LLM Course documentation
Классификация токенов
Классификация токенов

Первое приложение, которое мы рассмотрим, - это классификация токенов. Эта общая задача охватывает любую проблему, которую можно сформулировать как “присвоение метки каждому токену в предложении”, например:
- Распознавание именованных сущностей (Named entity recognition - NER): Поиск сущностей (например, лиц, мест или организаций) в предложении. Это можно сформулировать как приписывание метки каждому токену, имея один класс для сущности и один класс для “нет сущности”.
- Морфологическая разметка (Part-of-speech tagging - POS): Пометить каждое слово в предложении как соответствующее определенной части речи (например, существительное, глагол, прилагательное и т. д.).
- Выделение токенов (Chunking): Поиск токенов, принадлежащих одной и той же сущности. Эта задача (которая может быть объединена с POS или NER) может быть сформулирована как присвоение одной метки (обычно
B-) всем токенам, которые находятся в начале фрагмента текста, другой метки (обычноI-) - токенам, которые находятся внутри фрагмента текста, и третьей метки (обычноO) - токенам, которые не принадлежат ни к одному фрагменту.
Конечно, существует множество других типов задач классификации токенов; это лишь несколько показательных примеров. В этом разделе мы дообучим модель (BERT) для задачи NER, которая затем сможет вычислять прогнозы, подобные этому:
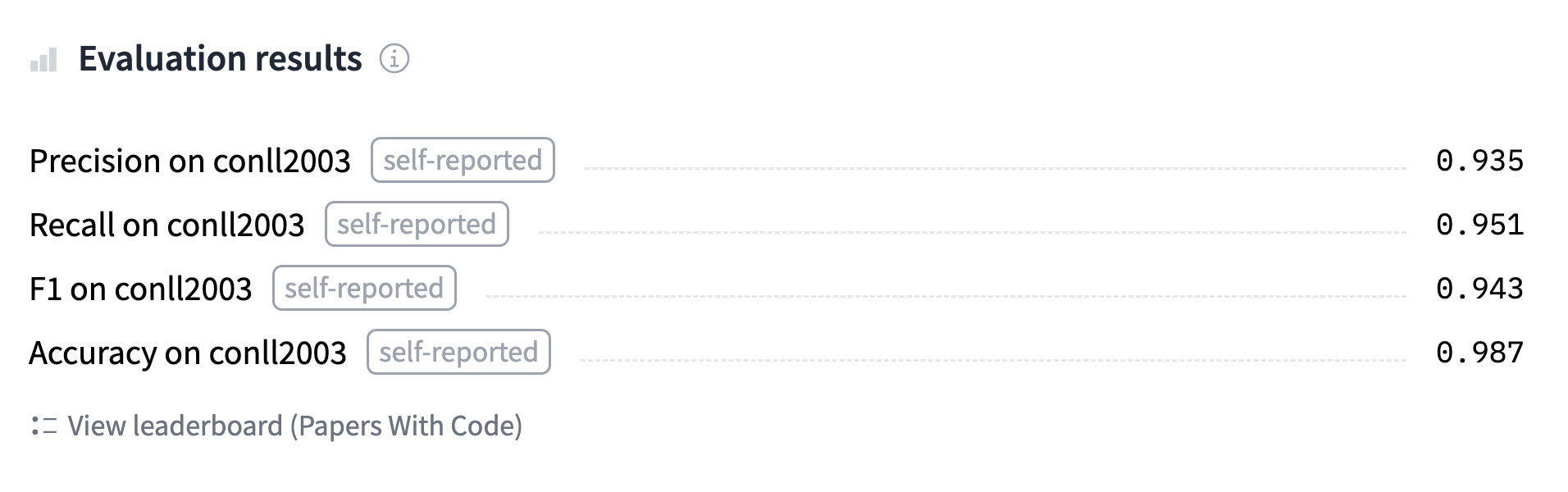
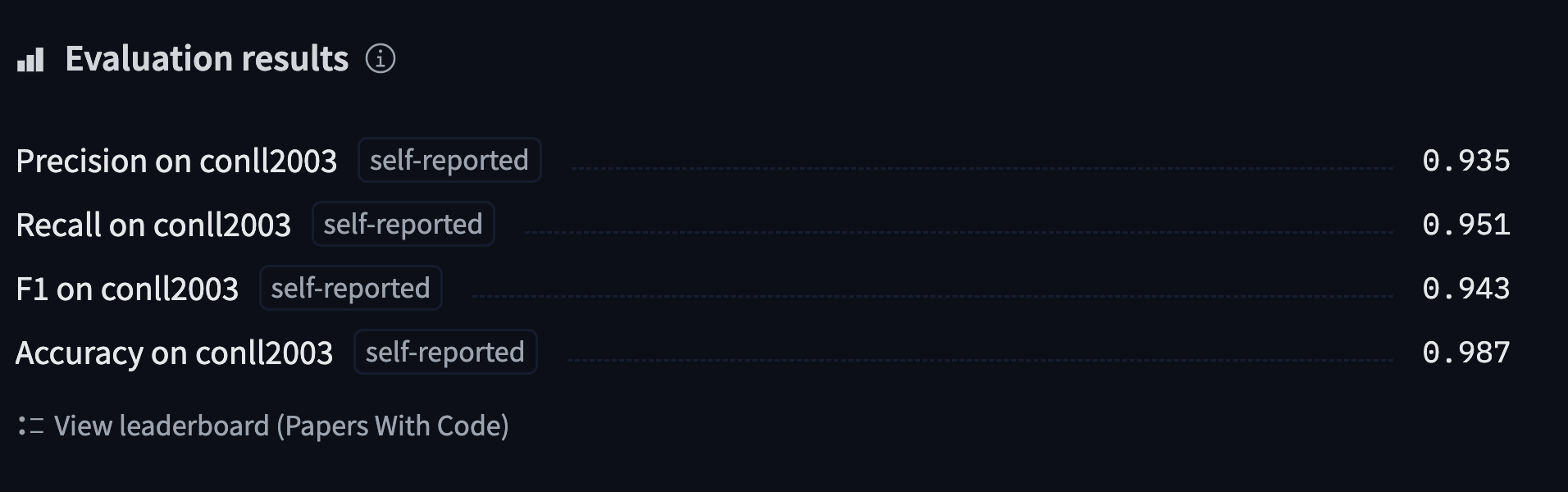
Вы можете найти модель, которую мы обучим и загрузим на хаб, и перепроверить ее предсказания здесь.
Подготовка данных
Прежде всего, нам нужен набор данных, подходящий для классификации токенов. В этом разделе мы будем использовать набор данных CoNLL-2003, который содержит новости от Reuters.
💡 Если ваш набор данных состоит из текстов, часть которых состоит из слов с соответствующими метками, вы сможете адаптировать описанные здесь процедуры обработки данных к своему набору данных. Обратитесь к Главе 5, если вам нужно освежить в памяти то, как загружать собственные данные в Dataset.
Датасет CoNLL-2003
Для загрузки датасета CoNLL-2003 мы используем метод load_dataset() из библиотеки 🤗 Datasets:
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")Это позволит загрузить и кэшировать датасет, как мы видели в Главе 3 для датасета GLUE MRPC. Изучение этого объекта показывает нам присутствующие столбцы и части тренировочного, проверочного и тестового наборов:
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})В частности, мы видим, что датасет содержит метки для трех задач, о которых мы говорили ранее: NER, POS и chunking. Существенным отличием от других датасетов является то, что входные тексты представлены не как предложения или документы, а как списки слов (последний столбец называется tokens, но он содержит слова в том смысле, что это предварительно токинизированные входные данные, которые еще должны пройти через токенизатор для токенизации по подсловам).
Давайте посмотрим на первый элемент обучающего набора:
raw_datasets["train"][0]["tokens"]['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']Поскольку мы хотим выполнить распознавание именованных сущностей, мы изучим теги NER:
raw_datasets["train"][0]["ner_tags"][3, 0, 7, 0, 0, 0, 7, 0, 0]Это метки в виде целых чисел, готовые для обучения, но они не всегда полезны, когда мы хотим проанализировать данные. Как и в случае с классификацией текста, мы можем получить доступ к соответствию между этими целыми числами и названиями меток, посмотрев на атрибут features нашего датасета:
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_featureSequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)Таким образом, этот столбец содержит элементы, которые являются последовательностями ClassLabel. Тип элементов последовательности указан в атрибуте feature этого ner_feature, и мы можем получить доступ к списку имен, посмотрев на атрибут names этого feature:
label_names = ner_feature.feature.names label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']Мы уже видели эти метки при изучении конвейера token-classification в Главе 6, но для краткости напомним:
Oозначает, что слово не соответствует какой-либо сущности.B-PER/I-PERозначает, что слово соответствует началу/находится внутри сущности персоны person.B-ORG/I-ORGозначает, что слово соответствует началу/находится внутри сущности organization.B-LOC/I-LOCозначает, что слово соответствует началу/находится внутри сущности location.B-MISC/I-MISCозначает, что слово соответствует началу/находится внутри сущности miscellaneous.
Теперь декодирование меток, которые мы видели ранее, дает нам следующее:
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'В качестве примера смешивания меток B- и I-, вот что дает тот же код для элемента обучающего множества с индексом 4:
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'Как мы видим, сущностям, состоящим из двух слов, например “European Union” и “Werner Zwingmann”, присваивается метка B- для первого слова и метка I- для второго.
✏️ Попробуйте! Выведите те же два предложения с метками POS или chunking.
Обработка данных
Как обычно, наши тексты должны быть преобразованы в идентификаторы токенов, прежде чем модель сможет понять их смысл. Как мы видели в Главе 6, существенным отличием задачи классификации токенов является то, что у нас есть предварительно токенизированные входные данные. К счастью, API токенизатора справляется с этим довольно легко; нам просто нужно предупредить tokenizer специальным флагом.
Для начала давайте создадим объект tokenizer. Как мы уже говорили, мы будем использовать предварительно обученную модель BERT, поэтому начнем с загрузки и кэширования соответствующего токенизатора:
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Вы можете заменить model_checkpoint на любую другую модель из Hub или на локальную папку, в которой вы сохранили предварительно обученную модель и токенизатор. Единственное ограничение - токенизатор должен быть создан с помощью библиотеки 🤗 Tokenizers, поэтому существует “быстрая” версия. Вы можете увидеть все архитектуры, которые поставляются с быстрой версией в этой большой таблице, а чтобы проверить, что используемый вами объект tokenizer действительно поддерживается 🤗 Tokenizers, вы можете посмотреть на его атрибут is_fast:
tokenizer.is_fast
TrueДля токенизации предварительно токинизированного ввода мы можем использовать наш tokenizer, как обычно, просто добавив is_split_into_words=True:
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']Как мы видим, токенизатор добавил специальные токены, используемые моделью ([CLS] в начале и [SEP] в конце), и оставил большинство слов нетронутыми. Слово lamb, однако, было токенизировано на два подслова, la и ##mb. Это вносит несоответствие между нашими входными данными и метками: список меток состоит всего из 9 элементов, в то время как наши входные данные теперь содержат 12 токенов. Учесть специальные токены легко (мы знаем, что они находятся в начале и в конце), но нам также нужно убедиться, что мы выровняли все метки с соответствующими словами.
К счастью, поскольку мы используем быстрый токенизатор, у нас есть доступ к суперспособностям 🤗 Tokenizers, что означает, что мы можем легко сопоставить каждый токен с соответствующим словом (как показано в Глава 6):
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]Немного поработав, мы сможем расширить список меток, чтобы он соответствовал токенам. Первое правило, которое мы применим, заключается в том, что специальные токены получают метку -100. Это связано с тем, что по умолчанию -100 - это индекс, который игнорируется в функции потерь, которую мы будем использовать (кросс-энтропия). Затем каждый токен получает ту же метку, что и токен, с которого началось слово, в котором он находится, поскольку они являются частью одной и той же сущности. Для токенов, находящихся внутри слова, но не в его начале, мы заменяем B- на I- (поскольку такие токены не являются началом сущности):
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Начало нового слова!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Специальный токен
new_labels.append(-100)
else:
# То же слово, что и предыдущий токен
label = labels[word_id]
# Если метка B-XXX, заменяем ее на I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labelsДавайте опробуем это на нашем первом предложении:
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]Как мы видим, наша функция добавила -100 для двух специальных токенов в начале и в конце и новый 0 для нашего слова, которое было разбито на две части.
✏️ Попробуйте! Некоторые исследователи предпочитают назначать только одну метку на слово и присваивать -100 другим подтокенам в данном слове. Это делается для того, чтобы длинные слова, часть которых состоит из множества субтокенов, не вносили значительный вклад в потери.
Чтобы предварительно обработать весь наш датасет, нам нужно провести токенизацию всех входных данных и применить align_labels_with_tokens() ко всем меткам. Чтобы воспользоваться преимуществами скорости нашего быстрого токенизатора, лучше всего токенизировать много текстов одновременно, поэтому мы напишем функцию, которая обрабатывает список примеров и использует метод Dataset.map() с параметром batched=True. Единственное отличие от нашего предыдущего примера заключается в том, что функция word_ids() должна получить индекс примера, идентификаторы слов которого нам нужны, с учётом того что входными данными для токенизатора являются списки текстов (или, в нашем случае, списки слов), поэтому мы добавляем и это:
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputsОбратите внимание, что мы еще не добавляли во входные данные дополняющие токены; мы сделаем это позже, при создании батчей с помощью коллатора данных.
Теперь мы можем применить всю эту предварительную обработку к другим частям нашего датасета:
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)Мы сделали самую сложную часть! Теперь, когда данные прошли предварительную обработку, само обучение будет выглядеть примерно так, как мы делали это в Главе 3.
Дообучение модели с помощью API Trainer
Фактический код, использующий Trainer, будет таким же, как и раньше; единственные изменения - это способ объединения данных в батч и функция вычисления метрики.
Сопоставление данных
Мы не можем просто использовать DataCollatorWithPadding, как в Главе 3, потому что в этом случае дополняются только входные данные (идентификаторы входов, маска внимания и идентификаторы типов токенов). Здесь наши метки должны быть дополнены точно так же, как и входы, чтобы они оставались одного размера, используя -100 в качестве значения, чтобы соответствующие прогнозы игнорировались при вычислении потерь.
Все это делает DataCollatorForTokenClassification. Как и DataCollatorWithPadding, он принимает токенизатор, используемый для предварительной обработки входных данных:
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)Чтобы проверить его на нескольких примерах, мы можем просто вызвать его на списке примеров из нашего токенизированного обучающего набора:
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])Давайте сравним это с метками для первого и второго элементов в нашем датасете:
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]Как мы видим, второй набор меток был дополнен до длины первого с помощью значения -100.
Метрики
Чтобы Trainer вычислял метрику каждую эпоху, нам нужно определить функцию compute_metrics(), которая принимает массивы прогнозов и меток и возвращает словарь с именами и значениями метрик.
Традиционно для оценки прогнозирования классификации токенов используется библиотека seqeval. Чтобы использовать эту метрику, сначала нужно установить библиотеку seqeval:
!pip install seqeval
Мы можем загрузить ее с помощью функции evaluate.load(), как мы это делали в Главе 3:
import evaluate
metric = evaluate.load("seqeval")Эта метрика ведет себя не так, как стандартная accuracy: на самом деле она принимает списки меток как строки, а не как целые числа, поэтому нам нужно полностью декодировать прогноз и метки перед передачей их в метрику. Давайте посмотрим, как это работает. Сначала мы получим метки для нашего первого обучающего примера:
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']Затем мы можем создать фальшивые прогнозы для них, просто изменив значение в индексе 2:
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])Обратите внимание, что метрика принимает список прогнозов (не только один) и список меток. Вот результат:
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}Она возвращает огромное количество информации! Мы получаем оценки precision, recall и F1 для каждой отдельной сущности, а также в целом. Для расчета метрик мы сохраним только общую оценку, но вы можете настроить функцию compute_metrics() так, чтобы она возвращала все метрики, которые вы хотите получить.
Эта функция compute_metrics() сначала берет argmax логитов, чтобы преобразовать их в прогнозы (как обычно, логиты и вероятности расположены в том же порядке, поэтому нам не нужно применять softmax). Затем нам нужно преобразовать метки и прогнозы из целых чисел в строки. Мы удаляем все значения, для которых метка равна -100, а затем передаем результаты в метод metric.compute():
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Удаляем игнорируемый индекс (специальные токены) и преобразуем в метки
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}Теперь, когда это сделано, мы почти готовы к определению нашего Trainer. Нам просто нужна model, чтобы дообучить ее!
Определение модели
Поскольку мы работаем над проблемой классификации токенов, мы будем использовать класс AutoModelForTokenClassification. Главное, что нужно помнить при определении этой модели, - это передать информацию о количестве имеющихся у нас меток. Проще всего передать это число с помощью аргумента num_labels, но если мы хотим получить красивый виджет инференса, подобный тому, что мы видели в начале этого раздела, то лучше задать правильное сопоставление меток.
Оно должно задаваться двумя словарями, id2label и label2id, которые содержат соответствие между идентификатором и меткой и наоборот:
id2label = {i: label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}Теперь мы можем просто передать их в метод AutoModelForTokenClassification.from_pretrained(), и они будут заданы в конфигурации модели, а затем правильно сохранены и загружены в Hub:
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)Как и в случае определения AutoModelForSequenceClassification в Главе 3, при создании модели выдается предупреждение о том, что некоторые веса не были использованы (те, что были получены из предварительно обученной головы), а другие инициализированы случайно (те, что были получены из новой головы классификации токенов), и что эту модель необходимо обучить. Мы сделаем это через минуту, но сначала давайте перепроверим, что наша модель имеет правильное количество меток:
model.config.num_labels
9⚠️ Если у вас есть модель с неправильным количеством меток, то при последующем вызове метода Trainer.train() вы получите непонятную ошибку (что-то вроде “CUDA error: device-side assert triggered”). Это главная причина ошибок, о которых сообщают пользователи, поэтому обязательно выполните эту проверку, чтобы убедиться, что у вас есть ожидаемое количество меток.
Дообучение модели
Теперь мы готовы к обучению нашей модели! Нам осталось сделать две последние вещи, прежде чем мы определим наш Trainer: войти в Hugging Face и определить наши аргументы для обучения. Если вы работаете в блокноте, есть удобная функция, которая поможет вам в этом:
from huggingface_hub import notebook_login
notebook_login()Появится виджет, в котором вы можете ввести свои учетные данные для входа в Hugging Face.
Если вы работаете не в ноутбуке, просто введите следующую строку в терминале:
huggingface-cli login
Как только это будет сделано, мы сможем определить наши TrainingArguments:
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)Большинство из них вы уже видели: мы задаем некоторые гиперпараметры (например, скорость обучения, количество эпох для обучения и затухание весов) и указываем push_to_hub=True, чтобы указать, что мы хотим сохранить модель и оценить ее в конце каждой эпохи, а также что мы хотим загрузить наши результаты в Model Hub. Обратите внимание, что с помощью аргумента hub_model_id можно указать имя репозитория, в который вы хотите передать модель (в частности, этот аргумент нужно использовать, чтобы передать модель в организацию). Например, когда мы передавали модель в организацию huggingface-course, мы добавили hub_model_id="huggingface-course/bert-finetuned-ner" в TrainingArguments. По умолчанию используемый репозиторий будет находиться в вашем пространстве имен и называться в соответствии с заданным вами выходным каталогом, так что в нашем случае это будет "sgugger/bert-finetuned-ner".
💡 Если выходной каталог, который вы используете, уже существует, он должен быть локальным клоном репозитория, в который вы хотите передать модель. Если это не так, вы получите ошибку при определении вашего Trainer и должны будете задать новое имя.
Наконец, мы просто передаем все в Trainer и запускаем обучение:
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()Обратите внимание, что во время обучения каждый раз, когда модель сохраняется (здесь - каждую эпоху), она загружается в Hub в фоновом режиме. Таким образом, при необходимости вы сможете возобновить обучение на другой машине.
После завершения обучения мы используем метод push_to_hub(), чтобы убедиться, что загружена самая последняя версия модели:
trainer.push_to_hub(commit_message="Training complete")Эта команда возвращает URL только что выполненного commit, если вы хотите его проверить:
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'Trainer также создает черновик карточки модели со всеми результатами оценки и загружает его. На этом этапе вы можете использовать виджет инференса на Model Hub, чтобы протестировать свою модель и поделиться ею с друзьями. Вы успешно дообучили модель для задачи классификации токенов - поздравляем!
Если вы хотите более глубоко погрузиться в цикл обучения, мы покажем вам, как сделать то же самое с помощью 🤗 Accelerate.
Индивидуальный цикл обучения
Теперь давайте рассмотрим полный цикл обучения, чтобы вы могли легко настроить нужные вам части. Он будет очень похож на тот, что мы делали в Главе 3, с некоторыми изменениями для оценки.
Подготовка всего к обучению
Сначала нам нужно создать DataLoader для наших датасетов. Мы используем наш data_collator в качестве collate_fn и перемешиваем обучающий набор, но не валидационный:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)Затем мы повторно инстанцируем нашу модель, чтобы убедиться, что мы не продолжаем дообучать модель, а снова начинаем с предварительно обученной модели BERT:
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)Тогда нам понадобится оптимизатор. Мы будем использовать классический AdamW, который похож на Adam, но с исправлениями в способе применения затухания весов:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)Когда у нас есть все эти объекты, мы можем отправить их в метод accelerator.prepare():
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 Если вы обучаетесь на TPU, вам нужно будет перенести весь код, начиная с ячейки выше, в специальную функцию обучения. Подробнее смотрите Главу 3.
Теперь, когда мы отправили наш train_dataloader в accelerator.prepare(), мы можем использовать его длину для вычисления количества шагов обучения. Помните, что это всегда нужно делать после подготовки загрузчика данных, так как этот метод изменит его длину. Мы используем классический линейный планировшик скорости обучения до 0:
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Наконец, чтобы передать нашу модель в Hub, нам нужно создать объект Repository в рабочей папке. Сначала авторизуйтесь в Hugging Face, если вы еще не авторизованы. Мы определим имя репозитория по идентификатору модели, который мы хотим присвоить нашей модели (не стесняйтесь заменить repo_name на свой собственный выбор; он просто должен содержать ваше имя пользователя, что и делает функция get_full_repo_name()):
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'sgugger/bert-finetuned-ner-accelerate'Затем мы можем клонировать этот репозиторий в локальную папку. Если она уже существует, эта локальная папка должна быть существующим клоном репозитория, с которым мы работаем:
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)Теперь мы можем загрузить все, что сохранили в output_dir, вызвав метод repo.push_to_hub(). Это поможет нам загружать промежуточные модели в конце каждой эпохи.
Цикл обучения
Теперь мы готовы написать полный цикл обучения. Чтобы упростить его оценочную часть, мы определяем функцию postprocess(), которая принимает прогнозы и метки и преобразует их в списки строк, как того ожидает наш объект metric:
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# Удаляем игнорируемый индекс (специальные токены) и преобразуем в метки
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictionsЗатем мы можем написать цикл обучения. После определения прогресс-бара, чтобы следить за ходом обучения, цикл состоит из трех частей:
- Само обучение представляет собой классическую итерацию по
train_dataloader, прямой проход по модели, затем обратный проход и шаг оптимизатора. - Оценка, в которой есть новшество после получения выходов нашей модели на батче: поскольку два процесса могли дополнять входы и метки до разных форм, нам нужно использовать
accelerator.pad_across_processes(), чтобы сделать прогнозы и метки одинаковой формы перед вызовом методаgather(). Если мы этого не сделаем, оценка либо завершится с ошибкой, либо зависнет навсегда. Затем мы отправляем результаты вmetric.add_batch()и вызываемmetric.compute()после завершения цикла оценки. - Сохранение и загрузка, где мы сначала сохраняем модель и токенизатор, а затем вызываем
repo.push_to_hub(). Обратите внимание, что мы используем аргументblocking=False, чтобы указать библиотеке 🤗 Hub на выполнение push в асинхронном процессе. Таким образом, обучение продолжается нормально, а эта (длинная) инструкция выполняется в фоновом режиме.
Вот полный код цикла обучения:
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Обучение
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Оценка
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# Необходимо добавить предсказания и метки для gather
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# Сохранение и загрузка
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)Если вы впервые видите модель, сохраненную с помощью 🤗 Accelerate, давайте посмотрим на три строки кода, которые идут вместе с ним:
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
Первая строка не требует пояснений: она указывает всем процессам подождать, пока все не окажутся на этой стадии, прежде чем продолжить работу. Это нужно для того, чтобы убедиться, что у нас одна и та же модель в каждом процессе перед сохранением. Затем мы берем unwrapped_model, которая является базовой моделью, которую мы определили. Метод accelerator.prepare() изменяет модель для работы в распределенном обучении, поэтому у нее больше не будет метода save_pretrained(); метод accelerator.unwrap_model() отменяет этот шаг. Наконец, мы вызываем save_pretrained(), но указываем этому методу использовать accelerator.save() вместо torch.save().
После того как это будет сделано, у вас должна получиться модель, выдающая результаты, очень похожие на те, что были обучены с помощью Trainer. Вы можете посмотреть модель, которую мы обучили с помощью этого кода, на huggingface-course/bert-finetuned-ner-accelerate. А если вы хотите протестировать какие-либо изменения в цикле обучения, вы можете напрямую реализовать их, отредактировав код, показанный выше!
Использование дообученной модели
Мы уже показали вам, как можно использовать модель, которую мы дообучили на Model Hub, с помощью виджета инференса. Чтобы использовать ее локально в pipeline, нужно просто указать соответствующий идентификатор модели:
from transformers import pipeline
# Замените это на свою собственную контрольную точку
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]Отлично! Наша модель работает так же хорошо, как и модель по умолчанию для этого конвейера!
< > Update on GitHub