

license: apache-2.0
datasets:
- Yirany/UniMM-Chat
- HaoyeZhang/RLHF-V-Dataset
language:
- en
library_name: transformers
Model Card for RLHF-V
Project Page | GitHub | Demo | Paper
News
- [2024.05.28] 📃 Our RLAIF-V paper is accesible at arxiv now!
- [2024.05.20] 🎉 We introduce RLAIF-V, our new alignment framework that utilize open-source models for feedback generation and reach super GPT-4V trustworthiness. You can download the corresponding dataset and models (7B, 12B) now!
- [2024.04.11] 🔥 Our data is used in MiniCPM-V 2.0, an end-side multimodal large language model that exhibits comparable trustworthiness with GPT-4V!
Brief Introduction
RLHF-V is an open-source multimodal large language model with the lowest hallucination rate on both long-form instructions and short-form questions.
RLHF-V is trained on RLHF-V-Dataset, which contains fine-grained segment-level human corrections on diverse instructions. The base model is trained on UniMM-Chat, which is a high-quality knowledge-intensive SFT dataset. We introduce a new method Dense Direct Preference Optimization (DDPO) that can make better use of the fine-grained annotations.
For more details, please refer to our paper.
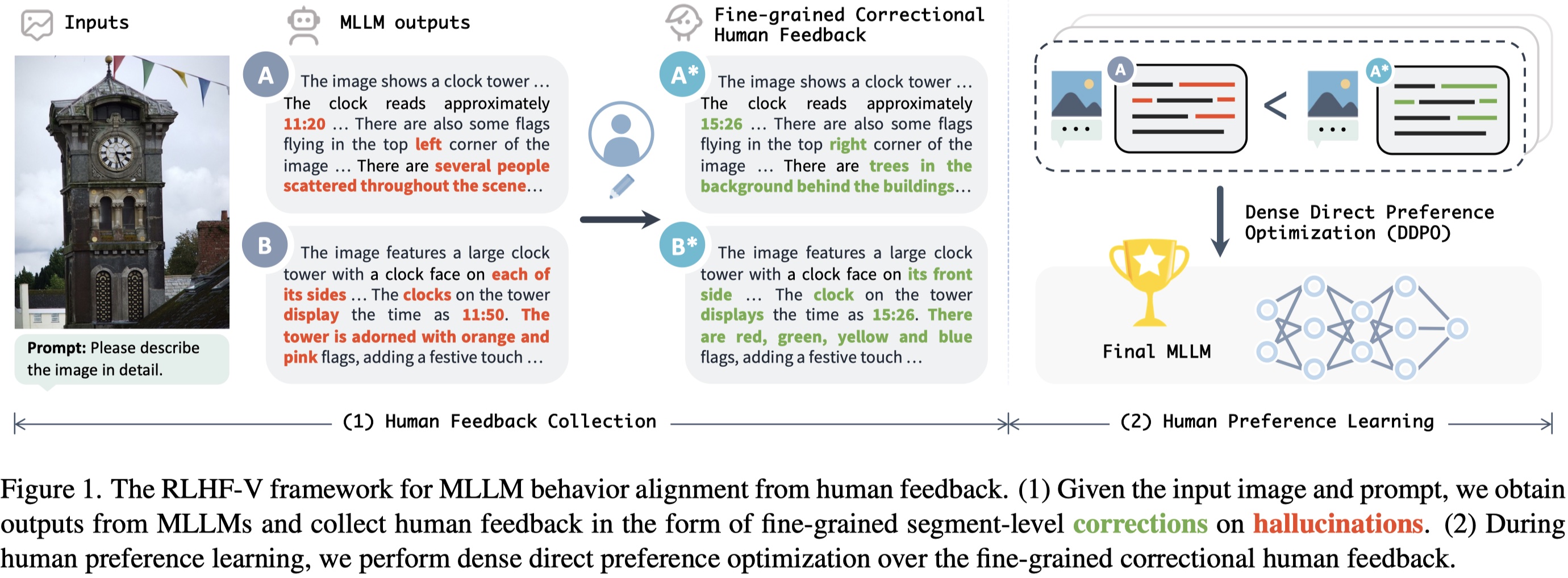
Model Details
Model Description
- Trained from model: Vicuna-13B
- Trained on data: RLHF-V-Dataset
Model Sources
- Project Page: https://rlhf-v.github.io
- GitHub Repository: https://github.com/RLHF-V/RLHF-V
- Demo: http://120.92.209.146:8081
- Paper: https://arxiv.org/abs/2312.00849
Performance
Low hallucination rate while being informative:

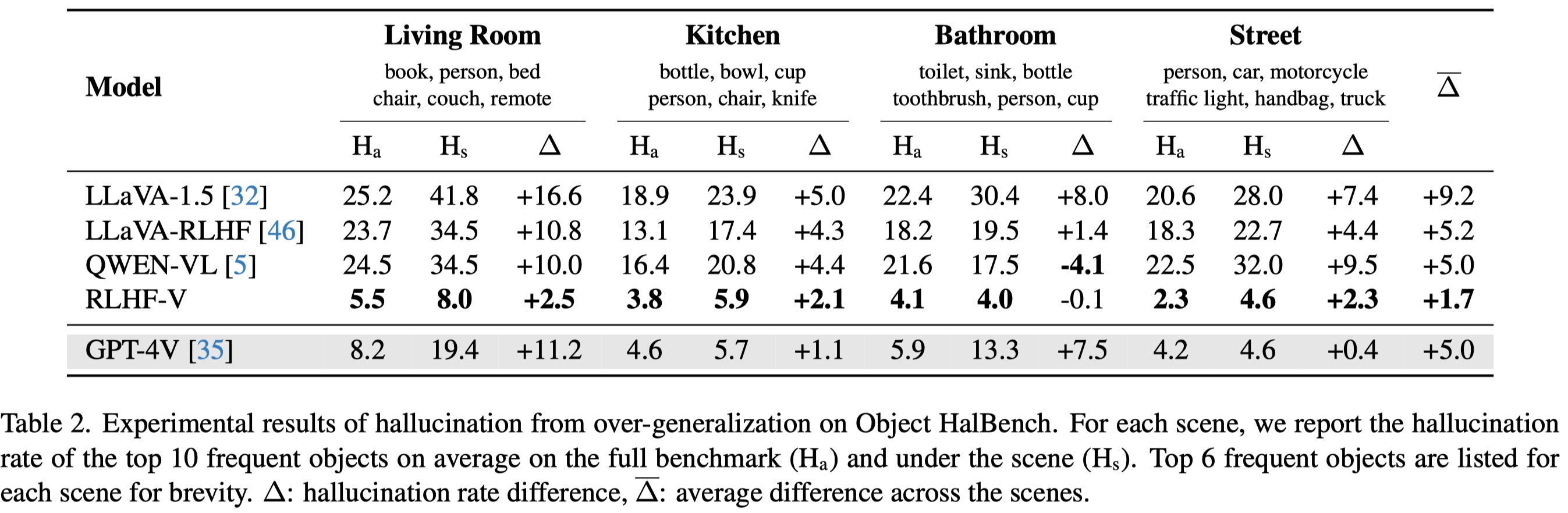
More resistant to over-generalization, even compared to GPT-4V:
Citation
If you find this work helpful, please consider cite our papers 📝:
@article{yu2023rlhf,
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
journal={arXiv preprint arXiv:2312.00849},
year={2023}
}
@article{yu2024rlaifv,
title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness},
author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong},
journal={arXiv preprint arXiv:2405.17220},
year={2024},
}