An introduction to Multi-Agents Reinforcement Learning (MARL)
From single agent to multiple agents
In the first unit, we learned to train agents in a single-agent system. When our agent was alone in its environment: it was not cooperating or collaborating with other agents.
When we do multi-agents reinforcement learning (MARL), we are in a situation where we have multiple agents that share and interact in a common environment.
For instance, you can think of a warehouse where multiple robots need to navigate to load and unload packages.

Or a road with several autonomous vehicles.
In these examples, we have multiple agents interacting in the environment and with the other agents. This implies defining a multi-agents system. But first, let’s understand the different types of multi-agent environments.
Different types of multi-agent environments
Given that, in a multi-agent system, agents interact with other agents, we can have different types of environments:
- Cooperative environments: where your agents need to maximize the common benefits.
For instance, in a warehouse, robots must collaborate to load and unload the packages efficiently (as fast as possible).
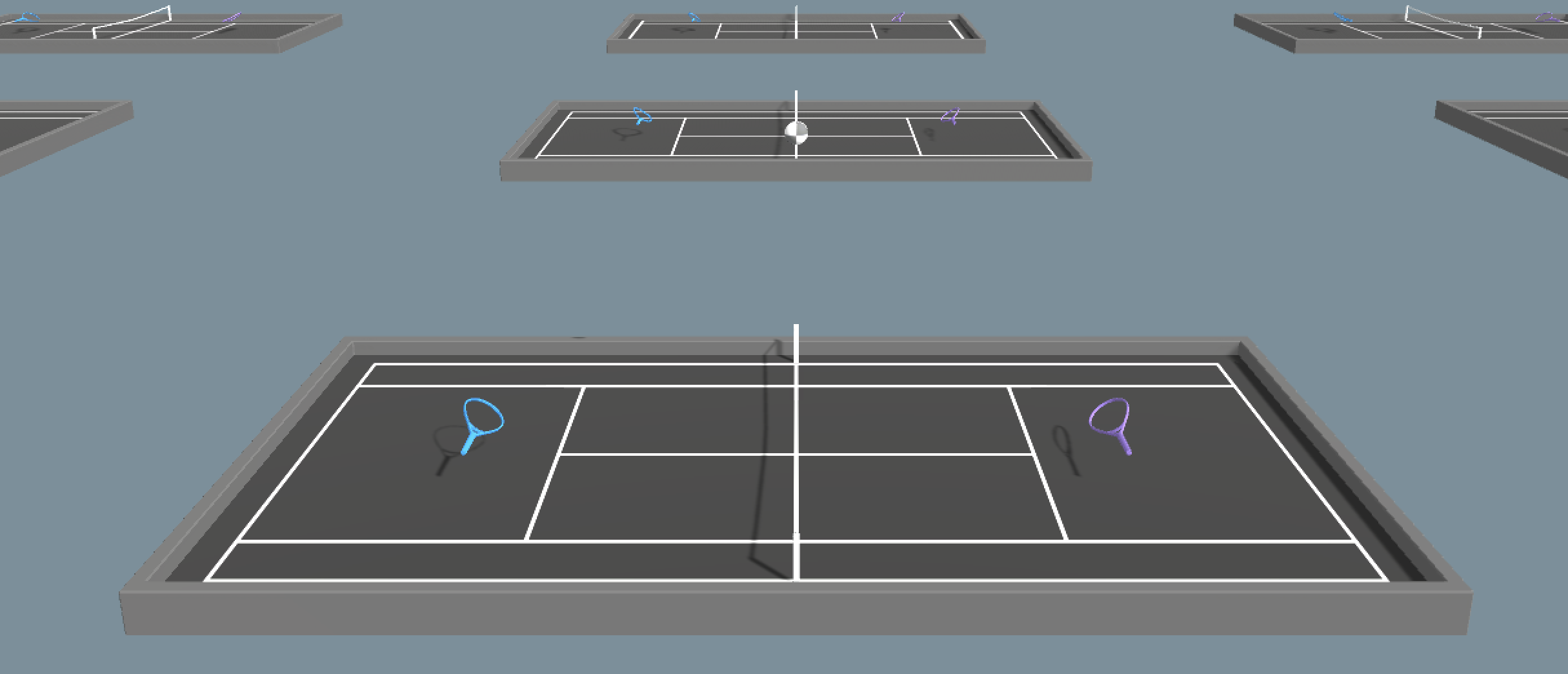
- Competitive/Adversarial environments: in this case, your agent wants to maximize its benefits by minimizing the opponent’s.
For example, in a game of tennis, each agent wants to beat the other agent.
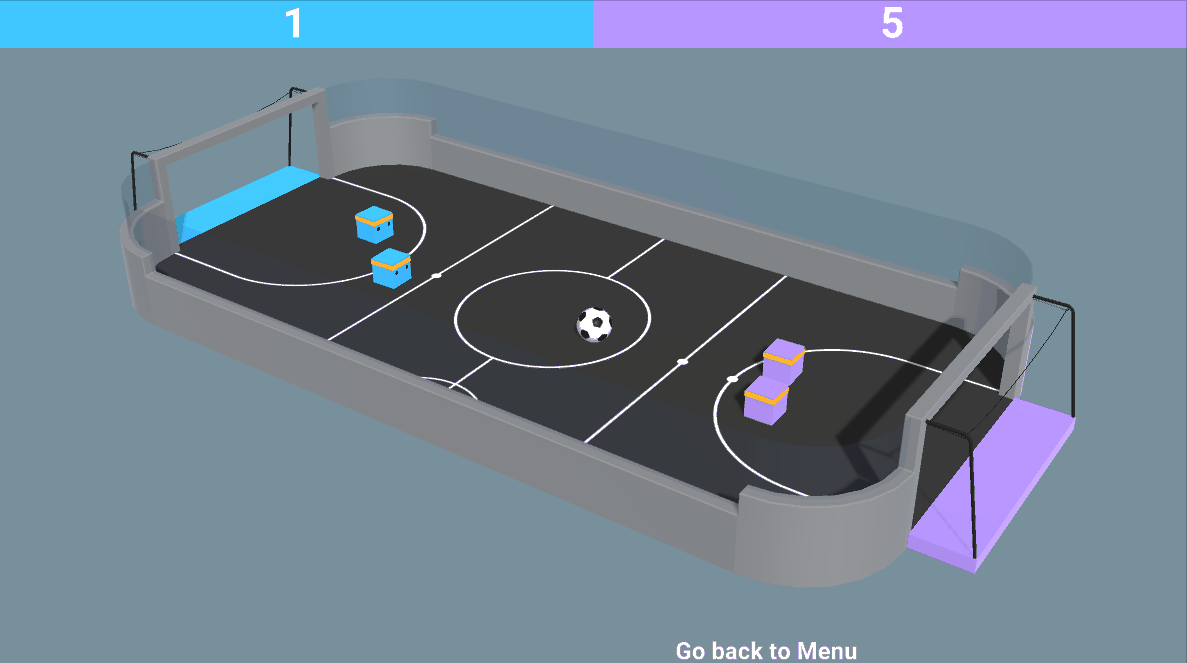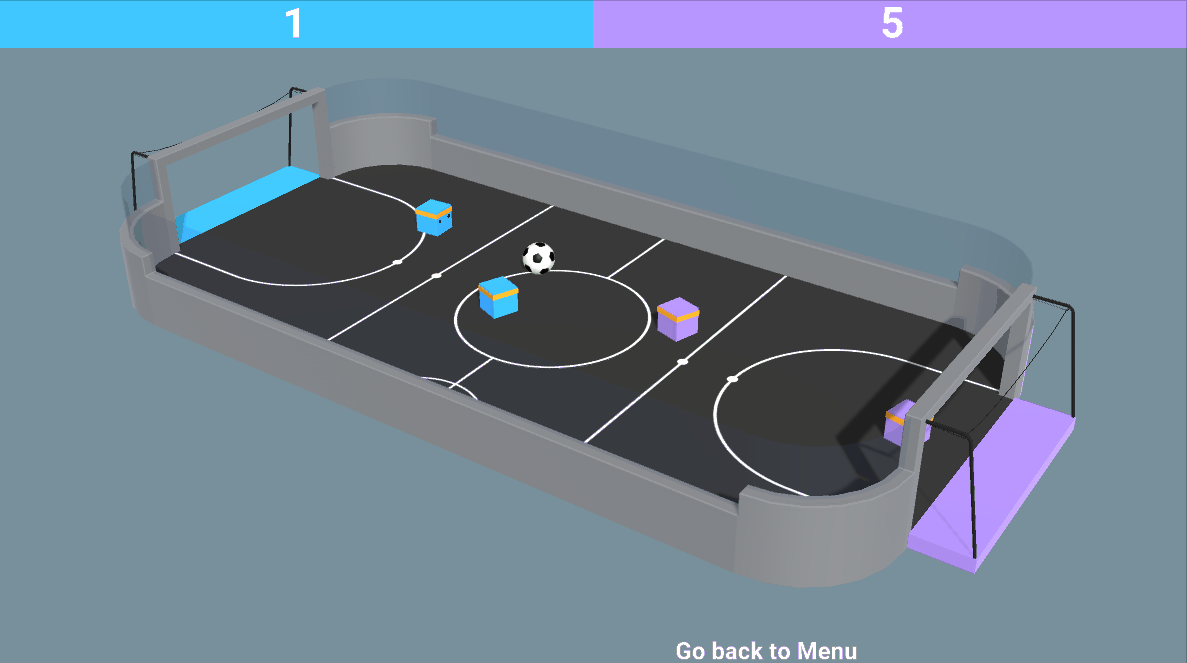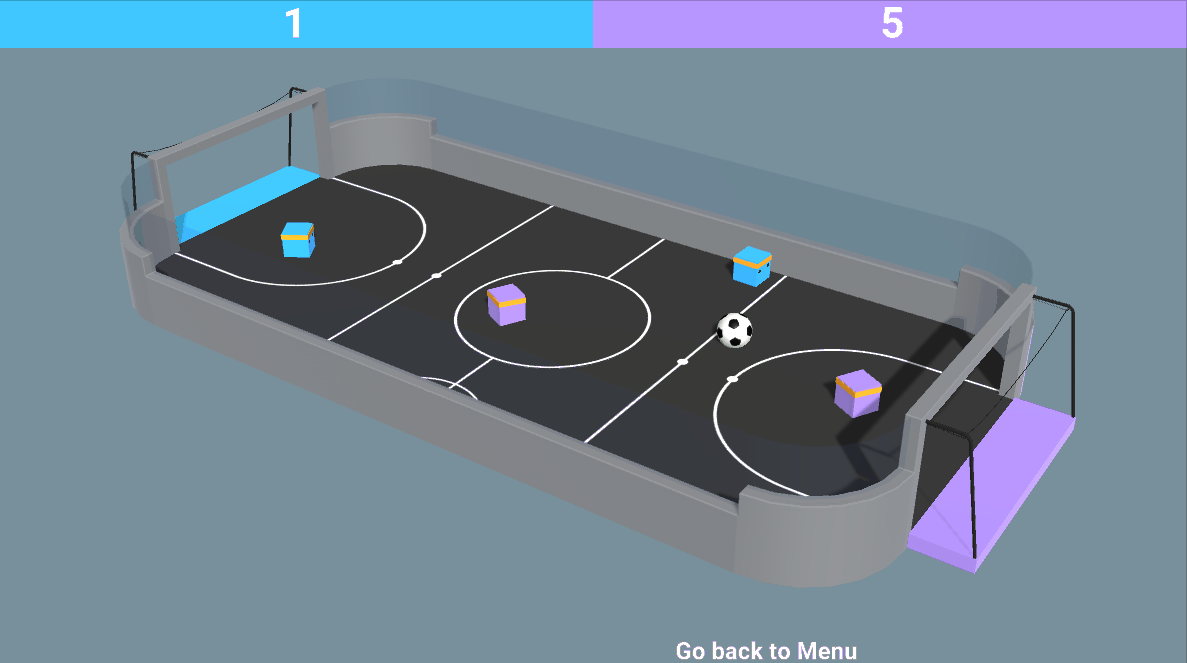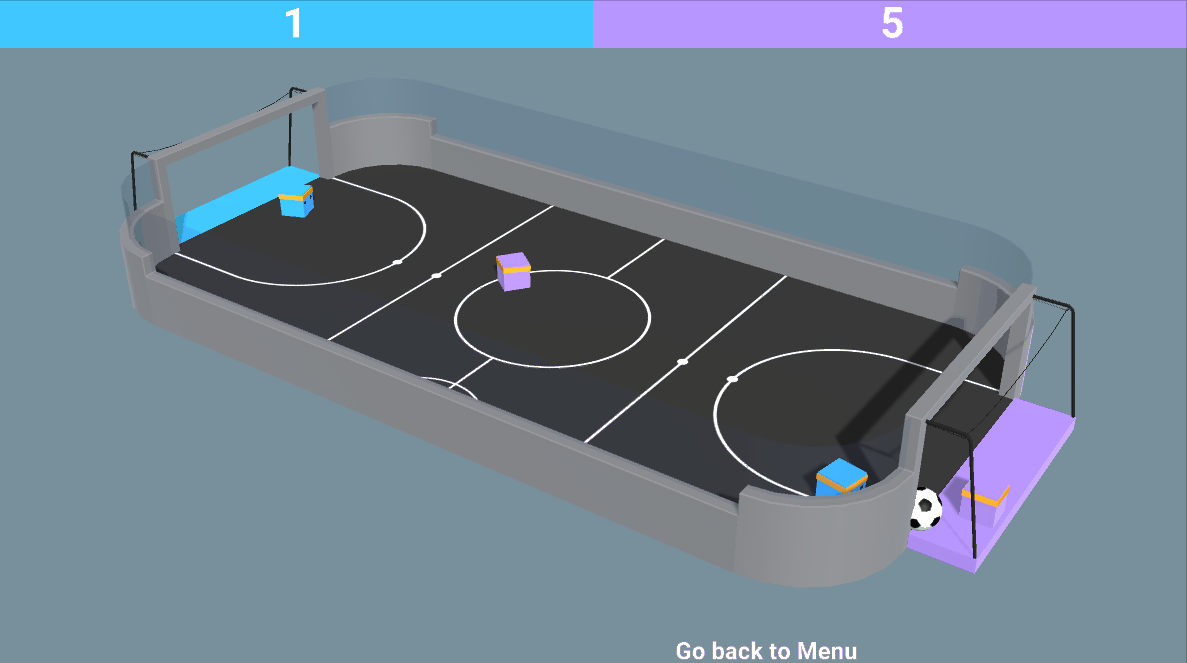
- Mixed of both adversarial and cooperative: like in our SoccerTwos environment, two agents are part of a team (blue or purple): they need to cooperate with each other and beat the opponent team.
So now we might wonder: how can we design these multi-agent systems? Said differently, how can we train agents in a multi-agent setting ?
< > Update on GitHub