Deep RL Course documentation
Designing Multi-Agents systems
Designing Multi-Agents systems
For this section, you’re going to watch this excellent introduction to multi-agents made by Brian Douglas .
In this video, Brian talked about how to design multi-agent systems. He specifically took a multi-agents system of vacuum cleaners and asked: how can can cooperate with each other?
We have two solutions to design this multi-agent reinforcement learning system (MARL).
Decentralized system
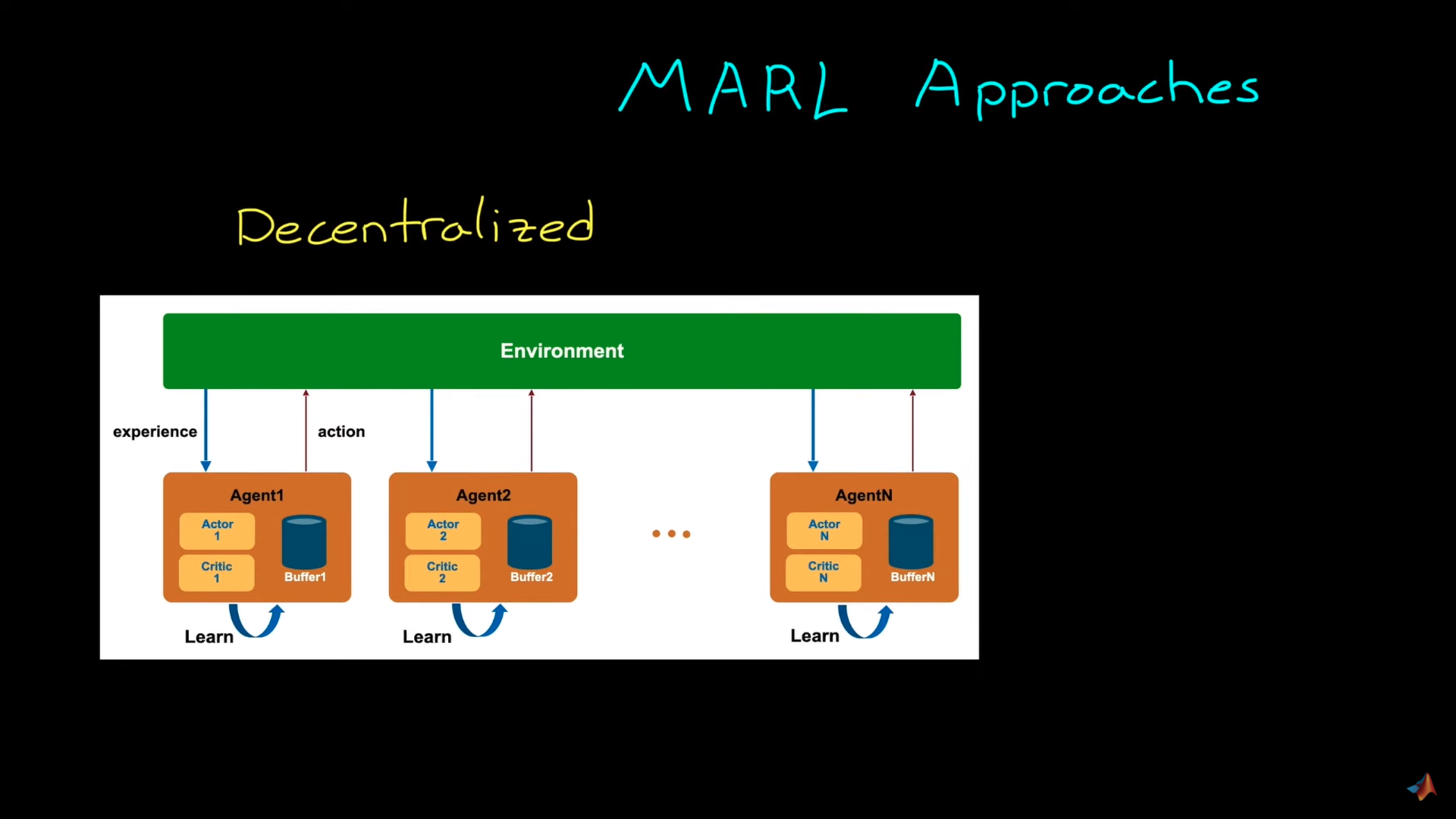
In decentralized learning, each agent is trained independently from the others. In the example given, each vacuum learns to clean as many places as it can without caring about what other vacuums (agents) are doing.
The benefit is that since no information is shared between agents, these vacuums can be designed and trained like we train single agents.
The idea here is that our training agent will consider other agents as part of the environment dynamics. Not as agents.
However, the big drawback of this technique is that it will make the environment non-stationary since the underlying Markov decision process changes over time as other agents are also interacting in the environment. And this is problematic for many Reinforcement Learning algorithms that can’t reach a global optimum with a non-stationary environment.
Centralized approach
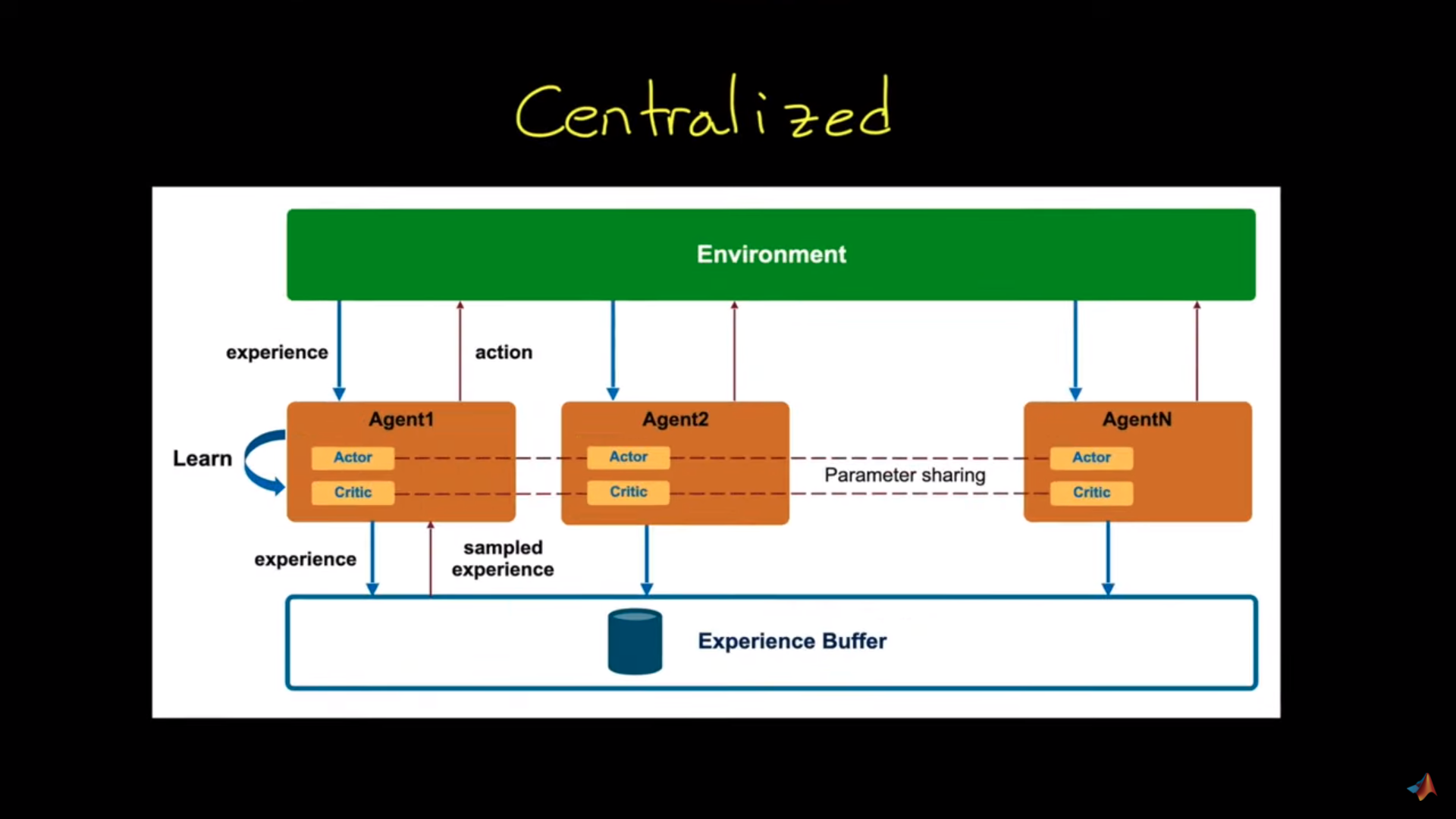
In this architecture, we have a high-level process that collects agents’ experiences: the experience buffer. And we’ll use these experiences to learn a common policy.
For instance, in the vacuum cleaner example, the observation will be:
- The coverage map of the vacuums.
- The position of all the vacuums.
We use that collective experience to train a policy that will move all three robots in the most beneficial way as a whole. So each robot is learning from their common experience. We now have a stationary environment since all the agents are treated as a larger entity, and they know the change of other agents’ policies (since it’s the same as theirs).
If we recap:
In a decentralized approach, we treat all agents independently without considering the existence of the other agents.
- In this case, all agents consider others agents as part of the environment.
- It’s a non-stationarity environment condition, so has no guarantee of convergence.
In a centralized approach:
- A single policy is learned from all the agents.
- Takes as input the present state of an environment and the policy outputs joint actions.
- The reward is global.