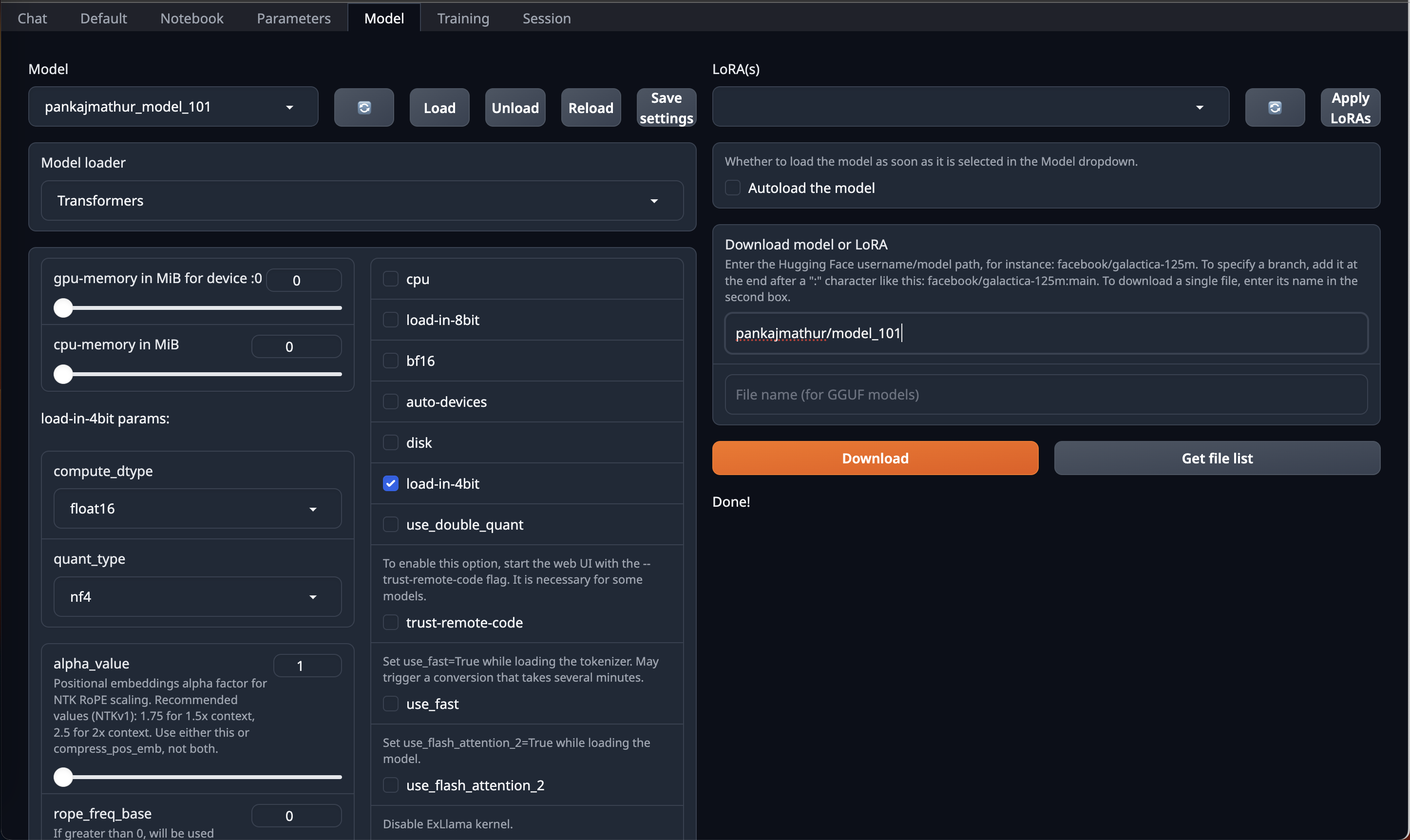
After that go to Default Tab/Page on OobaBooga Web UI and copy paste above prompt format into Input and Enjoy!
Code Instructions:
Below shows a code example on how to use this model
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("pankajmathur/model_009")
model = AutoModelForCausalLM.from_pretrained(
"pankajmathur/model_009",
torch_dtype=torch.float16,
load_in_4bit=True,
low_cpu_mem_usage=True,
device_map="auto"
)
system_prompt = "### System:\nYou are an AI assistant that follows instruction extremely well. Help as much as you can.\n\n"
#generate text steps
instruction = "Tell me about Orcas."
prompt = f"{system_prompt}### User: {instruction}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=4096)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Limitations & Biases:
While this model aims for accuracy, it can occasionally produce inaccurate or misleading results.
Despite diligent efforts in refining the pretraining data, there remains a possibility for the generation of inappropriate, biased, or offensive content.
Exercise caution and cross-check information when necessary.
Citiation:
Please kindly cite using the following BibTeX:
@misc{model_009,
author = {Pankaj Mathur},
title = {model_009: An Orca Style Llama2-70b model},
month = {August},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://https://huggingface.co/pankajmathur/model_009},
}
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 65.03 |
| ARC (25-shot) | 71.59 |
| HellaSwag (10-shot) | 87.7 |
| MMLU (5-shot) | 69.43 |
| TruthfulQA (0-shot) | 60.72 |
| Winogrande (5-shot) | 82.32 |
| GSM8K (5-shot) | 39.42 |
| DROP (3-shot) | 44.01 |
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 68.53 |
| AI2 Reasoning Challenge (25-Shot) | 71.59 |
| HellaSwag (10-Shot) | 87.70 |
| MMLU (5-Shot) | 69.43 |
| TruthfulQA (0-shot) | 60.72 |
| Winogrande (5-shot) | 82.32 |
| GSM8k (5-shot) | 39.42 |