

tags:
- math
- orchestration_of_experts
datasets:
- gsm8k
Leeroo Dedidcated Math Expert 🤗
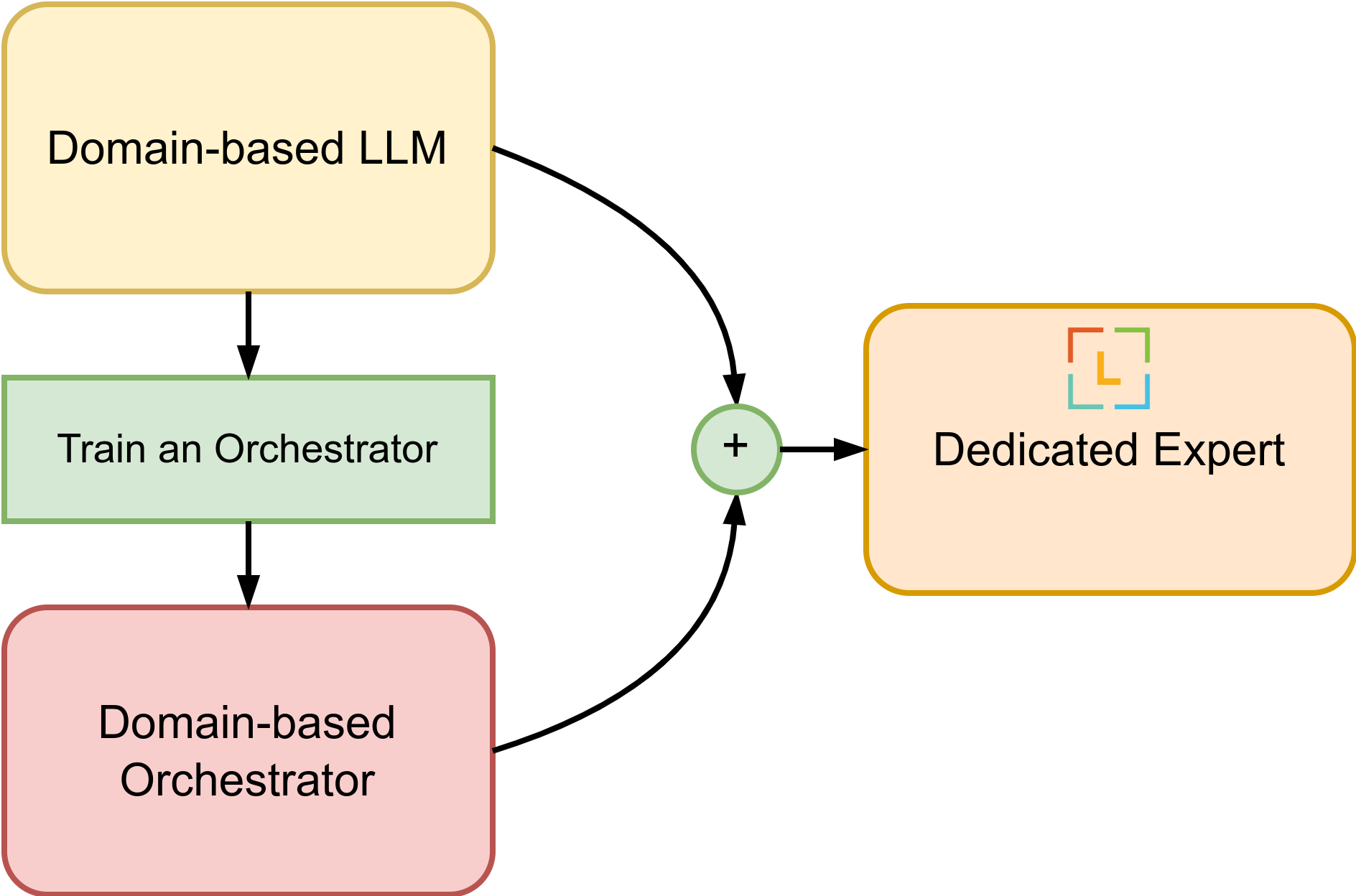
The model is built by applying Orchestration of Expert for the math domain. The dedicated model either generates solutions or, when necessary, utilizes GPT-4 (or similar performing LLM) to fill in gaps in its knowledge base. Specifically, when given an input, the dedicated model first determines if the input question is solvable with the base model. If solvable, the orchestrator is detached, and token generation is invoked using the base LLM expert. If the problem is difficult and requires a larger model like GPT-4, it produces <GPT4> token (i.e., token_id=32000).
The Orchestrator is first trained to estimate the knowledge of the base model, for any given query, then we marge into the base model (MetaMath7b, here).
In general for any domain, you can build it by:
- Choose a base LLM expert 🤗
- Train a domain-specific Orchestrator
- Merge Orchestrator with the base expert
✅ In evaluations using the GSM8k dataset of OpenLLM Leaderboard, Leeroo Math 7b model achieves an accuracy of 84.77% in 5-shot setting, positioning it among the top performers in its class and notably surpassing its base model, which scores 68.84% on the same dataset. This was accomplished while relying on GPT-4 for responses to half of the questions posed by GSM8k.
Sample Usage
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("leeroo/LeerooDedicated-Math-7b", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("leeroo/LeerooDedicated-Math-7b")
device = model.device
# the following question is answered by the leeroo expert
question = "Natalia sold clips to 48 of her friends in April,and then she sold half as many clips in May.How many clips did Natalia sell altogether in April and May?"
encodeds = tokenizer([question], return_tensors="pt")
model_inputs = encodeds['input_ids'].to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=False)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
# Natalia sold 48 clips in April.\nIn May, she sold half as many clips as in April,
# so she sold 48/2 = 24 clips.\nAltogether, Natalia sold 48 + 24 = 72 clips in April and May.\n#### 72\nThe answer is: 72</s>
# sends the following question to GPT4
question = "James loves to go swimming and has to swim across a 20-mile lake. He can swim at a pace of 2 miles per hour. He swims 60% of the distance. After that, he stops on an island and rests for half as long as the swimming time. He then finishes the remaining distance while going half the speed. How long did it take him to get across the lake?"
encodeds = tokenizer([question], return_tensors="pt")
model_inputs = encodeds['input_ids'].to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=False)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
# <GPT4></s>
You can also add your OpenAI API to get the full answer when <GPT4> token is generated:
from openai import OpenAI
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("leeroo/LeerooDedicated-Math-7b", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("leeroo/LeerooDedicated-Math-7b")
openai_client = OpenAI(
api_key= "OPENAI_API_KEY",
base_url= "https://api.openai.com/v1"
)
def generate(prompt, tokenizer, model, openai_client, max_new_tokens=100, verbose=True):
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k:v.to(model.device) for k,v in inputs.items()}
gen_tokens = model.generate( **inputs , max_new_tokens=max_new_tokens, do_sample=False, pad_token_id= tokenizer.pad_token_id)
if gen_tokens[0, inputs['input_ids'].shape[1]] != tokenizer.unk_token_id:
if verbose: print("\033[94mGenerating using MetaMath7b.\033[0m")
gen_text = tokenizer.decode(
gen_tokens[0, inputs['input_ids'].shape[1]:].tolist() )
else:
if verbose: print("\033[94mGenerating using gpt4.\033[0m")
gen_text = openai_client.completions.create(
model = "gpt-4-1106-preview", # NOTE you can use any bigger mode here having performance similar to gpt4
prompt = prompt,
max_tokens = max_new_tokens,
temperature = 0.0
).choices[0].text
return gen_text
# the following question is answered by the leeroo expert
prompt = "Question: Natalia sold clips to 48 of her friends in April,and then she sold half as many clips in May.How many clips did Natalia sell altogether in April and May?\nAnswer:"
generation = generate(prompt, tokenizer, model, openai_client, max_new_tokens=500)
print(generation)
#> Generating using MetaMath7b.
# Natalia sold 48 clips in April.\nIn May, she sold half as many clips as in April,
# so she sold 48/2 = 24 clips.\nAltogether, Natalia sold 48 + 24 = 72 clips in April and May.\n#### 72\nThe answer is: 72</s>
# sends the following question to GPT4
prompt = "James loves to go swimming and has to swim across a 40-mile lake. He can swim at a pace of 2 miles per hour. He swims 60% of the distance. After that, he stops on an island and rests for half as long as the swimming time. He then finishes the remaining distance while going half the speed. How many hours did it take him to get across the lake?"
generation = generate(prompt, tokenizer, model, openai_client, max_new_tokens=500)
print(generation)
#> Generating using gpt4.
# He swam 40*.6=24 miles
# So he swam for 24/2=12 hours
# He rested for 12/2=6 hours
# He had 40-24=16 miles left to swim
# He swam at 2/2=1 mile per hour
# So he swam for 16/1=16 hours
# So in total, it took him 12+6+16=34 hours
# 34
Learn More
🔍 To a deeper dive into our method and results, refer to HF blog 🤗, publication, and repository.
🌍 Join Leeroo community for further updates: Linkedin, Discord, X, Website.
Citation
@misc{mohammadshahi2024leeroo,
title={Leeroo Orchestrator: Elevating LLMs Performance Through Model Integration},
author={Alireza Mohammadshahi and Ali Shaikh and Majid Yazdani},
year={2024},
eprint={2401.13979},
archivePrefix={arXiv},
primaryClass={cs.CL}
}