Deep RL Course documentation
Introduction
Introduction

Since the beginning of this course, we learned to train agents in a single-agent system where our agent was alone in its environment: it was not cooperating or collaborating with other agents.
This worked great, and the single-agent system is useful for many applications.
But, as humans, we live in a multi-agent world. Our intelligence comes from interaction with other agents. And so, our goal is to create agents that can interact with other humans and other agents.
Consequently, we must study how to train deep reinforcement learning agents in a multi-agents system to build robust agents that can adapt, collaborate, or compete.
So today we’re going to learn the basics of the fascinating topic of multi-agents reinforcement learning (MARL).
And the most exciting part is that, during this unit, you’re going to train your first agents in a multi-agents system: a 2vs2 soccer team that needs to beat the opponent team.
And you’re going to participate in AI vs. AI challenge where your trained agent will compete against other classmates’ agents every day and be ranked on a new leaderboard.
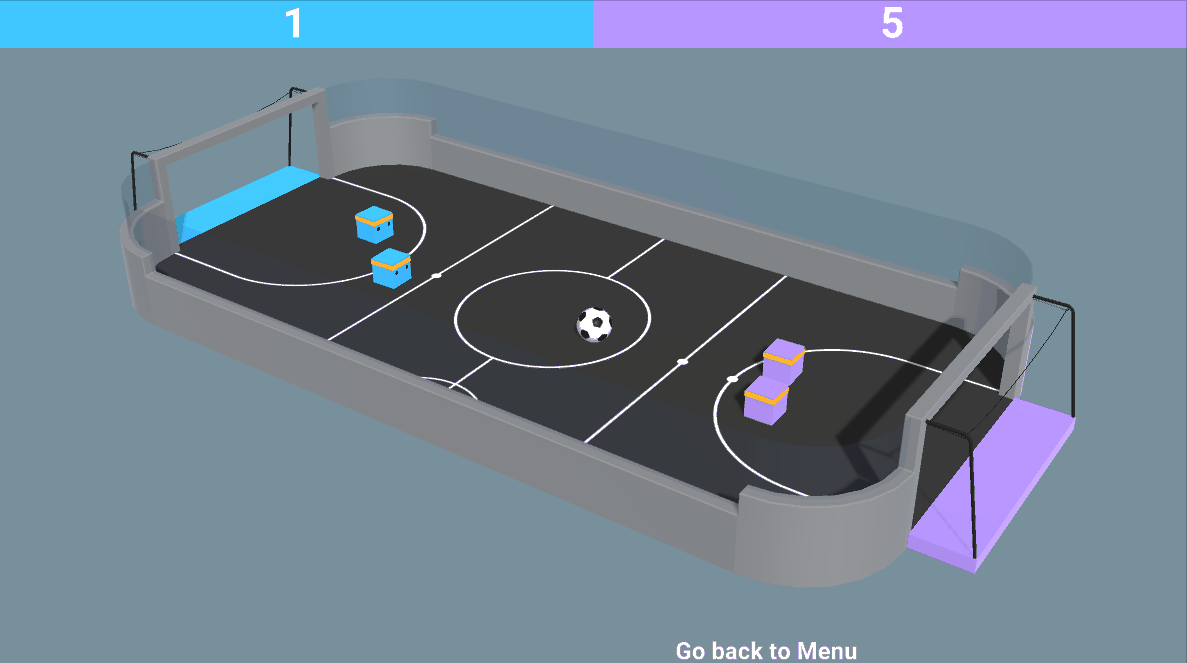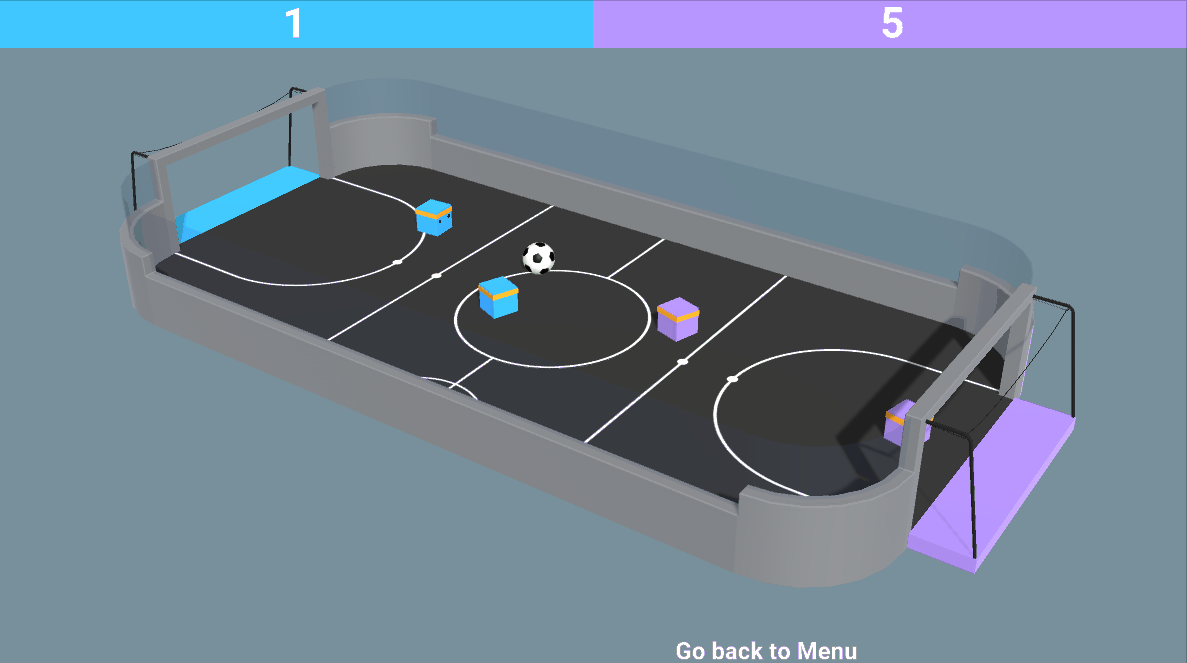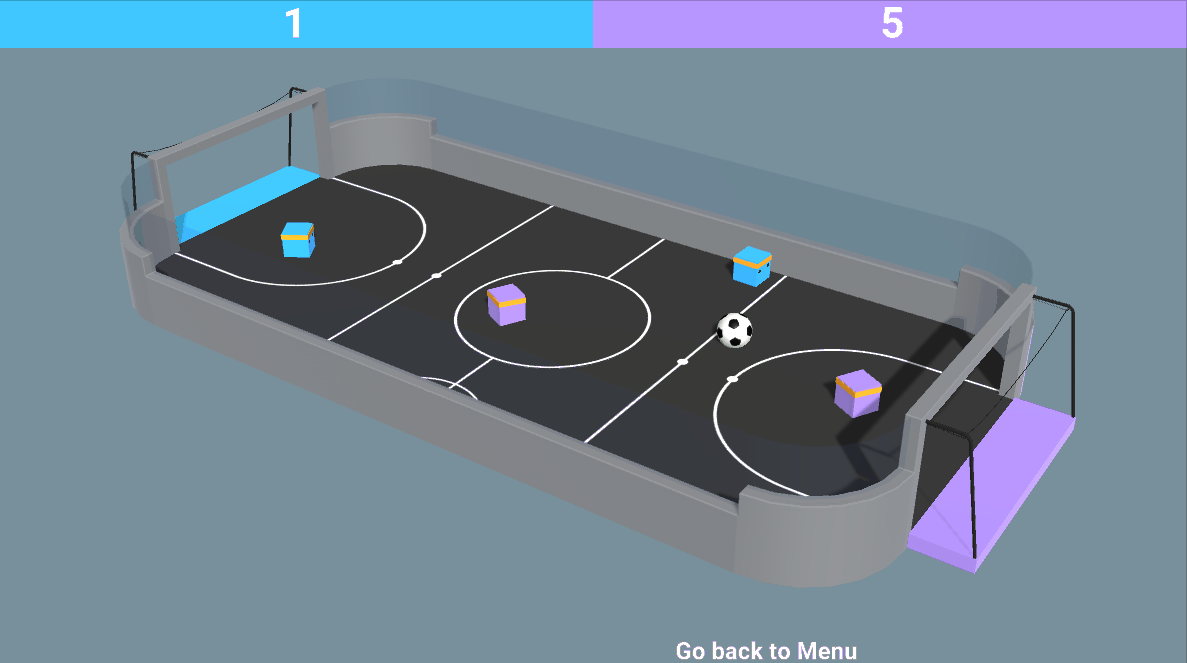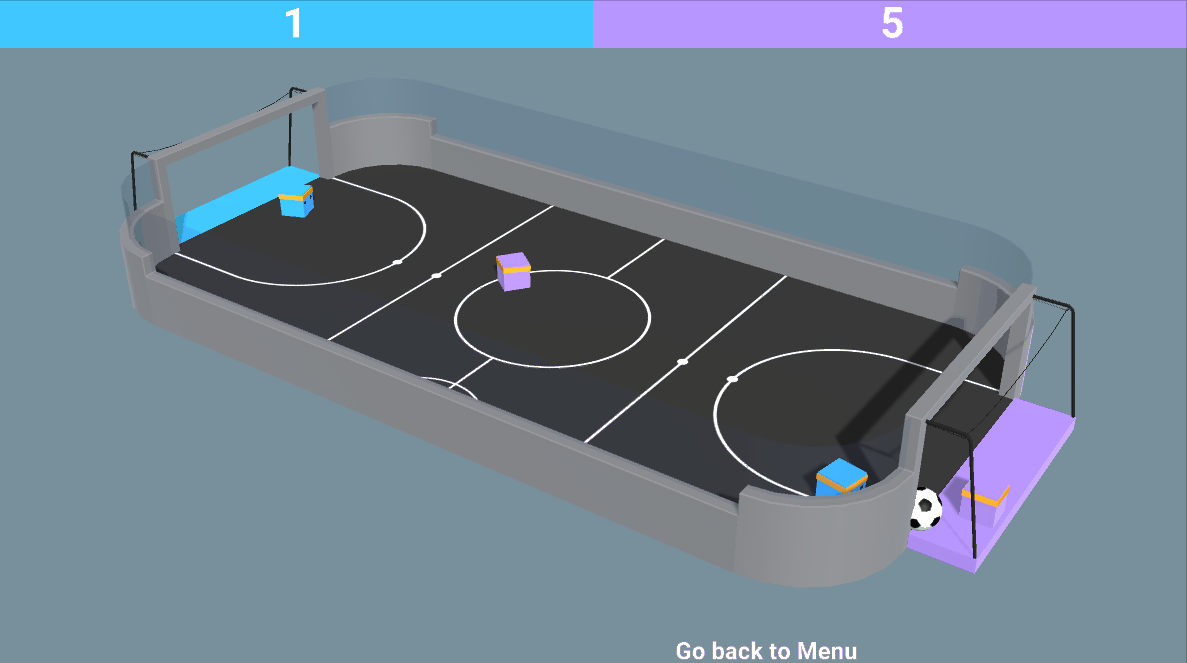
So let’s get started!
< > Update on GitHub