Classification de <i> tokens </i>
La première application que nous allons explorer est la classification de tokens. Cette tâche générique englobe tous les problèmes qui peuvent être formulés comme l’attribution d’une étiquette à chaque token d’une phrase, tels que :
- la reconnaissance d’entités nommées (NER de l’anglais Named Entity Recognition), c’est-à-dire trouver les entités (telles que des personnes, des lieux ou des organisations) dans une phrase. Ce tâche peut être formulée comme l’attribution d’une étiquette à chaque token faisant parti d’une entité en ayant une classe spécifique par entité, et une classe pour les tokens ne faisant pas parti d’entité.
- le part-of-speech tagging (POS), c’est-à-dire marquer chaque mot dans une phrase comme correspondant à une partie particulière (comme un nom, un verbe, un adjectif, etc.).
- le chunking, c’est-à-dire trouver les tokens qui appartiennent à la même entité. Cette tâche (qui peut être combinée avec le POS ou la NER) peut être formulée comme l’attribution d’une étiquette (habituellement
B-) à tous les tokens qui sont au début d’un morceau, une autre étiquette (habituellementI-) aux tokens qui sont à l’intérieur d’un morceau, et une troisième étiquette (habituellementO) aux tokens qui n’appartiennent à aucun morceau.
Bien sûr, il existe de nombreux autres types de problèmes de classification de tokens. Ce ne sont là que quelques exemples représentatifs. Dans cette section, nous allons finetuner un modèle (BERT) sur la tâche de NER. Il sera alors capable de calculer des prédictions comme celle-ci :
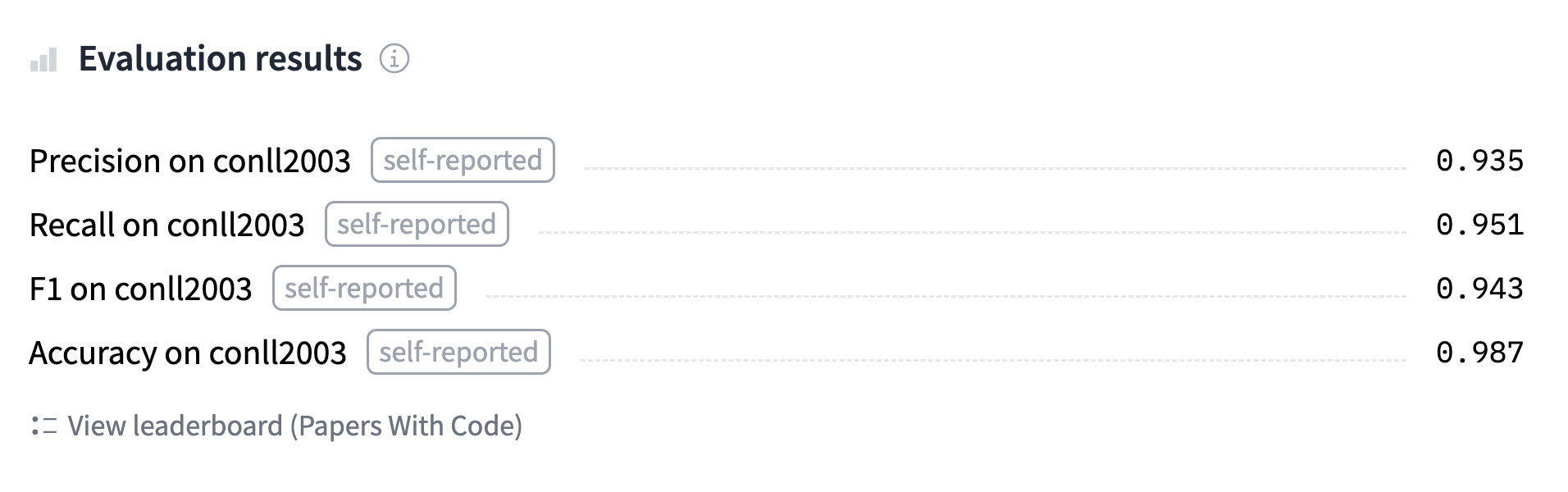
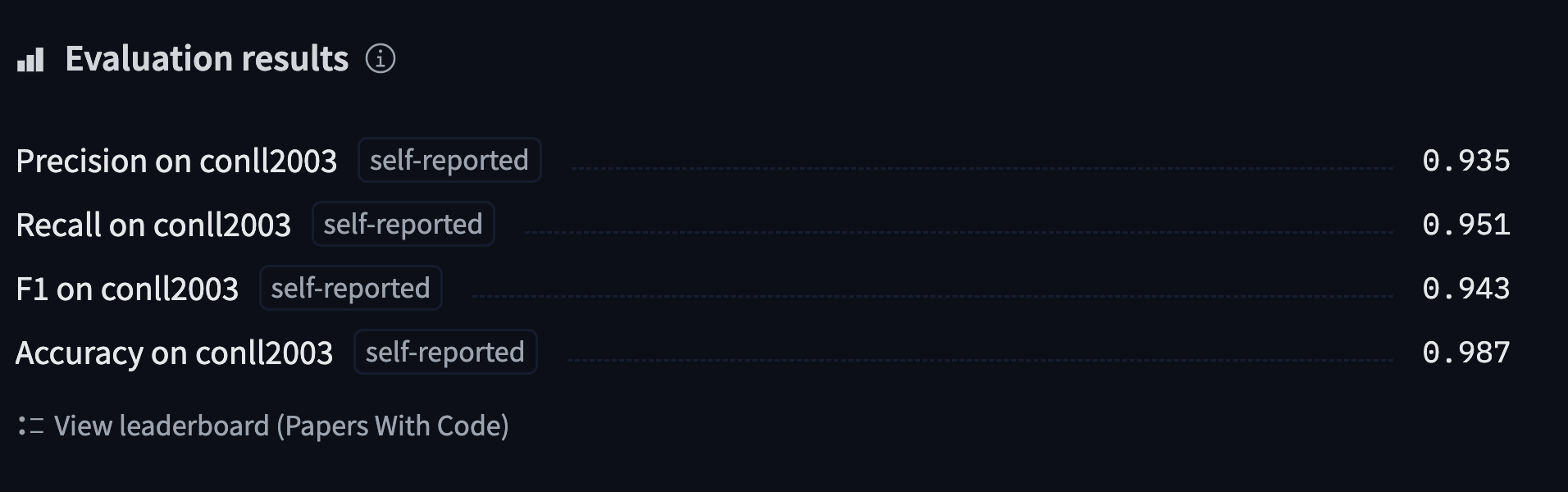
Vous pouvez trouver, télécharger et vérifier les précisions de ce modèle sur le Hub les prédictions du modèle que nous allons entraîner.
Préparation des données
Tout d’abord, nous avons besoin d’un jeu de données adapté à la classification des tokens. Dans cette section, nous utiliserons le jeu de données CoNLL-2003, qui contient des articles de presse de Reuters.
💡 Tant que votre jeu de données consiste en des textes divisés en mots avec leurs étiquettes correspondantes, vous pourrez adapter les procédures de traitement des données décrites ici à votre propre jeu de données. Reportez-vous au chapitre 5 si vous avez besoin d’un rafraîchissement sur la façon de charger vos propres données personnalisées dans un Dataset.
Le jeu de données CoNLL-2003
Pour charger le jeu de données CoNLL-2003, nous utilisons la méthode load_dataset() de la bibliothèque 🤗 Datasets :
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")Cela va télécharger et mettre en cache le jeu de données, comme nous l’avons vu dans chapitre 3 pour le jeu de données GLUE MRPC. L’inspection de cet objet nous montre les colonnes présentes dans ce jeu de données et la répartition entre les ensembles d’entraînement, de validation et de test :
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})En particulier, nous pouvons voir que le jeu de données contient des étiquettes pour les trois tâches que nous avons mentionnées précédemment : NER, POS et chunking. Une grande différence avec les autres jeux de données est que les entrées textuelles ne sont pas présentés comme des phrases ou des documents, mais comme des listes de mots (la dernière colonne est appelée tokens, mais elle contient des mots dans le sens où ce sont des entrées prétokénisées qui doivent encore passer par le tokenizer pour la tokenisation en sous-mots).
Regardons le premier élément de l’ensemble d’entraînement :
raw_datasets["train"][0]["tokens"]['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']Puisque nous voulons effectuer reconnaître des entités nommées, nous allons examiner les balises NER :
raw_datasets["train"][0]["ner_tags"][3, 0, 7, 0, 0, 0, 7, 0, 0]Ce sont les étiquettes sous forme d’entiers disponibles pour l’entraînement mais ne sont pas nécessairement utiles lorsque nous voulons inspecter les données. Comme pour la classification de texte, nous pouvons accéder à la correspondance entre ces entiers et les noms des étiquettes en regardant l’attribut features de notre jeu de données :
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_featureSequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)Cette colonne contient donc des éléments qui sont des séquences de ClassLabel. Le type des éléments de la séquence se trouve dans l’attribut feature de cette ner_feature, et nous pouvons accéder à la liste des noms en regardant l’attribut names de cette feature :
label_names = ner_feature.feature.names label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']Nous avons déjà vu ces étiquettes au chapitre 6 lorsque nous nous sommes intéressés au pipeline token-classification mais nosu pouvons tout de même faire un rapide rappel :
Osignifie que le mot ne correspond à aucune entité.B-PER/I-PERsignifie que le mot correspond au début/est à l’intérieur d’une entité personne.B-ORG/I-ORGsignifie que le mot correspond au début/est à l’intérieur d’une entité organisation.B-LOC/I-LOCsignifie que le mot correspond au début/est à l’intérieur d’une entité location.B-MISC/I-MISCsignifie que le mot correspond au début/est à l’intérieur d’une entité divers.
Maintenant, le décodage des étiquettes que nous avons vues précédemment nous donne ceci :
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'Et pour un exemple mélangeant les étiquettes B- et I-, voici ce que le même code nous donne sur le quatrième élément du jeu d’entraînement :
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'Comme on peut le voir, les entités couvrant deux mots, comme « European Union » et « Werner Zwingmann », se voient attribuer une étiquette B- pour le premier mot et une étiquette I- pour le second.
✏️ A votre tour ! Affichez les deux mêmes phrases avec leurs étiquettes POS ou chunking.
Traitement des données
Comme d’habitude, nos textes doivent être convertis en identifiants de tokens avant que le modèle puisse leur donner un sens. Comme nous l’avons vu au chapitre 6, une grande différence dans le cas des tâches de classification de tokens est que nous avons des entrées prétokénisées. Heureusement, l’API tokenizer peut gérer cela assez facilement. Nous devons juste avertir le tokenizer avec un drapeau spécial.
Pour commencer, nous allons créer notre objet tokenizer. Comme nous l’avons dit précédemment, nous allons utiliser un modèle BERT pré-entraîné, donc nous allons commencer par télécharger et mettre en cache le tokenizer associé :
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Vous pouvez remplacer le model_checkpoint par tout autre modèle que vous préférez à partir du Hub, ou par un dossier local dans lequel vous avez sauvegardé un modèle pré-entraîné et un tokenizer. La seule contrainte est que le tokenizer doit être soutenu par la bibliothèque 🤗 Tokenizers. Il y a donc une version rapide disponible. Vous pouvez voir toutes les architectures qui ont une version rapide dans ce tableau, et pour vérifier que l’objet tokenizer que vous utilisez est bien soutenu par 🤗 Tokenizers vous pouvez regarder son attribut is_fast :
tokenizer.is_fast
TruePour tokeniser une entrée prétokenisée, nous pouvons utiliser notre tokenizer comme d’habitude et juste ajouter is_split_into_words=True :
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']Comme on peut le voir, le tokenizer a ajouté les tokens spéciaux utilisés par le modèle ([CLS] au début et [SEP] à la fin) et n’a pas touché à la plupart des mots. Le mot lamb, cependant, a été tokenisé en deux sous-mots, la et ##mb. Cela introduit un décalage entre nos entrées et les étiquettes : la liste des étiquettes n’a que 9 éléments, alors que notre entrée a maintenant 12 tokens. Il est facile de tenir compte des tokens spéciaux (nous savons qu’ils sont au début et à la fin), mais nous devons également nous assurer que nous alignons toutes les étiquettes avec les mots appropriés.
Heureusement, comme nous utilisons un tokenizer rapide, nous avons accès aux superpouvoirs des 🤗 Tokenizers, ce qui signifie que nous pouvons facilement faire correspondre chaque token au mot correspondant (comme on le voit au chapitre 6) :
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]Avec un peu de travail, nous pouvons étendre notre liste d’étiquettes pour qu’elle corresponde aux tokens. La première règle que nous allons appliquer est que les tokens spéciaux reçoivent une étiquette de -100. En effet, par défaut, -100 est un indice qui est ignoré dans la fonction de perte que nous allons utiliser (l’entropie croisée). Ensuite, chaque token reçoit la même étiquette que le token qui a commencé le mot dans lequel il se trouve puisqu’ils font partie de la même entité. Pour les tokens à l’intérieur d’un mot mais pas au début, nous remplaçons le B- par I- (puisque le token ne commence pas l’entité) :
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Début d'un nouveau mot !
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Token spécial
new_labels.append(-100)
else:
# Même mot que le token précédent
label = labels[word_id]
# Si l'étiquette est B-XXX, nous la changeons en I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labelsEssayons-le sur notre première phrase :
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]Comme nous pouvons le voir, notre fonction a ajouté -100 pour les deux tokens spéciaux du début et de fin, et un nouveau 0 pour notre mot qui a été divisé en deux tokens.
✏️ A votre tour ! Certains chercheurs préfèrent n’attribuer qu’une seule étiquette par mot et attribuer -100 aux autres sous-tokens dans un mot donné. Ceci afin d’éviter que les longs mots qui se divisent en plusieurs batchs ne contribuent fortement à la perte. Changez la fonction précédente pour aligner les étiquettes avec les identifiants d’entrée en suivant cette règle.
Pour prétraiter notre jeu de données, nous devons tokeniser toutes les entrées et appliquer align_labels_with_tokens() sur toutes les étiquettes. Pour profiter de la vitesse de notre tokenizer rapide, il est préférable de tokeniser beaucoup de textes en même temps. Nous allons donc écrire une fonction qui traite une liste d’exemples et utiliser la méthode Dataset.map() avec l’option batched=True. La seule chose qui diffère de notre exemple précédent est que la fonction word_ids() a besoin de récupérer l’index de l’exemple dont nous voulons les identifiants de mots lorsque les entrées du tokenizer sont des listes de textes (ou dans notre cas, des listes de mots), donc nous l’ajoutons aussi :
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputsNotez que nous n’avons pas encore rembourré nos entrées. Nous le ferons plus tard lors de la création des batchs avec un assembleur de données.
Nous pouvons maintenant appliquer tout ce prétraitement en une seule fois sur les autres divisions de notre jeu de données :
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)Nous avons fait la partie la plus difficile ! Maintenant que les données ont été prétraitées, l’entraînement ressemblera beaucoup à ce que nous avons fait dans le chapitre 3.
<i> Finetuning </i> du modèle avec l’API Trainer
Le code utilisant Trainer sera le même que précédemment. Les seuls changements sont la façon dont les données sont rassemblées dans un batch ainsi que la fonction de calcul de la métrique.
Assemblage des données
Nous ne pouvons pas simplement utiliser un DataCollatorWithPadding comme dans le chapitre 3 car cela ne fait que rembourrer les entrées (identifiants d’entrée, masque d’attention et token de type identifiants). Ici, nos étiquettes doivent être rembourréés exactement de la même manière que les entrées afin qu’elles gardent la même taille, en utilisant -100 comme valeur afin que les prédictions correspondantes soient ignorées dans le calcul de la perte.
Tout ceci est fait par un DataCollatorForTokenClassification. Comme le DataCollatorWithPadding, il prend le tokenizer utilisé pour prétraiter les entrées :
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)Pour tester cette fonction sur quelques échantillons, nous pouvons simplement l’appeler sur une liste d’exemples provenant de notre jeu d’entraînement tokénisé :
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])Comparons cela aux étiquettes des premier et deuxième éléments de notre jeu de données :
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]Comme nous pouvons le voir, le deuxième jeu d’étiquettes a été complété à la longueur du premier en utilisant des -100.
Métriques
Pour que le Trainer calcule une métrique à chaque époque, nous devrons définir une fonction compute_metrics() qui prend les tableaux de prédictions et d’étiquettes, et retourne un dictionnaire avec les noms et les valeurs des métriques.
Le framework traditionnel utilisé pour évaluer la prédiction de la classification des tokens est seqeval. Pour utiliser cette métrique, nous devons d’abord installer la bibliothèque seqeval :
!pip install seqeval
Nous pouvons ensuite le charger via la fonction evaluate.load() comme nous l’avons fait dans le chapitre 3 :
import evaluate
metric = evaluate.load("seqeval")Cette métrique ne se comporte pas comme la précision standard : elle prend les listes d’étiquettes comme des chaînes de caractères et non comme des entiers. Nous devrons donc décoder complètement les prédictions et les étiquettes avant de les transmettre à la métrique. Voyons comment cela fonctionne. Tout d’abord, nous allons obtenir les étiquettes pour notre premier exemple d’entraînement :
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']Nous pouvons alors créer de fausses prédictions pour celles-ci en changeant simplement la valeur de l’indice 2 :
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])Notez que la métrique prend une liste de prédictions (pas seulement une) et une liste d’étiquettes. Voici la sortie :
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}Cela renvoie un batch d’informations ! Nous obtenons la précision, le rappel et le score F1 pour chaque entité séparée, ainsi que le score global. Pour notre calcul de métrique, nous ne garderons que le score global, mais n’hésitez pas à modifier la fonction compute_metrics() pour retourner toutes les métriques que vous souhaitez.
Cette fonction compute_metrics() prend d’abord l’argmax des logits pour les convertir en prédictions (comme d’habitude, les logits et les probabilités sont dans le même ordre, donc nous n’avons pas besoin d’appliquer la fonction softmax). Ensuite, nous devons convertir les étiquettes et les prédictions des entiers en chaînes de caractères. Nous supprimons toutes les valeurs dont l’étiquette est -100, puis nous passons les résultats à la méthode metric.compute() :
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}Maintenant que ceci est fait, nous sommes presque prêts à définir notre Trainer. Nous avons juste besoin d’un objet model pour finetuner !
Définir le modèle
Puisque nous travaillons sur un problème de classification de tokens, nous allons utiliser la classe AutoModelForTokenClassification. La principale chose à retenir lors de la définition de ce modèle est de transmettre des informations sur le nombre d’étiquettes que nous avons. La façon la plus simple de le faire est de passer ce nombre avec l’argument num_labels, mais si nous voulons un joli widget d’inférence fonctionnant comme celui que nous avons vu au début de cette section, il est préférable de définir les correspondances des étiquettes à la place.
Elles devraient être définies par deux dictionnaires, id2label et label2id, qui contiennent les correspondances entre identifiants et étiquettes et vice versa :
id2label = {i: label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}Maintenant nous pouvons simplement les passer à la méthode AutoModelForTokenClassification.from_pretrained(), ils seront définis dans la configuration du modèle puis correctement sauvegardés et téléchargés vers le Hub :
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)Comme lorsque nous avons défini notre AutoModelForSequenceClassification au chapitre 3, la création du modèle émet un avertissement indiquant que certains poids n’ont pas été utilisés (ceux de la tête de pré-entraînement) et que d’autres poids ont été initialisés de manière aléatoire (ceux de la tête de classification des nouveaux tokens), et que ce modèle doit être entraîné. Nous ferons cela dans une minute, mais vérifions d’abord que notre modèle a le bon nombre d’étiquettes :
model.config.num_labels
9⚠️ Si vous avez un modèle avec le mauvais nombre d’étiquettes, vous obtiendrez une erreur obscure lors de l’appel de la méthode Trainer.train() (quelque chose comme “CUDA error : device-side assert triggered”). C’est la première cause de bogues signalés par les utilisateurs pour de telles erreurs, donc assurez-vous de faire cette vérification pour confirmer que vous avez le nombre d’étiquettes attendu.
<i> Finetuning </i> du modèle
Nous sommes maintenant prêts à entraîner notre modèle ! Nous devons juste faire deux dernières choses avant de définir notre Trainer : se connecter à Hugging Face et définir nos arguments d’entraînement. Si vous travaillez dans un notebook, il y a une fonction pratique pour vous aider à le faire :
from huggingface_hub import notebook_login
notebook_login()Cela affichera un widget où vous pourrez entrer vos identifiants de connexion à Hugging Face.
Si vous ne travaillez pas dans un notebook, tapez simplement la ligne suivante dans votre terminal :
huggingface-cli login
Une fois ceci fait, nous pouvons définir nos TrainingArguments :
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)Vous avez déjà vu la plupart d’entre eux. Nous définissons quelques hyperparamètres (comme le taux d’apprentissage, le nombre d’époques à entraîner, et le taux de décroissance des poids), et nous spécifions push_to_hub=True pour indiquer que nous voulons sauvegarder le modèle, l’évaluer à la fin de chaque époque, et que nous voulons télécharger nos résultats vers le Hub. Notez que vous pouvez spécifier le nom du dépôt vers lequel vous voulez pousser avec l’argument hub_model_id (en particulier, vous devrez utiliser cet argument pour pousser vers une organisation). Par exemple, lorsque nous avons poussé le modèle vers l’organisation huggingface-course, nous avons ajouté hub_model_id="huggingface-course/bert-finetuned-ner"``TrainingArguments. Par défaut, le dépôt utilisé sera dans votre espace de noms et nommé d’après le répertoire de sortie que vous avez défini, donc dans notre cas ce sera "sgugger/bert-finetuned-ner".
💡 Si le répertoire de sortie que vous utilisez existe déjà, il doit être un clone local du dépôt vers lequel vous voulez pousser. S’il ne l’est pas, vous obtiendrez une erreur lors de la définition de votre Trainer et devrez définir un nouveau nom.
Enfin, nous passons tout au Trainer et lançons l’entraînement :
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()Notez que pendant l’entraînement, chaque fois que le modèle est sauvegardé (ici, à chaque époque), il est téléchargé sur le Hub en arrière-plan. De cette façon, vous serez en mesure de reprendre votre entraînement sur une autre machine si nécessaire.
Une fois l’entraînement terminé, nous utilisons la méthode push_to_hub() pour nous assurer que nous téléchargeons la version la plus récente du modèle :
trainer.push_to_hub(commit_message="Training complete")Cette commande renvoie l’URL du commit qu’elle vient de faire, si vous voulez l’inspecter :
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'Le Trainer rédige également une carte modèle avec tous les résultats de l’évaluation et la télécharge. A ce stade, vous pouvez utiliser le widget d’inférence sur le Hub pour tester votre modèle et le partager avec vos amis. Vous avez réussi à affiner un modèle sur une tâche de classification de tokens. Félicitations !
Si vous voulez plonger un peu plus profondément dans la boucle d’entraînement, nous allons maintenant vous montrer comment faire la même chose en utilisant 🤗 Accelerate.
Une boucle d’entraînement personnalisée
Jetons maintenant un coup d’œil à la boucle d’entraînement complète afin que vous puissiez facilement personnaliser les parties dont vous avez besoin. Elle ressemblera beaucoup à ce que nous avons fait dans le chapitre 3 avec quelques changements pour l’évaluation.
Préparer tout pour l’entraînement
D’abord nous devons construire le DataLoaders à partir de nos jeux de données. Nous réutilisons notre data_collator comme un collate_fn et mélanger l’ensemble d’entraînement, mais pas l’ensemble de validation :
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)Ensuite, nous réinstantifions notre modèle pour nous assurer que nous ne continuons pas le finetuning d’avant et que nous repartons bien du modèle pré-entraîné de BERT :
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)Ensuite, nous avons besoin d’un optimiseur. Nous utilisons le classique AdamW, qui est comme Adam, mais avec un correctif dans la façon dont le taux de décroissance des poids est appliquée :
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)Une fois que nous avons tous ces objets, nous pouvons les envoyer à la méthode accelerator.prepare() :
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 Si vous entraînez sur un TPU, vous devrez déplacer tout le code à partir de la cellule ci-dessus dans une fonction d’entraînement dédiée. Voir le chapitre 3 pour plus de détails.
Maintenant que nous avons envoyé notre train_dataloader à accelerator.prepare(), nous pouvons utiliser sa longueur pour calculer le nombre d’étapes d’entraînement. Rappelez-vous que nous devrions toujours faire cela après avoir préparé le dataloader car cette méthode modifiera sa longueur. Nous utilisons un programme linéaire classique du taux d’apprentissage à 0 :
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)Enfin, pour pousser notre modèle vers le Hub, nous avons besoin de créer un objet Repository dans un dossier de travail. Tout d’abord, connectez-vous à Hugging Face si vous n’êtes pas déjà connecté. Nous déterminons le nom du dépôt à partir de l’identifiant du modèle que nous voulons donner à notre modèle (n’hésitez pas à remplacer le repo_name par votre propre choix, il doit juste contenir votre nom d’utilisateur et ce que fait la fonction get_full_repo_name()) :
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'sgugger/bert-finetuned-ner-accelerate'Ensuite, nous pouvons cloner ce dépôt dans un dossier local. S’il existe déjà, ce dossier local doit être un clone existant du dépôt avec lequel nous travaillons :
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)Nous pouvons maintenant télécharger tout ce que nous sauvegardons dans output_dir en appelant la méthode repo.push_to_hub(). Cela nous aidera à télécharger les modèles intermédiaires à la fin de chaque époque.
Boucle d’entraînement
Nous sommes maintenant prêts à écrire la boucle d’entraînement complète. Pour simplifier sa partie évaluation, nous définissons cette fonction postprocess() qui prend les prédictions et les étiquettes, et les convertit en listes de chaînes de caractères comme notre objet metric l’attend :
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# Suppression de l'index ignoré (tokens spéciaux) et conversion en étiquettes
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictionsEnsuite, nous pouvons écrire la boucle d’entraînement. Après avoir défini une barre de progression pour suivre l’évolution de l’entraînement, la boucle comporte trois parties :
- L’entraînement proprement dit, qui est l’itération classique sur le
train_dataloader, passage en avant, puis passage en arrière et étape d’optimisation. - L’évaluation, dans laquelle il y a une nouveauté après avoir obtenu les sorties de notre modèle sur un batch : puisque deux processus peuvent avoir paddé les entrées et les étiquettes à des formes différentes, nous devons utiliser
accelerator.pad_across_processes()pour rendre les prédictions et les étiquettes de la même forme avant d’appeler la méthodegather(). Si nous ne le faisons pas, l’évaluation va soit se tromper, soit se bloquer pour toujours. Ensuite, nous envoyons les résultats àmetric.add_batch()et appelonsmetric.compute()une fois que la boucle d’évaluation est terminée. - Sauvegarde et téléchargement, où nous sauvegardons d’abord le modèle et le tokenizer, puis appelons
repo.push_to_hub(). Remarquez que nous utilisons l’argumentblocking=Falsepour indiquer à la bibliothèque 🤗 Hub de pousser dans un processus asynchrone. De cette façon, l’entraînement continue normalement et cette (longue) instruction est exécutée en arrière-plan.
Voici le code complet de la boucle d’entraînement :
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Entraînement
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# Nécessaire pour rembourrer les prédictions et les étiquettes à rassembler
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# Sauvegarder et télécharger
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)Au cas où ce serait la première fois que vous verriez un modèle enregistré avec 🤗 Accelerate, prenons un moment pour inspecter les trois lignes de code qui l’accompagnent :
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
La première ligne est explicite : elle indique à tous les processus d’attendre que tout le monde soit à ce stade avant de continuer. C’est pour s’assurer que nous avons le même modèle dans chaque processus avant de sauvegarder. Ensuite, nous prenons le unwrapped_model qui est le modèle de base que nous avons défini. La méthode accelerator.prepare() modifie le modèle pour qu’il fonctionne dans l’entraînement distribué, donc il n’aura plus la méthode save_pretrained() ; la méthode accelerator.unwrap_model() annule cette étape. Enfin, nous appelons save_pretrained() mais nous disons à cette méthode d’utiliser accelerator.save() au lieu de torch.save().
Une fois ceci fait, vous devriez avoir un modèle qui produit des résultats assez similaires à celui entraîné avec le Trainer. Vous pouvez vérifier le modèle que nous avons formé en utilisant ce code à huggingface-course/bert-finetuned-ner-accelerate. Et si vous voulez tester des modifications de la boucle d’entraînement, vous pouvez les implémenter directement en modifiant le code ci-dessus !
Utilisation du modèle <i> finetuné </i>
Nous vous avons déjà montré comment vous pouvez utiliser le modèle finetuné sur le Hub avec le widget d’inférence. Pour l’utiliser localement dans un pipeline, vous devez juste spécifier l’identifiant de modèle approprié :
from transformers import pipeline
# Remplacez ceci par votre propre checkpoint
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]Super ! Notre modèle fonctionne aussi bien que le modèle par défaut pour ce pipeline !