RAG 评估
本 notebook 演示了如何评估你的 RAG(Retrieval Augmented Generation),通过构建一个合成评估数据集并使用 LLM-as-a-judge 来计算你系统的准确性。
对于 RAG 系统的介绍,你可以查看这个技术指南!
RAG 系统很复杂: 这里有一个 RAG 流程图,我们用蓝色标注了系统增强的所有可能性:
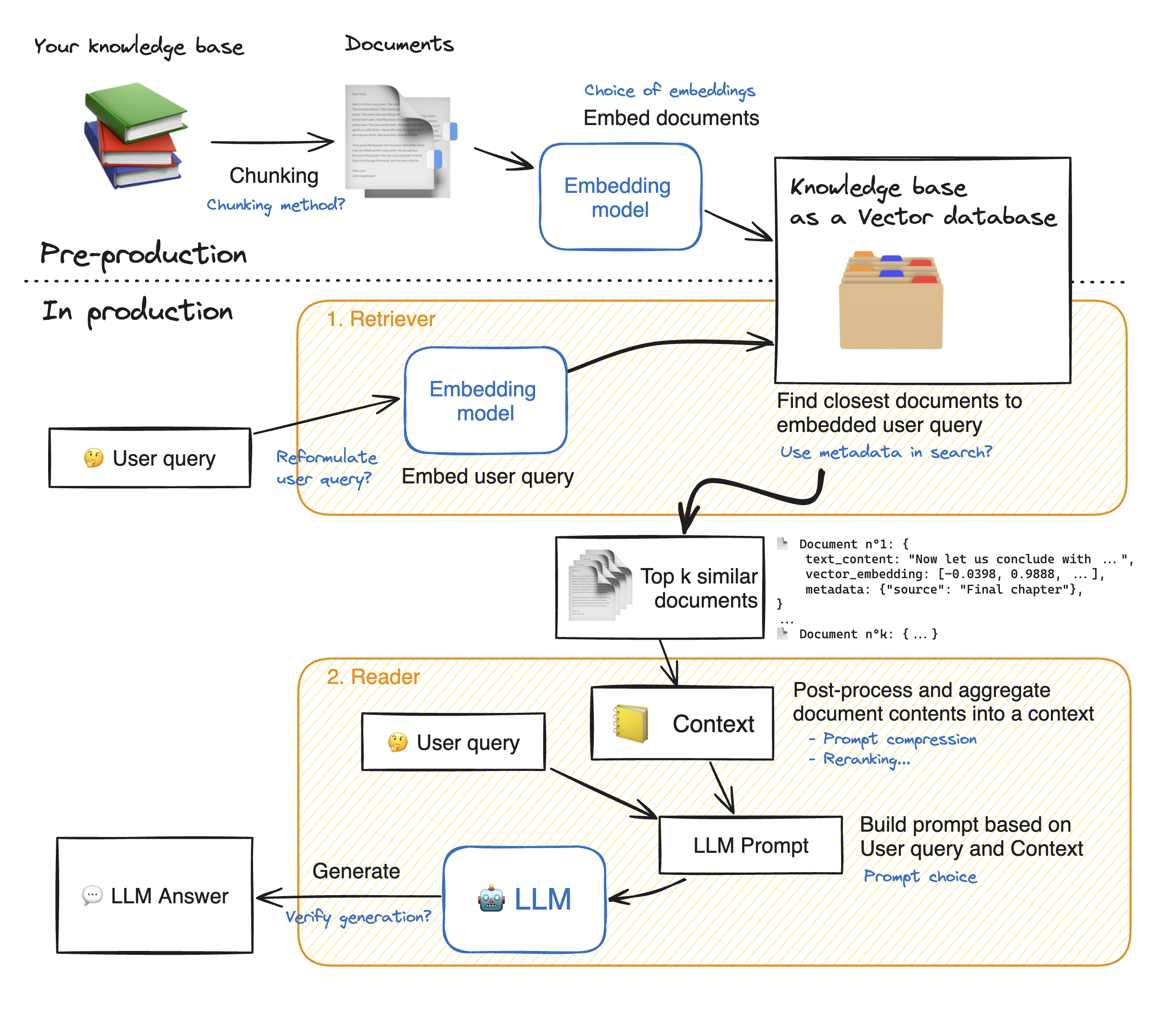
实施上述任何改进都可能会带来巨大的性能提升;但如果无法监控对系统性能的影响,那么进行任何更改都是无用的!让我们看看如何评估我们的 RAG 系统。
评估RAG性能
由于有如此多的部分需要调整,这些部分对性能有很大影响,因此对 RAG 系统进行基准测试是至关重要的。
对于我们的评估流水线,我们将需要:
- 一个带有问题-答案对的评估数据集(QA 对)
- 一个评估器,用于计算我们的系统在上面的评估数据集上的准确性。
➡️ 结果发现,我们可以在整个过程中使用 LLMs 来帮助!
- 评估数据集将由 LLM 🤖 合成生成,并且问题将由其他 LLM 🤖 过滤掉
- 然后,LLM-as-a-judge 智能体 🤖 将在这个合成数据集上执行评估。
让我们深入挖掘并开始构建我们的评估流水线! 首先,安装所需的模型依赖项。
!pip install -q torch transformers transformers langchain sentence-transformers tqdm openpyxl openai pandas datasets langchain-community ragatouille
%reload_ext autoreload
%autoreload 2from tqdm.auto import tqdm
import pandas as pd
from typing import Optional, List, Tuple
import json
import datasets
pd.set_option("display.max_colwidth", None)from huggingface_hub import notebook_login
notebook_login()加载你的知识基础
ds = datasets.load_dataset("m-ric/huggingface_doc", split="train")1. 为评估构建合成数据集
我们首先构建一个问题和相关上下文的综合数据集。方法是先从我们的知识库中获取元素,并让 LLM 根据这些文档生成问题。
然后,我们设置其他 LLM 智能体作为生成问答对的质置过滤器:每个智能体将作为一个特定缺陷的过滤器。
1.1. 准备源数据文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LangchainDocument
langchain_docs = [LangchainDocument(page_content=doc["text"], metadata={"source": doc["source"]}) for doc in tqdm(ds)]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=200,
add_start_index=True,
separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = []
for doc in langchain_docs:
docs_processed += text_splitter.split_documents([doc])1.2. 为问题生成设置智能体
我们采用 Mixtral 作为问答对的生成,因为他在各个排行榜上表现极佳,比如 Chatbot Arena。
from huggingface_hub import InferenceClient
repo_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
llm_client = InferenceClient(
model=repo_id,
timeout=120,
)
def call_llm(inference_client: InferenceClient, prompt: str):
response = inference_client.post(
json={
"inputs": prompt,
"parameters": {"max_new_tokens": 1000},
"task": "text-generation",
},
)
return json.loads(response.decode())[0]["generated_text"]
call_llm(llm_client, "This is a test context")QA_generation_prompt = """
Your task is to write a factoid question and an answer given a context.
Your factoid question should be answerable with a specific, concise piece of factual information from the context.
Your factoid question should be formulated in the same style as questions users could ask in a search engine.
This means that your factoid question MUST NOT mention something like "according to the passage" or "context".
Provide your answer as follows:
Output:::
Factoid question: (your factoid question)
Answer: (your answer to the factoid question)
Now here is the context.
Context: {context}\n
Output:::"""现在让我们生成我们的问答对。
对于这个例子,我们只生成 10 个问答对,并从 Hub 加载其余的。
但是对于你的特定知识库,考虑到你想要获得至少约 100 个测试样本,并且考虑到我们稍后会用我们的批判智能体过滤掉大约一半的样本,你应该生成更多的样本,超过 200 个。
import random
N_GENERATIONS = 10 # We intentionally generate only 10 QA couples here for cost and time considerations
print(f"Generating {N_GENERATIONS} QA couples...")
outputs = []
for sampled_context in tqdm(random.sample(docs_processed, N_GENERATIONS)):
# Generate QA couple
output_QA_couple = call_llm(llm_client, QA_generation_prompt.format(context=sampled_context.page_content))
try:
question = output_QA_couple.split("Factoid question: ")[-1].split("Answer: ")[0]
answer = output_QA_couple.split("Answer: ")[-1]
assert len(answer) < 300, "Answer is too long"
outputs.append(
{
"context": sampled_context.page_content,
"question": question,
"answer": answer,
"source_doc": sampled_context.metadata["source"],
}
)
except:
continuedisplay(pd.DataFrame(outputs).head(1))1.3. 设置批判智能体
之前的智能体生成的问题可能存在许多缺陷:在验证这些问题之前,我们应该进行质量检查。
因此,我们构建了批判智能体,它们将根据以下几个标准对每个问题进行评分,这些标准在这篇论文中给出:
- 具体性(Groundedness):问题是否可以从给定的上下文中得到回答?
- 相关性(Relevance):问题对用户是否相关?例如,
"transformers 4.29.1 发布的日期是什么?"对于 ML 用户来说并不相关。
我们注意到的一个最后的失败案例是,当一个函数是为生成问题的特定环境量身定做的,但本身难以理解,比如"这个指南中使用的函数的名称是什么?"。
我们也为这个标准构建了一个批判智能体:
- 独立(Stand-alone):对于一个具有领域知识/互联网访问权限的人来说,问题在没有任何上下文的情况下是否可以理解?与此相反的是,对于从特定博客文章生成的问题比如”这篇文章中使用的函数是什么?”
我们系统地用所有这些智能体对函数进行评分,每当任何一个智能体的分数太低时,我们就从我们的评估数据集中删除这个问题。
💡 当要求智能体输出分数时,我们首先要求它们产生其理由。这将帮助我们验证分数,但最重要的是,要求它首先输出理由给了模型更多的 token 来思考和详细阐述答案,然后再将其总结成一个单一的分数 token。
我们现在构建并运行这些批判智能体。
question_groundedness_critique_prompt = """
You will be given a context and a question.
Your task is to provide a 'total rating' scoring how well one can answer the given question unambiguously with the given context.
Give your answer on a scale of 1 to 5, where 1 means that the question is not answerable at all given the context, and 5 means that the question is clearly and unambiguously answerable with the context.
Provide your answer as follows:
Answer:::
Evaluation: (your rationale for the rating, as a text)
Total rating: (your rating, as a number between 1 and 5)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here are the question and context.
Question: {question}\n
Context: {context}\n
Answer::: """
question_relevance_critique_prompt = """
You will be given a question.
Your task is to provide a 'total rating' representing how useful this question can be to machine learning developers building NLP applications with the Hugging Face ecosystem.
Give your answer on a scale of 1 to 5, where 1 means that the question is not useful at all, and 5 means that the question is extremely useful.
Provide your answer as follows:
Answer:::
Evaluation: (your rationale for the rating, as a text)
Total rating: (your rating, as a number between 1 and 5)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here is the question.
Question: {question}\n
Answer::: """
question_standalone_critique_prompt = """
You will be given a question.
Your task is to provide a 'total rating' representing how context-independant this question is.
Give your answer on a scale of 1 to 5, where 1 means that the question depends on additional information to be understood, and 5 means that the question makes sense by itself.
For instance, if the question refers to a particular setting, like 'in the context' or 'in the document', the rating must be 1.
The questions can contain obscure technical nouns or acronyms like Gradio, Hub, Hugging Face or Space and still be a 5: it must simply be clear to an operator with access to documentation what the question is about.
For instance, "What is the name of the checkpoint from which the ViT model is imported?" should receive a 1, since there is an implicit mention of a context, thus the question is not independant from the context.
Provide your answer as follows:
Answer:::
Evaluation: (your rationale for the rating, as a text)
Total rating: (your rating, as a number between 1 and 5)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here is the question.
Question: {question}\n
Answer::: """print("Generating critique for each QA couple...")
for output in tqdm(outputs):
evaluations = {
"groundedness": call_llm(
llm_client,
question_groundedness_critique_prompt.format(context=output["context"], question=output["question"]),
),
"relevance": call_llm(
llm_client,
question_relevance_critique_prompt.format(question=output["question"]),
),
"standalone": call_llm(
llm_client,
question_standalone_critique_prompt.format(question=output["question"]),
),
}
try:
for criterion, evaluation in evaluations.items():
score, eval = (
int(evaluation.split("Total rating: ")[-1].strip()),
evaluation.split("Total rating: ")[-2].split("Evaluation: ")[1],
)
output.update(
{
f"{criterion}_score": score,
f"{criterion}_eval": eval,
}
)
except Exception as e:
continue现在让我们基于我们批判智能体的分数过滤掉不好的问题:
>>> import pandas as pd
>>> pd.set_option("display.max_colwidth", None)
>>> generated_questions = pd.DataFrame.from_dict(outputs)
>>> print("Evaluation dataset before filtering:")
>>> display(
... generated_questions[
... [
... "question",
... "answer",
... "groundedness_score",
... "relevance_score",
... "standalone_score",
... ]
... ]
... )
>>> generated_questions = generated_questions.loc[
... (generated_questions["groundedness_score"] >= 4)
... & (generated_questions["relevance_score"] >= 4)
... & (generated_questions["standalone_score"] >= 4)
... ]
>>> print("============================================")
>>> print("Final evaluation dataset:")
>>> display(
... generated_questions[
... [
... "question",
... "answer",
... "groundedness_score",
... "relevance_score",
... "standalone_score",
... ]
... ]
... )
>>> eval_dataset = datasets.Dataset.from_pandas(generated_questions, split="train", preserve_index=False)Evaluation dataset before filtering:
现在我们合成评估数据集已完成!我们可以在这个评估数据集上评估不同的 RAG 系统。
我们在这里只生成了少数几个问答对,以减少时间和成本。下面,让我们通过加载一个预先生成的数据集来进行下一部分:
eval_dataset = datasets.load_dataset("m-ric/huggingface_doc_qa_eval", split="train")2. 构建我们的 RAG 系统
2.1. 预处理文档来构建我们的向量数据库
- 在这一部分,我们将知识库中的文档分割成更小的片段:这些将是被检索器选取的片段,然后被阅读器 LLM 作为支持其答案的元素。
- 目标是构建语义上相关的片段:不要太小,以免不足以支持答案,也不要太大,以免稀释单个内容。
文本分割有许多选项:
- 每隔
n个单词/字符分割,但这有可能割裂段落甚至句子 - 在
n个单词/字符后分割,但只在句子边界处 - 递归分割 尝试通过树状处理文档来保留更多文档结构,首先在最大单元(章节)上分割,然后递归地在更小单元(段落,句子)上分割。 要了解更多关于分块的信息,我建议你阅读由 Greg Kamradt 编写的不错的教程 。
这个 space 让你可视化不同的分割选项是如何影响你得到的片段的流程。
在以下内容中,我们使用 Langchain 的
RecursiveCharacterTextSplitter。 💡 为了在我们的文本分割器中测量片段长度,我们的长度函数将不是字符的数量,而是 token 化文本中的 token 数量:实际上,对于后续处理 token 的嵌入器来说,以 token 为单位测量长度更为相关,并且在经验上表现更好.
from langchain.docstore.document import Document as LangchainDocument
RAW_KNOWLEDGE_BASE = [
LangchainDocument(page_content=doc["text"], metadata={"source": doc["source"]}) for doc in tqdm(ds)
]from langchain.text_splitter import RecursiveCharacterTextSplitter
from transformers import AutoTokenizer
def split_documents(
chunk_size: int,
knowledge_base: List[LangchainDocument],
tokenizer_name: str,
) -> List[LangchainDocument]:
"""
Split documents into chunks of size `chunk_size` characters and return a list of documents.
"""
text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
AutoTokenizer.from_pretrained(tokenizer_name),
chunk_size=chunk_size,
chunk_overlap=int(chunk_size / 10),
add_start_index=True,
strip_whitespace=True,
separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = []
for doc in knowledge_base:
docs_processed += text_splitter.split_documents([doc])
# Remove duplicates
unique_texts = {}
docs_processed_unique = []
for doc in docs_processed:
if doc.page_content not in unique_texts:
unique_texts[doc.page_content] = True
docs_processed_unique.append(doc)
return docs_processed_unique2.2. 检索器 - 嵌入 🗂️
检索器的作用类似于内部搜索引擎:给定用户查询,它从你的知识库中返回最相关的文档。
对于知识库,我们使用 Langchain 向量数据库,因为它提供了一个方便的 FAISS 索引,并允许我们在整个处理过程中保留文档元数据。
🛠️ 包含可选项:
- 调整分块方法:
- 片段(chunks)的大小
- 方法:在不同的分隔符上分割,使用语义分块…
- 更改嵌入模型
from langchain.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores.utils import DistanceStrategy
import os
def load_embeddings(
langchain_docs: List[LangchainDocument],
chunk_size: int,
embedding_model_name: Optional[str] = "thenlper/gte-small",
) -> FAISS:
"""
Creates a FAISS index from the given embedding model and documents. Loads the index directly if it already exists.
Args:
langchain_docs: list of documents
chunk_size: size of the chunks to split the documents into
embedding_model_name: name of the embedding model to use
Returns:
FAISS index
"""
# load embedding_model
embedding_model = HuggingFaceEmbeddings(
model_name=embedding_model_name,
multi_process=True,
model_kwargs={"device": "cuda"},
encode_kwargs={"normalize_embeddings": True}, # set True to compute cosine similarity
)
# Check if embeddings already exist on disk
index_name = f"index_chunk:{chunk_size}_embeddings:{embedding_model_name.replace('/', '~')}"
index_folder_path = f"./data/indexes/{index_name}/"
if os.path.isdir(index_folder_path):
return FAISS.load_local(
index_folder_path,
embedding_model,
distance_strategy=DistanceStrategy.COSINE,
)
else:
print("Index not found, generating it...")
docs_processed = split_documents(
chunk_size,
langchain_docs,
embedding_model_name,
)
knowledge_index = FAISS.from_documents(
docs_processed, embedding_model, distance_strategy=DistanceStrategy.COSINE
)
knowledge_index.save_local(index_folder_path)
return knowledge_index2.3. 阅读器 - LLM 💬
在这一部分,LLM 阅读器读取检索到的文档以形成其答案。
🛠️ 为了改善结果,我们尝试了以下选项:
- 切换重排序开启或关闭的状态
- 更改阅读器模型
RAG_PROMPT_TEMPLATE = """
<|system|>
Using the information contained in the context,
give a comprehensive answer to the question.
Respond only to the question asked, response should be concise and relevant to the question.
Provide the number of the source document when relevant.
If the answer cannot be deduced from the context, do not give an answer.</s>
<|user|>
Context:
{context}
---
Now here is the question you need to answer.
Question: {question}
</s>
<|assistant|>
"""from langchain_community.llms import HuggingFaceHub
repo_id = "HuggingFaceH4/zephyr-7b-beta"
READER_MODEL_NAME = "zephyr-7b-beta"
HF_API_TOKEN = ""
READER_LLM = HuggingFaceHub(
repo_id=repo_id,
task="text-generation",
huggingfacehub_api_token=HF_API_TOKEN,
model_kwargs={
"max_new_tokens": 512,
"top_k": 30,
"temperature": 0.1,
"repetition_penalty": 1.03,
},
)from ragatouille import RAGPretrainedModel
from langchain_core.vectorstores import VectorStore
from langchain_core.language_models.llms import LLM
def answer_with_rag(
question: str,
llm: LLM,
knowledge_index: VectorStore,
reranker: Optional[RAGPretrainedModel] = None,
num_retrieved_docs: int = 30,
num_docs_final: int = 7,
) -> Tuple[str, List[LangchainDocument]]:
"""Answer a question using RAG with the given knowledge index."""
# Gather documents with retriever
relevant_docs = knowledge_index.similarity_search(query=question, k=num_retrieved_docs)
relevant_docs = [doc.page_content for doc in relevant_docs] # keep only the text
# Optionally rerank results
if reranker:
relevant_docs = reranker.rerank(question, relevant_docs, k=num_docs_final)
relevant_docs = [doc["content"] for doc in relevant_docs]
relevant_docs = relevant_docs[:num_docs_final]
# Build the final prompt
context = "\nExtracted documents:\n"
context += "".join([f"Document {str(i)}:::\n" + doc for i, doc in enumerate(relevant_docs)])
final_prompt = RAG_PROMPT_TEMPLATE.format(question=question, context=context)
# Redact an answer
answer = llm(final_prompt)
return answer, relevant_docs3. 对 RAG 系统进行基准测试
RAG 系统和评估数据集现在准备好了。最后一步是在这个评估数据集上判断 RAG 系统的输出。 为此,我们设置了一个裁判智能体。 ⚖️🤖
在不同的 RAG 评估指标中,我们选择只关注忠实度,因为这是衡量我们系统性能的最佳的端到端指标。
我们使用 GPT4 作为评判者,因为它在实际应用中表现良好,但你也可以尝试其他模型,例如 kaist-ai/prometheus-13b-v1.0 或 BAAI/JudgeLM-33B-v1.0。
💡 在评估提示中,我们给出了每个指标的详细描述,采用 1-5 分的评分刻度,正如 Prometheus 的提示模板 所做的那样:这有助于模型精确地确定其指标。如果你给评判 LLM 一个模糊的评分刻度,那么不同示例之间的输出将不够一致。
💡 再次提示 LLM 在给出最终评分之前先输出其理由,这样它就有更多的 token 来帮助它正式化和详细阐述评判。
from langchain_core.language_models import BaseChatModel
def run_rag_tests(
eval_dataset: datasets.Dataset,
llm,
knowledge_index: VectorStore,
output_file: str,
reranker: Optional[RAGPretrainedModel] = None,
verbose: Optional[bool] = True,
test_settings: Optional[str] = None, # To document the test settings used
):
"""Runs RAG tests on the given dataset and saves the results to the given output file."""
try: # load previous generations if they exist
with open(output_file, "r") as f:
outputs = json.load(f)
except:
outputs = []
for example in tqdm(eval_dataset):
question = example["question"]
if question in [output["question"] for output in outputs]:
continue
answer, relevant_docs = answer_with_rag(question, llm, knowledge_index, reranker=reranker)
if verbose:
print("=======================================================")
print(f"Question: {question}")
print(f"Answer: {answer}")
print(f'True answer: {example["answer"]}')
result = {
"question": question,
"true_answer": example["answer"],
"source_doc": example["source_doc"],
"generated_answer": answer,
"retrieved_docs": [doc for doc in relevant_docs],
}
if test_settings:
result["test_settings"] = test_settings
outputs.append(result)
with open(output_file, "w") as f:
json.dump(outputs, f)EVALUATION_PROMPT = """###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: {{write a feedback for criteria}} [RESULT] {{an integer number between 1 and 5}}\"
4. Please do not generate any other opening, closing, and explanations. Be sure to include [RESULT] in your output.
###The instruction to evaluate:
{instruction}
###Response to evaluate:
{response}
###Reference Answer (Score 5):
{reference_answer}
###Score Rubrics:
[Is the response correct, accurate, and factual based on the reference answer?]
Score 1: The response is completely incorrect, inaccurate, and/or not factual.
Score 2: The response is mostly incorrect, inaccurate, and/or not factual.
Score 3: The response is somewhat correct, accurate, and/or factual.
Score 4: The response is mostly correct, accurate, and factual.
Score 5: The response is completely correct, accurate, and factual.
###Feedback:"""
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import SystemMessage
evaluation_prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(content="You are a fair evaluator language model."),
HumanMessagePromptTemplate.from_template(EVALUATION_PROMPT),
]
)from langchain.chat_models import ChatOpenAI
OPENAI_API_KEY = ""
eval_chat_model = ChatOpenAI(model="gpt-4-1106-preview", temperature=0, openai_api_key=OPENAI_API_KEY)
evaluator_name = "GPT4"
def evaluate_answers(
answer_path: str,
eval_chat_model,
evaluator_name: str,
evaluation_prompt_template: ChatPromptTemplate,
) -> None:
"""Evaluates generated answers. Modifies the given answer file in place for better checkpointing."""
answers = []
if os.path.isfile(answer_path): # load previous generations if they exist
answers = json.load(open(answer_path, "r"))
for experiment in tqdm(answers):
if f"eval_score_{evaluator_name}" in experiment:
continue
eval_prompt = evaluation_prompt_template.format_messages(
instruction=experiment["question"],
response=experiment["generated_answer"],
reference_answer=experiment["true_answer"],
)
eval_result = eval_chat_model.invoke(eval_prompt)
feedback, score = [item.strip() for item in eval_result.content.split("[RESULT]")]
experiment[f"eval_score_{evaluator_name}"] = score
experiment[f"eval_feedback_{evaluator_name}"] = feedback
with open(answer_path, "w") as f:
json.dump(answers, f)🚀 让我们运行一下测试和评估一下答案!👇
if not os.path.exists("./output"):
os.mkdir("./output")
for chunk_size in [200]: # Add other chunk sizes (in tokens) as needed
for embeddings in ["thenlper/gte-small"]: # Add other embeddings as needed
for rerank in [True, False]:
settings_name = f"chunk:{chunk_size}_embeddings:{embeddings.replace('/', '~')}_rerank:{rerank}_reader-model:{READER_MODEL_NAME}"
output_file_name = f"./output/rag_{settings_name}.json"
print(f"Running evaluation for {settings_name}:")
print("Loading knowledge base embeddings...")
knowledge_index = load_embeddings(
RAW_KNOWLEDGE_BASE,
chunk_size=chunk_size,
embedding_model_name=embeddings,
)
print("Running RAG...")
reranker = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0") if rerank else None
run_rag_tests(
eval_dataset=eval_dataset,
llm=READER_LLM,
knowledge_index=knowledge_index,
output_file=output_file_name,
reranker=reranker,
verbose=False,
test_settings=settings_name,
)
print("Running evaluation...")
evaluate_answers(
output_file_name,
eval_chat_model,
evaluator_name,
evaluation_prompt_template,
)检查结果
import glob
outputs = []
for file in glob.glob("./output/*.json"):
output = pd.DataFrame(json.load(open(file, "r")))
output["settings"] = file
outputs.append(output)
result = pd.concat(outputs)result["eval_score_GPT4"] = result["eval_score_GPT4"].apply(lambda x: int(x) if isinstance(x, str) else 1)
result["eval_score_GPT4"] = (result["eval_score_GPT4"] - 1) / 4average_scores = result.groupby("settings")["eval_score_GPT4"].mean()
average_scores.sort_values()结果示例
让我们加载通过调整这个 notebook 中可用的不同选项所获得的结果。关于这些选项为何有效或无效的更多细节,请参阅 高级 RAG 的 notebook。
正如在下面的图表中所看到的,一些调整并没有带来任何改善,而有些则带来了巨大的性能提升。
➡️ 所以没有单一的好方法:在调整你的 RAG 系统时,应该尝试几种不同的方向。
import plotly.express as px
scores = datasets.load_dataset("m-ric/rag_scores_cookbook", split="train")
scores = pd.Series(scores["score"], index=scores["settings"])fig = px.bar(
scores,
color=scores,
labels={
"value": "Accuracy",
"settings": "Configuration",
},
color_continuous_scale="bluered",
)
fig.update_layout(
width=1000,
height=600,
barmode="group",
yaxis_range=[0, 100],
title="<b>Accuracy of different RAG configurations</b>",
xaxis_title="RAG settings",
font=dict(size=15),
)
fig.layout.yaxis.ticksuffix = "%"
fig.update_coloraxes(showscale=False)
fig.update_traces(texttemplate="%{y:.1f}", textposition="outside")
fig.show()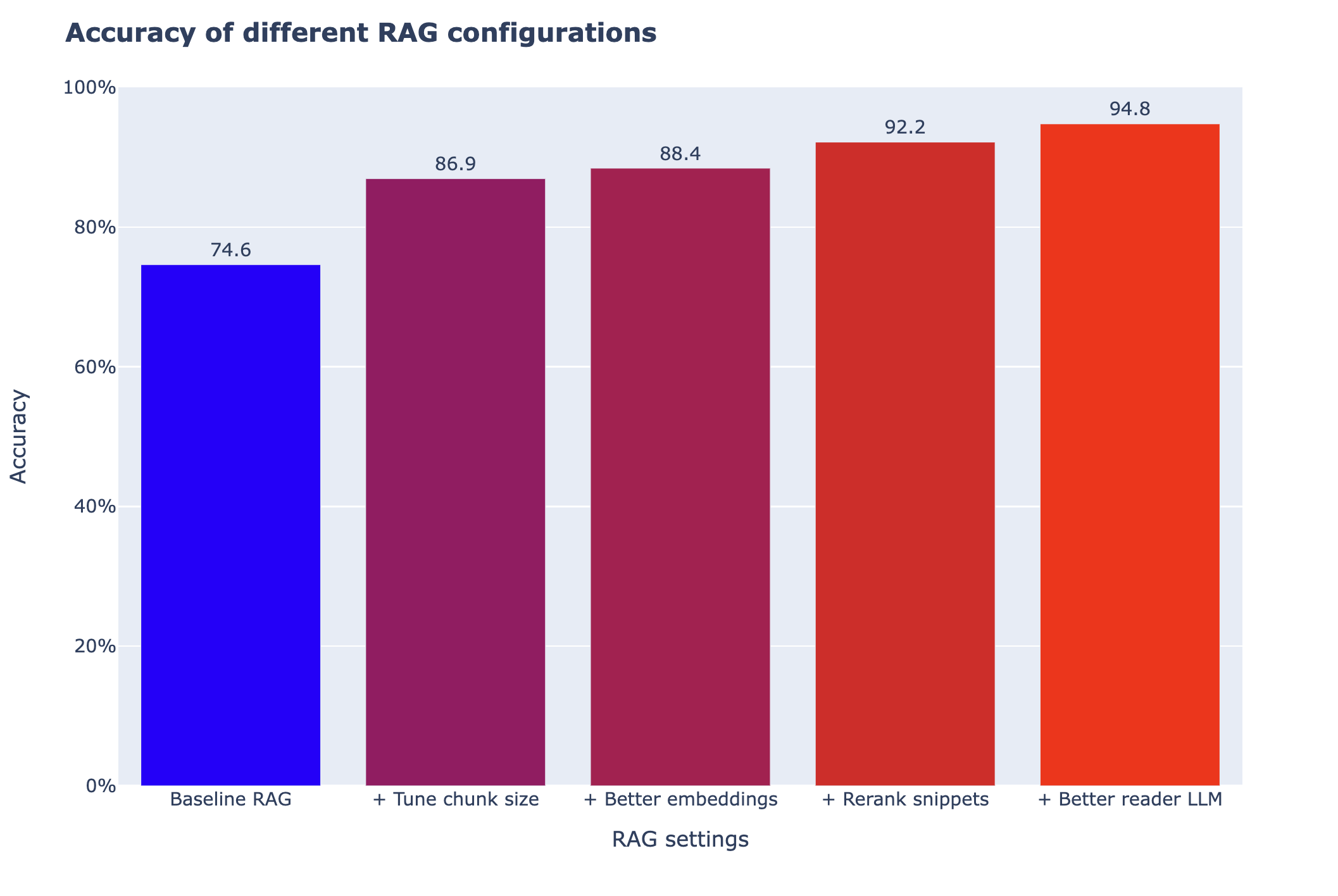
如上图所示,这些调整对性能的影响各不相同。尤其是调整片段大小,既简单又非常有影响力。
但这只是针对我们的情况:你的结果可能大不相同:现在你已经有了一个可靠的评估流水线,可以开始探索其他选项了!🗺️
< > Update on GitHub