Second Quiz
The best way to learn and to avoid the illusion of competence is to test yourself. This will help you to find where you need to reinforce your knowledge.
Q1: What is Q-Learning?
Q2: What is a Q-table?
Q3: Why if we have an optimal Q-function Q* we have an optimal policy?
Solution
Because if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take.

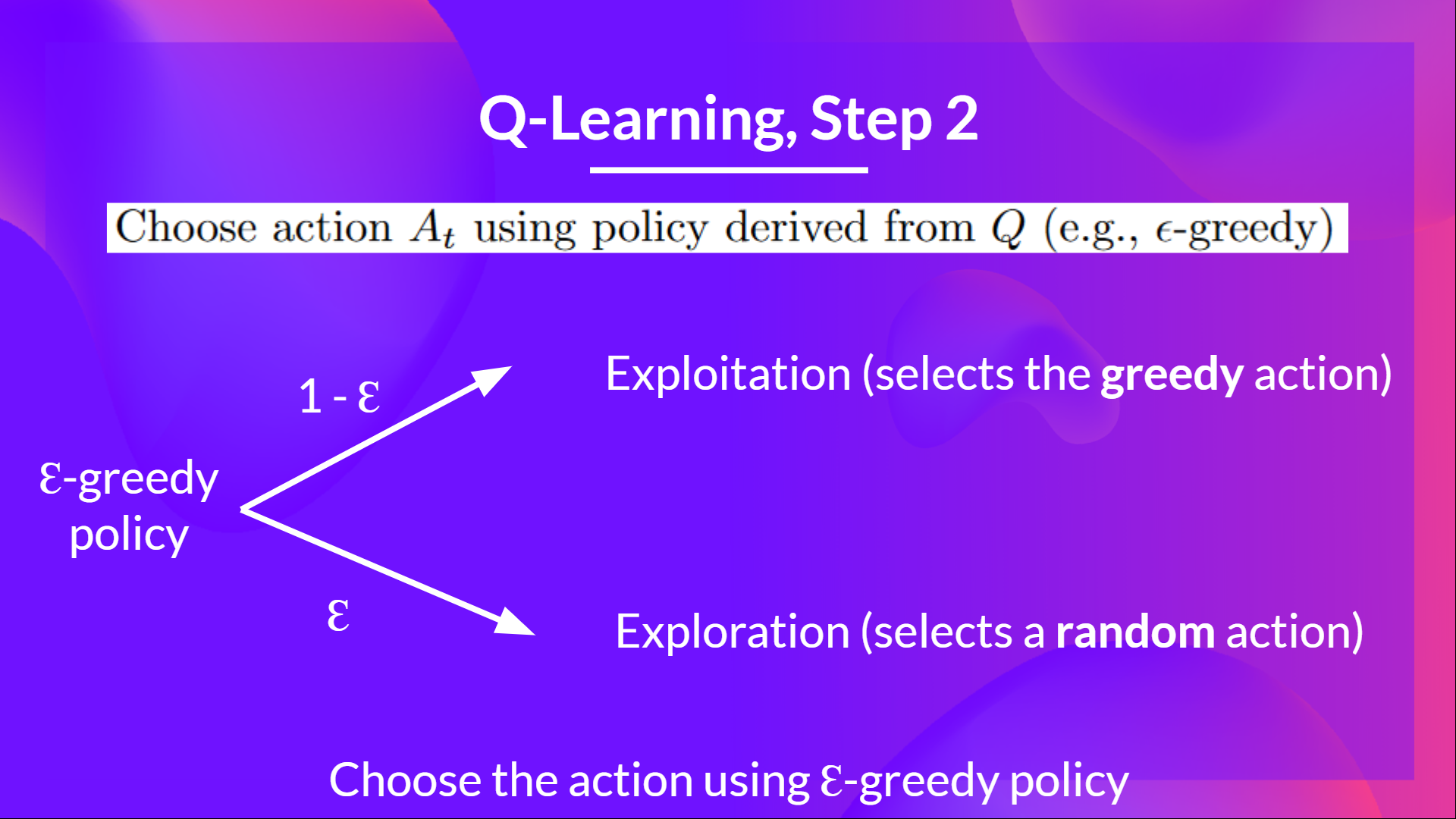
Q4: Can you explain what is Epsilon-Greedy Strategy?
Solution
Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.The idea is that we define epsilon ɛ = 1.0:
- With probability 1 — ɛ : we do exploitation (aka our agent selects the action with the highest state-action pair value).
- With probability ɛ : we do exploration (trying random action).
Q5: How do we update the Q value of a state, action pair?
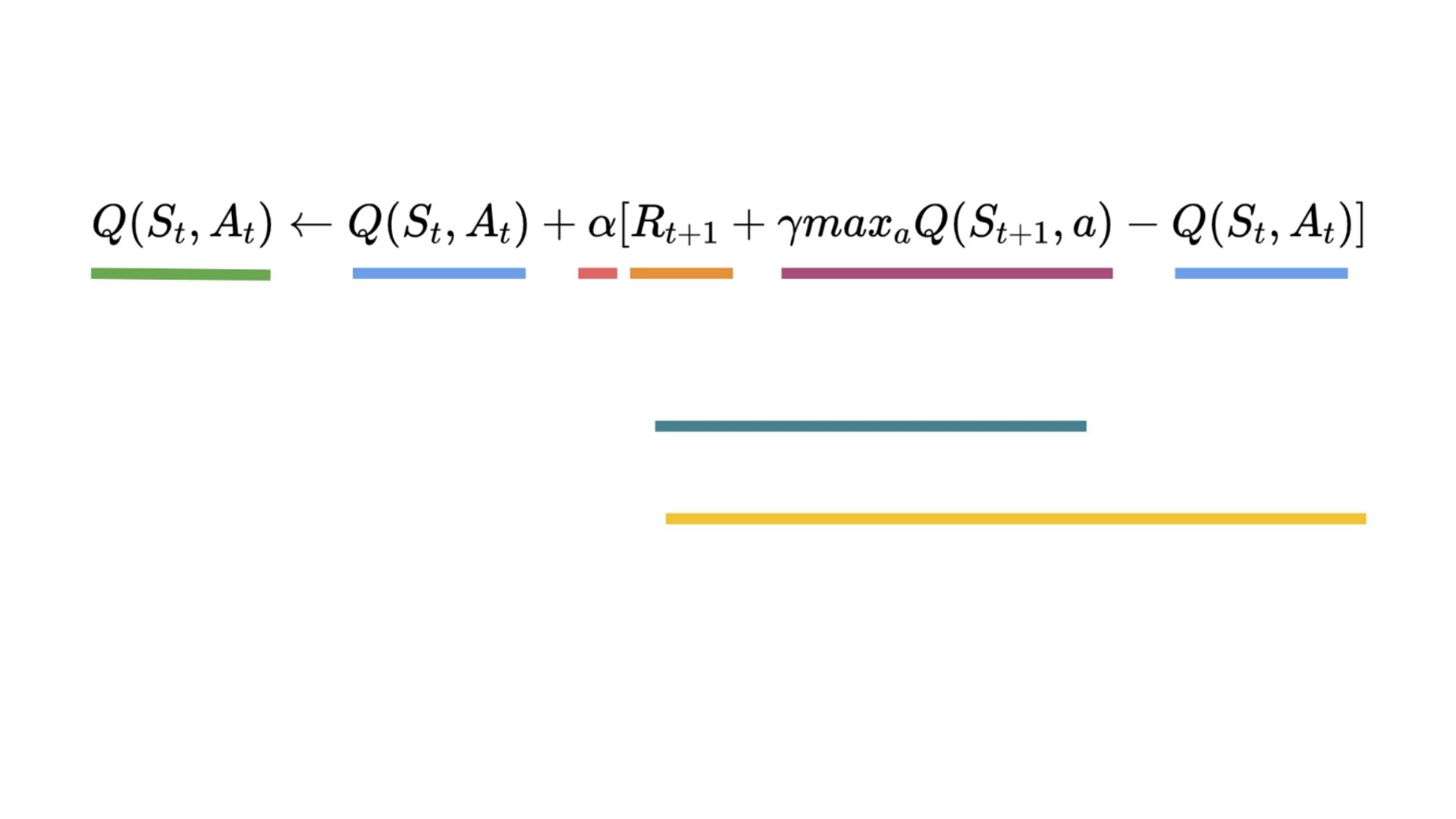
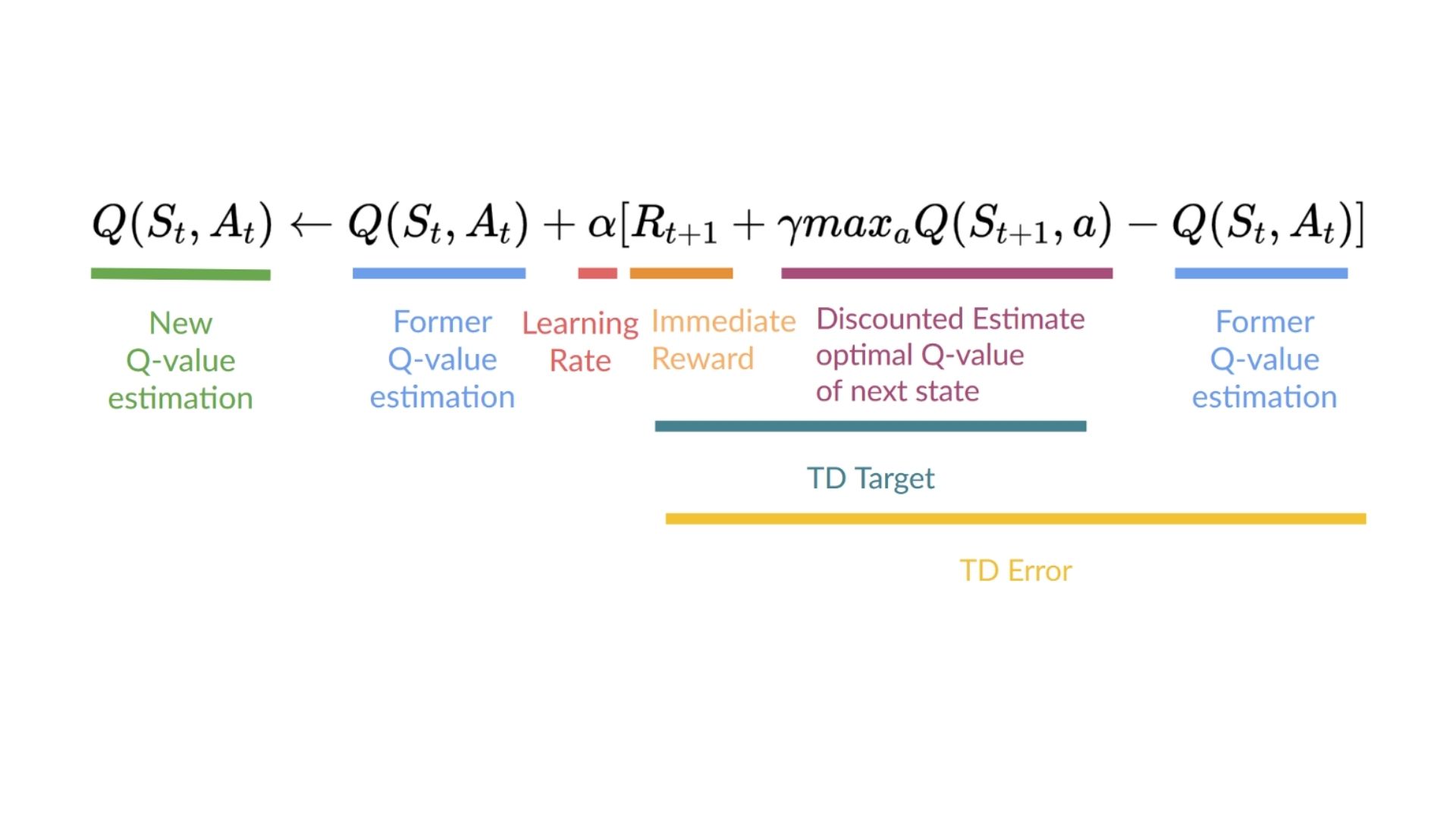
Solution
Q6: What’s the difference between on-policy and off-policy
Solution

Congrats on finishing this Quiz 🥳, if you missed some elements, take time to read again the chapter to reinforce (😏) your knowledge.
< > Update on GitHub