
Update README.md
Browse files
README.md
CHANGED
|
@@ -7,8 +7,8 @@ tags:
|
|
| 7 |
- not-for-all-audiences
|
| 8 |
---
|
| 9 |
|
| 10 |
-
# Limamono-7B (Mistral) v0.
|
| 11 |
-
This is a **very early version** (
|
| 12 |
_extremely limited_ amounts of almost entirely synthetic data of hopefully higher quality than typical
|
| 13 |
human conversations. The intended model audience is straight men and lesbians.
|
| 14 |
|
|
@@ -26,9 +26,9 @@ Other formats are not supported and may conflict with the special features of th
|
|
| 26 |
|
| 27 |
## Known issues and quirks
|
| 28 |
- The model may feel somewhat "overbaked".
|
| 29 |
-
- Characters may occasionally exhibit strange (unintended) speech quirks.
|
| 30 |
-
- Impersonation may
|
| 31 |
-
character message length.
|
| 32 |
|
| 33 |
## Prompt format
|
| 34 |
Limamono uses a slight variation of the [extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
|
|
@@ -58,8 +58,8 @@ Scenario: {{scenario}}
|
|
| 58 |
```
|
| 59 |
|
| 60 |
More in detail, the instruction should _preferably_ include a moderately long (a few hundred tokens
|
| 61 |
-
long) character description made in the style of the various fandom wikis on the Internet, with the
|
| 62 |
-
character name as the first line
|
| 63 |
|
| 64 |
You can refer to the included [Charlotte model card](https://huggingface.co/lemonilia/Limamono-Mistral-7B-v0.3/blob/main/Charlotte.png)
|
| 65 |
for an example on how characer descriptions can be formatted, but another option would be taking a
|
|
@@ -108,10 +108,9 @@ should be placed with a space _after_ the colon:
|
|
| 108 |
This has an effect on bot responses, but as of now it might not always reliably work. The lengths
|
| 109 |
used during training are: `micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`.
|
| 110 |
|
| 111 |
-
|
| 112 |
-
_temporary measure_ for increasing message length in case they become too short.
|
| 113 |
|
| 114 |
-
|
| 115 |
`### Input:` sequence, in order to help the model follow more closely its training data.
|
| 116 |
|
| 117 |
## Prose style
|
|
@@ -151,8 +150,11 @@ in the repository.
|
|
| 151 |
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
|
| 152 |
on one NVidia RTX3090.
|
| 153 |
|
| 154 |
-
The training data consisted of **
|
| 155 |
-
of roughly 4k tokens length.
|
|
|
|
|
|
|
|
|
|
| 156 |
|
| 157 |
### Training hyperparameters
|
| 158 |
- load_in_8bit: true
|
|
@@ -168,10 +170,17 @@ of roughly 4k tokens length.
|
|
| 168 |
- num_epochs: 3
|
| 169 |
- optimizer: adamw_torch
|
| 170 |
- lr_scheduler: constant
|
| 171 |
-
- learning_rate: 0.
|
| 172 |
- weight_decay: 0.1
|
| 173 |
- train_on_inputs: false
|
| 174 |
- group_by_length: false
|
| 175 |
- bf16: true
|
| 176 |
- fp16: false
|
| 177 |
-
- tf32: true
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
- not-for-all-audiences
|
| 8 |
---
|
| 9 |
|
| 10 |
+
# Limamono-7B (Mistral) v0.43
|
| 11 |
+
This is a **very early version** (43% completed) of a strongly NSFW roleplaying model trained with
|
| 12 |
_extremely limited_ amounts of almost entirely synthetic data of hopefully higher quality than typical
|
| 13 |
human conversations. The intended model audience is straight men and lesbians.
|
| 14 |
|
|
|
|
| 26 |
|
| 27 |
## Known issues and quirks
|
| 28 |
- The model may feel somewhat "overbaked".
|
| 29 |
+
- Characters may occasionally exhibit strange (unintended) speech quirks. Please report if found.
|
| 30 |
+
- Impersonation may sometimes occur early in the chat, in particular when trying to force a very
|
| 31 |
+
long character message length or regenerating the greeting message.
|
| 32 |
|
| 33 |
## Prompt format
|
| 34 |
Limamono uses a slight variation of the [extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
|
|
|
|
| 58 |
```
|
| 59 |
|
| 60 |
More in detail, the instruction should _preferably_ include a moderately long (a few hundred tokens
|
| 61 |
+
long) character description made in the style of the various fandom wikis on the Internet, **with the
|
| 62 |
+
character name as the first line**.
|
| 63 |
|
| 64 |
You can refer to the included [Charlotte model card](https://huggingface.co/lemonilia/Limamono-Mistral-7B-v0.3/blob/main/Charlotte.png)
|
| 65 |
for an example on how characer descriptions can be formatted, but another option would be taking a
|
|
|
|
| 108 |
This has an effect on bot responses, but as of now it might not always reliably work. The lengths
|
| 109 |
used during training are: `micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`.
|
| 110 |
|
| 111 |
+
From extended testing, a **long** length was found to work reasonably well.
|
|
|
|
| 112 |
|
| 113 |
+
It is also suggested to add `(length = tiny)` or `(length = short)` to the
|
| 114 |
`### Input:` sequence, in order to help the model follow more closely its training data.
|
| 115 |
|
| 116 |
## Prose style
|
|
|
|
| 150 |
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
|
| 151 |
on one NVidia RTX3090.
|
| 152 |
|
| 153 |
+
The training data consisted of **43** conversations (171k tokens / 763 messages)
|
| 154 |
+
of roughly 4k tokens length. The learning rate is the one that about minimizes the
|
| 155 |
+
eval loss on one epoch with a constant learning schedule. For the following two epochs
|
| 156 |
+
what would be normally considered overfitting occurs, but at the same time output
|
| 157 |
+
quality also improves.
|
| 158 |
|
| 159 |
### Training hyperparameters
|
| 160 |
- load_in_8bit: true
|
|
|
|
| 170 |
- num_epochs: 3
|
| 171 |
- optimizer: adamw_torch
|
| 172 |
- lr_scheduler: constant
|
| 173 |
+
- learning_rate: 0.0002
|
| 174 |
- weight_decay: 0.1
|
| 175 |
- train_on_inputs: false
|
| 176 |
- group_by_length: false
|
| 177 |
- bf16: true
|
| 178 |
- fp16: false
|
| 179 |
+
- tf32: true
|
| 180 |
+
|
| 181 |
+
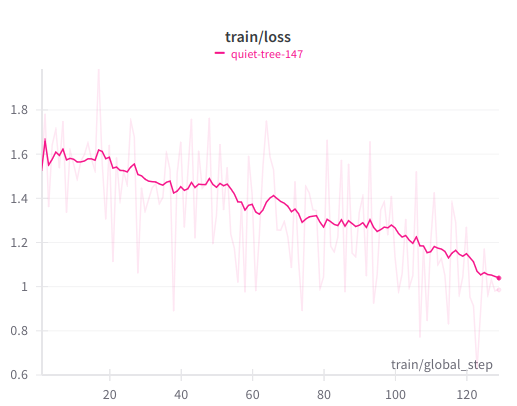
### Train loss graph
|
| 182 |
+
This one was obtained by experimentally repeating the data 3 times and finetuning for 1 epoch,
|
| 183 |
+
with similar end results but a smoother graph without sudden jumps compared to finetuning
|
| 184 |
+
unique data for 3 epochs.
|
| 185 |
+
|
| 186 |
+
|