Audio Course documentation
Ses veri kümesini ön işleme
Ses veri kümesini ön işleme
🤗 Veri Kümeleri ile bir veri kümesi yüklemek eğlencenin sadece yarısıdır. Bir modeli eğitmek veya çalıştırmak için kullanmayı planlıyorsanız Çıkarım yapmak için öncelikle verileri önceden işlemeniz gerekecektir. Genel olarak bu, aşağıdaki adımları içerecektir:
- Ses verilerinin yeniden örneklenmesi
- Veri kümesini filtreleme
- Ses verilerini modelin beklenen girişine dönüştürme
Ses verilerini yeniden örnekleme
load_dataset işlevi, ses örneklerini indirirken, bu örneklerin yayınlandığı örnekleme hızını kullanır. Bu, eğitmeyi veya çıkarmayı planladığınız modelin beklediği örnekleme hızı ile her zaman uyuşmaz. Örnekleme hızları arasında bir uyumsuzluk varsa, sesi modelin beklediği örnekleme hızına yeniden örnekleyebilirsiniz.
Çoğu önceden eğitilmiş model, ses veri kümelerinde 16 kHz örnekleme hızında önceden eğitildi. MINDS-14 veri kümesini keşfettiğinizde, bu verinin 8 kHz örnekleme hızında olduğunu görmüş olabilirsiniz, bu da muhtemelen bunu yükseltmemiz gerekeceği anlamına gelir.
Bunu yapmak için, 🤗 Datasets’ın cast_column yöntemini kullanabilirsiniz. Bu işlem sesi yerinde değiştirmez, ancak veri kümesine ses örneklerini yüklerken on-the-fly olarak örnekleme yapması gerektiğini belirtir. Aşağıdaki kod, örnekleme hızını 16 kHz olarak ayarlayacaktır:
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))MINDS-14 veri kümesindeki ilk ses örneğini yeniden yükleyin ve istenen “örnekleme hızına” yeniden örneklendiğini kontrol edin:
minds[0]Çıktı:
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}Dizi değerlerinin de artık farklı olduğunu fark edebilirsiniz. Bunun nedeni artık iki kat daha fazla genlik değerine sahip olmamızdır. daha önce sahip olduğumuz her biri.
Veri kümesini filtreleme
Verileri bazı kriterlere göre filtrelemeniz gerekebilir. Yaygın durumlardan biri, ses örneklerinin belirli bir Belirli süre. Örneğin, yetersiz bellek hatalarını önlemek için 20 saniyeden uzun örnekleri filtrelemek isteyebiliriz. Bir modeli eğitirken.
Bunu 🤗 Datasets’in filter metodunu kullanarak ve ona filtreleme mantığı olan bir fonksiyon geçirerek yapabiliriz. Bir tane yazarak başlayalım
Hangi örneklerin saklanacağını ve hangilerinin atılacağını gösteren işlev. Bu işlev, “ses_uzunluğu_aralığındadır”,
Örnek 20 saniyeden kısaysa “Doğru”yu, 20 saniyeden uzunsa “Yanlış”ı döndürür.
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDSFiltreleme işlevi bir veri kümesinin sütununa uygulanabilir ancak bunda ses izleme süresine sahip bir sütunumuz yoktur. veri kümesi. Ancak bir tane oluşturabilir, o sütundaki değerlere göre filtreleyebilir ve ardından kaldırabiliriz.
# ses dosyasından örneğin süresini almak için librosa'yı kullanalım
new_column = [librosa.get_duration(path=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# filtreleme işlevini uygulamak için 🤗 Veri Kümelerinin "filtre" yöntemini kullanın
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# geçici yardımcı sütunu kaldırın
minds = minds.remove_columns(["duration"])
mindsÇıktı:
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})Veri kümesinin 654 örnekten 624’e filtrelendiğini doğrulayabiliriz.
Ses verilerinin ön işlenmesi
Ses veri kümeleriyle çalışmanın en zorlayıcı yönlerinden biri, veriyi model eğitimi için doğru formatta hazırlamaktır. Gördüğünüz gibi, ham ses verileri örnek değerlerinin bir dizisi olarak gelir. Ancak, kullanıyorsanız, çıkarım için kullanıyor olsanız veya göreviniz için ince ayar yapmak istiyorsanız, önceden eğitilmiş modeller, ham verilerin giriş özelliklerine dönüştürülmesini bekler. Giriş özellikleri için gereksinimler bir modelden diğerine değişebilir - bunlar modelin mimarisine ve önceden eğitildiği verilere bağlıdır. İyi haber şu ki, her desteklenen ses modeli için 🤗 Transformers, ham ses verilerini modelin beklediği giriş özelliklerine dönüştürebilen bir özellik çıkarıcı sınıfı sunar.
Peki özellik çıkarıcı ham ses verileriyle ne yapar? Şimdi Whisper‘ın fotoğraflarına bir göz atalım Bazı ortak özellik çıkarma dönüşümlerini anlamak için özellik çıkarıcı. Whisper, önceden eğitilmiş bir modeldir. Alec Radford ve diğerleri tarafından Eylül 2022’de yayınlanan otomatik konuşma tanıma (ASR). OpenAI’den.
İlk olarak, Whisper özellik çıkarıcısı bir ses örneklerinin yığınını, tüm örneklerin 30 saniyelik bir giriş uzunluğuna sahip olduğu şekilde doldurur/keser. Bu süreden daha kısa olan örnekler, sıfırları dizinin sonuna ekleyerek 30 saniyeye kadar doldurulur (bir ses sinyalindeki sıfırlar, hiç sinyal veya sessizlikle karşılık gelir). 30 saniyeden daha uzun olan örnekler 30 saniyeye kadar kesilir. Yığındaki tüm öğeler giriş uzayındaki maksimum uzunluğa doldurulduğu/kesildiği için bir dikkat maskesine ihtiyaç yoktur. Whisper bu açıdan benzersizdir, diğer çoğu ses modelleri, dizilerin nerede doldurulduğunu ayrıntılı olarak belirten ve bu nedenle öz-dikkat mekanizmasında nerede görmezden gelinmesi gerektiğini belirten bir dikkat maskesi gerektirir. Whisper, bir dikkat maskesi olmadan çalışacak şekilde eğitilmiştir ve girişleri nerede göz ardı edeceğini doğrudan konuşma sinyallerinden çıkarır.
Whisper özellik çıkarıcısının gerçekleştirdiği ikinci işlem, doldurulmuş ses dizilerini log-mel spektrogramlarına dönüştürmektir. Hatırlarsanız, bu spektrogramlar bir sinyalin frekanslarının zaman içinde nasıl değiştiğini, mel ölçeğinde ifade edilmiş ve insan işitmesini daha iyi temsil etmek için decibel cinsinden ölçülmüş şekilde açıklar (log kısmı).
Tüm bu dönüşümler birkaç satır kodla ham ses verilerinize uygulanabilir. Devam edelim ve yükleyelim ses verilerimize hazır olmak için önceden eğitilmiş Whisper kontrol noktasından özellik çıkarıcı:
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")Daha sonra, tek bir ses örneğini “feature_extractor”dan geçirerek ön işleme tabi tutacak bir işlev yazabilirsiniz.
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return featuresVeri hazırlama fonksiyonunu tüm eğitim örneklerimize 🤗 Datasets’in harita yöntemini kullanarak uygulayabiliriz:
minds = minds.map(prepare_dataset)
mindsÇıktı:
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)Bu kadar kolay, artık veri kümesinde ‘giriş_özellikleri’ olarak log-mel spektrogramlarımız var.
Bunu ‘minds’ veri kümesindeki örneklerden biri için görselleştirelim:
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()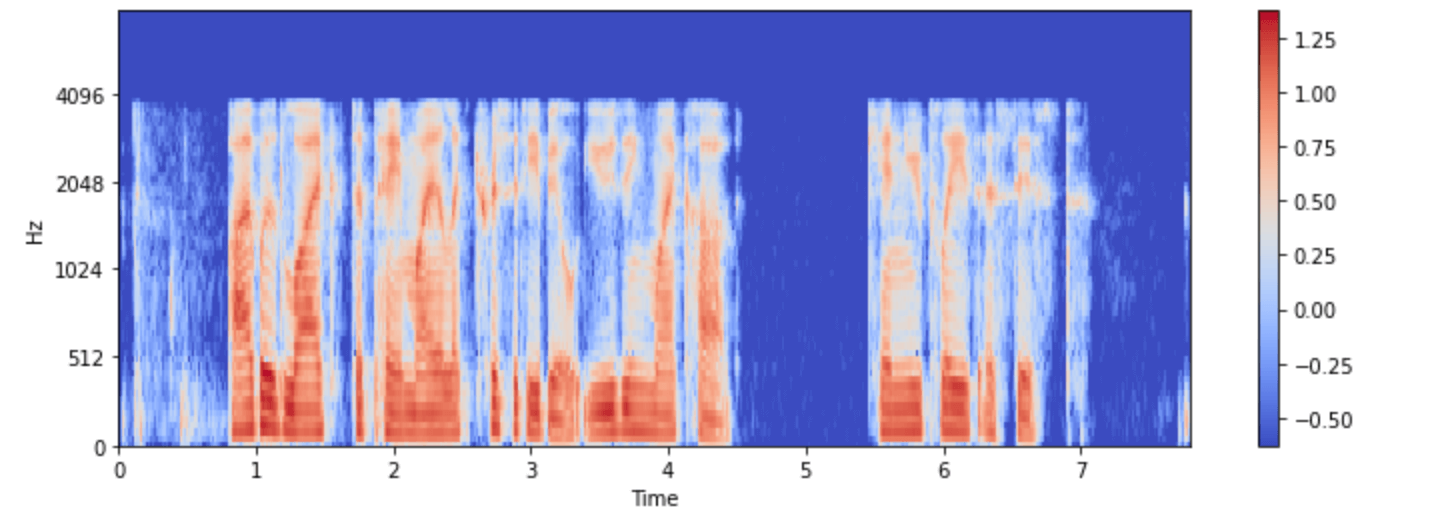
Artık Whisper modelindeki ses girişinin ön işlemeden sonra nasıl göründüğünü görebilirsiniz.
Modelin özellik çıkarıcı sınıfı, ham ses verilerinin modelin beklediği formata dönüştürülmesiyle ilgilenir. Fakat, ses içeren birçok görev çok modludur; Konuşma tanıma. Bu gibi durumlarda 🤗 Transformers modele özel olarak da hizmet vermektedir. metin girişlerini işlemek için belirteçler. Tokenizer’lara ilişkin derinlemesine bilgi edinmek için lütfen NLP kursumuza bakın.
Whisper ve diğer multimodal modeller için özellik çıkarıcıyı ve tokenizer’ı ayrı ayrı yükleyebilir veya her ikisini de sözde işlemci. İşleri daha da kolaylaştırmak için, bir modelin özellik çıkarıcısını ve işlemcisini bir bilgisayardan yüklemek için ‘Otomatik İşlemci’yi kullanın. kontrol noktası şöyle:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")Burada temel veri hazırlama adımlarını gösterdik. Elbette özel veriler daha karmaşık ön işleme gerektirebilir.
Bu durumda, herhangi bir özel veri dönüşümü gerçekleştirmek için prepare_dataset fonksiyonunu genişletebilirsiniz. 🤗 Veri Kümeleri ile,
bunu bir Python işlevi olarak yazabiliyorsanız veri kümenize uygulayabilirsiniz!!