
Update README.md
Browse files
README.md
CHANGED
|
@@ -13,22 +13,22 @@ tags:
|
|
| 13 |
|
| 14 |
# Model Card for Model ID
|
| 15 |
|
| 16 |
-
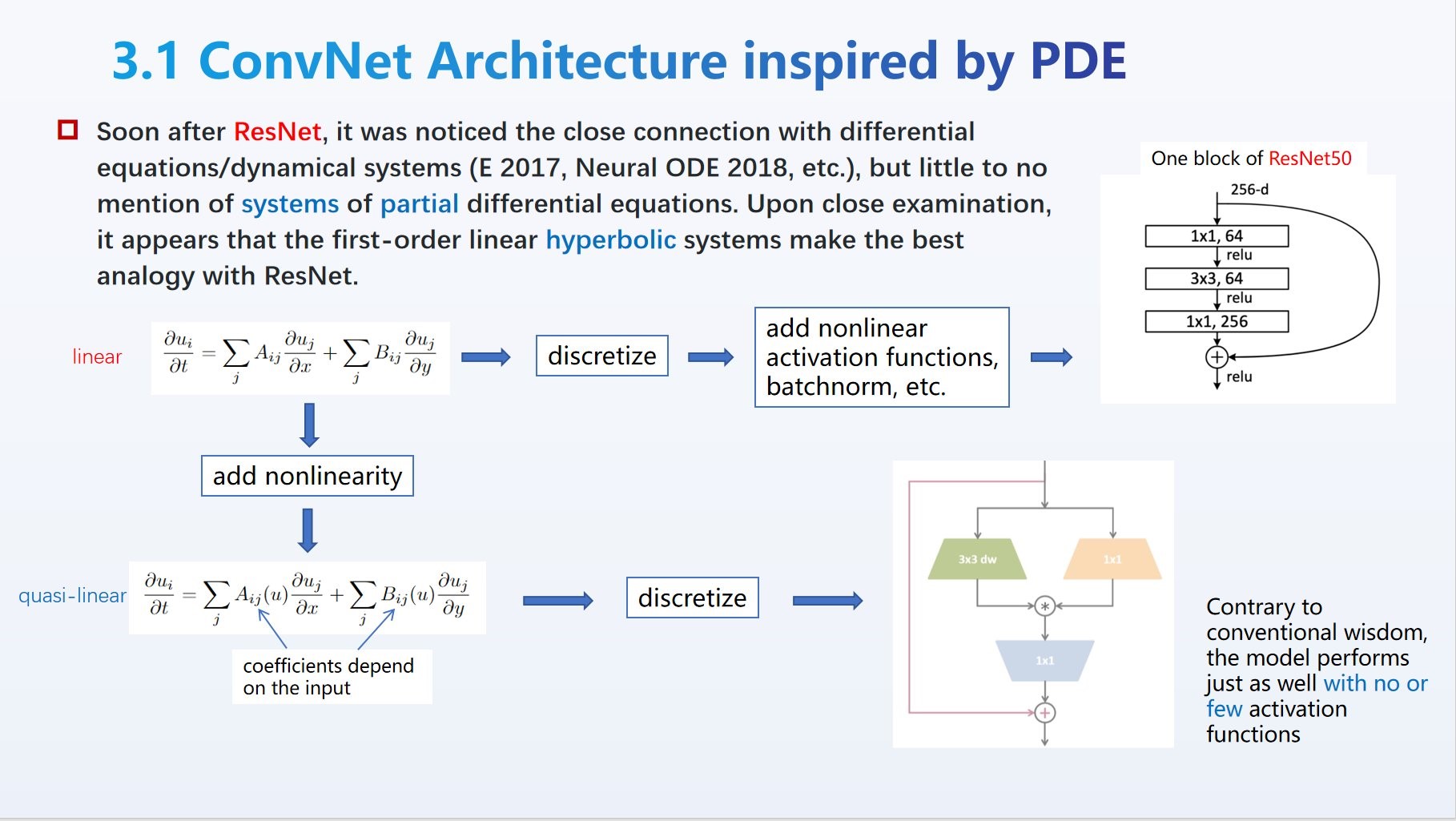
Based on a class of partial differential equations called **quasi-linear hyperbolic systems** [[Liu et al, 2023](https://github.com/liuyao12/ConvNets-PDE-perspective)], the **QLNet** breaks into uncharted waters of ConvNet model space marked by the use of (element-wise) multiplication in lieu of ReLU as the primary nonlinearity. It achieves comparable performance as ResNet50 on ImageNet-1k (acc=**78.61**), demonstrating that it has the same level of capacity/expressivity, and deserves
|
| 17 |
|
| 18 |
-
The overall architecture
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
-
One notable feature is that the architecture (trained or not) admits a *continuous* symmetry in its parameters. Check out the [notebook](https://colab.research.google.com/#fileId=https://huggingface.co/liuyao/QLNet/blob/main/QLNet_symmetry.ipynb) for a demo that makes a
|
| 23 |
|
| 24 |
FAQ (as the author imagines):
|
| 25 |
|
| 26 |
- **Q**: *Who needs another ConvNet, when the SOTA for ImageNet-1k is now in the low 80s with models of comparable size?*
|
| 27 |
-
- **A**: Aside from lack of resources to perform extensive experiments, the real answer is that the new symmetry has the potential to be exploited (
|
| 28 |
- **Q**: *Multiplication is too simple, someone must have tried it?*
|
| 29 |
- **A**: Perhaps. My guess is whoever tried it soon found the model fail to train with standard ReLU. Without the conviction in the underlying PDE perspective, maybe it wasn't pushed to its limit.
|
| 30 |
- **Q**: *Is it not similar to attention in Transformer?*
|
| 31 |
-
- **A**:
|
| 32 |
- **Q**: *If the parameter space has a symmetry (beyond permutations), perhaps there's redundancy in the weights.*
|
| 33 |
- **A**: The transformation in our demo indeed can be used to reduce the weights from the get-go. However, there are variants of the model that admit a much larger symmetry. It is also related to the phenomenon of "flat minima" found empirically in some conventional neural networks.
|
| 34 |
|
|
|
|
| 13 |
|
| 14 |
# Model Card for Model ID
|
| 15 |
|
| 16 |
+
Based on a class of partial differential equations called **quasi-linear hyperbolic systems** [[Liu et al, 2023](https://github.com/liuyao12/ConvNets-PDE-perspective)], the **QLNet** breaks into uncharted waters of ConvNet model space marked by the use of (element-wise) multiplication in lieu of ReLU as the primary nonlinearity. It achieves comparable performance as ResNet50 on ImageNet-1k (acc=**78.61**), demonstrating that it has the same level of capacity/expressivity, and deserves further analysis and study (hyper-paremeter tuning, optimizer, etc.) by the academic community.
|
| 17 |
|
| 18 |
+
The overall architecture follows that of the origianl ConvNet (LeCun) and ResNet (He et al.), with the adoption of "depthwise convolution" as in MobileNet.
|
| 19 |
|
| 20 |

|
| 21 |
|
| 22 |
+
One notable feature is that the architecture (trained or not) admits a *continuous* symmetry in its parameters. Check out the [notebook](https://colab.research.google.com/#fileId=https://huggingface.co/liuyao/QLNet/blob/main/QLNet_symmetry.ipynb) for a demo that makes a transformation on the weights while leaving the output *unchanged*.
|
| 23 |
|
| 24 |
FAQ (as the author imagines):
|
| 25 |
|
| 26 |
- **Q**: *Who needs another ConvNet, when the SOTA for ImageNet-1k is now in the low 80s with models of comparable size?*
|
| 27 |
+
- **A**: Aside from a lack of resources to perform extensive experiments, the real answer is that the new symmetry has the potential to be exploited (as a kind of symmetry-aware optimization). The "non-activation" nonlinearity is more "natural" (coordinate independence) as in many equations in mathematics and physics. Activation (of neurons or units) is but a legacy from the early days of models inspired by *biological* neural networks.
|
| 28 |
- **Q**: *Multiplication is too simple, someone must have tried it?*
|
| 29 |
- **A**: Perhaps. My guess is whoever tried it soon found the model fail to train with standard ReLU. Without the conviction in the underlying PDE perspective, maybe it wasn't pushed to its limit.
|
| 30 |
- **Q**: *Is it not similar to attention in Transformer?*
|
| 31 |
+
- **A**: Yes, indeed. It's natural to wonder if the activation functions in Transformer could be removed (or reduced) while still achieve comparable performance.
|
| 32 |
- **Q**: *If the parameter space has a symmetry (beyond permutations), perhaps there's redundancy in the weights.*
|
| 33 |
- **A**: The transformation in our demo indeed can be used to reduce the weights from the get-go. However, there are variants of the model that admit a much larger symmetry. It is also related to the phenomenon of "flat minima" found empirically in some conventional neural networks.
|
| 34 |
|