metadata
license: apache-2.0
tags:
- mlx
- mlx-image
- vision
- image-classification
datasets:
- imagenet-1k
library_name: mlx-image
vit_base_patch16_224.dino
A Vision Transformer image classification model trained on ImageNet-1k dataset with DINO.
The model was trained in self-supervised fashion on ImageNet-1k dataset. No classification head was trained, only the backbone.
Disclaimer: This is a porting of the torch model weights to Apple MLX Framework.

How to use
pip install mlx-image
Here is how to use this model for image classification:
from mlxim.model import create_model
from mlxim.io import read_rgb
from mlxim.transform import ImageNetTransform
transform = ImageNetTransform(train=False, img_size=224)
x = transform(read_rgb("cat.png"))
x = mx.expand_dims(x, 0)
model = create_model("vit_base_patch16_224.dino")
model.eval()
logits, attn_masks = model(x, attn_masks=True)
You can also use the embeds from layer before head:
from mlxim.model import create_model
from mlxim.io import read_rgb
from mlxim.transform import ImageNetTransform
transform = ImageNetTransform(train=False, img_size=512)
x = transform(read_rgb("cat.png"))
x = mx.expand_dims(x, 0)
# first option
model = create_model("vit_base_patch16_224.dino", num_classes=0)
model.eval()
embeds = model(x)
# second option
model = create_model("vit_base_patch16_224.dino")
model.eval()
embeds, attn_masks = model.get_features(x)
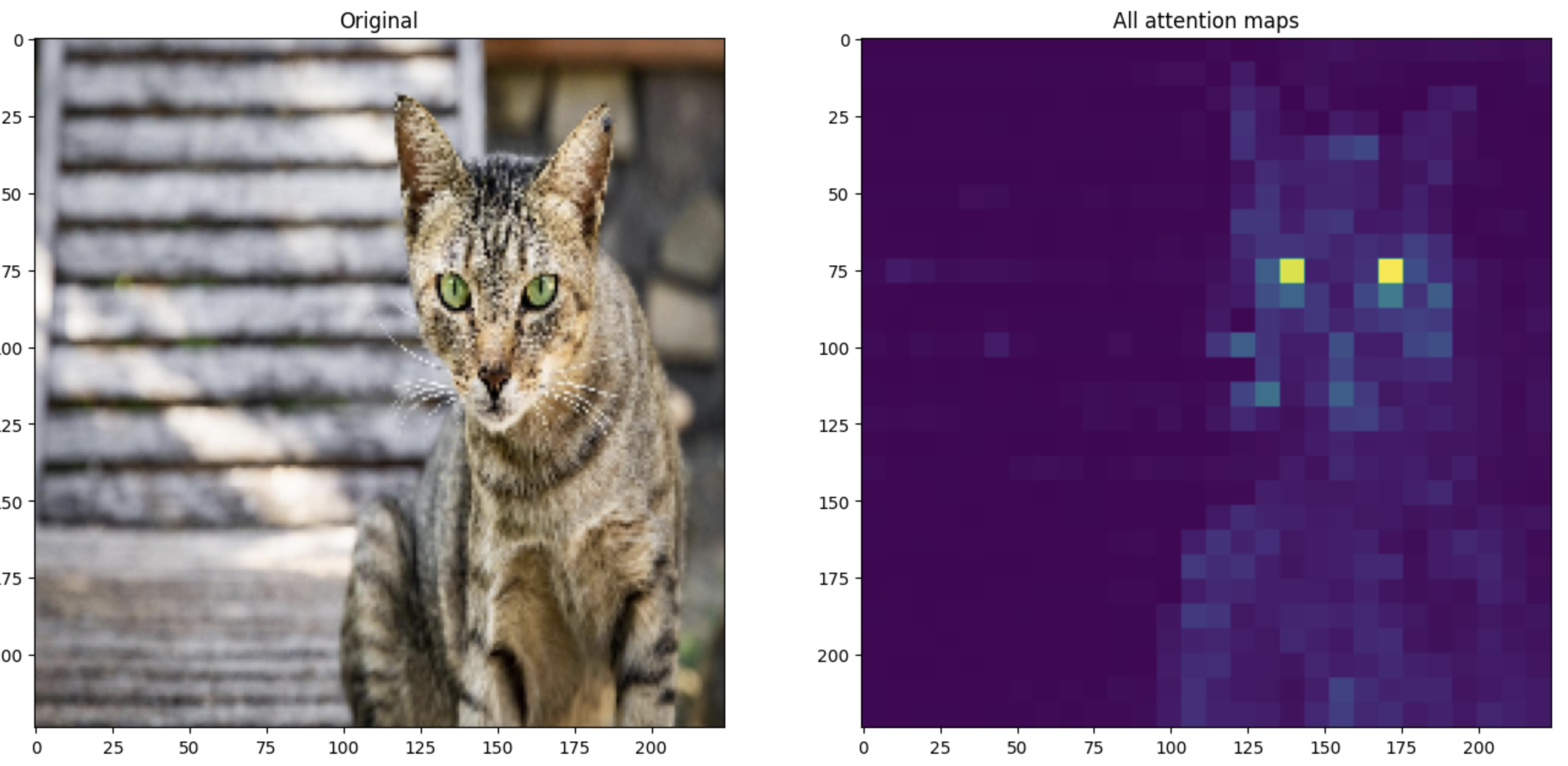
Attention maps
You can visualize the attention maps using the attn_masks returned by the model. Go check the mlx-image notebook.