

language:
- en
pipeline_tag: text-generation
tags:
- code
license: apache-2.0
OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement
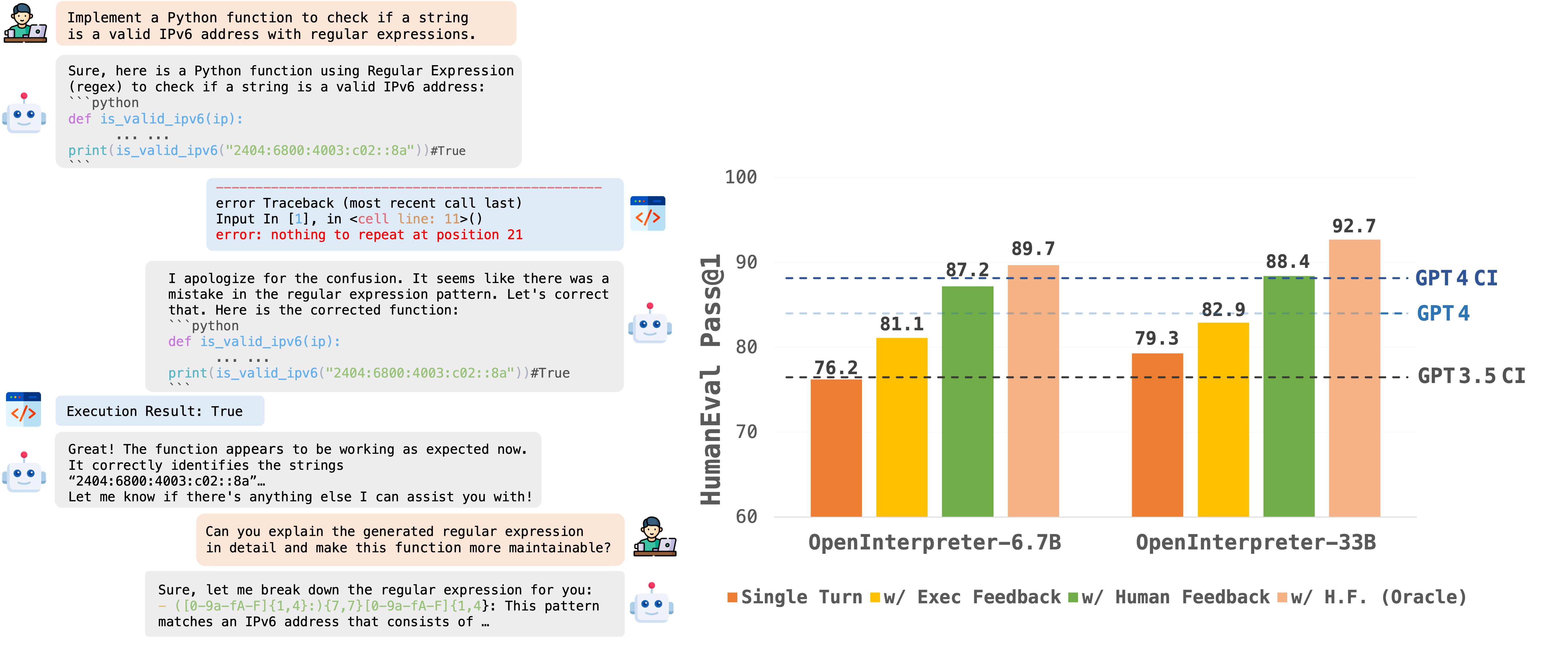
Introduction
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: "OpenCodeInterpreter: A System for Enhanced Code Generation and Execution" available on arXiv.
Model Information
This model is based on deepseek-coder-1.3b-base.
Benchmark Scores
The performance of the OpenCodeInterpreter-DS-1.3B is highlighted below, showcasing the improvements when execution feedback is incorporated. Scores are presented for two benchmarks: HumanEval and MBPP, with an average increase indicated to demonstrate the overall enhancement in performance.
| Benchmark | HumanEval (+) | MBPP (+) | Average (+) |
|---|---|---|---|
| OpenCodeInterpreter-DS-1.3B | 0.652 (0.61) | 0.634 (0.524) | 0.643 (0.567) |
| + Execution Feedback | 0.652 (0.622) | 0.652 (0.556) | 0.652 (0.589) |
Note: The values in parentheses represent scores prior to the integration of execution feedback, illustrating the performance improvements across benchmarks.
Model Usage
Inference
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="m-a-p/OpenCodeInterpreter-DS-1.3B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
Contact
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. We're here to assist you!"