Token 分類

我們將探索的第一個應用是Token分類。這個通用任務包括任何可以表述為“為句子中的詞或字分配標籤”的問題,例如:
- 實體命名識別 (NER): 找出句子中的實體(如人物、地點或組織)。這可以通過為每個實體或“無實體”指定一個類別的標籤。
- 詞性標註 (POS): 將句子中的每個單詞標記為對應於特定的詞性(如名詞、動詞、形容詞等)。
- 分塊(chunking): 找到屬於同一實體的Token。這個任務(可結合POS或NER)可以任何將一塊Token作為制定一個標籤(通常是B -),另一個標籤(通常I -)表示Token是否是同一塊,和第三個標籤(通常是O)表示Token不屬於任何塊。也就是標出句子中的短語塊,例如名詞短語(NP),動詞短語(VP)等。
當然,還有很多其他類型的token分類問題;這些只是幾個有代表性的例子。在本節中,我們將在 NER 任務上微調模型 (BERT),然後該模型將能夠計算如下預測:
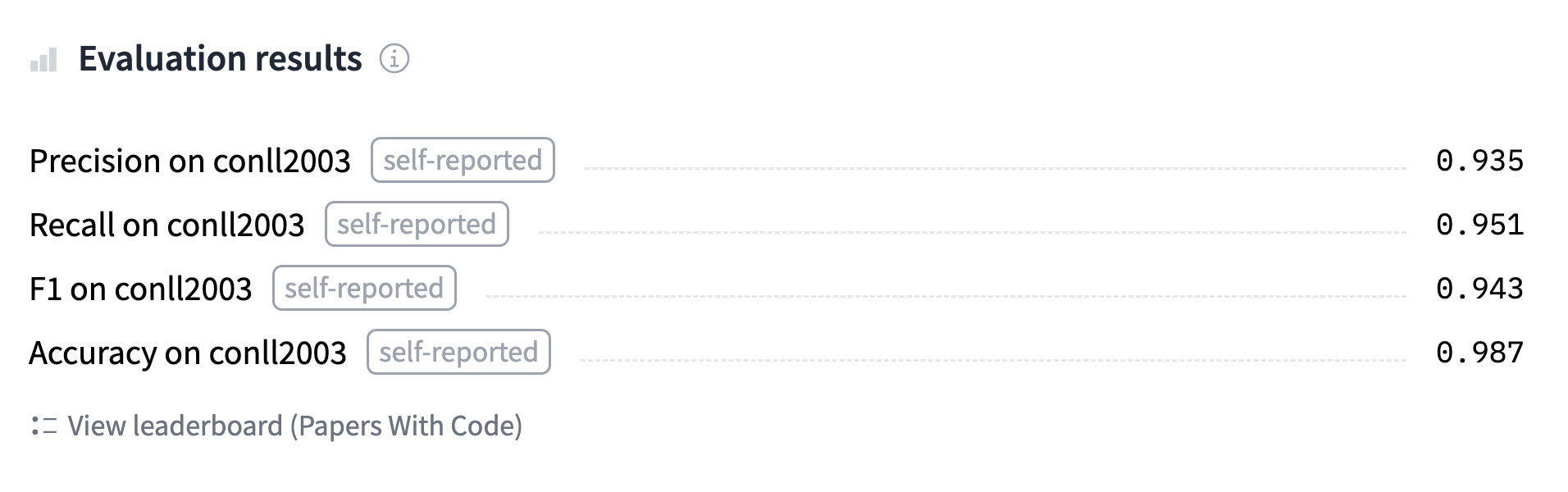
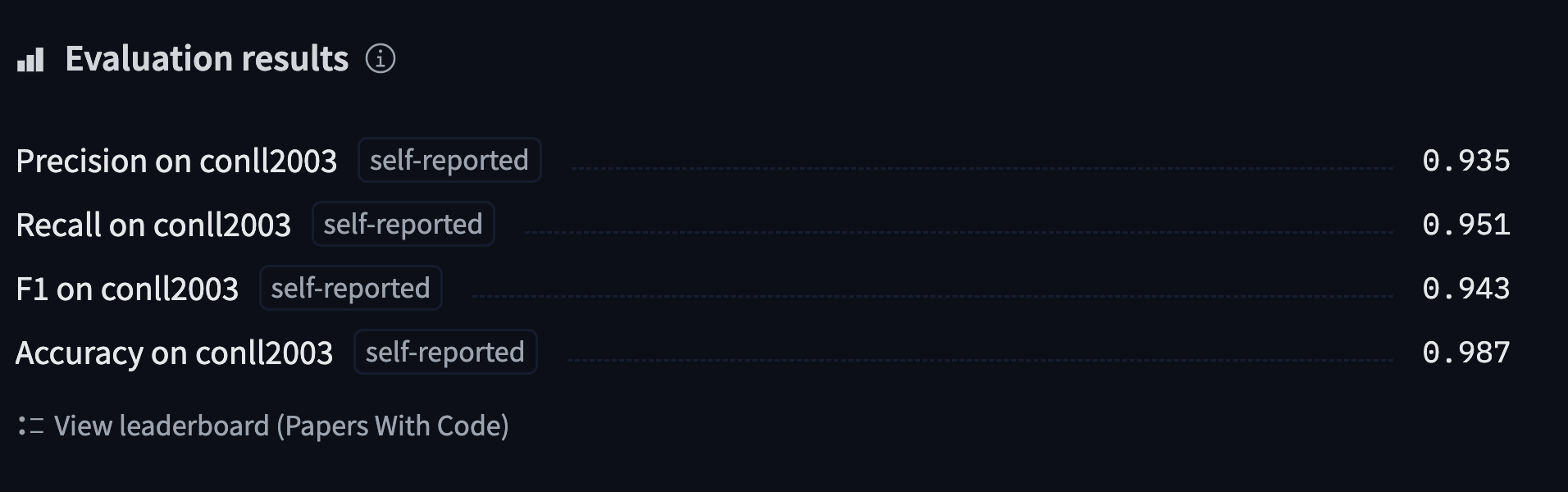
您可以在這裡.找到我們將訓練並上傳到 Hub的模型,可以嘗試輸入一些句子看看模型的預測結果。
準備數據
首先,我們需要一個適合標記分類的數據集。在本節中,我們將使用CoNLL-2003 數據集, 其中包含來自路透社的新聞報道。
💡 只要您的數據集由帶有相應標籤的分割成單詞並的文本組成,您就能夠將這裡描述的數據處理過程應用到您自己的數據集。如果需要複習如何在.Dataset中加載自定義數據,請參閱Chapter 5。
CoNLL-2003 數據集
要加載 CoNLL-2003 數據集,我們使用 來自 🤗 Datasets 庫的load_dataset() 方法:
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")這將下載並緩存數據集,就像和我們在第三章 加載GLUE MRPC 數據集一樣。檢查這個對象可以讓我們看到存在哪些列,以及訓練集、驗證集和測試集之間是如何分割的:
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})特別是,我們可以看到數據集包含我們之前提到的三個任務的標籤:NER、POS 和chunking。與其他數據集的一個很大區別是輸入文本不是作為句子或文檔呈現的,而是單詞列表(最後一列稱為 tokens ,但它包含的是這些詞是預先標記化的輸入,仍然需要通過標記器進行子詞標記)。
我們來看看訓練集的第一個元素:
raw_datasets["train"][0]["tokens"]['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']由於我們要執行命名實體識別,我們將查看 NER 標籤:
raw_datasets["train"][0]["ner_tags"][3, 0, 7, 0, 0, 0, 7, 0, 0]這一列是類標籤的序列。元素的類型在ner_feature的feature屬性中,我們可以通過查看該特性的names屬性來訪問名稱列表:
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_featureSequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)因此,這一列包含的元素是ClassLabels的序列。序列元素的類型在ner_feature的feature中,我們可以通過查看該feature的names屬性來訪問名稱列表:
label_names = ner_feature.feature.names label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']我們在第六章, 深入研究token-classification 管道時已經看到了這些標籤 ,但為了快速複習:
O表示這個詞不對應任何實體。B-PER/I-PER意味著這個詞對應於人名實體的開頭/內部。B-ORG/I-ORG的意思是這個詞對應於組織名稱實體的開頭/內部。B-LOC/I-LOC指的是是這個詞對應於地名實體的開頭/內部。B-MISC/I-MISC表示該詞對應於一個雜項實體的開頭/內部。
現在解碼我們之前看到的標籤:
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'例如混合 B- 和 I- 標籤,這是相同的代碼在索引 4 的訓練集元素上的預測結果:
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'正如我們所看到的,跨越兩個單詞的實體,如“European Union”和“Werner Zwingmann”,模型為第一個單詞標註了一個B-標籤,為第二個單詞標註了一個I-標籤。
✏️ 輪到你了! 使用 POS 或chunking標籤識別同一個句子。
處理數據
像往常一樣,我們的文本需要轉換為Token ID,然後模型才能理解它們。正如我們在第六章所學的那樣。不過在標記任務中,一個很大的區別是我們有pre-tokenized的輸入。幸運的是,tokenizer API可以很容易地處理這個問題;我們只需要用一個特殊的tokenizer。
首先,讓我們創建tokenizer對象。如前所述,我們將使用 BERT 預訓練模型,因此我們將從下載並緩存關聯的分詞器開始:
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)你可以更換把 model_checkpoint 更換為 Hub,上您喜歡的任何其他型號,或使用您本地保存的預訓練模型和分詞器。唯一的限制是分詞器需要由 🤗 Tokenizers 庫支持,有一個“快速”版本可用。你可以在這張大表, 上看到所有帶有快速版本的架構,或者檢查 您可以通過查看它is_fast 屬性來檢測正在使用的tokenizer對象是否由 🤗 Tokenizers 支持:
tokenizer.is_fast
True要對預先標記的輸入進行標記,我們可以像往常一樣使用我們的tokenizer 只需添加 is_split_into_words=True:
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']正如我們所見,分詞器添加了模型使用的特殊Token([CLS] 在開始和[SEP] 最後) 而大多數單詞未被修改。然而,單詞 lamb,被分為兩個子單詞 la and ##mb。這導致了輸入和標籤之間的不匹配:標籤列表只有9個元素,而我們的輸入現在有12個token 。計算特殊Token很容易(我們知道它們在開頭和結尾),但我們還需要確保所有標籤與適當的單詞對齊。
幸運的是,由於我們使用的是快速分詞器,因此我們可以訪問🤗 Tokenizers超能力,這意味著我們可以輕鬆地將每個令牌映射到其相應的單詞(如Chapter 6):
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]通過一點點工作,我們可以擴展我們的標籤列表以匹配token 。我們將應用的第一條規則是,特殊token 的標籤為 -100 。這是因為默認情況下 -100 是一個在我們將使用的損失函數(交叉熵)中被忽略的索引。然後,每個token 都會獲得與其所在單詞的token 相同的標籤,因為它們是同一實體的一部分。對於單詞內部但不在開頭的Token,我們將B- 替換為 I- (因為token 不以實體開頭):
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Start of a new word!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Special token
new_labels.append(-100)
else:
# Same word as previous token
label = labels[word_id]
# If the label is B-XXX we change it to I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labels讓我們在我們的第一句話上試一試:
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]正如我們所看到的,我們的函數為開頭和結尾的兩個特殊標記添加了 -100 ,併為分成兩個標記的單詞添加了一個新的0 。
✏️ 輪到你了! 一些研究人員更喜歡每個詞只歸屬一個標籤, 並分配 -100 給定詞中的其他子標記。這是為了避免分解成大量子標記的長詞對損失造成嚴重影響。按照此規則更改前一個函數使標籤與輸入id對齊。
為了預處理我們的整個數據集,我們需要標記所有輸入並在所有標籤上應用 align_labels_with_tokens() 。為了利用我們的快速分詞器的速度優勢,最好同時對大量文本進行分詞,因此我們將編寫一個處理示例列表的函數並使用帶 batched=True 有選項的 Dataset.map()方法 .與我們之前的示例唯一不同的是當分詞器的輸入是文本列表(或者像例子中的單詞列表)時 word_ids() 函數需要獲取我們想要單詞的索引的ID,所以我們也添加它:
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputs請注意,我們還沒有填充我們的輸入;我們稍後會在使用數據整理器創建batch時這樣做。
我們現在可以一次性將所有預處理應用於數據集的其他部分:
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)我們已經完成了最難的部分!現在數據已經被預處理了,實際的訓練看起來很像我們第三章做的.
使用 Trainer API 微調模型
使用 Trainer 的實際代碼會和以前一樣;唯一的變化是數據整理成時批處理的方式和度量計算函數。
數據排序
我們不能像第三章那樣只使用一個 DataCollatorWithPadding 因為這隻會填充輸入(輸入 ID、注意掩碼和標記類型 ID)。在這裡我們的標籤應該以與輸入完全相同的方式填充,以便它們保持長度相同,使用 -100 ,這樣在損失計算中就可以忽略相應的預測。
這一切都是由一個 DataCollatorForTokenClassification完成.它是一個帶有填充的數據整理器它需要 tokenizer 用於預處理輸入:
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)為了在幾個樣本上測試這一點,我們可以在訓練集中的示例列表上調用它:
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])讓我們將其與數據集中第一個和第二個元素的標籤進行比較:
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]正如我們所看到的,第二組標籤的長度已經使用 -100 填充到與第一組標籤相同。
評估指標
為了讓 Trainer 在每個epoch計算一個度量,我們需要定義一個 compute_metrics() 函數,該函數接受預測和標籤數組,並返回一個包含度量名稱和值的字典
用於評估Token分類預測的傳統框架是 seqeval. 要使用此指標,我們首先需要安裝seqeval庫:
!pip install seqeval
然後我們可以通過加載它 load_metric() 函數就像我們在第三章做的那樣:
from datasets import load_metric
metric = load_metric("seqeval")這個評估方式與標準精度不同:它實際上將標籤列表作為字符串,而不是整數,因此在將預測和標籤傳遞給它之前,我們需要完全解碼它們。讓我們看看它是如何工作的。首先,我們將獲得第一個訓練示例的標籤:
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']然後我們可以通過更改索引 2 處的值來為那些創建假的預測:
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])請注意,該指標的輸入是預測列表(不僅僅是一個)和標籤列表。這是輸出:
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}它返回很多信息!我們獲得每個單獨實體以及整體的準確率、召回率和 F1 分數。對於我們的度量計算,我們將只保留總分,但可以隨意調整 compute_metrics() 函數返回您想要查看的所有指標。
這compute_metrics() 函數首先採用 logits 的 argmax 將它們轉換為預測(像往常一樣,logits 和概率的順序相同,因此我們不需要應用 softmax)。然後我們必須將標籤和預測從整數轉換為字符串。我們刪除標籤為 -100 所有值 ,然後將結果傳遞給 metric.compute() 方法:
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}現在已經完成了,我們幾乎準備好定義我們的 Trainer .我們只需要一個 model 微調!
定義模型
由於我們正在研究Token分類問題,因此我們將使用 AutoModelForTokenClassification 類。定義這個模型時要記住的主要事情是傳遞一些關於我們的標籤數量的信息。執行此操作的最簡單方法是將該數字傳遞給 num_labels 參數,但是如果我們想要一個很好的推理小部件,就像我們在本節開頭看到的那樣,最好設置正確的標籤對應關係。
它們應該由兩個字典設置, id2label 和 label2id ,其中包含從 ID 到標籤的映射,反之亦然:
id2label = {i: label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}現在我們可以將它們傳遞給 AutoModelForTokenClassification.from_pretrained() 方法,它們將在模型的配置中設置,然後保存並上傳到Hub:
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)就像我們在第三章,定義我們的 AutoModelForSequenceClassification ,創建模型會發出警告,提示一些權重未被使用(來自預訓練頭的權重)和一些其他權重被隨機初始化(來自新Token分類頭的權重),我們將要訓練這個模型。我們將在一分鐘內完成,但首先讓我們仔細檢查我們的模型是否具有正確數量的標籤:
model.config.num_labels
9⚠️ 如果模型的標籤數量錯誤,稍後調用Trainer.train()方法時會出現一個模糊的錯誤(類似於“CUDA error: device-side assert triggered”)。這是用戶報告此類錯誤的第一個原因,因此請確保進行這樣的檢查以確認您擁有預期數量的標籤。
微調模型
我們現在準備好訓練我們的模型了!在定義我們的 Trainer之前,我們只需要做最後兩件事:登錄 Hugging Face 並定義我們的訓練參數。如果您在notebook上工作,有一個方便的功能可以幫助您:
from huggingface_hub import notebook_login
notebook_login()這將顯示一個小部件,您可以在其中輸入您的 Hugging Face 賬號和密碼。如果您不是在notebook上工作,只需在終端中輸入以下行:
huggingface-cli login
Once this is done, we can define our TrainingArguments:
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)您之前已經看過其中的大部分內容:我們設置了一些超參數(例如學習率、要訓練的 epoch 數和權重衰減),然後我們指定 push_to_hub=True 表明我們想要保存模型並在每個時期結束時對其進行評估,並且我們想要將我們的結果上傳到模型中心。請注意,可以使用hub_model_id參數指定要推送到的存儲庫的名稱(特別是,必須使用這個參數來推送到一個組織)。例如,當我們將模型推送到huggingface-course organization, 我們添加了 hub_model_id=huggingface-course/bert-finetuned-ner 到 TrainingArguments 。默認情況下,使用的存儲庫將在您的命名空間中並以您設置的輸出目錄命名,因此在我們的例子中它將是 sgugger/bert-finetuned-ner。
💡 如果您正在使用的輸出目錄已經存在,那麼輸出目錄必須是從同一個存儲庫clone下來的。如果不是,您將在聲明 Trainer 時遇到錯誤,並且需要設置一個新名稱。
最後,我們只是將所有內容傳遞給 Trainer 並啟動訓練:
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()請注意,當訓練發生時,每次保存模型時(這裡是每個epooch),它都會在後臺上傳到 Hub。這樣,如有必要,您將能夠在另一臺機器上繼續您的訓練。
訓練完成後,我們使用 push_to_hub() 確保我們上傳模型的最新版本
trainer.push_to_hub(commit_message="Training complete")This command returns the URL of the commit it just did, if you want to inspect it:
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'這 Trainer 還創建了一張包含所有評估結果的模型卡並上傳。在此階段,您可以使用模型中心上的推理小部件來測試您的模型並與您的朋友分享。您已成功在Token分類任務上微調模型 - 恭喜!
如果您想更深入地瞭解訓練循環,我們現在將向您展示如何使用 🤗 Accelerate 做同樣的事情。
自定義訓練循環
現在讓我們看一下完整的訓練循環,這樣您可以輕鬆定義所需的部分。它看起來很像我們在第三章, 所做的,對評估進行了一些更改。
做好訓練前的準備
首先我們需要為我們的數據集構建 DataLoader 。我們將重用我們的 data_collator 作為一個 collate_fn 並打亂訓練集,但不打亂驗證集:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)接下來,我們重新實例化我們的模型,以確保我們不會從之前的訓練繼續訓練,而是再次從 BERT 預訓練模型開始:
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)然後我們將需要一個優化器。我們將使用經典 AdamW ,這就像 Adam ,但在應用權重衰減的方式上進行了改進:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)Once we have all those objects, we can send them to the accelerator.prepare() method:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 如果您在 TPU 上進行訓練,則需要將以上單元格中的所有代碼移動到專用的訓練函數中。有關詳細信息,請參閱 第3章。
現在我們已經發送了我們的 train_dataloader 到 accelerator.prepare() ,我們可以使用它的長度來計算訓練步驟的數量。請記住,我們應該始終在準備好dataloader後執行此操作,因為該方法會改變其長度。我們使用經典線性學習率調度:
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)最後,要將我們的模型推送到 Hub,我們需要創建一個 Repository 工作文件夾中的對象。如果您尚未登錄,請先登錄 Hugging Face。我們將從我們想要為模型提供的模型 ID 中確定存儲庫名稱(您可以自由地用自己的選擇替換 repo_name ;它只需要包含您的用戶名,可以使用get_full_repo_name()函數的查看目前的repo_name):
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'sgugger/bert-finetuned-ner-accelerate'Then we can clone that repository in a local folder. If it already exists, this local folder should be an existing clone of the repository we are working with:
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)We can now upload anything we save in output_dir by calling the repo.push_to_hub() method. This will help us upload the intermediate models at the end of each epoch.
Training loop
訓練循環
我們現在準備編寫完整的訓練循環。為了簡化它的評估部分,我們定義了這個 postprocess() 接受預測和標籤並將它們轉換為字符串列表的函數,也就是 metric對象需要的輸入格式:
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictions然後我們可以編寫訓練循環。在定義一個進度條來跟蹤訓練的進行後,循環分為三個部分:
- 訓練本身,這是對
train_dataloader的經典迭代,向前傳遞模型,然後反向傳遞和優化參數 - 評估,在獲得我們模型的輸出後:因為兩個進程可能將輸入和標籤填充成不同的形狀,在調用
gather()方法前我們需要使用accelerator.pad_across_processes()來讓預測和標籤形狀相同。如果我們不這樣做,評估要麼出錯,要麼永遠不會得到結果。然後,我們將結果發送給metric.add_batch(),並在計算循環結束後調用metric.compute()。 - 保存和上傳,首先保存模型和標記器,然後調用
repo.push_to_hub()。注意,我們使用參數blocking=False告訴🤗 hub 庫用在異步進程中推送。這樣,訓練將正常繼續,並且該(長)指令將在後臺執行。
這是訓練循環的完整代碼:
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# Necessary to pad predictions and labels for being gathered
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)果這是您第一次看到用 🤗 Accelerate 保存的模型,讓我們花點時間檢查一下它附帶的三行代碼:
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
第一行是不言自明的:它告訴所有進程等到都處於那個階段再繼續(阻塞)。這是為了確保在保存之前,我們在每個過程中都有相同的模型。然後獲取unwrapped_model,它是我們定義的基本模型。
accelerator.prepare()方法將模型更改為在分佈式訓練中工作,所以它不再有save_pretraining()方法;accelerator.unwrap_model()方法將撤銷該步驟。最後,我們調用save_pretraining(),但告訴該方法使用accelerator.save()而不是torch.save()。
當完成之後,你應該有一個模型,它產生的結果與Trainer的結果非常相似。你可以在hugs face-course/bert-fine - tuning -ner-accelerate中查看我們使用這個代碼訓練的模型。如果你想測試訓練循環的任何調整,你可以直接通過編輯上面顯示的代碼來實現它們!
使用微調模型
我們已經向您展示瞭如何使用我們在模型中心微調的模型和推理小部件。在本地使用它 pipeline ,您只需要指定正確的模型標識符:
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]太棒了!我們的模型與此管道的默認模型一樣有效!