|
--- |
|
license: other |
|
license_name: qwen2 |
|
license_link: https://huggingface.co/Qwen/Qwen2-72B/blob/main/LICENSE |
|
--- |
|
|
|
# Tess-v2.5 (Qwen2-72B) |
|
|
|
 |
|
|
|
# Depracated - Please use [Tess-v2.5.2](https://huggingface.co/migtissera/Tess-v2.5.2-Qwen2-72B) |
|
|
|
# Update: |
|
|
|
I was testing a new feature with the Tess-v2.5 dataset. If you had used the model, you might have noticed that the model generations sometimes would end up with a follow-up question. This is intentional, and was created to provide more of a "natural" conversation. |
|
|
|
What had happened earlier was that the stop token wasn't getting properly generated, so the model would go on to answer its own question. |
|
|
|
I have fixed this now, and Tess-v2.5.2 is available on HF here: [Tess-v2.5.2 Model](https://huggingface.co/migtissera/Tess-v2.5.2-Qwen2-72B/tree/main) |
|
|
|
Tess-v2.5.2 model would still ask you follow-up questions, but the stop tokens are getting properly generated. If you'd like to not have the follow-up questions feature, just add the following to your system prompt: "No follow-up questions necessary". |
|
|
|
Thanks! |
|
|
|
# Tess-v2.5 (Qwen2-72B) |
|
|
|
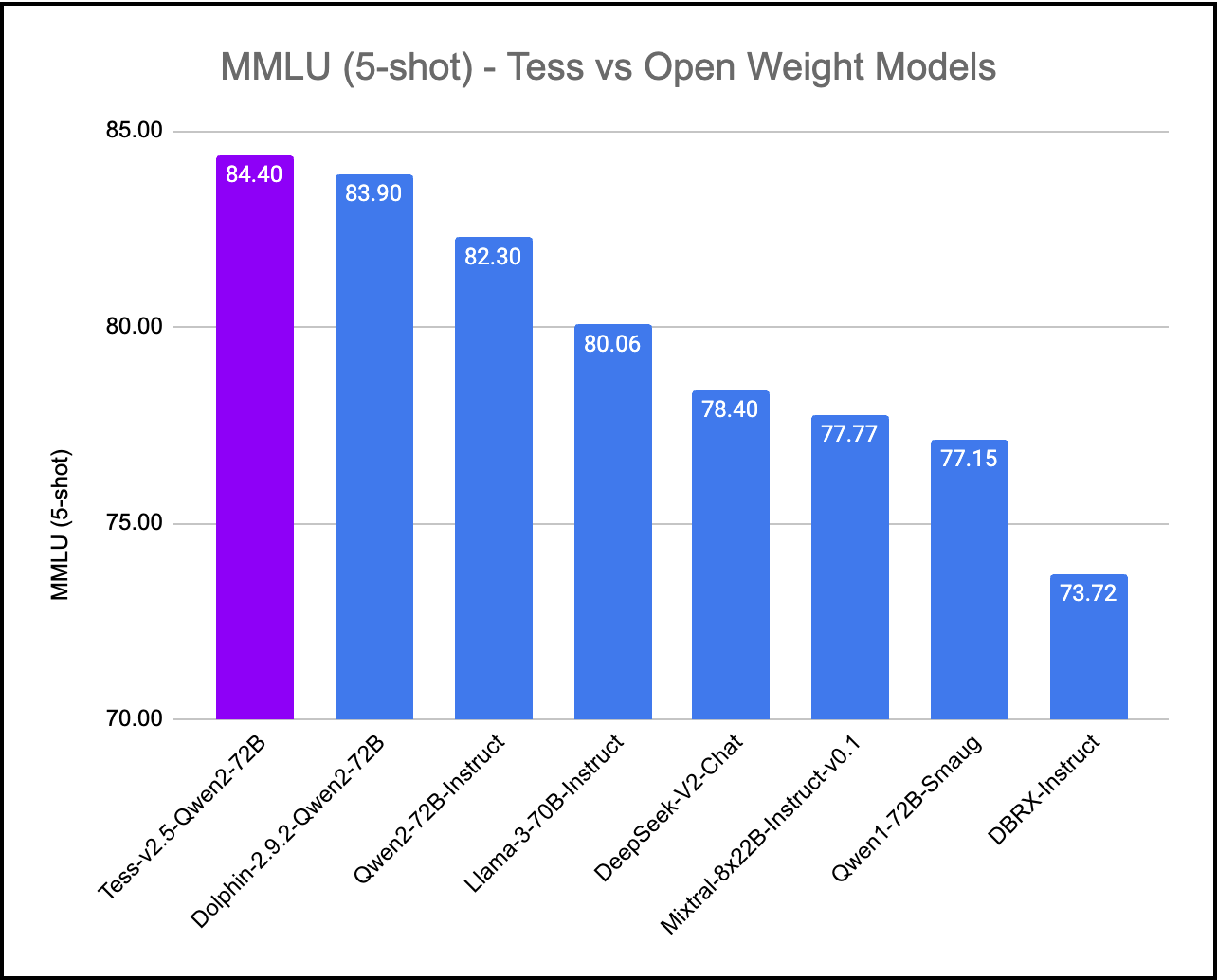
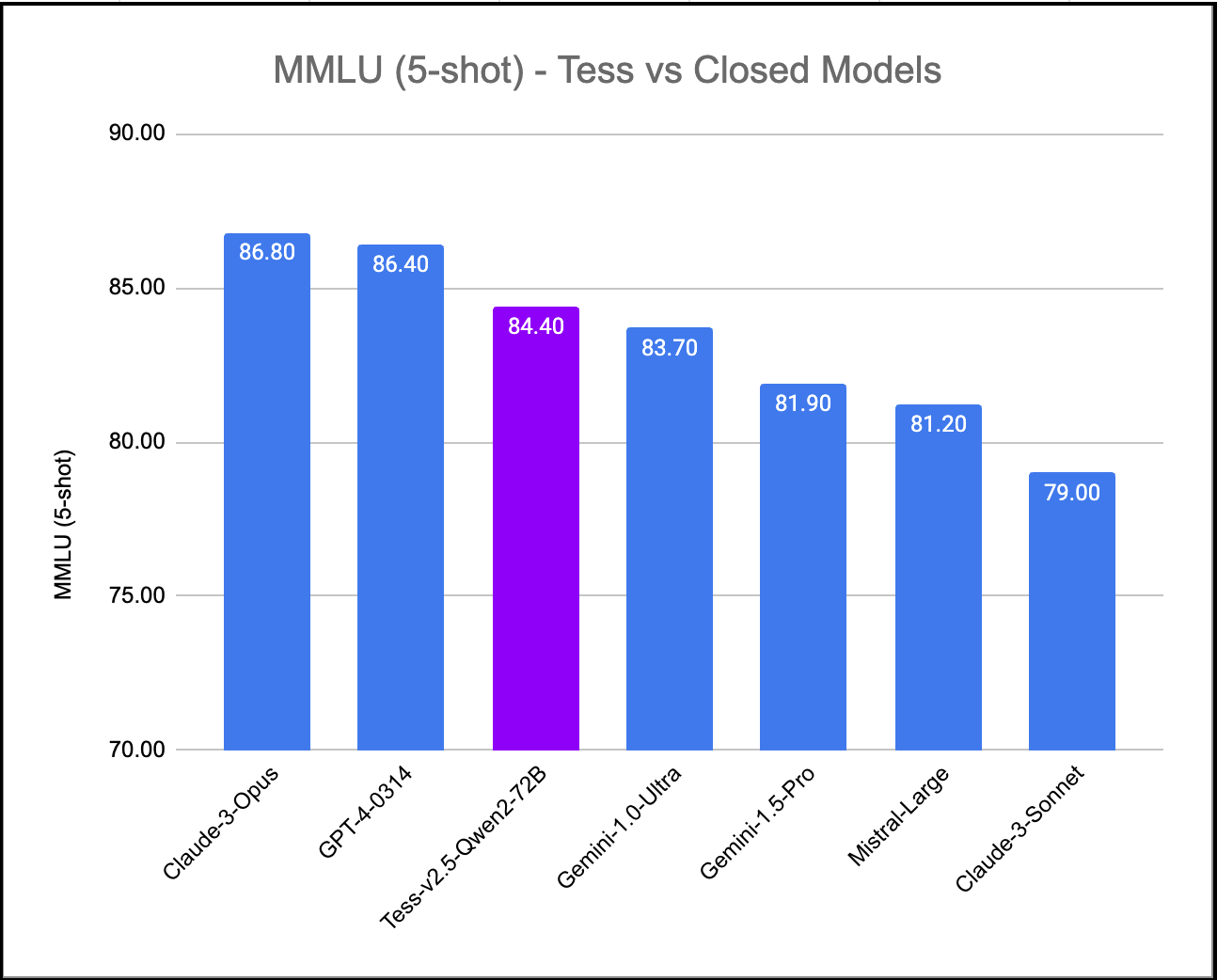
We've created Tess-v2.5, the latest state-of-the-art model in the Tess series of Large Language Models (LLMs). Tess, short for Tesoro (<em>Treasure</em> in Italian), is the flagship LLM series created by Migel Tissera. Tess-v2.5 brings significant improvements in reasoning capabilities, coding capabilities and mathematics. It is currently the #1 ranked open weight model when evaluated on MMLU (Massive Multitask Language Understanding). It scores higher than all other open weight models including Qwen2-72B-Instruct, Llama3-70B-Instruct, Mixtral-8x22B-Instruct and DBRX-Instruct. Further, when evaluated on MMLU, Tess-v2.5 (Qwen2-72B) model outperforms even the frontier closed models Gemini-1.0-Ultra, Gemini-1.5-Pro, Mistral-Large and Claude-3-Sonnet. |
|
|
|
Tess-v2.5 (Qwen2-72B) was fine-tuned over the newly released Qwen2-72B base, using the Tess-v2.5 dataset that contain 300K samples spanning multiple topics, including business and management, marketing, history, social sciences, arts, STEM subjects and computer programming. This dataset was synthetically generated using the [Sensei](https://github.com/migtissera/Sensei) framework, using multiple frontier models such as GPT-4-Turbo, Claude-Opus and Mistral-Large. |
|
|
|
The compute for this model was generously sponsored by [KindoAI](https://kindo.ai). |
|
|
|
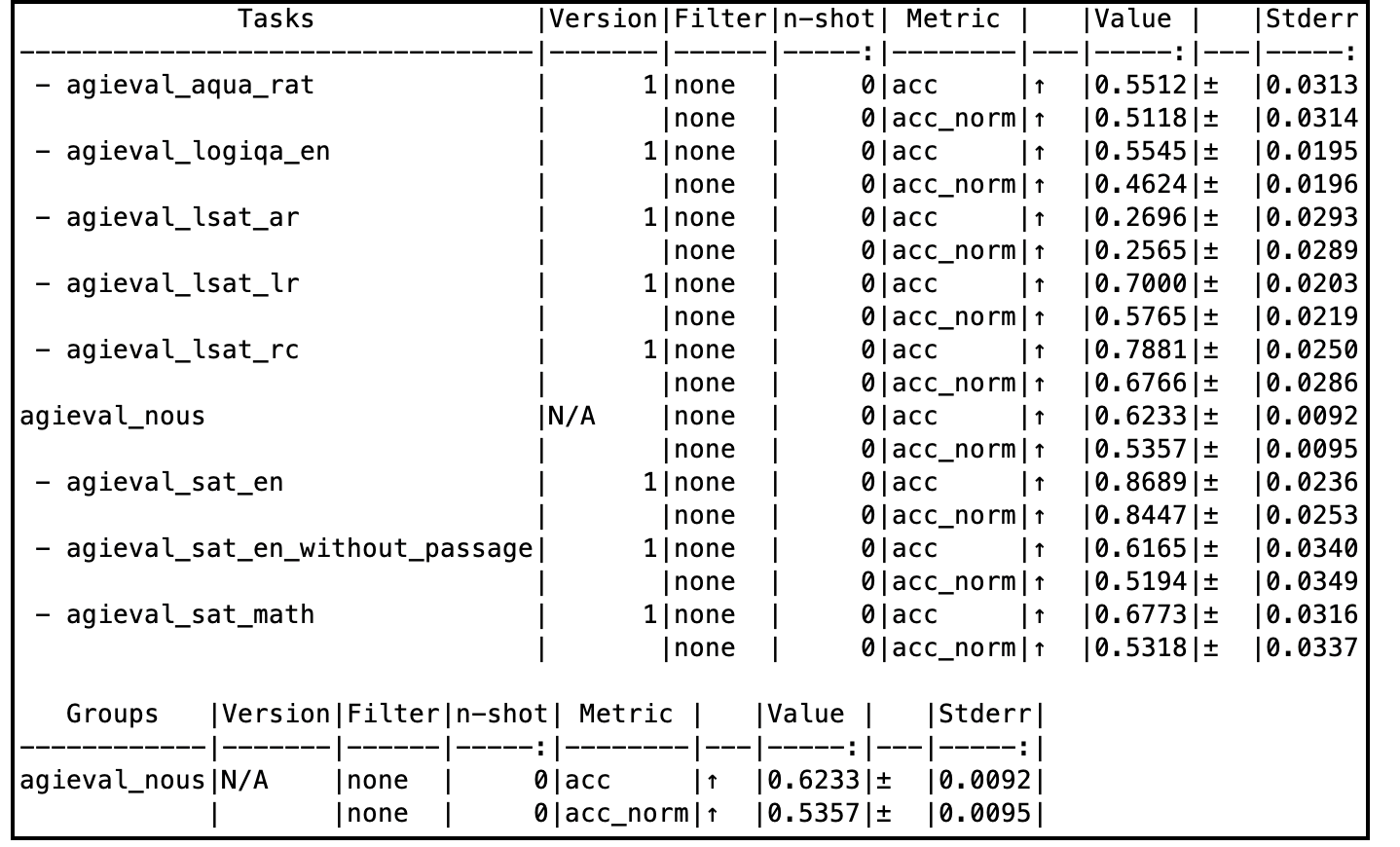
When evaluated on a subset of AGIEval (Nous), this model compares very well with the godfather GPT-4-0314 model as well. |
|
|
|
# Training Process |
|
|
|
Tess-v2.5 model was initiated with the base weights of Qwen2-72B. It was then fine-tuned with the Tess-v2.5 dataset, using Axolotl as the training framework. Most of Tess models follow a common fine-tuning methodology: low learning rates, low number of epochs, and uses very high quality and diverse data. This model was fine-tuned on a 4xA100 VM on Microsoft Azure for 4 days. The model has not been aligned with RLHF or DPO. |
|
|
|
The author believes that model's capabilities seem to come primariliy from the pre-training process. This is the foundation for every fine-tune of Tess models, and preserving the entropy of the base models is of paramount to the author. |
|
|
|
# Evaluation Results |
|
|
|
Tess-v2.5 model is an overall well balanced model. All evals pertaining to this model can be accessed in the [Evals](https://huggingface.co/migtissera/Tess-v2.5-Qwen2-72B/tree/main/Evals) folder. |
|
|
|
Complete evaluation comparison tables can be accessed here: [Google Spreadsheet](https://docs.google.com/spreadsheets/d/1k0BIKux_DpuoTPwFCTMBzczw17kbpxofigHF_0w2LGw/edit?usp=sharing) |
|
|
|
|
|
## MMLU (Massive Multitask Language Understanding) |
|
 |
|
|
|
 |
|
|
|
## AGIEval |
|
 |
|
|
|
|
|
# Sample code to run inference |
|
|
|
Note that this model uses ChatML prompt format. |
|
|
|
```python |
|
import torch, json |
|
from transformers import AutoModelForCausalLM, AutoTokenizer |
|
from stop_word import StopWordCriteria |
|
|
|
model_path = "migtissera/Tess-v2.5-Qwen2-72B" |
|
output_file_path = "/home/migel/conversations.jsonl" |
|
|
|
model = AutoModelForCausalLM.from_pretrained( |
|
model_path, |
|
torch_dtype=torch.float16, |
|
device_map="auto", |
|
load_in_4bit=False, |
|
trust_remote_code=True, |
|
) |
|
|
|
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True) |
|
|
|
terminators = [ |
|
tokenizer.convert_tokens_to_ids("<|im_end|>") |
|
] |
|
|
|
def generate_text(instruction): |
|
tokens = tokenizer.encode(instruction) |
|
tokens = torch.LongTensor(tokens).unsqueeze(0) |
|
tokens = tokens.to("cuda") |
|
|
|
instance = { |
|
"input_ids": tokens, |
|
"top_p": 1.0, |
|
"temperature": 0.75, |
|
"generate_len": 1024, |
|
"top_k": 50, |
|
} |
|
|
|
length = len(tokens[0]) |
|
with torch.no_grad(): |
|
rest = model.generate( |
|
input_ids=tokens, |
|
max_length=length + instance["generate_len"], |
|
use_cache=True, |
|
do_sample=True, |
|
top_p=instance["top_p"], |
|
temperature=instance["temperature"], |
|
top_k=instance["top_k"], |
|
num_return_sequences=1, |
|
pad_token_id=tokenizer.eos_token_id, |
|
eos_token_id=terminators, |
|
) |
|
output = rest[0][length:] |
|
string = tokenizer.decode(output, skip_special_tokens=True) |
|
return f"{string}" |
|
|
|
conversation = f"""<|im_start|>system\nYou are Tesoro, a helful AI assitant. You always provide detailed answers without hesitation.<|im_end|>\n<|im_start|>user\n""" |
|
|
|
while True: |
|
user_input = input("You: ") |
|
llm_prompt = f"{conversation}{user_input}<|im_end|>\n<|im_start|>assistant\n" |
|
answer = generate_text(llm_prompt) |
|
print(answer) |
|
conversation = f"{llm_prompt}{answer}\n" |
|
json_data = {"prompt": user_input, "answer": answer} |
|
|
|
with open(output_file_path, "a") as output_file: |
|
output_file.write(json.dumps(json_data) + "\n") |
|
``` |
|
|
|
# Join My General AI Discord (NeuroLattice): |
|
https://discord.gg/Hz6GrwGFKD |
|
|
|
# Limitations & Biases: |
|
|
|
While this model aims for accuracy, it can occasionally produce inaccurate or misleading results. |
|
|
|
Despite diligent efforts in refining the pretraining data, there remains a possibility for the generation of inappropriate, biased, or offensive content. |
|
|
|
Exercise caution and cross-check information when necessary. This is an uncensored model. |
|
|
