(Automatic) Curriculum Learning for RL
While most of the RL methods seen in this course work well in practice, there are some cases where using them alone fails. This can happen, for instance, when:
- the task to learn is hard and requires an incremental acquisition of skills (for instance when one wants to make a bipedal agent learn to go through hard obstacles, it must first learn to stand, then walk, then maybe jump…)
- there are variations in the environment (that affect the difficulty) and one wants its agent to be robust to them
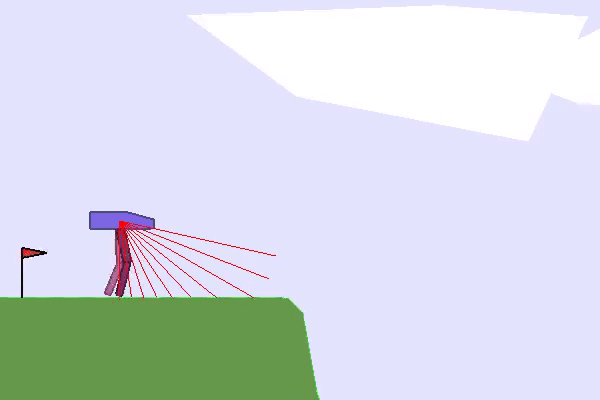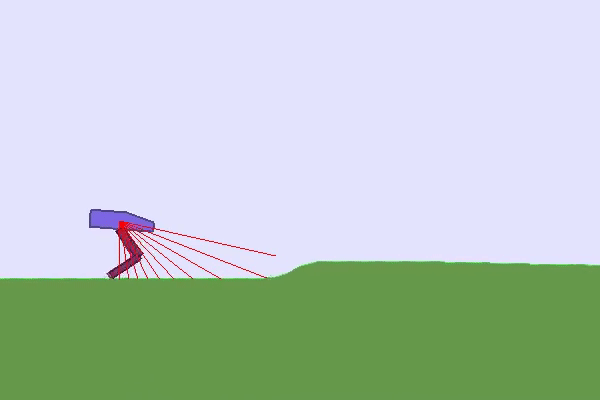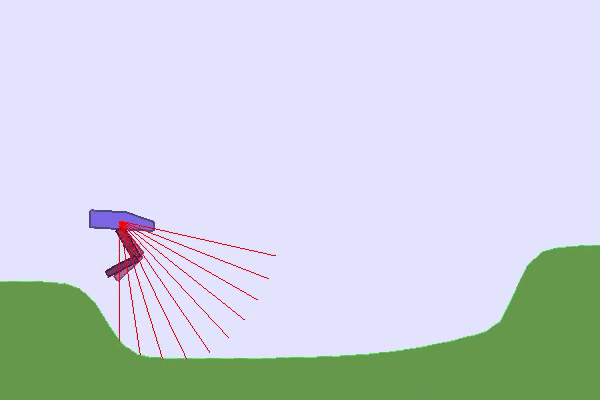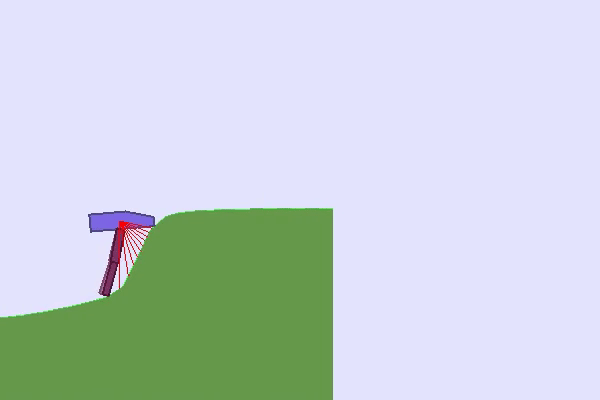

In such cases, it seems needed to propose different tasks to our RL agent and organize them such that the agent progressively acquires skills. This approach is called Curriculum Learning and usually implies a hand-designed curriculum (or set of tasks organized in a specific order). In practice, one can, for instance, control the generation of the environment, the initial states, or use Self-Play and control the level of opponents proposed to the RL agent.
As designing such a curriculum is not always trivial, the field of Automatic Curriculum Learning (ACL) proposes to design approaches that learn to create such an organization of tasks in order to maximize the RL agent’s performances. Portelas et al. proposed to define ACL as:
… a family of mechanisms that automatically adapt the distribution of training data by learning to adjust the selection of learning situations to the capabilities of RL agents.
As an example, OpenAI used Domain Randomization (they applied random variations on the environment) to make a robot hand solve Rubik’s Cubes.

Finally, you can play with the robustness of agents trained in the TeachMyAgent benchmark by controlling environment variations or even drawing the terrain 👇
Further reading
For more information, we recommend that you check out the following resources:
Overview of the field
Recent methods
- Evolving Curricula with Regret-Based Environment Design
- Curriculum Reinforcement Learning via Constrained Optimal Transport
- Prioritized Level Replay
Author
This section was written by Clément Romac
< > Update on GitHub