トークン分類

最初に紹介するアプリケーションは、トークン分類です。この汎用的なタスクは「文中の各トークンにラベルを付ける」と定義可能な、以下のような問題を含みます。
- 固有表現認識(NER): 文中に含まれる人名、地名、組織名などの固有のエンティティを検出します。これは、固有エンティティを1クラス、固有エンティティなしを1クラスとして、各トークンにラベルを付与するタスクと定義できます。
- 品詞タグ付け(POS): 文中の各単語を特定の品詞(名詞、動詞、形容詞など)に対応するものとしてマークします。
- チャンキング(chunking): 同じエンティティに属するトークンを見つけます。このタスク(POSやNERと組み合わせることができます)は、チャンクの先頭にあるトークンには一つのラベル(通常
B-)、チャンクの中にあるトークンには別のラベル(通常I-)、どのチャンクにも属さないトークンには三つ目のラベル(通常O)を付けることと定義できます。。
もちろん、トークン分類問題には他にも多くの問題があり、これらは代表的な例に過ぎません。このセクションでは、NERタスクでモデル(BERT)を微調整し、以下のような予測計算ができるようにします。
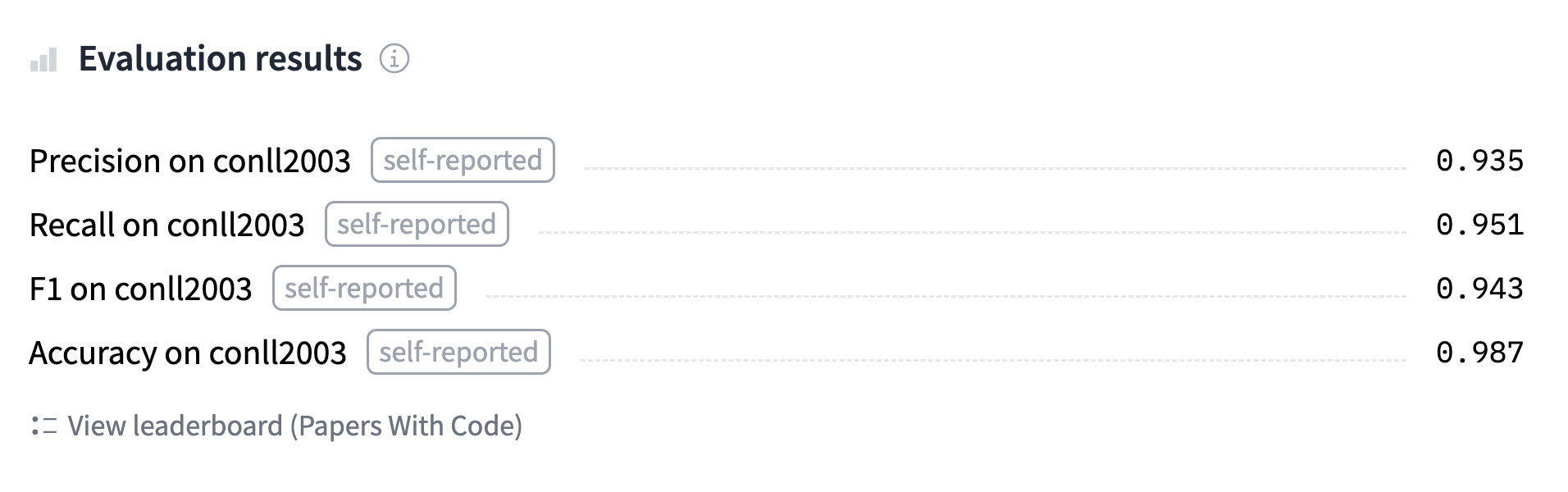
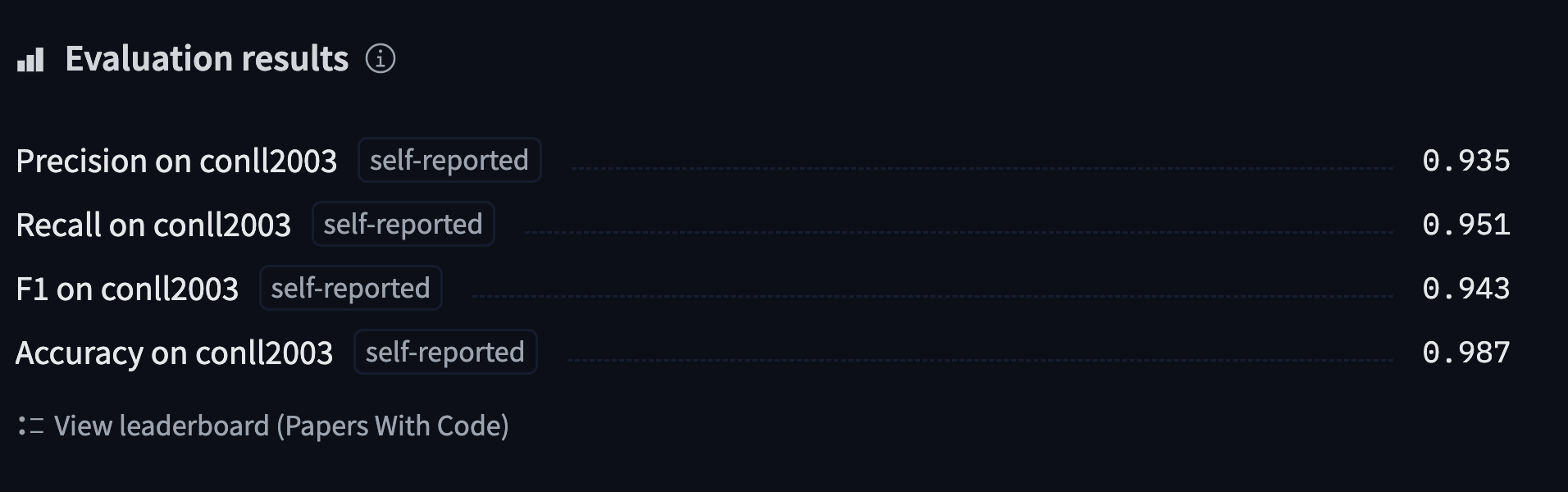
あなたは学習済みモデルをHubで探したり、Hubにアップロードし、その予測値をここで再確認することができます 。
データの準備
まず最初に、トークン分類に適したデータセットが必要です。このセクションでは、CoNLL-2003 datasetを使います。このデータセットはロイターが配信するニュース記事を含みます。
💡 単語とそれに対応するラベルに分割されたテキストからなるデータセットであれば、ここで説明するデータ処理を自分のデータセットに適用することができます。独自のデータを Dataset にロードする方法について復習が必要な場合は、第5章 を参照してください。
The CoNLL-2003 dataset
CoNLL-2003のデータセットをロードするために、🤗 Datasetsライブラリの load_dataset() メソッドを使用します。
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")これはデータセットをダウンロードしキャッシュします。第3章でGLUE MRPC datasetを扱ったときと同じです。このオブジェクトを調べると、定義された列と、トレーニングセット、検証セット、テストセットの3つに分割されている事がわかります。
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})特に、このデータセットには、先に述べた3つのタスク用のラベル、NER、POS、チャンキングが含まれていることがわかります。他のデータセットとの大きな違いは、入力テキストが文や文書としてではなく、単語のリストとして表示されていることです(最後の列はtokens呼ばれていますが、これはトークン化前の入力で、まだサブワード トークン化のためにtokenizer処理する必要があるという意味で単語を含んでいます)。
それでは、学習セットの最初の要素を見てみましょう。
raw_datasets["train"][0]["tokens"]['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']今回は固有表現認識を行いたいので、NERタグを見ることにします。
raw_datasets["train"][0]["ner_tags"][3, 0, 7, 0, 0, 0, 7, 0, 0]これは学習時に使われるラベルのため整数値で格納されています。データを調べるときには必ずしも便利ではありません。テキスト分類のように、データセットの features 属性を見れば、これらの整数値が何のラベルであるか調べる事ができます。
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_featureSequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)つまり、このカラムは ClassLabel の要素を含んでいます。各要素の型は、この ner_feature の feature 属性にあり、その feature の names 属性を見ることで名前のリストを確認する事ができます。
label_names = ner_feature.feature.names label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']これらのラベルは第6章で、token-classificationパイプラインを学んだときに掘り下げましたが、簡単に復習しておきましょう。
Oはその単語がどのエンティティにも対応しないことを意味します。B-PER/I-PERは、その単語が 人(person) エンティティの先頭、または内部であることを意味します。B-ORG/I-ORGは、その単語が 組織(organization) エンティティの先頭、または内部であることを意味します。B-LOC/I-LOCは、その単語が 場所(location) エンティティの先頭、または内部であることを意味します。B-MISC/I-MISCは、その単語が その他(miscellaneous) エンティティの先頭、または内部であることを意味します。
さて、先ほどのラベルをデコードすると、以下のようになります。
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'また、B- と I-のラベルを混在させた例として、学習セットの4番目の要素について同じコードを実行すると、以下のようになります。
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'このように、“European Union” と “Werner Zwingmann” のように2つの単語にまたがるエンティティは、最初の単語には B- ラベルが、2番目の単語には I- ラベルが付与されます。
✏️ あなたの番です! 同じ2つの文をPOSラベルまたはチャンキングラベルと一緒に出力してください。
データの処理
いつものように、モデルが意味を理解できるようにするために、テキストはトークンIDに変換される必要があります。第6章で見たように、トークン分類タスクの場合の大きな違いは、入力があらかじめトークン化されていると言う事です。幸いなことに、tokenizer API はこの点をかなり簡単に処理できます。特別なフラグを指定して tokenizer に警告するだけです。
まず最初に、tokenizer オブジェクトを作成しましょう。前に述べたように、事前学習済みBERTモデルを使用する予定なので、関連するtokenizerをダウンロードしてキャッシュすることから始めます。
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)あなたはmodel_checkpoint を自由に置き換える事ができます。Hub にある好きなモデルや、自分の端末に保存した事前学習済みモデルやtokenizerをで置き換えることができます。
唯一の制約は、tokenizerが 🤗 Tokenizers ライブラリによってバックアップされる必要があることです。これにより「高速」バージョンが用意されます。この大きなテーブル で高速バージョンを持つ全てのアーキテクチャを見ることができます。使用している tokenizer オブジェクトが本当に 🤗 Tokenizers でバックアップされているかどうかを確認するには、is_fast 属性を見る事が確認できます。
tokenizer.is_fast
Trueトークン化前の入力をトークン化するには、普段通り tokenizer を使用して、 is_split_into_words=True を追加するだけです。
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']見ての通り、トークン化はモデルが使用する特殊なトークン(先頭の [CLS] と末尾の [SEP] )を追加し、ほとんどの単語はそのままにしました。しかし、lambという単語はlaと##mbという2つのサブワードにトークン化されました。このため、入力とラベルの間にミスマッチが生じます。ラベルのリストには9つの要素しかありませんが、入力のリストには12のトークンがあります。特殊なトークンを考慮するのは簡単ですが(最初と最後にあることが分かっています)、すべてのラベルを適切な単語に揃えることも必要です。
幸い、高速なtokenizerを使っているので、🤗 Tokenizers のスーパーパワーにアクセスすることができ、それぞれのトークンを対応する単語に簡単にマッピングすることができます (これは 第6章 で見たとおりです)。
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]ほんの少しの作業で、トークンにマッチするようにラベルリストを拡張することができます。最初に適用するルールは、特殊なトークンには -100 というラベルを付けるというものです。これはデフォルトで -100 がこれから使う損失関数(クロスエントロピー)で無視される数だからです。次に、単語内の各トークンは単語の先頭のトークンと同じラベルが付与されます。これは同じエンティティの一部であるためです。単語の内部にあり、かつ先頭にないトークンについては、B- を I- に置き換えます(そのトークンはエンティティを開始しないためです)。
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Start of a new word!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Special token
new_labels.append(-100)
else:
# Same word as previous token
label = labels[word_id]
# If the label is B-XXX we change it to I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labelsそれでは、最初の文章で試してみましょう。
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]見てわかるように、この関数は最初と最後の2つの特別なトークンに対して -100 を追加し、2つのトークンに分割された単語に対して新たに 0 を追加しています。
✏️ あなたの番です! 研究者の中には、1つの単語には1つのラベルしか付けず、与えられた単語内の他のサブトークンに-100を割り当てることを好む人もいます。これは、多くのサブトークンに分割される長い単語が学習時の損失に大きく寄与するのを避けるためです。このルールに従って、ラベルと入力IDを一致させるように、前の関数を変更してみましょう。
データセット全体の前処理として、すべての入力をトークン化し、すべてのラベルに対して align_labels_with_tokens() を適用する必要があります。高速なtokenizerの速度を活かすには、たくさんのテキストを同時にトークン化するのがよいでしょう。そこで、サンプルのリストを処理する関数を書いて、 Dataset.map() メソッドに batched=True オプションを付けて使用することにしましょう。以前の例と唯一違うのは、tokenizerへの入力がテキストのリスト(この場合は単語のリストのリスト)である場合、 word_ids() 関数は単語IDが欲しいリストのインデックスを必要とするので、これも追加します。
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputsまだ、入力をパディングしていないことに注意してください。 これは後でデータ照合ツールでバッチを作成するときにやることにします。
これで、データセットの分割に対して、すべての前処理を一度に適用することができるようになりました。
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)一番大変なところをやりましたね! データの前処理が終わったので、実際の学習は第3章でやったような感じになりますね。
Trainer API でモデルを微調整する
実際に Trainer を使用するコードは、これまでと同じです。変更点は、データをバッチ化する方法と、指標を計算する関数だけです。
データ照合
第3章 にあるような DataCollatorWithPadding は入力 (入力 ID、アテンションマスク、トークンタイプ ID) のみをパディングするので使えません。ここでは、ラベルのサイズが変わらないように、入力と全く同じ方法でパディングを行います。値として -100 を使用し、対応する予測値が損失計算で無視されるようにします。
これは全て DataCollatorForTokenClassification によって行われます。DataCollatorWithPaddingと同様に、入力の前処理に使用されるtokenizer` を受け取ります。
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)これをいくつかのサンプルでテストするには、トークン化されたトレーニングセットからサンプルのリストに対して呼び出すだけでよいのです。
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])これをデータセットの1番目と2番目の要素のラベルと比較してみましょう。
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]見ての通り、2つ目のラベルのセットは最初のラベルの長さに -100s を使ってパディングされています.
指標
Trainer にエポック毎に指標を計算させるためには、compute_metrics() 関数を定義する必要があります。これは予測とラベルの配列を受け取り、指標の名前と値を含む辞書を返す関数です。
トークン分類予測の評価に使われる伝統的な枠組みはseqevalです。この指標を使うには、まず seqeval ライブラリをインストールする必要があります。
!pip install seqeval
そして、第3章 で行ったように evaluate.load() 関数で読み込むことができるようになります。
import evaluate
metric = evaluate.load("seqeval")この指標は標準的な精度指標のように動作しません:実際にはラベルのリストを整数ではなく文字列として受け取るので、予測値とラベルを指標に渡す前に完全にデコードする必要があります。
それでは、どのように動作するか見てみましょう。まず、最初の学習サンプルに対するラベルを取得します。
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']そして、インデックス2の値を変更するだけで、それらの疑似予測を作成することができます。
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])この指標は予測値のリスト(1つだけではない)とラベルのリストを受け取ることに注意してください。以下はその出力です。
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}とても多くの情報を取得しています! 各エンティティの精度、再現率、F1スコア、そして総合的なスコアです。
私達の指標計算では、総合的なスコアのみを保持することにします。
しかし、お望みならcompute_metrics()関数を微調整して、報告させたいすべての指標を返すこともできます。
この compute_metrics() 関数は、まず 最終レイヤーが出力するベクトルの最大値を予測値に変換します(最終レイヤーが出力する生の値は通常は確率に変換されますが、最大値は確率に変換しなくとも同じなので、softmax で確率に変換させる必要はありません)。次に、ラベルと予測値の両方を整数から文字列に変換する必要があります。ラベルが -100 である値をすべて削除し、その結果を metric.compute() メソッドに渡します。
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}これで、Trainer を定義する準備はほぼ整いました。あとは微調整をするための model が必要です。
モデルを定義
今回はトークン分類の問題を扱うので、 AutoModelForTokenClassification クラスを使用します。このモデルを定義する際に覚えておくべきことは、ラベルの数に関する情報を渡すことです。最も簡単な方法は num_labels 引数でその数を渡すことですが、このセクションの最初に見たような素敵な推論ウィジェットを動作させたい場合は、代わりに正しいラベルの対応関係を設定した方が良いでしょう。
id2labelとlabel2id` という 2 つの辞書型データがあり、ID からラベル、ラベルから ID へのマッピングを設定することができます。
id2label = {i: label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}あとはそれらを AutoModelForTokenClassification.from_pretrained() メソッドに渡せば、モデルの構成に設定され、適切に保存されて Hub にアップロードされます。
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)第3章 で AutoModelForSequenceClassification を定義したときのように、モデルを作成すると、いくつかの重みが使われていない(事前学習済みモデルのヘッド部の重み)、他のいくつかの重みがランダムに初期化されている(新しく接続したトークン分類ヘッドの重み)、このモデルはトレーニングする必要があるという警告が表示されます。トレーニングはすぐにでも実行できますが、まずはこのモデルが正しい数のラベルを持つことを再確認しましょう。
model.config.num_labels
9⚠️ ラベルの数が間違っているモデルがあると、後で model.fit() を呼び出すときによくわからないエラー(“CUDA error: device-side assert triggered”のようなエラー)が発生します。このようなエラーはユーザーから報告されるバグの原因として一番多いものです。このチェックを必ず行い、期待通りのラベル数であることを確認してください。
モデルの微調整
これでモデルを学習する準備が整いました!
しかし、Trainerを定義する前に、最後に2つのことをする必要があります。
Hugging Faceにログインし、学習用ハイパーパラメータを定義する必要があります。もしNotebookで作業しているなら、これを助ける便利な関数があります。
from huggingface_hub import notebook_login
notebook_login()これにより、Hugging Faceのログイン情報を入力するウィジェットが表示されます。
Notebookで作業していない場合は、ターミナルに次の行を入力するだけです。
huggingface-cli login
完了したら、TrainingArgumentsを定義する事ができるようになります。
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)これらのパラメータのほとんどは以前に見たことがあると思います。
ハイパーパラメータ(学習率、学習エポック数、ウェイト減衰など)を設定し、push_to_hub=True を指定して、モデルを保存して各エポック終了時に評価し、その結果をモデルハブにアップロードすることを指示します。
なお、 hub_model_id 引数でプッシュ先のリポジトリ名を指定できます (特に、特定の組織(organization)にプッシュする場合は、この引数を使用する必要があります)。例えば、huggingface-course organization にモデルをプッシュする場合、TrainingArguments に hub_model_id="huggingface-course/bert-finetuned-ner" を追加しました。
デフォルトでは、使用されるリポジトリはあなたの名前が使われ、設定した出力ディレクトリちなんだ名前、例えば今回の例では "sgugger/bert-finetuned-ner" となります。
最後に、すべてを Trainer に渡して、トレーニングを開始するだけです。
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()学習が行われている間、モデルが保存されるたびに(ここではエポックごとに)バックグラウンドでHubにアップロードされることに注意してください。このようにして、必要に応じて別のマシンで学習を再開することができます。
学習が完了したら、push_to_hub() メソッドを使用して、最新バージョンのモデルをアップロードするようにします。
trainer.push_to_hub(commit_message="Training complete")このコマンドは、今行ったコミットの URL を返すので、それを検査したい場合は、このコマンドを使用します。
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'また、Trainerはすべての評価結果を含むモデルカードを起草し、アップロードします。この段階で、Model Hub上の推論ウィジェットを使ってモデルをテストし、友人と共有することができます。これで、トークン分類タスクのモデル微調整に成功しました。
おめでとうございます!
もう少し深く学習ループについて学びたい場合は、🤗 Accelerate を使って同じことをする方法を紹介します。
カスタムトレーニングループ
それでは、必要な部分を簡単にカスタマイズできるように、トレーニングループの全体像を見てみましょう。これは、第3章 で行ったこととよく似ていますが、評価のために少し変更が加えられています。
トレーニングのための準備
まず、データセットから DataLoader を作成する必要があります。ここでは、data_collator を collate_fn として再利用し、トレーニングセットをシャッフルします。ただし、検証セットはシャッフルしません。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)次に、モデルの再定義を行います。これは、以前の微調整を継続するのではなく、BERTで事前学習したモデルから再び開始することを確認するためです。
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)それから、オプティマイザが必要になります。ここでは、古典的な AdamW を使用します。これは Adam のようなものですが、重みの減衰の適用方法を修正したものです。
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)これらのオブジェクトをすべて取得したら、それらを accelerator.prepare() メソッドに送ります。
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 TPUでトレーニングする場合は、上のセルから始まるコードを全て専用のトレーニング関数に移動する必要があります。詳しくは第3章を参照してください。
これで train_dataloader を accelerator.prepare() に送ったので、そのデータ長を用いて学習ステップ数を計算することができます。このメソッドはdataloaderの長さを変更するので、常にdataloaderを準備した後に行う必要があることを忘れないでください。ここでは、学習率から0まで古典的な線形スケジュールを使用します。
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)最後に、モデルをHubにプッシュするために、作業フォルダに Repository オブジェクトを作業フォルダに作成する必要があります。まず、まだログインしていなければHugging Faceにログインしてください。モデルに付与したいモデルIDからリポジトリ名を決定します。(repo_nameは自由に置き換えてください;ユーザー名を含む必要があるだけで、これは関数 get_full_repo_name() が行っている事です)。
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'sgugger/bert-finetuned-ner-accelerate'そして、そのリポジトリをローカルフォルダーにクローンすることができます。すでに存在するのであれば、このローカルフォルダーは作業中のリポジトリの既存のクローンであるべきです。
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)これで repo.push_to_hub() メソッドを呼び出すことで、output_dir に保存したものをアップロードできるようになりました。これにより、各エポック終了時に中間モデルをアップロードすることができます。
学習ループ
これで学習ループを書く準備ができました。
評価部分を簡略化するため、postprocess() 関数を簡単に定義します。
この関数は予測値とラベルを受け取って metric オブジェクトが期待するような文字列のリストに変換します。
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# Remove ignored index (special tokens) and convert to labels
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictions次に、トレーニングループを書きます。トレーニングの進捗を確認するためのプログレスバーを定義した後、ループは3つのパートに分かれます。
学習そのもの。
train_dataloaderに対する古典的な繰り返しで、モデルを前方に伝播させ、後方に逆伝播させ、最適化のステップを行います。評価。モデルの出力をバッチで取得した後に、新しい事をします。2つのプロセスで入力とラベルを異なる形状にパディングしているかもしれないので、
gather()メソッドを呼ぶ前にaccelerator.pad_across_processes()を使って予測値とラベルを同じ形状にする必要があるのです。これを行わないと、評価がエラーになるか、永遠にハングアップします。そして、結果をmetric.add_batch()に送り、評価ループが終了したらmetric.compute()を呼び出します。保存とアップロード。まずモデルとtokenizerを保存し、次に
repo.push_to_hub()を呼び出します。引数blocking=Falseを使って、🤗 Hub libraryに非同期処理でプッシュするように指示していることに注意してください。この指定をすると、トレーニングは通常通り行われ、この(長い時間のかかる)命令はバックグラウンドで実行されます。
以下は、トレーニングループの完全なコードです。
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# Necessary to pad predictions and labels for being gathered
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)今回初めて🤗 Accelerateで保存されたモデルをご覧になる方のために、それに付随する3行のコードを少し点検してみましょう。
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
最初の行は明らかです。この行は、すべてのプロセスに、全プロセスがその行に達するまで、処理を待つよう指示します。これは、保存する前に、すべてのプロセスが同じモデルになっている事を確認するためです。次に unwrapped_model を取得します。これは定義したベースモデルです。accelerator.prepare() メソッドは分散して学習するようにモデルを変更するので、save_pretrained() メソッドを持たなくなります。accelerator.unwrap_model() メソッドはそのステップを元に戻します。最後に、save_pretrained() を呼び出しますが、このメソッドには torch.save() の代わりに accelerator.save() を使用するように指示します。
これが完了すると、Trainer で学習したものとほぼ同じ結果を得ることができるモデルができあがります。このコードを使って学習したモデルは huggingface-course/bert-finetuned-ner-accelerate で確認することができます。また、学習ループの微調整を試したい場合は、上に示したコードを編集することで直接実装することができます!
微調整したモデルを使う
Model Hubで微調整したモデルを推論ウィジェットで使用する方法は既に紹介しました。ローカル環境のpipelineで使用する場合は、モデル識別子を指定します。
from transformers import pipeline
# Replace this with your own checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]素晴らしい! 私たちのモデルは、このパイプラインのデフォルトのものと同じように動作しています!