
Push Keras model using huggingface_hub.
Browse files- .gitattributes +1 -0
- README.md +39 -19
- fingerprint.pb +3 -0
- keras_metadata.pb +2 -2
- model.png +0 -0
- saved_model.pb +3 -0
- variables/variables.data-00000-of-00001 +3 -0
- variables/variables.index +0 -0
.gitattributes
CHANGED
|
@@ -36,3 +36,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 36 |
model[[:space:]]v3.keras filter=lfs diff=lfs merge=lfs -text
|
| 37 |
model-v3.keras filter=lfs diff=lfs merge=lfs -text
|
| 38 |
model.keras filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 36 |
model[[:space:]]v3.keras filter=lfs diff=lfs merge=lfs -text
|
| 37 |
model-v3.keras filter=lfs diff=lfs merge=lfs -text
|
| 38 |
model.keras filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
variables/variables.data-00000-of-00001 filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,30 +1,50 @@
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
- id
|
| 4 |
-
datasets:
|
| 5 |
-
- mabzak/indonesia-youtube-comment
|
| 6 |
-
widget:
|
| 7 |
-
- text: "Saya suka"
|
| 8 |
---
|
| 9 |
|
| 10 |
-
|
| 11 |
|
| 12 |
-
|
| 13 |
|
| 14 |
-
##
|
| 15 |
|
| 16 |
-
|
| 17 |
|
| 18 |
-
##
|
| 19 |
|
| 20 |
-
|
| 21 |
|
| 22 |
-
|
| 23 |
|
| 24 |
-
|
| 25 |
-
seed_text = "Saya suka"
|
| 26 |
-
predicted_sentence = predict_next_sentence(seed_text, model, tokenizer, max_sequence_length, num_words=9)
|
| 27 |
-
print("Kalimat yang Diprediksi:", predicted_sentence)
|
| 28 |
-
```
|
| 29 |
|
| 30 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
library_name: keras
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
| 4 |
|
| 5 |
+
## Model description
|
| 6 |
|
| 7 |
+
More information needed
|
| 8 |
|
| 9 |
+
## Intended uses & limitations
|
| 10 |
|
| 11 |
+
More information needed
|
| 12 |
|
| 13 |
+
## Training and evaluation data
|
| 14 |
|
| 15 |
+
More information needed
|
| 16 |
|
| 17 |
+
## Training procedure
|
| 18 |
|
| 19 |
+
### Training hyperparameters
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
+
The following hyperparameters were used during training:
|
| 22 |
+
|
| 23 |
+
| Hyperparameters | Value |
|
| 24 |
+
| :-- | :-- |
|
| 25 |
+
| name | Adam |
|
| 26 |
+
| weight_decay | None |
|
| 27 |
+
| clipnorm | None |
|
| 28 |
+
| global_clipnorm | None |
|
| 29 |
+
| clipvalue | None |
|
| 30 |
+
| use_ema | False |
|
| 31 |
+
| ema_momentum | 0.99 |
|
| 32 |
+
| ema_overwrite_frequency | None |
|
| 33 |
+
| jit_compile | True |
|
| 34 |
+
| is_legacy_optimizer | False |
|
| 35 |
+
| learning_rate | 0.0010000000474974513 |
|
| 36 |
+
| beta_1 | 0.9 |
|
| 37 |
+
| beta_2 | 0.999 |
|
| 38 |
+
| epsilon | 1e-07 |
|
| 39 |
+
| amsgrad | False |
|
| 40 |
+
| training_precision | float32 |
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
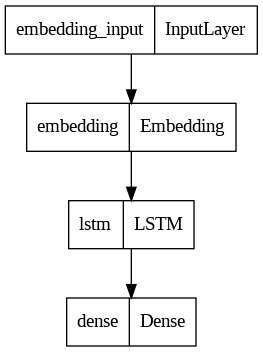
## Model Plot
|
| 44 |
+
|
| 45 |
+
<details>
|
| 46 |
+
<summary>View Model Plot</summary>
|
| 47 |
+
|
| 48 |
+

|
| 49 |
+
|
| 50 |
+
</details>
|
fingerprint.pb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ab55a949ac879df2d85d64a1b1c3dd6f65f8aea908d8f509124d3b76e1a704ba
|
| 3 |
+
size 58
|
keras_metadata.pb
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:438d6b3d8eab6b5ae104e596bba206ae0794156effa661496ac97f8ee7ea88ba
|
| 3 |
+
size 10118
|
model.png
ADDED
|
saved_model.pb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5e5960c424747c13b35feb410a215cd6b9f777c9d71ed9aed041961a3ca11ce0
|
| 3 |
+
size 622142
|
variables/variables.data-00000-of-00001
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1aabf1d4d7799aa049196fa17c18ab33e53d123bd9b7045e0b73f188fd7358ce
|
| 3 |
+
size 18304732
|
variables/variables.index
ADDED
|
Binary file (662 Bytes). View file
|
|
|